
浅析分布式数据库的技术框架及其在金融行业中的应用规划
摘 要:
随着互联网金融业务的快速发展,银行需要处理的数据呈爆炸式增长,传统的关系型数据库已无法满足新的业务需求,于是,近年各银行纷纷开始了分布式数据库的研究与试点。本文拟对分布式数据库的技术实现原理进行分析,试图梳理出分布式数据库的技术框架和功能模块,以及各功能模块采用的关键技术和技术特点,以帮助从业人员,在进行分布式数据库选型时,能更清晰地了解各类数据库产品的特点,并能够根据业务场景,选择合适的数据库。
关键词:关系型数据库,分布式数据库,NoSQL、NewSQL、OLTP、OLAP
一、前言
早期银行业务系统处理的主要是交易型数据,数据量较少,传统关系型数据库(如SQL Server、Oracel、DB2等)已足够应对。随着互联网金融业务的快速发展,业务系统需要处理的数据呈爆炸式增长,传统数据库因其扩展能力有限,已无法满足业务系统越来越高的数据处理能力要求。于是,新型的分布式数据库系统应运而生。
本文拟先对数据库进行分类,了解各类数据库的特点,参考人行的分布式数据库技术架构规范,并结合业界主流分布式数据库的技术实现,试图梳理出通用技术框架,并根据各功能模块的主要技术特点,结合业务场景,提出分布式数据库系统在金融领域的应用规划,供大家参考。
二、数据库的分类
为了更高效地了解不同厂商分布式数据库的产品特点,我们需要对数据库产品进行分类。业界对数据库的分类尚未形成统一的标准,但都大同小异,本文数据库分类参考了451 Group分析报告中的《数据库行业全景图》。
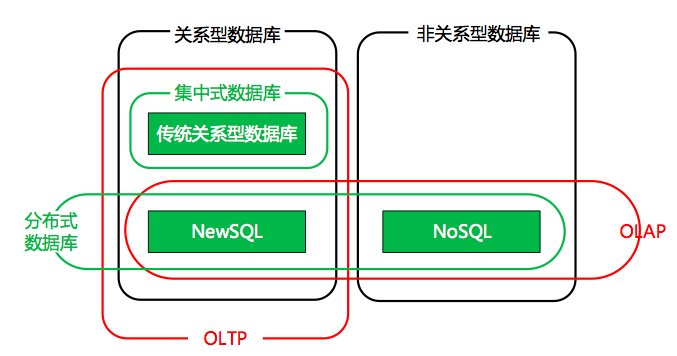
数据库根据其数据模型,可分为关系型数据库(RDBMS)和非关系型数据库(NoSQL)。其中,关系型数据库根据其技术特性,分为传统关系型数据库和NewSQL数据库;根据业务负载特征,可分为OLTP数据库和OLAP数据库。
根据部署架构,可分为集中式数据库和分布式数据库。其中NoSQL数据库与NewSQL数据库均为分布式数据库。
各类数据库的特性描述如下:
1、关系型数据库与非关系型数据库
关系型数据库(RDBMS)即SQL数据库,支持SQL操作,具备ACID属性,用于处理存储结构化数据,包括传统关系型数据库与NewSQL数据库。
非关系型数据库,通常为NoSQL数据库。NoSQL(Not Only SQL)即“不仅仅是SQL”,提倡运用非关系型的、分布式的数据存储系统,通常以牺牲复杂SQL、ACID 事务支持和数据的一致性为代价,以此换取弹性扩展能力。常用的NoSQL数据库有基于键值(Key-Value)的,如 levelDB、Rocks DB、redis等;基于列存储的,如:Bigtable、HBASE等;基于文档的,如:MangoDB;其他如基于图的Neo4j,基于时间序列数据的InfluxDB等。
2、传统关系型数据库与NewSQL数据库
传统关系型数据库与NewSQL数据库均属于关系型数据库。早期使用的关系型数据库是传统关系型数据库,扩展能力有限,如商业软件Oracle、DB2,开源软件MySQL、PostgreSQL等。
