分布式存储系统概述(二)
(接上篇)
四、 IO 性能
对于存储系统,经常用 IOPS ( I/O per second )、带宽( Throughput )、时延( Latency )这三个参数作为性能衡量指标。 IOPS 指的是系统在单位时间( 1 秒)内能处理的最大的 I/O 数量。把 IOPS 的值乘以 IO 尺寸,就得到了带宽指标。所以说, IOPS 和带宽不是两个独立的指标。那为什么人们为什么要采用两个指标来做度量呢?实际上,这和存储系统本身的特性相关:对于不同尺寸和访问模式(随机 / 顺序)的数据,存储系统性能会表现出很大差异!具体来说,在相同的设备上,对于小尺寸 IO (如 4KB 、 8KB )的随机读写和大尺寸 IO (如 1MB 以上)的读写,从存储系统所能获得的带宽可能有数量级的差异 ! 所以,我们提到存储存储系统的 IOPS ,一般是指在小尺寸 IO (即小 IO )下每秒内可获得的 IO 次数;而带宽指大尺寸 IO (即大 IO )下(这里不再区分随机 / 顺序不同模式的原因是大 IO 性能对不同模式不敏感)的读写存储系统所获得的吞吐量。再进一步追问,为什么不同尺寸 IO 在性能上会有如此大的差异呢?这是存储介质( HDD 、 SSD )的特性所决定的。以目前在存储系统中最广泛使用的磁盘( HDD )为例,一般 SATA 接口的硬盘,在 4KB 的 IO 尺寸下, IOPS 值大概是 100 ,照此计算,此时的带宽是 0.4MB; 在 1MB 的 IO 尺寸下,其带宽却可以达到 100MB 。由此可见,不同的 IO 模式,磁盘的带宽值可以相差数百倍!至于磁盘的性能表现为何如此,这是由其物理特性和读写方式决定的,此处不再详述。
实际上,正式因为磁盘在不同 IO 尺寸和访问模式下性能的巨大差异,才导致了需要对以磁盘为主要存储介质的存储系统进行性能优化的可能。如果磁盘在任意 IO 下的性能是相同的,性能优化的意义就大打折扣。
对存储系统的写性能优化和读性能优化,其原理并不相同。
实际上,在存储系统的发展过程中,对性能优化的一个关键技术就是如何能充分发挥存储介质的性能。在存储系统中,和 IO 处理直接相关的部件基本指标如下图所示:
从上图可以看出,从 CPU 到 CPU Cache ,再到 DRAM 内存、 PCM ( Phase-Change Memory ,非易失性内存的一种)、 SSD 、 HDD ,访问时延和容量都迅速变大。所以,对于性能优化,一方面要充分利用高速缓存介质,另一方面要充分 HDD 和 SSD 的性能,因为数据最终要存储在这些介质上。
如前所述,对于 HDD 来说,其大块数据的顺序读写性能远高于随机读写性能。对于 SSD 来说,作为半导体存储,不存在 HDD 通过机械臂寻道导致的时延问题,但由于其自身的 GC 机制(垃圾回收),顺序访问的性能同样高于随机访问,当然,其访问性能差异远没有 HDD 大。应用访问存储的 IO 读写模式并不固定,既有以随机小 IO 居多的应用(如数据库) , 也有以 IO 居多的应用(如视频、 HPC 等),当然,更多的是大小 IO 混杂应用。
既然大 IO 可以充分发挥硬盘( HDD 或 SSD )性能,那么,性能优化的一个方向就是把小 IO 变成大 IO ,把随机 IO 变成顺序 IO 。下面分别从 IO 存取两方面分别说明。
首先看一下基本的数据写入流程:

在应用将数据写入到存储系统的内存后,系统会在把数据的副本(通常以日志形式)写入非易失性高速介质(如 NVDIMM 、 PCM 、 NVMe SSD 等)后,就会向应用返回写入成功信息;然后,内存中的数据以异步的形式写入真正的存储介质,即硬盘中。这样做一方面可以在节点数据可靠性(因为写入了非易失性介质中,即使突然断电,系统重启后数据可恢复)的前提下做到低时延,另一方面可以对内存中的写入数据(小 IO )进行一定的处理,使得这些数据写入硬盘是获得更好的性能。从而在整体上写入性能上获得低时延,更高的带宽。
把写入的随机小 IO 变成大 IO (或顺序 IO )的方法之一就是利用写缓存技术。其原理如下:
我们以磁盘为例进行说明。大体上有两类方法进行写性能优化。
