
五种业界主流存储双活架构设计读写性能对比分析
在之前的文章《五种业界主流存储双活方案解析(方案特点)》中,笔者对华为 HyperMetro 、 EMC Vplex 、 IBM SVC 、 HDS GAD 和 NetApp MetroCluster 等五个厂商存储双活方案的特点、仲裁需求、仲裁机制和两地三中心扩展方案进行了详细的解析。在本篇文章中,笔者将从另一个角度,也是存储双活方案的另一大关键点 --- 读写性能入手,剖析这五种存储跨中心双活方案的 I/O 读写流程和对业务主机带来的性能影响。
性能影响问题是存储双活方案的突出问题,因为双活系统在写入数据时,会写两次数据,尤其是通过复制功能写到远端存储的过程,传输链路的性能也会影响整体性能。因此,存储双活不可避免要遇到性能问题,这也是各大厂商存储双活方案标明最大支持 RTT 或者站点间距的原因之一。相比单存储直接提供读写来说,存储双活一定会增加读写响应时间,更别说存储还是跨两个不同数据中心的,随着距离的增加,理论上每增加 100KM ,会增加 1MS 的 RTT (往返延迟时间),通常单个 I/O 总耗时在 1-3MS 左右,就会认为单个存储 I/O 时延处于比较高性能的模式(最大支持的 IOPS 也是存储选型的重要考虑因素),如果加上其他因素,如“数据头处理”和“并发”, 1MS 的“理论”时延增加的影响会成倍增加,将原本处于高性能模式的 I/O 响应时间拉高,对应用或者数据库来说,“变慢”了。所以存储双活的初衷是只是为了高可用性和提高总体并发、吞吐量,并不是为了降低读写响应时间。然而,我们在选型存储双活方案时,依旧需要考虑如何尽量降低双活的存储所带来的性能降低影响,哪种方案会带来较小的性能影响。因此,笔者现就目前国内主流的五种存储双活方案在双活性能上的特点进行解析。
一、华为 HyperMetro
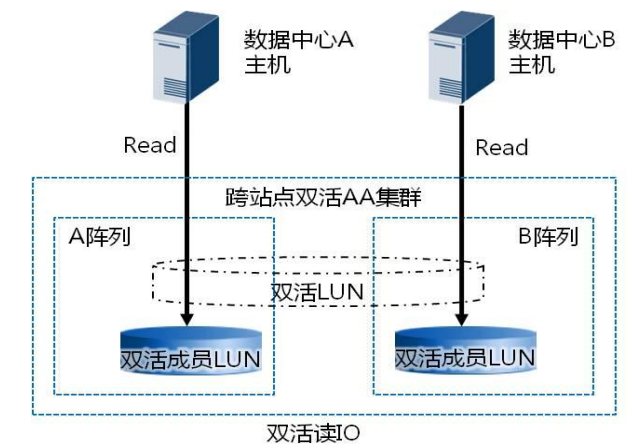
1 、读 I/O :针对数据读场景, 华为 HyperMetro 方案架构下, 双活数据中心的业务主机只需要读本数据中心对应的双活存储阵列即可,如下图所示,这样可以有效避免主机跨数据中心读取数据,提升整体读 I/O 访问性能。
2 、写 I/O :针对数据写场景,业务主机直接写本数据中心对应的双活存储阵列,避免主机跨数据中心转发数据(在转发写模式下,区分主从 LUN ,从 LUN 的写 I/O 将被控制器转发到主 LUN 的控制器处理写 I/O ,并将数据回同步至从 LUN ),充分利用 HyperMetro AA 双活能力,如下图左所示, AA 集群的每个控制器都能够接收写 I/O ,由本地控制器处理本地主机的写 I/O 请求,减少跨数据中心的转发次数,提升方案整体性能。数据写 I/O 过程如下图右所示:
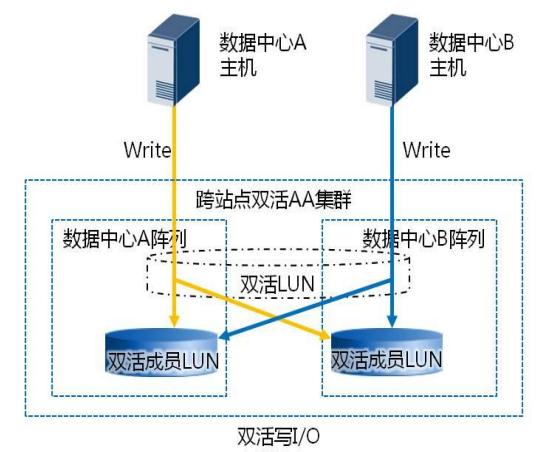
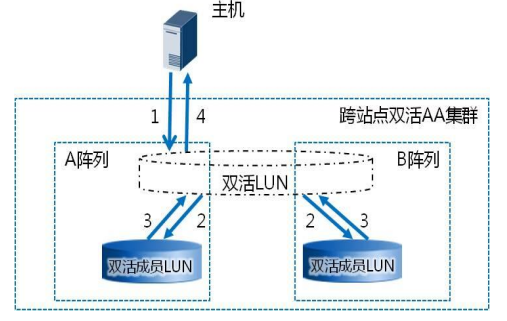
假如数据中心 A 的存储阵列收到写 I/O ,写 I/O 处理流程如下:
( 1 )申请写权限和记录写日志:数据中心 A 存储阵列收到主机写请求,先申请双活 Pair 的写权限。获得写权限后,双活 Pair 将该请求记录写日志(保证断点续传)。日志中只记录地址信息,不记录具体的写数据内容。该日志采用具有掉电保护能力的内存空间记录以获得良好的性能。
( 2 )执行双写:将该请求拷贝两份分别写入本地 LUN 和远端 LUN 的 Cache 。
( 3 )双写结果处理:等待两端 LUN 的写处理结果都返回。