NewSQL数据库为应对爆炸式增长的数据需求而生。采用分布式技术,支持SQL操作,满足ACID属性,同时具备良好的扩展能力,如Cockroach DB、Google Spanner/F1、TiDB、OceanBase等。
3、OLTP数据库与OLAP数据库
OLTP(On-line Transaction Processing 联机事务处理)数据库,适用于事务管理型系统,该类系统处理的是高并发且数据量级不大的交易,如INSERT, UPDATE, DELETE等。OLTP是传统关系型数据库的主要应用。
OLAP(On-line Analytical Processing联机分析处理)数据库,适用于查询频率较低,但通常会涉及到非常复杂的聚合计算的系统。该类系统需要进行复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。如数据仓库,风险预警等。
4、集中式数据库与分布式数据库
集中式数据库将数据在物理空间上集中存储和处理,是一种较为经典、传统的架构模式;
分布式数据库是物理上分散而逻辑上集中的数据库系统,利用分布式事务处理、数据自动分片、数据多副本存储等技术,将分散在计算机网络的多个逻辑相关节点连接起来,共同对外提供服务。
NewSQL数据库与NoSQL数据库采用分布式部署,均为分布式数据库。
5、数据库分类示意图:
三、分布式数据库的技术框架
就分布式数据库的技术框架而言,可分为计算模块、存储模块和管理模块。各模块的技术框架介绍如下:
(一)计算模块
计算模块包括接口层、解析层和计算层。
1、接口层
接口层负责接口调用,是分布式数据库对外提供服务的统一接口,可提供包括SQL接口、JDBC/ODBC以及其他驱动等方式的接入。
2、解析层
解析层包括解析器、优化器,负责解析数据库收到的指令,(包括SQL语句和其他指令),同时对解析结果进行优化,生成执行计划,并将指令与计划自动分配到各计算节点并行执行。
在解析层中,我们需要关注产品对SQL的兼容性,以及对存储过程的支持情况
3、计算层
计算层负责资源管理,确定计算框架,采用合适的通讯协议,通过分布式事务处理等技术确保数据正确性,借助并发控制、动态资源分配等技术提升分布式数据库在复杂业务场景的计算效率,同时保证整体系统的可靠性。各模块功能如下:
- 资源管理
主要负责计算资源的管理,包括CPU、内存的调度,磁盘I/O管理、动态资源分配等。
合理的资源管理设计,能最大程度发挥计算资源的效率,提升分布式数据库在复杂业务场景的计算效率。
- 计算框架
分布式数据库通常采用MPP计算框架,实现并行计算的能力。
MPP(Massively Parallel Processing),大规模并行处理。MPP先对数据进行分块, 交给不同节点储存。查询时,各数据块利用所在节点的计算资源分别处理, 然后汇总到leader node进行合并。
MPP 有shared everything /Disk / Nothing三种类型。
- 负载管理
包括资源管控、租户隔离、租户的SLA、并发控制等等,合理的负载管理,能有效隔不同数据库租户之间的相互影响,确保租户获得需要的SLA。
- 通讯管理
分布式数据库网络中,传输层通常可采用TCP/UDP协议,链路层可采用Ethernet/RDMA协议。
