
常用分布式数据库的分析与比较 ——NoSQL数据库篇
摘 要:
非关系型数据库,也叫NoSQL数据库,通常采用非关系型、分布式的数据存储系统,支持高性能、高并发,并有良好的扩展性,但大都以牺牲一致性为代价。NoSQL数据库用于存储非结构化数据,适用于联机分析(OLAP)的应用场景。此外,NoSQL数据库不支持SQL语言,尤其不支持连接(JOIN)操作。
根据数据模型,NoSQL数据库一般有以下几种类型:基于键值对的,如:levelDB、Berkeley DB、Rocks DB、redis、Dynamo等;基于列存储的,如:Bigtable、HBASE等,基于文档的,如:MangoDB,其他如基于图的Neo4j,基于时间序列数据的InfluxDB等。
本文拟介绍几种典型NoSQL数据库的实现原理,以帮助读者对各类NoSQL数据库有一个初步的了解,并在实际工作中,能够根据应用场景,选择合适的数据库。
关键词:
NoSQL、存储引擎、分布式存储、LevelDB、BerkeleyDB、RocksDB、redis、Dynamo、Bigtable、Hbase、MongoDB
在实际使用中,基于应用场景,NoSQL数据库可分为两大类:一类只支持单机部署方式,通常作为其他大型分布式NoSQL数据库的存储引擎,如LevelDB、BerkeleyDB、RocksDB。另一类采用集群部署方式,支持分布式存储,如Dynamo、redis、Hbase、MongoDB等,常用于实际应用场景。
一、 常被用于存储引擎的NoSQL数据库
(一) Level DB
LevelDB是基于键值对的NoSQL数据库,其本质上维护的是一个大型的单机版哈希表,是谷歌开源的key/value数据库,支持C/C++,数据的存储结构采用LSM树,并以文件的形式存储在磁盘上,通常作为其他大型数据库的存储引擎。
LevelDB 的数据存储分为两个部分:内存中的可变部分和磁盘上的不变部分。磁盘部分又分为多个层级,不同层级的数据会定期从上往下移动。当磁盘底层的冷数据被修改后,它又会再次进入内存,一段时间后又会被持久化回到磁盘文件,并慢慢下移动到底层。
1. Level DB的整体架构
- Memtable:可读写的内存数据结构表,用于新数据的写入;
- Immutable Memtable:只读的内存结构表。达到Memtable设置的容量上限后,Memtable会变为Immutable,同时会有新的Memtable生成。Immutable Mumtable不再接受用户写入,
- Log文件:写Memtable前会先写Log文件,Log通过append的方式顺序写入。Log用于数据库宕机后未写入磁盘的内存数据的恢复;
- SST文件:磁盘数据存储文件。分为Level 0到Level N多层,每一层包含多个SST文件;单层SST文件总量随层次增加成倍增长;
SST文件内数据有序(Level0除外),Level0的SST文件由Immutable直接Dump产生,其他Level的SST文件由其上一层的文件和本层文件归并产生;SST文件在归并过程中顺序写生成,生成后仅可能在之后的归并中被删除,而不会有任何的修改操作。
- Manifest文件: 用于记录SST文件的元数据信息,包括SST文件所属Level,该文件的最大、最小key,以及其他一些LevelDB需要的元信息。
Manifest文件有多个,SST文件每次进行Compaction时,都会生成新的Manifest。
- Current文件:用于记录当前Manifest的文件名。
2、 LevelDB数据读写流程: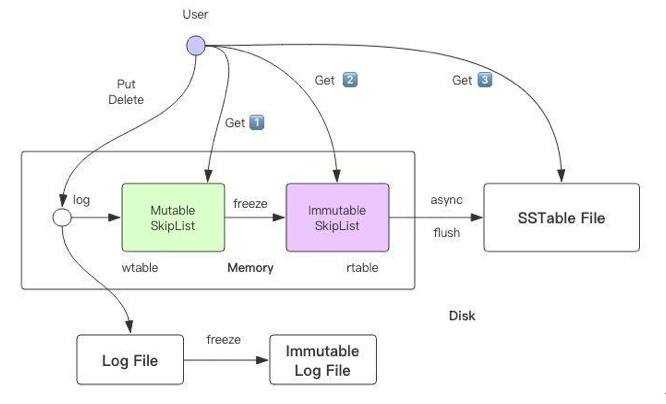
对于写数据,接口会先进行日志写入,待日志写入后,才将数据写入内存表(MemTable)
当内存表达到阈值时,内存表冻结,变为Immutable MemTable,同时生成一个新的 Memtable 继续接受写操作。Immutable MemTable 将会被异步线程写入SST表中。
