分布式存储技术探讨系列:Ceph的数据分布算法
## 1. 引言
数据分布是分布式存储系统的要解决的首要问题,在分布式存储系统当中,最核心也是最基本的要求就是数据的分布算法或者规则能够解决以下几个问题:
(1) 数据负载均衡:数据能够均匀地分布在磁盘容量不等的存储节点;
(2) 故障隔离:保障不同的数据副本分布于不同的故障隔离域;
(3) 节点变动与数据迁移:正常节点上的迁移影响达到最小,数据量达到最少。
很多分布式存储系统都会用到一致性哈希算法来支撑其数据的均衡分布。例如在Aamzon的Dyanmo键值存储系统,OpenStack的Swift对象存储系统。而Ceph的数据分布主要是靠哈希和CRUSH算法支撑的,而CRUSH算法又是其核心算法。
2. Object_PG映射算法
2.1 映射过程
从客户端维度看Object-PG的过程,需要经过两个关键步骤:
(1)File —> Object:将文件按照固定粒度大小(2M/4M)进行切分,得到对象(Obj-ID);
(2)Object —> PG:通过哈希算法HASH(Obj-ID) % PG_Number,得到PG(PG-ID)。
首先,通过接口调用保障文件可以平均切分为多个2/4M的对象以及对象的有序标识号。然后,通过哈希算法将有序序列分散,经过取余计算将对象均匀分布在逻辑分区内的PG上。
2.2 PG的价值
我们知道,在Ceph中的Pool& PG(Placement Group)其实是逻辑概念,它是把Ceph的整个存储空间用Pool划为若干逻辑的分区,每一个Pool又是由很多个PG组成,每一个PG对应于唯一Object的数据分布控制,它对应于一个OSD的故障隔离组(1Primary-OSD & 2Replic-OSD)。结合图2.2所示,我们可以清晰看到PG在数据分布当中的首个核心价值。
图2.2 FIle_PG 数据映射分布图示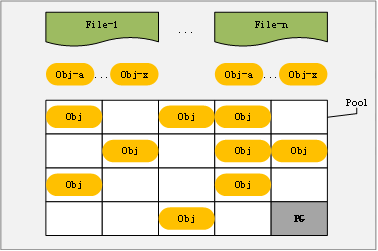
结合图2.2,我们回过头来看File_PG的算法过程:
首先,从File到Object的切分过程,会得到一组有序标识的Objects;然后经过哈希并取余的算法( HASH(Obj-ID) % PG_Number )得到Object对应的PG。Pool和PG的组成结构是个虚拟的概念,在物理节点经常变动的整个过程当中,每一个Pool之内的PG数量是不会发生变化的。不难理解, 随着写入文件数量规模越来越大,被切分的一个个有序Object组会均匀分布在图2.2 Pool当中的各个PG上,而且Object-ID的取值范围远远超过PG_Number,这样就会保障同一个文件当中Object在整个Pool分布的分散性特点。**
虽然Object-PG并不代表数据的物理分布达到了应有的均衡性,但是最起码为后续PG-OSD映射的均衡性奠定了基础。读到这里,或许有人会有疑问“ 为什么不直接完成Object-OSD的映射,这样不是更直接,性能更好么? ”。
那么,顺着这个疑问的思路,我们不妨把算法改变为( HASH(Obj-ID) % OSD_Number ),这里的取余被除数由PG_Number变成了OSD_Number,逻辑节点变成了物理节点,不变的因素变成了经常会发生变化的因素(故障&扩容)。一旦发生这种变化,之前存储的所有数据的计算结果大概率发生变化,这样的变化会带来大规模的数据迁移。这显然是与分布式系统数据分布的基本诉求点是相悖的。
因此,无论是采用哈希一致性算法还是采用其他数据分布算法,中间的虚拟对象是必要的。**
3. PG_OSD映射算法
3.1 Cluster_Map
Ceph的cluster map 包含的几个主要map分别是 Monitor map、OSD map、CRUSH map、PG map。这些 cluster map 将有助于知晓集群的状态和配置。接下来分别看看这些Map当中都包含了那些基础的信息。
(1) Monitor Map:它包含Monitor基本信息,例如集群ID、monitor节点信息、IP地址和端口号、配置版本、时间戳等相关信息。
(2) OSD Map:一方面是OSD自身的信息(节点、容量、状态、权重等);另外一方面是存储池相关的信息(存储池名称、ID、类型、副本级别、PGs)。
(3) PG Map:一方面是PG自身信息(ID、版本、时间戳、OSD map的最新版本号、容量);另外一方面是对象信息(数量、状态、时间戳、OSD sets等)。
