互联网服务Ceph
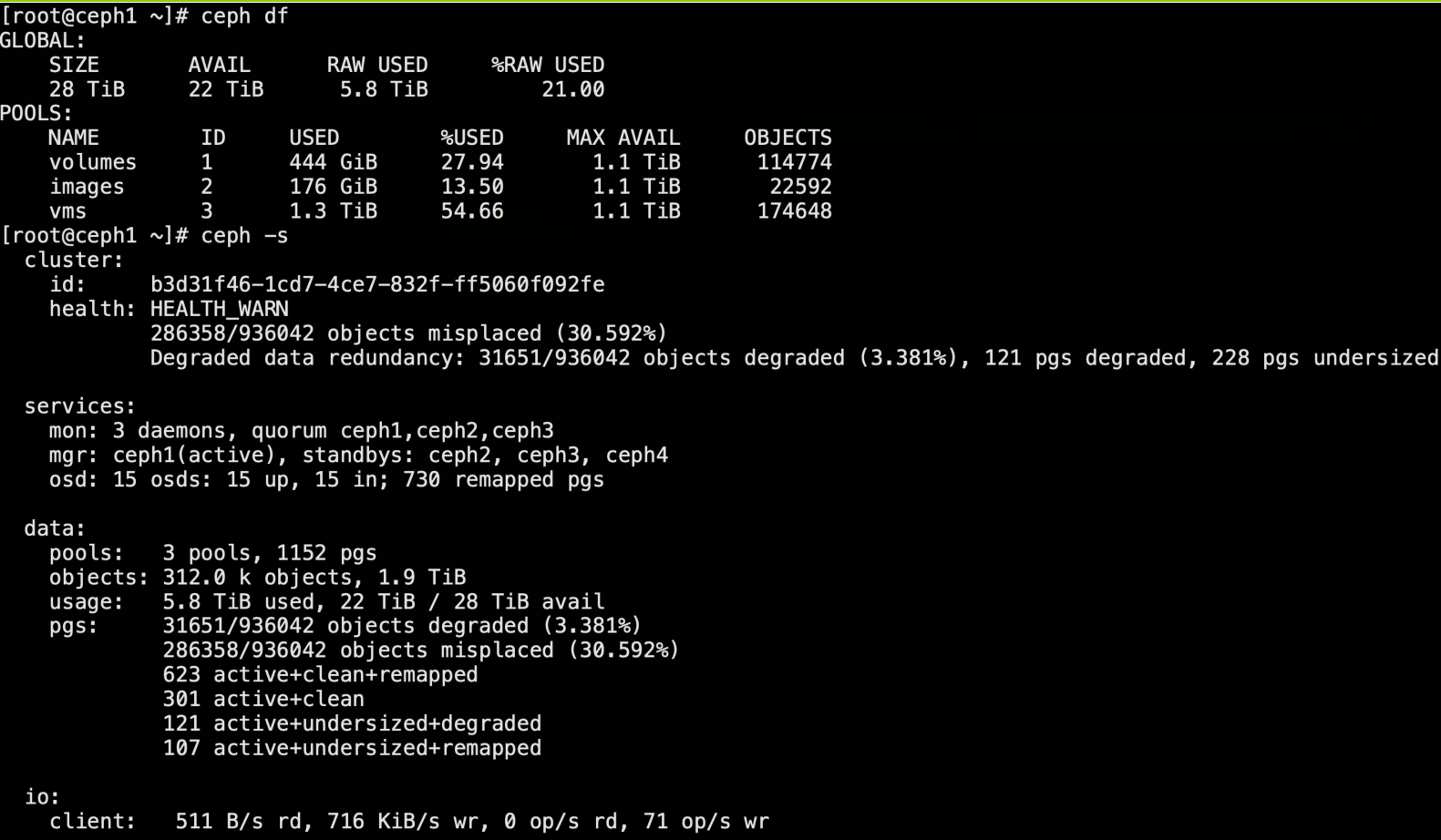
ceph osd磁盘空间不一致,导致大磁盘空间使用率极低,如何解决?
ceph集群初始时有9个osd,其中六个0.5T,三个0.9T,使用70%后扩容加入六个osd,都是3.6T,调整过pg及pgp,集群恢复之后,新的数据并不多往大磁盘的osd写,导致前面使用率已经很高的osd很快又濒临写满,导致整个集群空间利用率很低,通过批量调节reweight后,数据并没有明显往后几个大osd迁移,只是在前几个小osd来回迁移,并且pg会出现大量misplaced状态,请问如何提高后加入的大osd的空间使用率?多谢!