读数据时,Get 操作会优先查询 MemTable,如果找不到就去 Immutable MemTable 中去找,Immutable MemTable 如果还找不到,再去磁盘文件里去找。
3、磁盘结构
每个文件都会对应一个层级,每个层级都会有多个文件。底层的文件内容来源于上一层,最终它们都会来源于 0 层文件,而 0 层的文件又来源于内存里的 Immutable 序列化。
一个Immutable 会被序列化为一个完整的 0 层文件。
文件的Compaction有两种方式:minor Compaction和Major Compaction。把memtable中的数据导出到0 层 SST文件,称之为“Minor Compaction”;从N层SST文件下沉到N+1层SST文件称之为“Major Compaction”。
(二) Berkeley DB
Berkeley DB是嵌入式数据库,支持C、C++、Java、Perl、Python、PHP、Tcl等,提供一系列可直接访问数据库的函数,可被加载到进程,通过进程内调用访问。BerkeleyDB不是关系/对象型数据库,不提供数据库常见的高级功能(如存储过程,触发器等),不支持网络访问,程序通过进程内的API访问数据库。
BerkeleyDB支持四种数据存储结构及相应算法:哈希表(Hash Table)、B树(BTree)、队列(Queue)、记录号(Recno)。
Berkeley DB是Oracle公司的一个产品,也常被用作其他NoSQL数据库的存储引擎。
(三) Rocks DB
Rocks DB 是Facebook开源的单机版数据库,数据库内容以磁盘文件形式存储。与Level DB类似,RocksDB的存储也是基于LSM的数据结构,但对闪存、固态硬盘、HDFS做了优化。
RocksDB与LevelDB的比较:
- RocksDB的底层存储支持分布式存储HDFS。而LevelDB则只支持本地文件存储;
- RocksDB支持一次获取多个K-V,且支持Key的范围查找。而LevelDB每次只能获取单个Key;
- RocksDB除了支持的Put、Delete外,还支持Merge,可对多个Put进行合并;
- RocksDB提供一些方便的工具,可解析sst文件中的K-V记录、MANIFEST文件的内容等。而LevelDB则没有相应的工具,只能通过程序读取sst文件中的K-V信息;
- RocksDB合并时支持多线程,而LevelDB只支持单线程;
- RocksDB合并时有过滤器功能,可对不符合条件的K-V进行丢弃;
- 压缩时RocksDB可支持多种压缩算法,而LevelDB只支持snappy。
- RocksDB支持增量备份和全量备份,允许将已删除的数据备份到指定目录,供后续恢复。
- RocksDB单个进程可启用多个实例,而LevelDB只允许启用单个实例。
- RocksDB允许根据需要开辟多个Memtable,以解决Put与Compact速度差异带来的性能瓶颈。而LevelDB只有一个Memtable。
二、 其他常用NoSQL数据库
(一) Redis
Redis是一种基于内存的键值对数据库,主要是通过查找键的方式来读写对应的值,且提供一定的数据持久化能力。限于成本的原因,Redis 一般用于存储一些常用和主要的数据,比如用户登录的信息等。
**要了解redis数据库,我们必须先了解Redis的数据读写流程:
1、 redis的读操作流程**
- 当第一次读取数据时,读取 Redis失败,此时就会触发程序读取数据库,并把读出的数据写入 Redis;
- 后续需要读取该数据时,可直接读取 Redis,这样可大大提高数据的读取速度。
2、 Redis的写操作流程: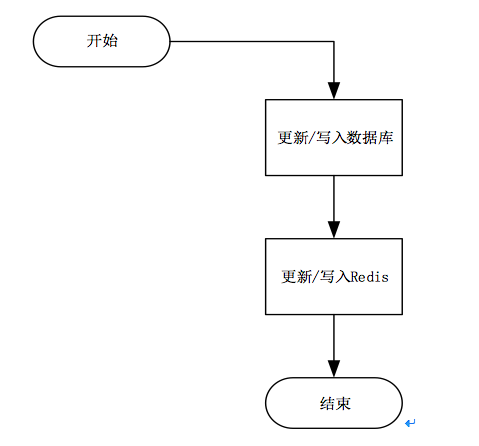
- 当进行数据更新/写入时,先更新/写入数据库,再写入redis。
- 从流程可以看出,更新或者写入数据时,需要多一次 Redis 的操作,会增加数据的写入时间,故redis不适合数据写入频繁的场景。