RDMA(Remote Direct Memory Access 远程直接内存访问),是为解决网络传输中服务器端数据处理的延迟而产生的。其特点是:数据可通过网络与远程服务器间直接进行数据传输,不需要内核参与,从而减少了数据的额外移动和复制,有效提高了数据库性能。
RDMA有三种实现方式:Infiniband、RoCE、iWARP。
- 分布式事务管理
分布式数据库同常采用二阶段提交(2PC)来保证分布式事务的ACID属性。
为了实现并发访问控制,分布式数据库需支持分布式事务的隔离性,以解决并发事务执行过程中存在的脏读、不可重复读、幻读等问题。支持的隔离级别包括:已提交读、可重复读、串行化;
分布式数据库需具备锁的管控能力,包括锁的类型、锁的级别、锁的互斥、死锁处理等。
在实际技术实现时,计算层和存储层都需要实现分布式事务处理。
- 可靠性管理
可靠性管理包括服务的高可用和数据的高可用。
服务高可用主要从部署架构方面考虑,如采用的是集群、还是主备部署,并从机房、机柜、供电、布线层面,保证基础设施的高可用。
数据的高可用主要针对数据副本的管理,包括副本数据的复制技术(如流复制、块复制和WAL重构)和数据的一致性管理(强一致性和最终一致性)。
数据的三种复制技术采用的实现方式不同:
流复制。包括操作日志与SQL语句,通过重放操作,实现数据副本的复制。块复制。通过数据块的复制,实现数据副本的复制。
常用的数据一致性技术有Paxos、Raft。
WAL重构,定期进行快照复制,并实时复制快照之后的操作日志,当需要数据恢复时,可用过快照+日志的方式,将数据恢复到最新状态。WAL重构常用于数据的灾备。
在实际技术实现时,计算层和存储层都需要可靠性管理。其中,服务高可用在计算层和存储层上都要关注,而数据的高可用主要在存储层上实现。
(二)存储模块
存储层属于存储模块,包括数据存储组织管理和日志组织管理。数据存储组织管理包括数据分片/分区策略、数据更新机制、数据存储结构、索引管理、数据物理结构等;日志组织管理包括日志类型和日志的归档方式等。无论是数据还是日志,最终存储在物理介质上,存储介质可以是本地磁盘或外部存储。各模块功能如下:
1、数据存储组织管理
- 数据分片/分区管理
数据的切分有两个维度:水平分片和垂直分区。
水平分片,按照一定的规则,将数据集划分成相互独立、正交的数据子集后,再将数据子集分布到不同的分片节点上。常见的数据分片策略有Hash、Roundrobin两种方式
垂直分区,分片后的数据,按照一定的规则进行切分,再根据分区策略,将数据分布在分片集群内的各存储单元上。常见的分区策略有一致性Hash/一致性Hash、range和list三种方式。
- 数据更新机制
数据在磁盘的组织和更新方式有两种方式:In-place、Append-only
In-place,数据更新时,直接对内存缓冲区中的数据进行修改,然后刷新到磁盘上,完成数据的更新操作。Append-only,数据更新时,将新的数据直接追加到内存文件上,(而不对原来的数据进行修改),并定期保存在磁盘上。
- 数据存储结构
存储上,数据可以以“行存”、“列存”、“KV”、“文档”、“图”和“序列”等方式组织存储,不同的数据存储组织适用于不同的业务类型。
逻辑上,数据可以以“库/表/记录”的方式组织,如Oracle、DB2等传统关系型数据库;也可以以“库/集合/文档”的方式组织,如MangoDB;或以“文件”的方式组织,如RocksDB等。