其一是 IO 调度法。在多个随机小 IO 写入缓存(高速介质,如内存)后,由算法根据 IO 调度:调度的结果是部分小 IO (逻辑位置相邻)被合并成较大 IO ;部分小 IO 被重排,重排后的 IO 可以使磁盘的磁头以相对较好的顺序性访问磁盘,从而提升写入性能。
其二是数据重映射法。这种方法的核心思想是小 IO 不再进行“ in-place ”的写入,而是通过引入一个重映射层(或称索引层),把随机写入的 IO 以追加写( append )的方式变成变成对磁盘的顺序写入。这样就可以充分利用磁盘顺序写入的高带宽特性,付出的代价是首先,要建立原有随机小 IO 和新的顺序 IO 之间的映射表(索引);其次,要有垃圾回收机制,因为数据不是以“ in-place ”的方法写入的,旧有的数据必须在系统后台定期进行清理,释放出空间。再次,新的映射层会导致对上层应用来说逻辑连续的数据在磁盘上可能不再连续,从而对数据的连续读性能造成影响。
实际上,以上两种对写性能的优化思路在系统层面和部件层面都广泛存储。除了广为人知的存储系统软件、操作系统等层面使用写缓存技术,在部件层面,比如 RAID 卡、 HDD 、 SSD 等,也都存在用于写优化的缓存层。
对于读性能的优化,主要的方法是根据应用 IO 读请求的特点对数据进行预取,预取数据放在高速缓存( Cache )中,这样,在下一个读请求命中 Cache 时,可以快速返回数据。我们知道,在存储系统中,读 Cache 的容量比介质容量要小若干个数量级。所以,此种方法的核心的如何对读请求作出正确的预测,使得后续读请求数据可命中 Cache 。实际上,多相当多的应用来说,读取数据时具备一定的空间局部性( temporal locality ),也就是说,假设应用目前在读取第 K 块数据,那么接下来有很大的几率读取第 K 块附件的数据,所以我们可以将第 K 块附件的数据(对于 HDD 来说,这些数据数据很可能也是物理连续的,可以充分发挥磁盘顺序读取的性能优势)预读到 Cache 中。当然,如果对于真正完全随机的数据,预读的方法是没有用处的,反而会造成一定的系统负担。真实世界中,完全随机的读取时很少的。目前人们在探索利用 AI 的算法对读请求进行模式识别,这会比简单地根据空间局部性预测命中率更高,一些公司在这方面已经取得了很好的结果。同写缓存类似,读缓存也分为多个层次。
分布式存储中,一般存在一个由各存储节点的高速介质(易失或非易失性内存)组成的分布式全局缓存。全局缓存一般采用读写缓存分离设计。这样做的好处是一方面避免读写缓存相互影响(写缓存刷盘、读缓存淘汰数据),一方面可以对读写缓存独立实施实现灵活的策略(缓存空间占用大小、副本数、后端存取介质等)。除此之外,为实现对后端存储介质友好(大块连续数据)的数据写入,还会在全局缓存层实现随机小 IO 到大块顺序 IO 的 IO 聚合功能。如前文所述,此时需要记录随机小对象到聚合对象的映射关系,这个映射一般采用 KV 数据库实现(一般基于 LSM 或 B+ 树实现,典型如 RockDB )。在存储海量数据时, KV 数据库的读写效率会称为影响性能的关键因素。
利用缓存(单层或多层)固然可以提升读写性能,但需注意由此引入的读写数据一致性的问题。比如,在多层级的读写缓存中,由于在写入过程中数据是自上而下(也是由高速到低速)逐层写入的,在读取数据时,为保证数据一致性,必须保证同一层级先写后读(先从写缓存寻找数据再从读缓存寻找数据),不同层级自上而下的原则。
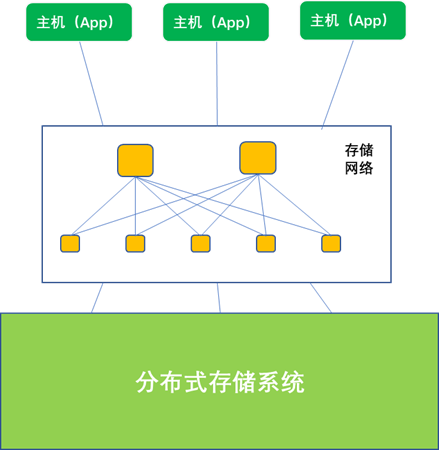
对于由 N 个节点组成的分布式存储系统,主机应用可能通过网络,连接 N 个节点中的部分或全部节点,并行读写存储系统。所以,从理论上说,存储系统作为一个整体的性能不超过各个节点性能之和。要使系统到达高性能,从数据布局( data layout )的角度说,一方面要将数据充分打散存储,另一方面就是要将保证数据在存储介质上基本均衡。数据打散就是存储系统把来自主机应用的大块数据切割成小块,分散放置到不同节点的不同硬盘上,这就相当于以并行的方式访问硬盘,性能自然高。数据均衡则从概率的角度使得每块硬盘具有近似的访问几率,这样就从整体上可以发挥所有硬盘的能力,从而达到性能最佳值。