3、Redis在高速写场合下的操作流程
redis为了支持高速写数据场景,对写流程进行了优化: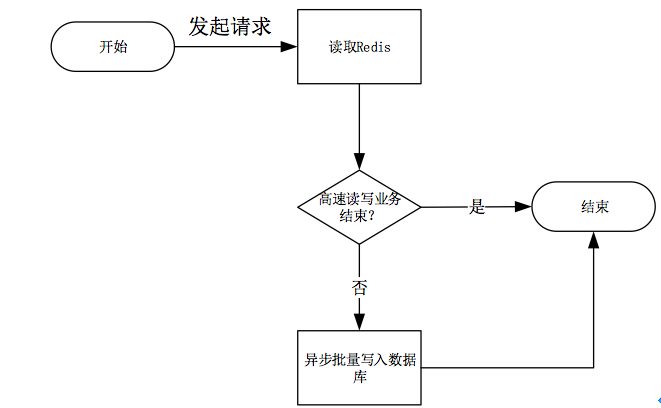
- 当写请求到达服务器时,只在 Redis 上进行操作,从而大大提高了数据库的写速度;
- 本次写完成后,redis会判断该高速写业务是否已结束,如未结束,则不会操作数据库;如结束,则会触发事件,将 Redis 的缓存的数据以批量的形式一次性写入数据库,完成持久化的工作
4、Redis高可用性架构
Redis的持久化功能,使Redis具备了在服务器重启的情况下不会损失(或少量损失)数据的能力,但仍然存在单点故障。为了避免单点故障,我们通常为redis设计了不同的高可用架构。Redis支持的高可用性架构有三种:主从备份、哨兵模式、redis-cluster群集:
1) 主从模式
在主从架构中,数据库分为两类:主数据库(master)和从数据库(slave)。主数据库只有一台,可以进行读写操作,从数据库可以有多台(至少一台),一般只提供只读服务,利用redis的复制(replication)功能,实现主从数据库的数据同步
正常情况下,由主数据库提供服务,当主数据库故障时,手工方式将其中一台从数据库升级为主数据库,继续提供服务。
一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。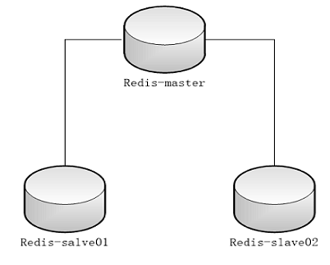
2) 哨兵模式
主从模式的数据库切换需要手工干预,而哨兵模式下,可以实现主从模式的自动化切换。哨兵工具可实现自动化的系统监控和故障恢复功能。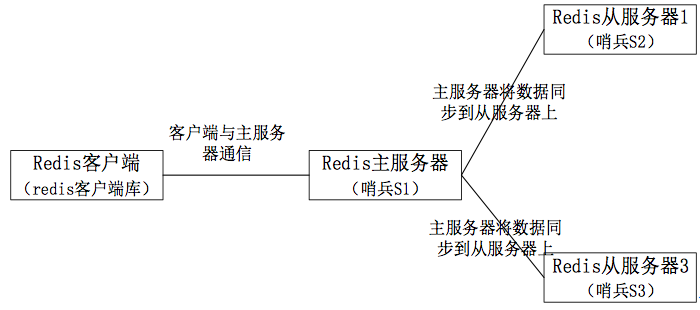
主从数据库的切换过程:
- slave leader升级为master
- 其他slave修改为新master的slave
- 客户端修改连接
- 老的master如果重启成功,变为新master的slave
3) redis-cluster群集模式
即使使用哨兵模式,每个redis存储的内容也是完整的数据,浪费内存且有木桶效应。为了最大化利用内存,可以采用cluster群集模式。具体做法如下:
在redis-cluster中,共分为16384个hash slot,(分配到集群的master中),每个master分得一部分slot。当服务器收到数据时,采用hash slot的算法,将数据分布到Master上。
redis-cluster群集至少需要3主3从,且每个实例使用不同的配置文件。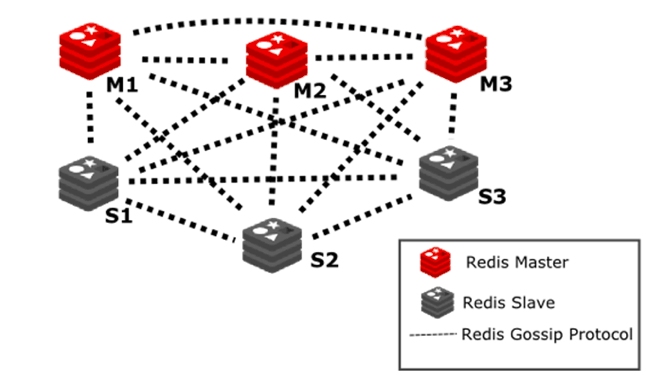
在redis-cluster架构中,redis-master节点可用于读写操作,而redis-slave节点则一般只用于备份,其与对应的master拥有相同的slot集合,若某个redis-master意外失效,则再将其对应的slave进行升级为临时redis-master。
5、Redis数据库支持的数据类型
Redis可以存储键和五种不同类型的值之间的映射。键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
6、 Redis数据库的适用场景
决定是否采用redis作为缓存数据库时,我们需要考虑以下问题:
- 业务数据是否常用?命中率如何?如果命中率很低,就没有必要写入缓存;
- 该业务数据是读操作多,还是写操作多?如果写操作多,频繁需要写入数据库,也没有必要使用缓存;
- 业务数据大小如何?如果数据量大(比如几百兆),会给缓存带来很大的压力,也没有必要使用缓存;
(二) Dynamo
Dynamo是亚马逊开发的基于键值对的高可用、分布式NoSQL数据库,其底层采用GFS进行数据存储,闭源。
虽然Dynamo是闭源数据库,但其设计理念颇为经典,有不少开源数据库(如Voldemort、Riak)借鉴了它的设计思想,故这里对Dynamo使用的几个关键技术进行介绍。