常用的存储算法有B+树,LSM和Hash。
数据最终组织成页或LOB块的方式,存储到文件系统中。
- 索引管理
索引的类型有文本、位图、倒排等,各种索引的特点如下:
倒排索引,也叫反向索引(inverted index)。是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。单词词典常用的数据结构包括哈希加链表结构和树形结构
文本索引支持对字符串内容的全文检索查询。文本索引可以包含字符串或字符串元素数组。一个集合有且只能有一个文本索引,但是该索引可以包含多个字段。
位图索引是一种使用位图的特殊数据库索引。主要针对大量相同值的列而创建,索引块的一个索引行中存储键值和起止Rowid,以及这些键值的位置编码,位置编码中的每一位表示键值对应的数据行的有无。
2、日志组织管理
- 日志类型
常用的日志类型有redo、undo等。
redo log,重做日志,也是预写日志,记录了数据的创建和修改,提供前滚操作,防止故障时的数据丢失,用来保证事务安全。
undo log,回滚日志,记录的是如何还原修改,提供回滚操作,同时提供MVCC,undo log也会产生redo log,
- 日志归档方式
日志可以有归档和未归档两种方式。
未归档模式,不保留重做历史的日志操作模式,只能够用于保护例程失败,而不能够保护介质损坏;
归档模式,指保留重做日志历史的日志操作模式。这种日志操作模式不仅可用于保护例程失败,还可以用于保护介质损坏的情况。
3、存储介质
存储介质可以是本地磁盘,也可以是外部集中式存储或分布式存储。如采用本地磁盘,需利用复制技术,如raft或Paxos协议,实现多副本保存,以保证数据的可用性。如采用外部存储,则数据的可用性由外部存储保证。
(三)管理模块
管理模块负责分布式数据库的运维和管理,提供数据库参数配置和运行监控接口,通用要求包括自动化部署、扩缩容、可视化、多租户等;维护要求方面包括自动告警、版本升级、状态监控、性能监控、系统日志、系统配置、故障的隔离、自愈等,数据管理部分包括导入导出、数据同步、数据迁移、备份恢复等;容灾管理方面包括双活/多活、读写分离、主备三种模式。
分布式数据库的技术框架如下图所示:
四、各类分布式数据库的典型架构
NoSQL数据库和NewSQL数据库均为分布式数据库,其中,NewSQL数据库有两大类:分库分表的数据库访问中间件和原生分布式数据库。
(一)NoSQL数据库
NoSQL数据库通常有三大组件:协调节点、数据节点和配置节点,各组件的功能如下:
- 协调节点。在集群中可作为网关使用,提供客户端应用程序和数据节点集群之间的外部API接口,或简单的SQL支持,负责语法解析、优化,形成执行计划,下压给数据节点执行,负责数据分片和聚合,记录元数据到配置节点,或从配置节点读取元数据。
- 配置节点。用于保存集群的配置信息和数据分片的元数据信息等。
- 数据节点。负责分片数据的实际存储和管理。数据可保存在本地磁盘或分布式存储,采用多副本方式保证数据的可靠性;如采用本地存储,副本间的数据一致性采用Paxos或raft,如采用分布式存储,由分布式存储保证副本间的数据一致