( 4 )响应主机:双活 Pair 返回主机写 I/O 操作完成,完成一次写 I/O 周期。
从整个写 I/O 流程可以看出, HyperMetro 为了保证两个数据中心存储的数据实时一致,写操作都需要等待两端存储写成功之后再返回主机“写成功”。双活 I/O 性能因为实时双写导致了一定的时延增加,该写 I/O 流程相较于本地写 I/O 而言,额外增加了以下四个时延点。
(1) 写权限申请时,等待分布式锁产生的时延;
(2) DCL 机制(数据变化记录)产生的时延;
( 3 )跨站点将写 I/O 拷贝至远端 LUN Cache ;
( 4 )远端 LUN Cache 收到写 I/O 后,将处理结果返回至本地。
这四个时延点中最主要的还是 3 和 4 中组成的 1 倍跨站点往返时延( RTT ),此外,华为 HyperMetro 设计了一系列 I/O 性能优化方案,以减小对写时延的影响,提升整体双活的业务性能。
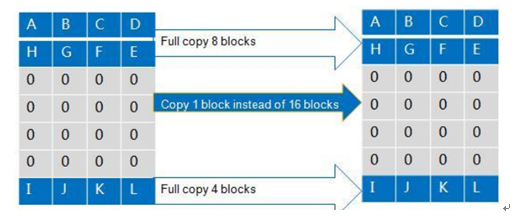
( 1 )数据零拷贝:在双活镜像数据的初始同步或者恢复过程中的增量同步过程中,差异数据块通常有大量的零数据块,无需逐块复制,该功能叫数据零拷贝。例如,虚拟化场景下,新建虚拟机时会产生大量的零数据块,一个数十 GB 的操作系统盘,实际非零数据块仅 2-3GB 。 HyperMetro 零页面识别技术的实现方法如下:通过硬件芯片,对数据拷贝源端进行快速识别,找出零数据,在拷贝过程中,对全零数据特殊标识,只传输一个较小的特殊页面到对端,不再全量传输。相比全量同步,该技术可有效减少同步数据量,减少带宽消耗,缩短整体 I/O 同步时延。
( 2 ) FastWrite 技术: HyperMetro 通过 FastWrite 功能对阵列间数据传输进行了协议级优化,应用 SCSI 协议的 First Burst Enabled 功能,将写数据的链路传输交互次数减少一半。正常的 SCSI 流程中,写 I/O 在传输的双端要经历“写命令”、“写分配完成”、“写数据”和“写执行状态”等多次交互。利用 FastWrite 功能,优化写 I/O 交互过程,将“写命令”和“写数据”合并为一次发送,并取消“写分配完成”交互过程,将跨站点写 I/O 交互次数减少一半。该技术将单次写 I/O 的 RTT 控制在 1 倍,避免无效交互产生的 RTT 。
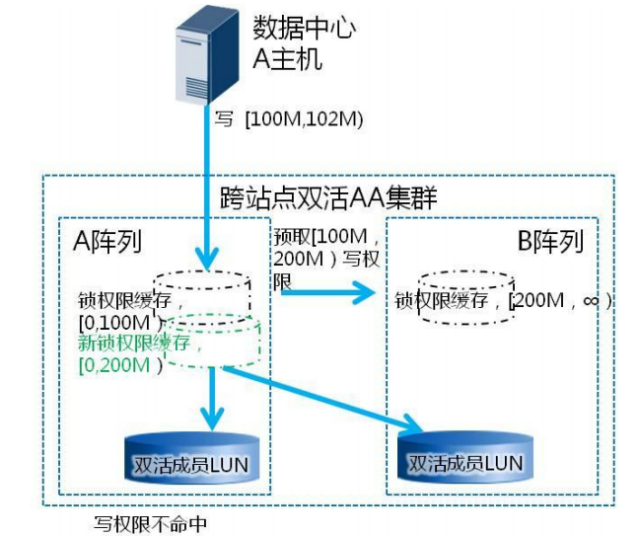
( 3 )智能的锁预取和缓存策略:本地写 I/O 时,需对主机 I/O 访问的 LBA 区间加分布式范围锁进行并发互斥,通过分布式范围锁,可以避免频繁的锁请求交互,减少跨站点交互交互频率。当 HyperMetro 的分布式锁技术在写权限本地无缓存(范围锁)的情况下,会通过较小的控制报文,向锁权限缓存节点申请写权限,并多预取部分区间的写权限缓存到本地,如下图左所示。后续的连续写 I/O 可快速在本地命中写权限,不需要再跨站点申请写权限,这样将进一步减少交互频率,如下图右所示。

二、 EMC VPLEX
1 、读 I/O : EMC Vplex 具有读缓存,可以通过写 I/O 的独特机制,实现读 I/O 的加速。 Vplex Local/Metro/Geo 架构的读 I/O 流程如下:
( 1 )读 I/O 的时候先读 Local Cache ,如命中则直接读取,相较于直接读后端存储阵列,内存较机械硬盘的读取性能有着显著提升,因此,从 Cache 内存中直接命中读 I/O ,将大幅提升读 I/O 性能;