数据布局就是要把打散的定长数据块映射到系统中的某个硬盘上。映射的方法基本可以分成两类。一类是显示映射法,就是系统对于每个分块数据,根据硬盘的状态(容量、使用率等)显示地指定,并把这个映射关系记录下来形成映射表。之后,读写这块数据都要查询这个映射表。另一类方法是采用广义的 HASH 计算法,就是根据分块数据的特性(命名空间、 LUN 或文件名、地址偏移信息等)利用 HASH 函数以伪随机的方法映射到某个硬盘。这个映射关系不需要显示记录,因为 HASH 函数的计算极快,下次访问此数据块只要再计算一下就可以找到对应的硬盘。在分布式存储中常用的 DHT 、 CRUSH 等方法均属此类。
显示映射法和广义 HASH 法各有千秋。显示映射法可以设置灵活的数据布局策略,在数据均衡、迁移、数据耐久性变更等方面易于实现,但因为要显示的记录映射关系,不易处理海量数据。广义 HASH 法因不需要存储映射表,存储的数据量理论上可以无穷大,但其在数据均衡性、数据布局策略灵活变更等方面不及显示映射法。实际的分布式存储系统往往两种方法结合使用。
十多年前,存储系统的存储介质主要是 HDD 磁盘。因为 CPU 、内存和 HDD 性能的巨大差异,单颗 CPU 下可以挂数十块甚至上百块磁盘。随着 SSD 技术的长足进步(性能、容量不断增长,价格则不断下降), SSD 在存储系统中被广泛采用,全闪存储设备高速增长。 SSD 和 CPU 都是基于半导体技术,性能差异已经显著缩小。目前商用的单块 NVMe SSD ( PCIe 4.0 )的带宽性能可达 6~8GB/s , IOPS 达数十万。这个性能是 HDD 的千百倍。对于存储系统来说,除了基本的读写之外,还需要提供 EC/RAID 计算、快照 / 克隆、数据重删、压缩、加密等增值功能,这些功能叠加在一起,对 CPU 的性能的要求急剧提升。这对以通用计算为目的设计的 CPU 来说就显得有些心有余而力不足。此时,就需要一些专用处理器做协议卸载,这些专用硬件如智能网卡、计算存储设备( Computational Storage Device )、 DPU ( Data Processing Unit )等。 DPU 专为数据处理而设计,存储系统可以利用 CPU+DPU 的组合方案,把存储 IO 处理、纠删码计算、数据重删、数据压缩、加密等功能卸载到 DPU 上, CPU 只集中于系统控制面的功能。一些更加激进的公司甚至在存储系统中用 DPU 完全取代了 CPU 。从整个存储行业来看, DPU 的应用还处于起步阶段,后续随着 DPU 本身的不断发展,它会在存储系统中发挥越来越重要的作用。
存储系统的性能发挥不仅依赖于其本身,还与存储访问协议和网络相关。
常用的存储网络包括 FC 、 EHT/IP 、 IB 等。其中 FC 网络专为存储设计,在网络稳定性、可用性、时延等方面具有优势,但其速率不如 ETH 和 IB ,成本也高; IB 网络主要应用在超算领域,可为应用提供超高带宽,但其成本高,供应商少; ETH/IP 是数据中心最为广泛采用的网络技术,带宽高,成本低,但其在拥塞避免、拥塞控制、时延、易用性等方便不如 FC 。近几年, EHT 借鉴 IB 网络的 RDMA 方法,将 RDMA 承载在无损以太网上,发展了 RoCE ( RDMA over Converged Ethernet )方法。为了更好地和存储结合,一些厂商还在 RoCE 的基础上进行了增强,使其可用性(快速故障倒换)、易用性和丢包率等指标接近 FC 。
在访问协议上,传统存储主要以 SCSI 协议访问磁盘。 SCSI 协议不能发挥 SSD 介质的高性能, NVMe 协议以及 NVMe-oF 协议应运而生。 NVMe 协议面向 SSD 介质设备,在并发能力(队列数量、队列深度)和传输能力上均好于 SCSI 。 NVMe-oF 协议兼容性好,可以使 NVMe 运行在多种网络上。

在实际部署中,将 NVMe 承载在 FC 上、 RoCE 上、以及 TCP 上是目前常用的方法。
(未完待续)
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1作者其他文章
评论 1 · 赞 2
评论 2 · 赞 4
评论 1 · 赞 3
评论 1 · 赞 1
评论 0 · 赞 1
添加新评论1 条评论
2023-06-09 16:09