1、数据分区
Dynamo采用一致性哈希算法对数据进行分区,并引入虚拟节点概念,将虚拟节点映射到物理节点上。数据存取时,根据哈希值,将数据分布到虚拟节点上。
DynamoDB虚拟节点是固定的,当增、删服务器节点时,虚拟节点的数量不变,只需改变虚拟节点和物理节点的对应关系。
虚拟节点的引入,解决了数据在节点上分布不均匀的问题,并最大限度地减少了服务器增减时的缓存重新分布。
2、高可用性
Dynamo采用多副本方式保证数据的高可用,并采用Quorum机制保证数据的一致性
3、数据一致性检测
Dynamo采用Merkle树算法,来检测多副本之间的一致性。
(三) Bigtable
Bigtable是基于列存储的NoSQL数据库。
BigTable是Google设计的分布式数据存储系统,是基于列存储的NoSQL数据库鼻祖。
传统的关系型数据库都是基于行存储的,一条记录所有列的数据都存储在一起,而基于列存储的NoSQL数据库则不同,它将同一列(不同行)数据集中在一起存储。这样,如果只需查询某些列的数据时,就不需要查询整行的数据,从而提高查询效率。
1. BigTable数据模型
BigTable是一个稀疏、分布式、持久化的多维排序映射。本质上说,BigTable是一个键值(key-value)映射。BigTable的键有三维,分别是行键(row key)、列键(column key)和时间戳(timestamp),行键和列键都是字节串,时间戳是64位整型;而值是一个字节串。可以用 (row:string, column:string, time:int64)→string 来表示一条键值对记录。
行键可以是任意字节串,通常有10-100字节,行的读写都是原子性的。BigTable根据行键自动划分为片(tablet)。片的大小控制在100-200MB(通常为128M)。行是表的第一级索引,我们可以把该行的列、时间和值看成一个整体,简化为一维键值映射,
列是第二级索引,每行拥有的列是不受限制的,可随时增减。列被分为多个列族,同个列族里的列一般存储相同类型的数据。一行的列族很少变化,但是列族里的列可以随意添加删除。
时间戳是第三级索引。BigTable允许保存数据的多个版本,版本区分的依据就是时间戳。时间戳可以由BigTable赋值,代表数据进入BigTable的准确时间,也可以由客户端赋值。
查询时,如果只给出行列,那么返回的是最新版本的数据;如果给出了行列时间戳,那么返回的是时间小于或等于时间戳的数据。
BigTable的数据最终会以文件的形式放到GFS。
BigTable数据模型的特点:
- 同一张BigTable表内容可以分布在不同的节点上,行键可以是任意的字符串,BigTable根据行键的字典将表内容分区存储
- 同一列族的列数据类型一般是一样的。
- BigTable仅保证单行数据修改的原子性,不保证多行数据修改的原子性
- 本质上,BigTable的数据模型是一个分布式的、稀疏的、巨型的哈希表,其键是三元组,行键、列和时间戳,其值是行的内容
2. BigTable系统架构
BigTable数据库系统由主服务器和tablet服务器构成。主服务器负责将Tablet(数据分片)分配到Tablet服务器、负责Tablet服务器的健康检查、负载均衡、资源回收、数据模式的改变(例如创建表)等。Tablet服务器负责处理数据的读写,以及Tablet的拆分。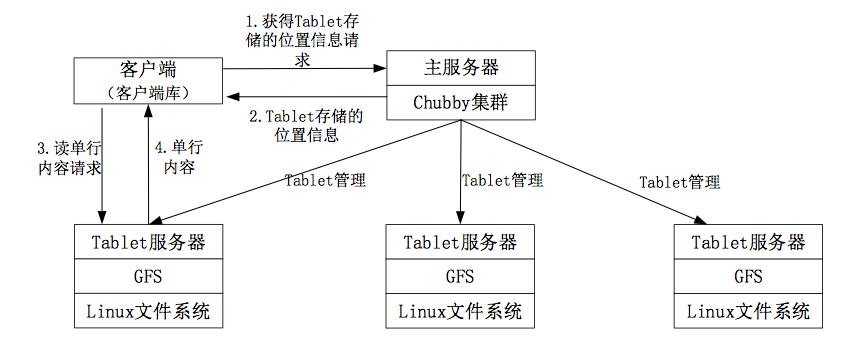
BigTable利用Chubby集群管理系统来调度任务、管理资源、监测服务器状态并处理服务器故障、保证集群中主服务器的唯一性。利用GFS存储数据文件和日志,数据文件采用SSTable格式。
Chubby服务器用于保存根Tablet的位置信息、保存用户的权限信息、确保同一时刻只有一台主服务器、并用于了解集群中其他Tablet服务器信息
BigTable架构中的几个概念:
- Tablet:是BigTable数据库中的最小存储单元,每个Tablet 128M。BigTable根据行键的字典顺序将大表的内容进行分区存储,每个存储分区称为一个Tablet。当tablet分区中存储的行超过Tablet容量时,就会进行分裂。
根据Tablet中存储的信息不同,可分为元数据tablet、根tablet。
- 元数据tablet。用于记录tablet存储位置信息的数据称为元数据,存放元数据信息的tablet叫元数据Tablet。
- 根tablet。元数据Tablet最后一行数据、以及该元数据的Tablet ID作为元数据索引。用于存放其他元数据索引的Tablet,叫根Tablet。根Tablet只有一个,不可分裂
3、Tablet服务器的查找
BigTable在Chubby上保存了一个固定文件名的文件,该文件的内容是根Tablet的位置,
查找Tablet A所在服务器的步骤如下:
- 从Chubby中得到根Tablet位置信息,即根Tablet存放在哪个Tablet服务器上;
- 联系相应Tablet服务器,读取根Tablet内容,然后在根Tablet中查找A所在的元数据Tablet;
- 读取相应元数据tablet,获取A的位置信息,即A存储在哪个Tablet服务器上;
- 查到A所在的Tablet服务器后,开始进行数据的读写。
BigTable底层数据采用LSM树存储,故其数据读写、归并方式与LevelDB相似,本文不再描述。
(四) Apache Hbase
HBase是BigTable的开源实现,是基于列存储的分布式NoSQL数据库,采用HDFS作为其文件存储系统。
1、 HBase数据模型
HBASE的数据模式与BigTable一样,也采用行键(row key)、列族(Columns Family)/列键(column key)、时间戳(timestamp)来描述数据。数据模型如下(下图为一条记录):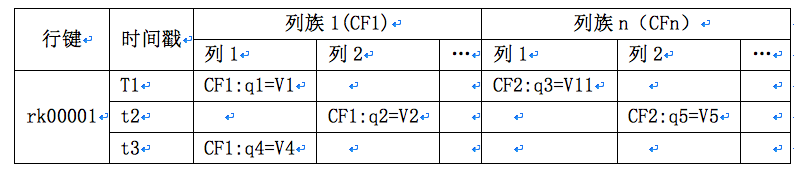
行键(row key),行记录的唯一标识,行键按照字典顺序来排序,可以是任意字符串,最多只能存储64k的字节数据;
列族(Columns Family)/列键(column key),存储相同类型数据的列可以归集为一个列族,列族可以有多个列键成员,每个列键必须归属于某个列族。列族在使用表之前定义。
Cell,通过行键和列族确定的唯一存储单元称为cell。每个cell可以保存同一份数据的多个版本。
时间戳(timestamp),cell中保存的多个版本的数据通过时间戳来进行索引。
2、HBase体系架构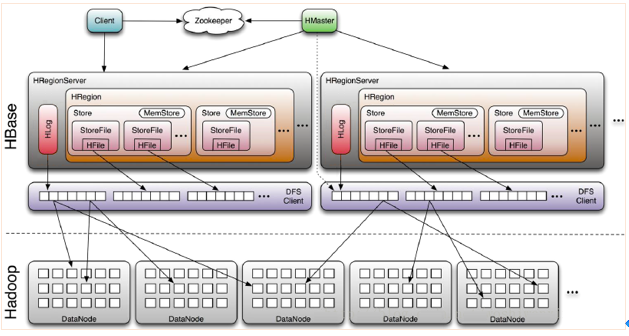
- Client
Ø Hbase客户端。包含访问HBase的接口,如linux Shell、Java api;
Ø 维护缓存, 加快HBase的访问速度。
Ø Client与HMaster之间进行管理类操作;与HRegionServer之间进行数据读写类操作 - Zookeeper
Ø 监控Master状态,保证任何时候,集群中只有一个master
Ø 存贮所有Region的寻址入口。
Ø 实时监控Region server状态,感知Regionserver的上线和下线信息。并实时通知Master
Ø 存储HBase的部分元数据 - Master
Ø 为Region server分配region(新建表)
Ø 负责Region server的负载均衡
Ø 负责region的重新分配(region失效后的重新分配、region过大之后拆分region的分配)
Ø HDFS上的垃圾回收
Ø 管理用户对table的增删改操作 - RegionServer
Ø 管理本机region,
Ø 处理client对这些region的读写请求,并与HDFS进行交互;
Ø Region server负责切分在运行过程中变得过大的region
Ø 一台RegionServer有一个Hlog和多个Region - HLog(WAL log):