(4) CRUSH Map:它保存的信息包括集群设备列表、bucket列表、故障域(failure domain)分层结构、保存数据时用到的为故障域定义的规则(rules)等。
PG_OSD的映射过程主要依赖于PG Map & CRUSH Map。 接下来我们来看看CRUSH Map究竟是一个什么样的数据结构。将代码的结构化逻辑提取出来之后,如下所示

这里面,“device”即OSD实例,“types”={root、region、datacenter、room、pod、pdu、row、rack、chassis、host、osd}。从“types”可选项的数据结构不难看出它是一个分层的树形结构,从上到下包含了根、区域、数据中心、机房...、主机、磁盘系列分层对象。如图3.1.2所示:
图3.1 CRUSH Map说明示意图

图中,黑色的节点我们称之为Bucket,绿色的节点称之为Leaf,那么“buckets”就保存了一颗具有所有OSD信息的完整的树形结构,
- bucket-type: 类型 (磁盘、主机、机柜...), 用来指定 该Bucket 在CRUSH分层结构中的位置 ;
- alg : Ceph提供多个bucket类型的算法选择用来寻址其下面的叶子节点;
- weight: bucket 下面所有节点的权重累积信息, 所有的磁盘无论其容量大小都要被加入到集群中被同等地利用。CRUSH给每个OSD分配一个权重。OSD的权重越高,说明它的物理存储容量越大。权重表示设备容量之间的相对差异 ;
- item: bucket 下面所有 干节点bucket 以及 叶子 节点的列表信息,包含权重 。
接下来再看CRUSH Map当中的“rules”,CRUSH map 包含了若干 CRUSH rules 来决定存储池内的数据存放方式。它们定义了存储池的属性,以及存储池中数据的存放方式。它们指定了复制(replication)和放置(placement)策略。
- step take: 获取一个 bucket 名称,开始遍历其树。
- step choose:选择某类型的若干(N)bucket,这里数字 N 通常是存储池的副本份数。
- step chooseleaf:首先选择指定 bucket 类型的一组 bucket,然后从每个bucket 的子树中选择叶子节点。该组中 bucket 的数目 N 通常是该存储池的副本份数。
3.2 CRUSH寻址算法
从上一节的介绍当中,我们基本了解了CRUSH Map的数据结构以及不同参数的重要意义。本节我们基于以上基础,来分析从PG到OSD的具体过程。这个过程就是要在CRUSH树形结构中解决“从哪里出发?途径哪几条路?到达哪些终点目标?”这几个问题;那么为了解决这几个问题需要如下输入“PG Map、CRUSH Map、Rule”。如图3.2所示:
图3.2 CRUSH 寻址流程示意图

如图,PG_OSD逻辑过程当中的PG要解决三个问题:
(1)Where:从哪里开始寻找OSD,原点在哪里?我们在上一节内容当中的CRUSH Map的定义当中看到了。其中“rules”的实例会明确定义PG寻找OSD的原点应该是哪一个Bucket实例。这个我们在做Ceph集群规划配置的时候可以输入我们相应的规则,默认为根节点。
(2)How:如何寻找OSD的路由,原点下面有很多分支,路由如何选择?同样在CRUSH Map当中的“rules”的实例当中会定义。具体为“step choose firstn {num} type {busket-type}”,只不过这里需要一些输入。
根据我们的规则确定副本数和故障隔离区类型获得了num&busket-type,可以启动计算了。在计算的过程当中还要调用CRUSH算法,而CRUSH算法就需要PG_ID、Buckets Tree等这些数据结构实例以及相应参数num的输入,才可以最终得到相应数目的Buckets。
(3)Which:如何寻找到具体的OSD?既然Bucket都定了,那么我们只需要在How的循环过程中寻找每个Bucket下面的Leaf节点。如何能定位到这个叶子节点,这就需要遍历Bucket数据结构里面定义的Item数据结构了。按照前文的解释,Item本身是一个包含了Bucket下面所有OSD及其权重Weight的集合,目标是权重最大,但是如何遍历就取决于Items的几种数据结构组织模式,也就是Bucket实例参数当中的 alg (Uniform、List、Tree、Straw),不同的数据结构在寻址复杂性以及集群变化后的受影响程度上都会有较大的差异。后面的章节我们继续这个问题。
