国产数据库可靠性/运维问题如何兜底?
近日,与一分布式架构的先行者交流当前的技术架构,原来的Oracle数据库不管是跑在Power小机还是x86服务器,数据库都是推荐采用EMC,HDS,华为这些专业厂家的外置企业级高可靠存储,确保长期的稳定可靠,几年都不会有问题,盘的故障很正常,存储系统自动隔离修复,上层数据库无感。
而现在采用了国产分布式数据库,承载了关键的系统,换到服务器内置NVMe盘,一台服务器配置4~24块3.84TB SSD,生产中心两个机房很近的楼层,合计5副本模式,客户反馈时不时就出现不明原因的坏盘,数据库就切换节点,然后恢复重建副本就非常复杂,节点切换了就肯定得修复,万一再有一台服务器出问题就更麻烦了。关键是这个问题没有解决方案,有病但是没有“药”,只能眼睁睁地看着盘坏了就切换节点影响业务,再重建副本。客户需要调研一下SSD盘的故障率,现在现网本地盘量很大,都上X万块了,假如有0.X%左右的年故障率,那平均每月甚至每周都可能坏的,每周都因为一块盘故障就切换节点,hang住几十秒,进行复杂的人工恢复,是不是太不让人省心了。
另外客户反馈某系统数据库改造规划要上千台服务器,这个都上X亿了,成本太高。服务器采购的时候固定典型配置了10块3.84TB盘甚至24块,但是应用系统可能就几百GB数据,导致很多SSD盘空间太浪费了,应用系统数据库容量是很难跟服务器本地盘容量匹配,资源分布到孤岛似的各节点。客户领导要求调研有没有更好的方案?
其实这个传说中的分布式架构的确给很多用户带来巨大的困扰。经典IOE时代,Oracle数据库+企业级高可靠存储是标配,Oracle也可以做多副本,重要系统数据库怎么敢推荐架在不可靠的服务器本地盘呢?Oracle管好自己的数据库逻辑,硬件的可靠性加固交给硬件厂商。但是国产数据库厂商是大胆地推荐,还自以为是最佳实践,这个就只是简单的三副本而已,这么多盘/RAID是没有人管的,出现问题导致业务中断/数据出问题,国产数据库负责兜底背锅吗?目前看都把责任推给服务器,OS或者盘的厂商了,三不管地带,最后还是客户运维部门买单。
本质来说,企业存储是高度整合集成了多盘RAID能力、多盘池化、磨损均衡算法、反磨损均衡算法、克隆快照复制特性、高速缓存及高可靠加固特性比如RAS,对研发、测试、制造都有非常高的质量要求,对各部件来料检测远比服务器高,制造环节烤机测试也要一周的时间确保发货到现场少出问题,品控要求更高。盘的任何故障比如坏盘、慢盘、超时盘能控制下去并快速隔离检测,故障是收敛而不是扩散到更大范围,通过存储RAID系统自动恢复,不会故障扩散到导致数据库节点切换的问题。数据存储系统踢盘是很严格谨慎的,因为盘上有数据,换盘要重建数据的。
记得十几年前在研发期间,那个时候也犯过简单幼稚的错误,存储系统盘一坏了就踢掉,结果客户现场就一点点问题就踢,给客户业务带来很多麻烦,比如出现多盘失效等。后来专门成立了盘的研究部门,研究盘的各种故障模式,包含SSD盘的故障模式,软件进行可靠性加固,避免频繁踢盘,还有慢盘,超时盘怎么快速隔离等措施,避免hang死。而现在分布式数据库何止简单粗暴的踢盘,它是把这台服务器都踢掉。打一个比喻,就类似人生病了,脚长了一个疮,一个小病而已,医生说,不行,要把整条腿给锯掉!
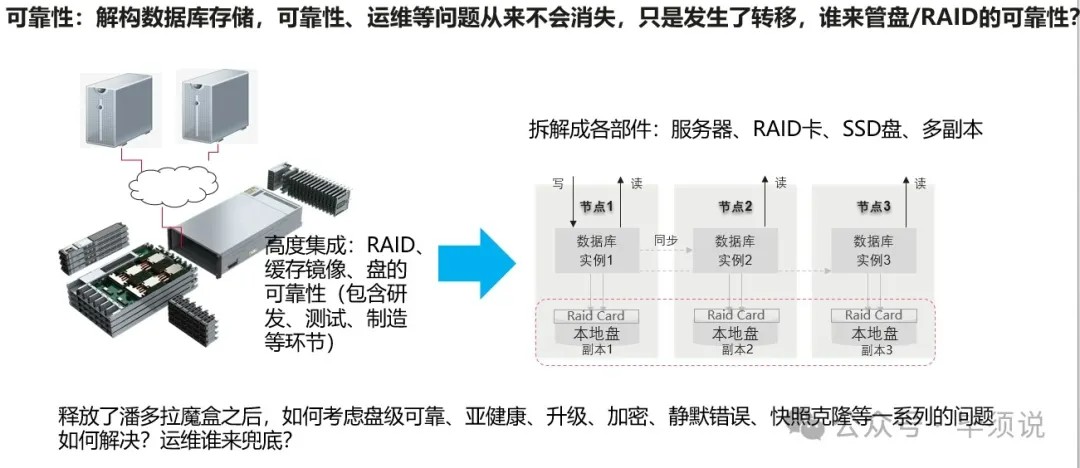
而现在,所谓的软件定义硬件架构,数据库厂商通过推荐打开了这个潘多拉魔盒,重要数据库架在分散的孤岛似的各服务器本地盘、多副本,甚至推荐直通模式,连盘RAID都不做了,高可靠的问题一样存在,并没有消失,只是发生了转移,转移到服务器厂家、盘厂家、OS厂家或者RAID卡厂商而已,但是谁来为这些问题兜底负责呢?
就像开篇讲的,每周就可能坏盘、慢盘、超时盘、SSD FW BUG挂死、或者内存坏,那就切节点,进行繁杂的恢复操作。曾经一客户反馈一块盘导致整个数据库集群拉崩,也有一块盘静默错误bit反转导致数据库文件系统损坏,数据库直接崩了,还有SSD盘不到两年就磨损写穿了,需要批量更换迁移数据库等等各种问题。就类似人每月或者每周都生病,都去医院看病,但是没有根治的“药”,谁受得了?这些问题都转移给了客户数据中心运维部门。所以单部件,系统级的可靠性都是很重要的,不生病才是真正的健康、可靠。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1作者其他文章
评论 0 · 赞 2
评论 1 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 1
评论 1 · 赞 1
添加新评论0 条评论