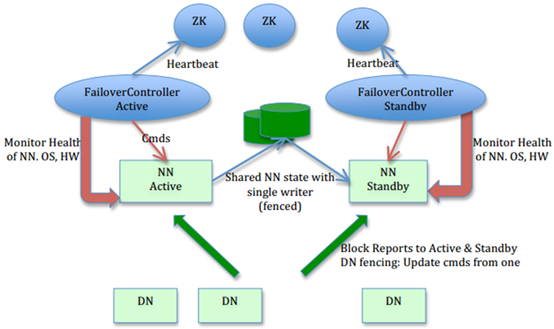
NamenodeHA原理详解社区hadoop2.2.0release版本开始支持NameNode的HA,本文将详细描述NameNodeHA内部的设计与实现。为什么要NamenodeHA?NameNodeHighAvailability即高可用。NameNode很重要,挂掉会导致存储停止服务,无法进行数据的读写,基于此NameNode的计算(MR,Hive等)也无法完成...
(more)关注一下同时补充一些背景,这块我参与的比较深所以有一些观点刚好也借此机会跟同行们讨论一下。首先是BI层由于存在自主分析的需求,所以聚合结果或者临时表这种方式业务上不可行,客户常见的分析维度经过多轮筛选依旧在70+个,且个人认为随着产品更加扁平维度会以标签的形式扩...
大数据是收集、整理、处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称。虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性、规模,以及价值在最近几年才经历了大规模扩展。本文将介绍大数据系统一个最基本的组件:处理框架...
(more)大数据时代已经来临,教育行业作为社会大众共享的无形财富,其开放己成为数据整合和共享应用的前提条件。“十三五"期间有望形成和谐健康的行业生态。基础设施提供商、大数据服务商、数据挖掘与分析提供商、数据应用服务提供商、数据安全提供商、教育行政部门以及教育大数据...
(more)大数据时代已经来临,教育行业作为社会大众共享的无形财富,其开放己成为数据整合和共享应用的前提条件。“十三五"期间有望形成和谐健康的行业生态。基础设施提供商、大数据服务商、数据挖掘与分析提供商、数据应用服务提供商、数据安全提供商、教育行政部门以及教育大数据...
(more)elk 常用组件, 上层业务封装还需要求其他组件完成日志分析 elk + redis + mysql 热点数据 , 热点分析等等, 看你的业务是什么模式和 开发人员偏好
SparkStreaming和Strom都属于实时计算框架,有点都是可以做到对数据的实时处理。SparkStreaming是基于Spark Core实现的,所以对数据的处理要形成RDD,暨要形成数据窗口,所以其处理过程可以称之为微批处理,而storm是可以做到实时处理每一条数据的,所以相对来说,实时性比sparkstream...
无论是hive还是spark,数据都是按数据块大小读取。建议试下写parquet文件前设置parquet.block.size参数,保证每个块大小合适,如果要在读取时改变并行效果,可以通过设置repartition调整partition个数。通过两个参数配合应该能满足你的需求。...
Kafka可保证在同一partition中的消息是有序的,producer把数据按照同一主键发到同一个partition即可。