协调节点实现接口层、解析层、计算层的相关能力,数据节点实现存储层的相关能力(具体能力和关键技术见上一章节)。
(二)NewSQL数据库
业界常用的NewSQL数据库有两种技术路线:分库分表的数据库访问中间件方式和原生分布式数据库方式。
1、分库分表的数据库访问中间件模式
分库分表的数据库访问中间件方式由中间件和传统关系型数据库共同组成。传统关系型数据库天然具备良好的ACID属性,通过数据库访问中间件进行分库分表,满足数据库的扩展性要求。应用系统在访问数据库时,首先访问数据库中间件,由中间件根据规则,将数据分散到多个库/表中进行存储,查询时,再将多个库/表的数据聚合在一起,返回给应用。目前,数据库访问中间件大都以兼容MySQL为主。其典型架构如下:
在上述架构中,数据库访问中间件实现接口层、解析层、计算层的相关能力,传统关系型数据库(如MySQL)实现存储层的相关能力。
数据保存在存储层中,数据的可用性和可靠性由分片数据库集群保证(每个分片数据库集群可以是一个数据库高可用集群,如MySQL的MGR、Oracle的RAC等)
数据库访问中间件本身不保存数据,只做数据的分片、路由;
2、原生分布式数据库模式
原生分布式数据库对数据库系统进行重构,原生支持分布式事务处理与数据切分,主要由SQL层和存储引擎层两部分组成。其中,SQL层为客户端提供接口服务,并负责SQL语句的解析、优化,生成执行计划,下发到数据库存储引擎层执行,SQL层不保存数据。
数据库存储引擎层负责数据的分片和聚合,记录元数据,并将数据保存到本地磁盘或外部存储,数据保存采用多副本方式。如采用本地存储,副本间的数据一致性采用Paxos或raft,如采用分布式存储,由分布式存储保证副本间的数据一致。典型架构图如下所示: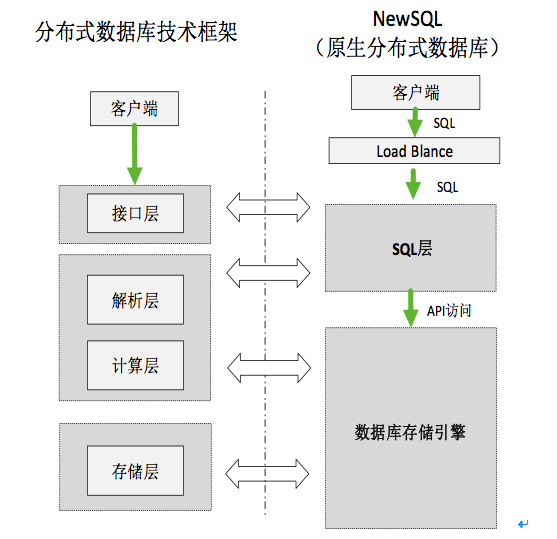
各厂商在对数据库系统进行重构时,侧重点有所不同:有的侧重SQL层的重构,而存储引擎采用开源的数据库存储引擎,如TiDB;有的产商则侧重存储引擎层的重构,而SQL层采用开源数据库,如SequoiaDB。
3、两种技术路线NewSQL数据库比较
五、分布式数据库的应用规划
1、数据的分类
数据按其组织结构,可分为结构化数据、半结构化数据和非结构化数据。各类数据的特点如下:
结构化数据,也称行数据,是由二维表结构来逻辑表达和实现的数据,严格遵循数据格式与长度规范,数据处理时效性要求较高,通常采用OLTP数据库存储和管理。如所要处理的数据量小,数据增长速度慢,可选用传统关系型数据库(RDBMS)处理,如所需处理的数据量大,数据增长速度快,可选用NewSQL数据库处理;
非结构化数据,不宜采用关系型数据库来处理的数据,如各类图片、音频、视频等。创建和管理数据项时,通常采用多值字段和变长字段,广泛应用于全文检索和各种多媒体信息处理领域。该类数据量大、数据增长速度快,但对时效性要求相对较低。通常选用OLAP数据库或hadoop等大数据平台存储和管理。
半结构化数据,不同于结构化数据和非结构化数据,它形式上是结构化的数据,但结构变化很大,如各种格式的办公文档、XML、HTML、Json等。当我们要了解数据的细节时,就不能将数据简单的组织成一个文件,而是要做结构化处理。但因为结构变化很大,又不能简单地创建一个表和他对应。半结构化数据通常采用OLAP数据库存储和管理。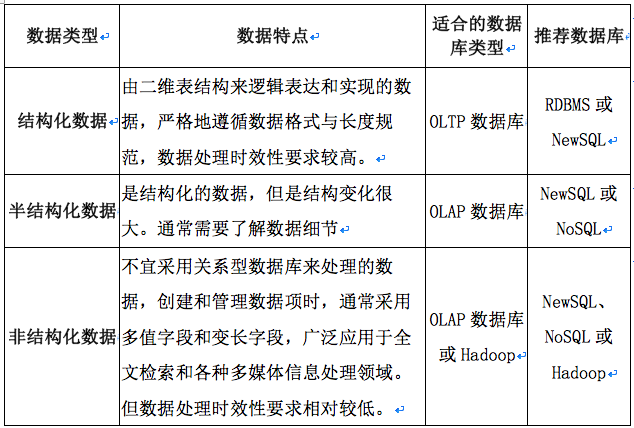