Ø 每次用户操作写入MemStore前,都会先写操作日志到HLog文件。HLog文件定期会滚动出新,并删除旧的文件(已持久化到StoreFile中的数据) - HRegion
Ø HBASE中分布式存储和负载均衡的最小单元,它是表或者表的一部分。不同的HRegion可以分布在不同的HRegion server上
Ø HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据;随着region不断增大,当增大到阀值候,region就会进行裂变;当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver上。
Ø 一个HRegion包多个Store - Store
Ø Store是HBase存储的核心。一个store对应于一个列族,故一个表由多少个列族就有多少个Store
Ø 一个Store由一个位于内存中的MemStore和多个位于磁盘中的StoreFile组成。
Ø Store的存储采用LSM树 - Memstore
Ø 内存缓冲区默认128M。数据写入时,先写入Memstore - Storefile
Ø Storefile位于磁盘,一个Storefile对应一个Hfile。Storefile是逻辑概念,以Hfile方式存储在HDFS上。
一个RegionServer包含一个Hlog和多个Region,一张表由多个region组成,(不同的region可以存储在不同的Region Server上), 一个region有一个或多个store组成,一个store对应一个CF(列族),每个Strore又由一个memStore和0至多个StoreFile组成。StoreFile 以HFile格式保存在HDFS上。
3、数据写入流程:
当客户端向HBASE写数据时,会先记Log,再将数据写入 memstore。当memstore中的数据达到阈值时(默认128M),hregionserver会启动 flashcache进程,将Memstore中的数据写入storefile,每次写入形成单独的一个storefile。
当storefile文件的数量增长到一定阈值后,系统会进行合并,形成新的storefile。
当region所有storefile的大小总和超过阈值,会把当前的region 分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡。
4、数据查询流程
当客户端检索数据时,先在memstore查找,如找不到,再到storefile中查找。
(五) MangoDB
MangoDB是基于文档的NoSQL数据库,该类数据库将一个文档作为一条记录存储起来,一条记录就是一个文档。文档NoSQL数据库对同个文档的CRUD(Create、Read、Update、Delete)满足ACID属性,但对跨多个文档的操作不满足ACID属性
1、MongoDB的基本概念/术语
MongoDB 的主要概念有:文档(document)、集合(collection)、数据库(database),三者层层包含,层次结构如下: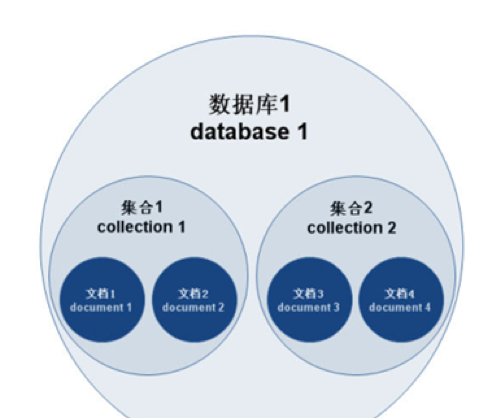
MongoDB中,数据库、集合、文档与关系型数据库中数据库、表、行的概念相类似,可作如下对照: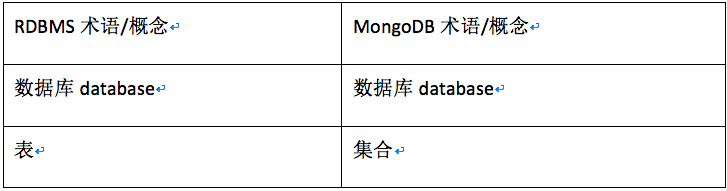

- 一个mongod实例中允许创建多个数据库。
- 一个数据库中允许创建多个集合(集合相当于关系型数据库的表)。
- 一个集合则是由若干个文档构成(文档相当于关系型数据库的行)
- 文档是MongoDB中数据的基本单元。
2、数据库文件类型
MongoDB的数据库文件主要有3种:journal 日志文件、namespace 表名文件、data 数据及索引文件:
- 日志文件:用于存放日志,当系统宕机时,用于恢复尚未来得及同步到硬盘的内存数据。
