GPU、CPU优化利用?
如何通过GPU 计算节点与 CPU 指令集的配置,高效完成机器学习、深度学习、图像识别等 AI 计算任务,高性能地承载企业大规模并行计算需求,能否通过滚动升级方式,在主机不停机、应用不停服的状态下完成升级,有效保障企业业务的连续性
提问者已获得满意解答
3同行回答
NGC应用市场有大量可用的GPU加速的AI模型镜像,数据科学家可以开箱即用,将关注点放在业务目标。同时容器和K8S编排技术的引入,正是让业务连续性有了很大程度的提升。红帽的企业级容器平台产品,可以将CPU 内存 GPU 磁盘等计算资源统一池化。一个集群的管理节点统一调度工作节点,容器化的应用可以根据负载分配策略分布在相应的节点。无论计划内升级停机还是故障宕机情况下,受影响的应用Pod可以迅速漂移到其他可用节点。因此,从用户服务的角度看是完全满足高可用和稳定性要求的。
收起1. NVAIE可以支持只有CPU的服务器完成机器学习任务。例如Triton Inference Server 用于多推理模型部署可以支持仅有CPU的服务器。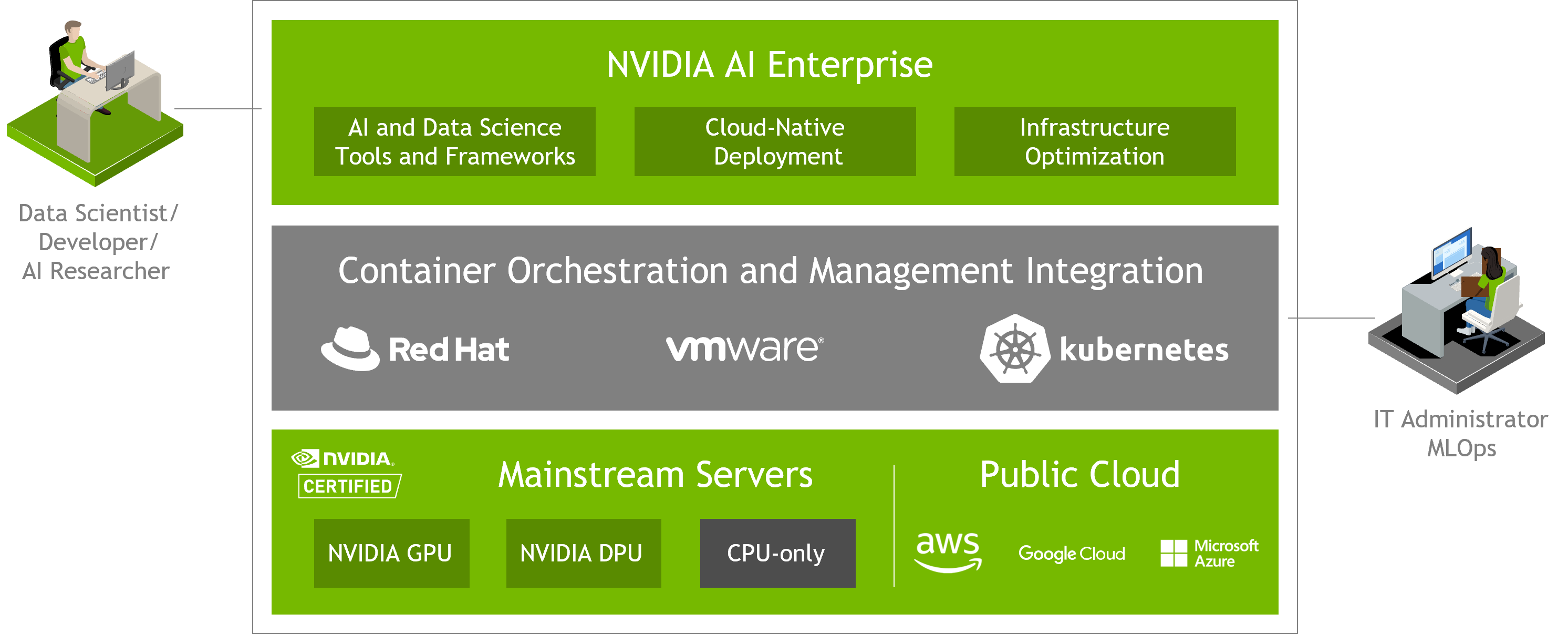
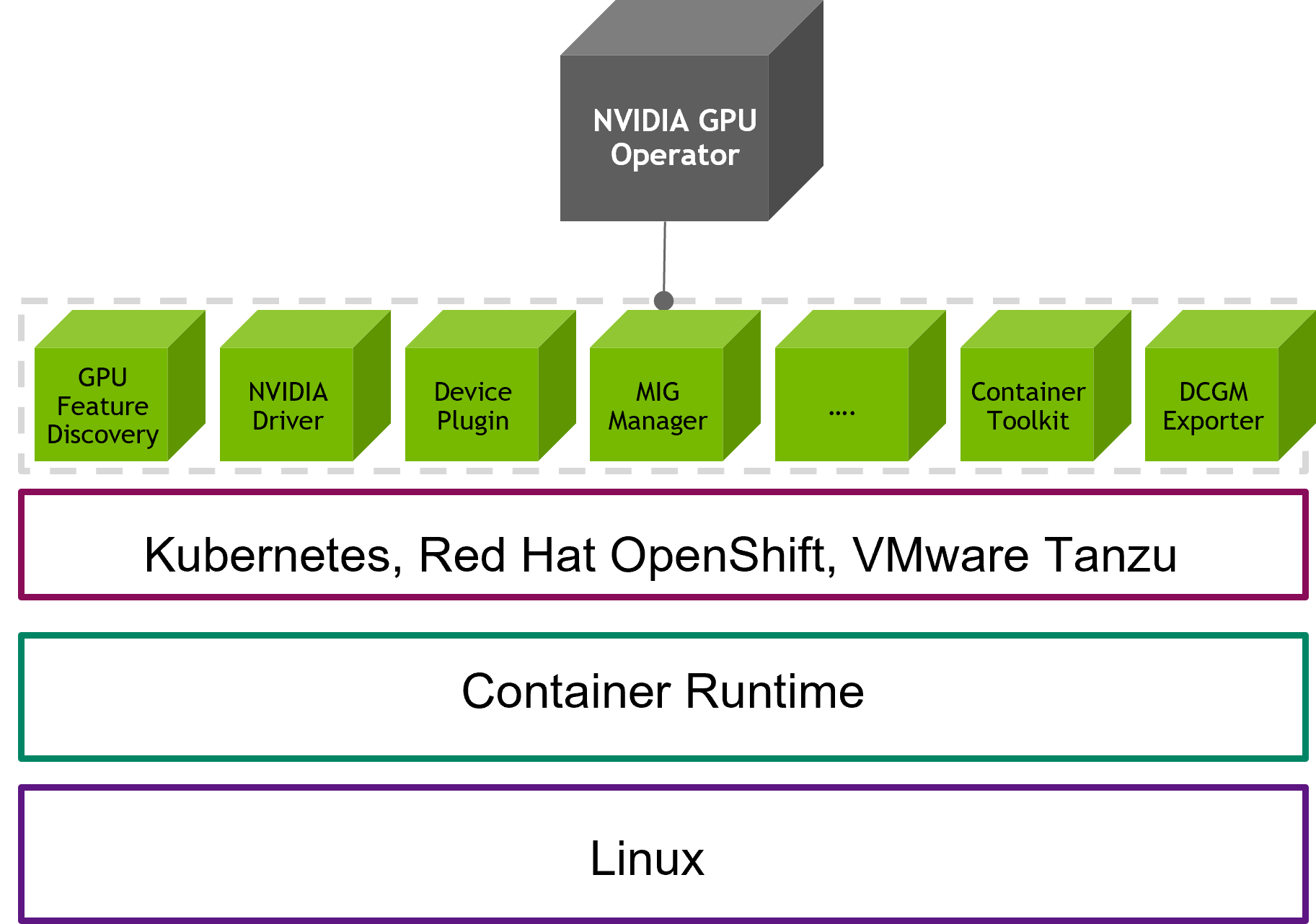
2. NVAIE中GPU Operator,基础架构团队也可以将 CPU 映像与 GPU 工作节点一起使用。