2、应用系统的分类与特点
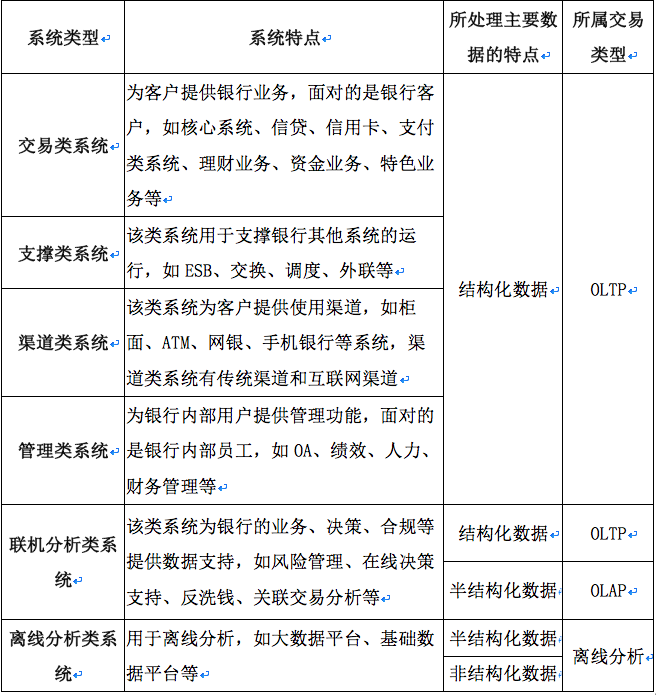
应用系统按其所处理的业务特点,可分为交易类系统、支撑类系统、渠道类系统、管理类系统和分析类系统,其中分析类系统可分为联机分析类系统和离线分析类系统,各类系统特点如下:
- 交易类系统:为客户提供银行业务,面对的是银行客户,是银行的主要业务系统。如核心系统、信贷、信用卡、支付类系统、理财业务、资金业务、特色业务等;
- 支撑类系统:该类系统用于支撑银行其他系统的运行,如ESB、交换、调度、外联等;
- 渠道类系统:该类系统为客户提供使用渠道,如柜面、ATM、网银、手机银行等系统,渠道类系统有传统渠道和互联网渠道;
- 管理类系统:为银行内部用户提供管理功能,面对的是银行内部员工,如OA、绩效、人力、财务管理等。
上述系统所处理的主要是结构化数据。
- 联机分析类系统:该类系统为银行的业务、决策、合规等提供数据支持,如风险管理、在线决策支持、反洗钱、关联交易分析等。该类系统处理的数据有结构化数据和半结构化数据。其中结构化数据主要为元数据,半结构化提供业务分析
- 离线分析类系统:主要用于离线分析,如大数据平台、基础数据平台等。所处理的多为半结构化数据和非结构化数据
3、应用系统的数据库规划

六、关于分布式数据库的选型思考
在进行分布式数据库选型时,我们既要考虑到传统技术的兼容性和新技术的前瞻性。
在传统技术的兼容性方面,既要满足传统关系型数据库的ACID要求,还要考虑对SQL的完整支持,尽量对应用无感知。
在新技术前瞻性方面,要考虑到数据库的扩展能力,能根据业务需求,支持系统的平滑升级与扩容;根据业务场景,选择合适数据库,在此基础下,进行适当创新:要求所选择的数据库能支持复杂的业务场景,尽量做到同个数据库平台既支持OLTP应用,又支持OLAP应用,打破数据的孤岛效应;支持多模和多租户模式,让同个数据库平台能支持多种应用场景,同时简化数据库的运维;
适配性方面,能支持多种操作系统和多种编程语言,并适配多种硬件平台(如 X86、ARM、MIPS 等架构);此外,还有考虑到多租户隔离的有效性,并为不同用户提供不同的SLA服务。
七、结束语
分布式数据库是近几年发展的新技术,率先应用在互联网行业,因此成熟案例较多,但在金融行业的应用尚处起步阶段,成熟案例相对较少。如何根据金融行业的业务特点,结合分布式数据库技术,选择合适的分布式数据库产品,是目前产商和银行IT人员共同需要考虑的问题,本文抛砖引玉,希望对大家有所帮助。
参考文献:
[1] 人民银行.《分布式数据库技术金融应用规范技术架构》
[2] 杨冬青 李红燕 唐世渭等译.数据库系统概念.机械工业出版社
[3] 周立柱 范 举 吴 昊等译.分布式数据库系统原理.清华大学出版社
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3作者其他文章
评论 3 · 赞 15
评论 2 · 赞 21
评论 3 · 赞 11
评论 3 · 赞 13
评论 1 · 赞 9
添加新评论0 条评论