- 命名文件dbname.ns:用来存储整个数据库的集合以及索引的名字。默认16M。可调整到2G。
- 数据文件dbname.0, dbname.1,… 用于存放数据或索引。第一个数据文件会以“数据库名.0”命名,如 my-db.0。默认大小是64M,当第一个文件空间将用完时,生成第二个数据文件,如my-db.1。文件大小为128M,第三个为256M。最大2G。
每个Database(DB)由一个.ns文件及若干个数据文件组成。
3、数据文件结构
Namespace:每个数据库包含多个namespace(对应collection名),通过命名文件dbname.ns快速定位某个namespace的起始位置。
数据文件:每个数据文件被划分成多个extent,每个extent只包含一个namespace的数据,同一个namespace的所有extent之间以双向链表形式组织。
Extent:是MongoDB存储数据(BSON文档)和索引的逻辑容器,每个extent包含多个Record(对应document),同一个extent下的所有record以双向链表形式组织。
Record记录,用于存放数据(MongoDB的BSON文档),每一个记录包含记录头、BSON文档和额外的padding空间。每个Record对应mongodb里的一个文档
如下图所示(my-db.1和my-db.2 是数据库的两个数据文件):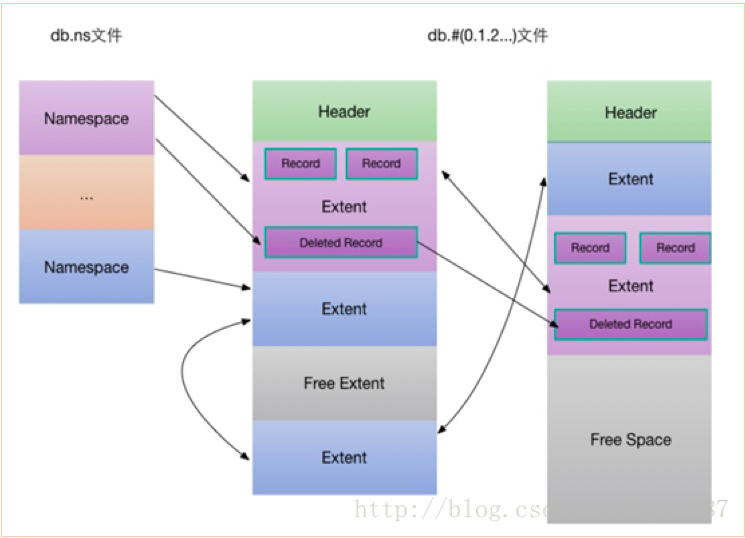
- 一个数据文件可以划分为多个Extent,
- 每一个Extent只包含一个namespace(集合)的数据或者索引
- 同一个Extent只能有数据或索引,不能两者共存
- 每个Extent可以有多个Record记录
4、MongoDB的存储引擎
MongoDB 3.0引入插件式存储引擎API,为第三方存储引擎的接入提供便利。MongoDB支持多种存储引擎,常用的如MMAPv1、WiredTiger、In-Memory等。MMAPv1是mongodb原生的存储引擎,3.2版本以后,默认引擎改为WiredTiger。以下介绍WiredTiger存储引擎的实现原理。
WiredTiger的数据读写过程:当WiredTiger进行数据写操作时,会先写入Cache,并持久化到WAL(Write ahead log),每60s或log文件达到2GB时会做一次Checkpoint,将当前的数据持久化,产生一个新的快照。当Wiredtiger连接初始化时,首先将数据恢复至最新的快照状态,然后根据WAL恢复数据,以保证存储可靠性。
Wiredtiger的Cache采用B树方式组织,每个B树节点为一个page,root page是B树的根节点,internalpage是B树的中间索引节点,leaf page真正用于存储数据;B树的数据以page为单位按需从磁盘加载或写入磁盘。
WriedTiger特性
- DocumentLevel Concurrency(文档级别的锁):多个写操作可以同时修改同一集合中的不同文档,修改同一文档时必须串行执行。
- wiredTiger基于“文档级别”lock机制,允许多个客户端同时更新一个colleciton中的不同文档,因此具有更高的读写负载和并发量。
- Snapshotsand Checkpoints(快照和检查点):mongoDB每60秒或日志文件达到2G会创建一个检查点(产生一个snapshot,该Snapshot呈现的是和内存中数据一致的视图),当向Disk写入数据时,WiredTiger将Snapshot中的所有数据以一致性方式写入到数据文件(Disk Files)中
- Journal(日志):开启 journal 后,每次写入会记录一条操作日志(通过journal可以重新构造出写入的数据)
- Compression(压缩):WiredTiger对存储集合(Collection)和索引(Index)进行压缩。
在一个MongoDB复制集中,多种存储引擎可以并存,以满足更复杂的应用需求。例如,可以使用In-memory存储引擎进行低延时的操作,同时使用基于磁盘的存储引擎完成持久化。