3.3 Bucket alg
前面的章节介绍,我们基本解决了从PG到OSD这个路径当中的大部分问题,只剩下唯一的问题就是用什么样的算法去遍历Bucket下面的所有Leaf节点,以确定最终的OSD。这里就需要搞清楚Bucket下面所有节点的数据组合类型(Bucket alg)以及它相应的算法特性。Bucket alg定义的是Bucket的组织模式,主要有四种类型:Uniform、List、Tree、Straw。
(1) Uniform: 当所有存储设备的权重都统一时可以使用这种类型的bucket , 当权重不统一时不能使用。在这种类型的bucket中添加或者删除设备将会 导致大量 数据重新放置 , 效率 较差 。适用于所有子节点权重相同的情况,而且bucket很少添加删除 节点 ,这种情况查找速度应该是最快的 。
(2) List: 这种桶把它们的内容汇聚为链表。它基于 RUSH P 算法,一个列表就是一个自然、直观的扩张集群:对象会按一定概率被重定位到最新的设备、或者像从前一样仍保留在较老的设备上。结果是优化了新条目加入桶时的数据迁移。然而,如果从链表的中间或末尾删除了一些条目,将会导致大量没必要的挪动。所以这种桶适合永不或极少缩减的场景。
(3) Tree: 它用一种二进制搜索树, 规模效率远高于列表 。列表buckets对于少量的数据项还是高效的, 当链表达到较大规模时, 其时间复杂度就太大了。树状buckets由RUSHT发展而来,它通过将这些大量的数据项储存到一个二叉树中来解决这个问题。它将定位的时间复杂度由O(n)降低到O(logn),这使得它们更适合管理更大规模的设备或嵌套桶。
(4) Straw: 这种类型让Bucket所包含的所有item公平的竞争 ,而不需要遍历 。这种算法就像抽签一样,所有的item都有机会被抽中 ,但是长签被抽中的概率更高 。每个签的 长度是基于OSD权重基础之上又加入了随机因子参与被计算出来的权重,可以将有限的权重序列变为散列化长度的抽签 。这种Bucket是Ceph 曾 默认使用的Bucket,所以它也是经过大规模测试的,稳定性较好。虽然它的查询性能不如List和Tree,但它在控制数据迁移方面是最优的。 后续优化之后又出现了Straw2。
对比来看,从查询复杂度、添加节点以及删除节点三个维度来看各个alg类型的优略:
| 类型 | 时间复杂度 | 添加节点 | 删除节点 |
| Uniform | O(1) | Poor | Poor |
| List | O(n) | Optimal | Poor |
| Tree | O(logn) | Good | Good |
| Straw | O(n) | Better | Better |
从以上各种数据结构类型的三个维度对比来看,Straw在各个维度都比较均衡的类型,也更适合大规模的分布式存储系统,因此通常都会采用Straw来作为Bucket的数据结构类型来使用。
4. 结语
Ceph数据分布本身是依靠动态计算来实现Object到OSD的映射,无论是数据的写还是后期的读操作,都是要依靠算法来实现。分布式存储系统本身对数据分布有三个基本诉求:通过PG虚拟化节点的设计、CRUSH寻址算法的输入因子(PG-ID、CRUSH-MAP)两部分的影响,数据均衡分布应该是可以满足诉求的;通过CRUSH-MAP的分层树状结构以及CRUSH算法当中的Rule输入,也可以满足关于分布式存储数据分布故障隔离的诉求;最后通过Bucket数据结构类型的选择,也可以在不同场景下实现数据迁移的最小化。因此Ceph的数据分布算法机制满足了分布式存储所要求的所有基本诉求。
但是,并不是说Ceph本身是一个防止四海皆准的分布式存储系统,我们仍然需要根据具体的业务场景以及系统规模因素,对故障隔离规则、Bucket数据结构类型等关键因素提前进行规划,这样才能更好的适应企业分布式存储业务的具体场景,发挥出其应有的效应。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞2本文隶属于专栏

作者其他文章
评论 10 · 赞 17
评论 2 · 赞 14
评论 5 · 赞 4
评论 0 · 赞 10
评论 1 · 赞 10
添加新评论0 条评论