5、 MongoDB分布式集群架构
MongoDB 有三种集群部署模式,分别为主从复制(Master-Slaver)、副本集(Replica Set)和分片(Sharding)模式。
1) 主从复制(Master-Slaver)
主从复制是 MongoDB 中最简单的数据库同步备份的集群技术,其基本的设置方式是建立一个主节点(Primary)和一个或多个从节点(Secondary),主从节点均运行 MongoDB 实例,完成数据的存储、查询与修改操作,如下图所示。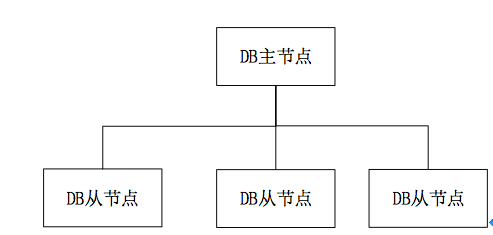
该模式集群中只能有一个主节点,主节点提供所有的增、删、查、改服务。从节点不提供任何服务,(但是可以通过设置使从节点提供查询服务,以减少主节点的压力)。
主节点记录所有操作,从节点定期轮询主节点,以获取这些操作,然后更新从节点数据,以保证数据与主节点一致。
当主节点故障时,需人工将从节点升级为主节点。
2) 副本集(Replica Set)
集群架构如下所示: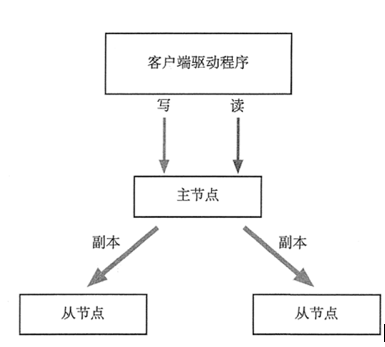
集群拥有一个主节点和多个从节点,主节点提供所有服务,从节点不提供任何服务,(或提供只读服务)。区别在于:当集群中主节点故障时,从节点自动投票,选举出新的主节点,该过程对应用透明的。
3) 分片(Sharding)
分片是指将数据拆分并分散存放在不同机器上的过程。MongoDB 支持自动分片。其分片集群模式如下图所示: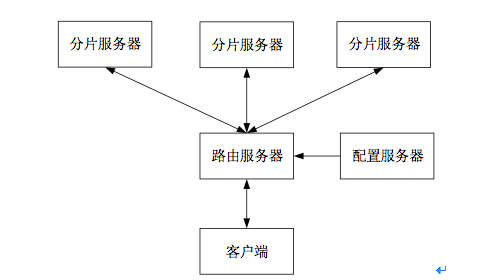
分片集群的三个重要的组件:
- 分片服务器Shard Server。用于存储实际的数据块。
每个Shard Server 都是一个 MongoDB数据库实例。一个数据库集合可分成多个块存储在不同的Shard Server 中。在实际生产中,一个 Shard Server 可由几台机器组成一个副本集来承担,以防止单点故障。
- 配置服务器Config Server。是一个独立的MongoDB进程,保存集群的配置信息和分片的元数据信息,集群启动之初建立。
- 路由服务器Route Server。也是一个独立的MongoDB进程,在集群中可作为路由使用,提供客户端应用程序和分片集群之间的接口。客户端由此接入,让整个集群看起来像是一个单一的数据库。
Route Server本身不保存数据,启动时从 Config Server中加载集群信息到缓存中,并将客户端的请求路由给每个Shard Server,当Shard Server 返回结果后进行聚合并返回客户端。Sharding 模式适合处理大量数据,它将数据分开存储,不同服务器保存不同的数据,所有服务器数据的总和即为整个数据集。
在实际生产环境中,Master-Slaver模式目前已经不推荐使用,副本集和分片结合使用,以满足高可用性和高可扩展性的需求。
三、 常用NoSQL数据库的比较与适用应用场景

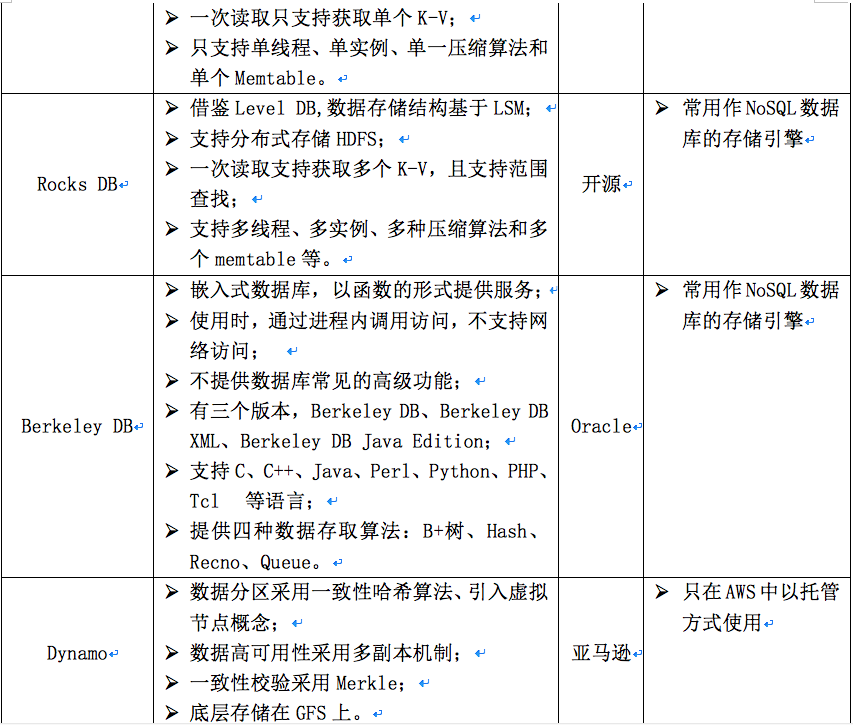


关于应用场景的归类和数据库的选择问题,仁者见仁,智者见智,选择不是非此即彼。需要大家根据自己的业务特色,结合数据库的技术特点,做出恰当的选择,本文不再做进一步描述。
常用分布式数据库的分析与比较系列篇
常用分布式数据库的分析与比较——NewSQL数据库篇:
https://www.talkwithtrend.com/Article/248323
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞11作者其他文章
评论 3 · 赞 15
评论 2 · 赞 21
评论 3 · 赞 13
评论 1 · 赞 9
评论 2 · 赞 11
添加新评论3 条评论
2022-10-10 17:41
2020-05-06 11:04
2020-04-20 11:46