( 2 )如果没有命中 Local Cache ,将继续在 Global Cache 中查找,如果命中,则从对应的 Vplex 引擎 Cache 中将其读取到 Local Cache ,因此,两引擎的 VplexMetro/Geo 架构存在 1 倍的跨站点往返时延;
( 3 )如果在 Global Cache 中没有命中,则从本地后端的存储阵列中读取到 Local Cache 中,并同时修改 Local 和 Global Cache 中的信息与索引信息(表明其他引擎可以从该引擎 Cache 读取数据),本次读 I/O 加速无效果。
( 4 )无论有没有命中 Cache ,最后都将反馈主机读 I/O 结果,本次读 I/O 周期结束。
从整个读 I/O 流程可以看出,相较于常见的后端存储直接读取,由于读 Cache 的存在,对读 I/O 性能的提升是有积极意义的,命中 Local Cache 将提升数倍读响应时间,没有命中 Local Cache 几乎和直接后端存储读取性能一致,在实际联机型应用读写比例大致为 7 : 3 的情况下,提升读 I/O 的效果是显而易见的。
2、 写 I/O : EMC Vplex 同样也具备“写缓存”, Vplex Metro 没有真实的“写缓存”,实际上是读缓存,用于加速读 I/O ,模式采用的是写直通缓存; Vplex Geo 具有真实的写缓存,模式采用的是回写缓存。其中 Vplex Metro 写 I/O 流程如下图所示:
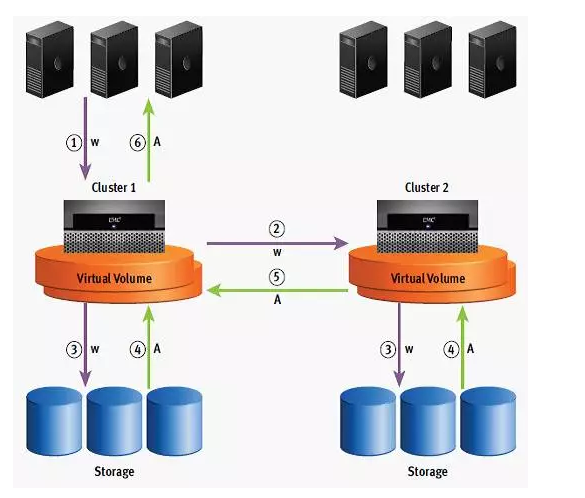
Vplex Metro/Geo 的写 I/O 步骤如下:
(1) 写 I/O 时先判断是否在 Local 、 Global Cache 中有对应的旧数据,如果没有,则直接写入本地 Local Cache ;
(2) 如果有旧数据,需先废除旧数据再写入 Local Cache 。若通过 Global Cache 查询到 旧数据存在于其他站点 Vplex 引擎中,则需要跨数据中心查询和废除旧数据,通讯具有 1 倍的跨站点往返时延;
(3) 写入 Local Cache 后, Vplex Metro 和 Geo 的处理方式有所区别, Vplex Metro 通过写直通缓存模式将写 I/O 刷入两套后端存储阵列,刷入跨站点的后端存储将引入 1 倍的跨站点往返时延;而 Vplex Geo 通过回写缓存模式将写 I/O 写入引擎控制器的缓存,并异步镜像至另一套 Vplex 集群的引擎控制器的写 Cache 中;
(4) Vplex Metro 待两套存储全部写反馈完成,最后将反馈主机写 I/O 周
期完成,同时 Global Cache 中的索引做相应修改,并在所有引擎上共享该信息,实现分布式缓存一致性;而 Vplex Geo 在镜像异步写发起后,直接反馈主机写
I/O 周期完成,并待两个引擎的 Cache 达到高水位后刷入后端存储。
从整个写 I/O 流程可以看出, Vplex Metro 为了加速读 I/O ,引入了读 Cache ,
为了保证读 I/O 的数据一致性( AccessAnyWhere ),又引入了 Global Cache ,造成写 I/O 必须要查询本地和其他引擎的 Local Cache 是否有旧数据,以及时废弃旧数据,更新和同步所有引擎的 Global Cache 。这样的机制原理势必牺牲了一定的写 I/O 性能,相较于后端存储直接写,引入了两倍的 RTT 和更新同步 Local 、 Global Cache 过程的时延。其应用场景更适合于查询比例远高于更新比例的联机型应用。
三、 IBM SVC
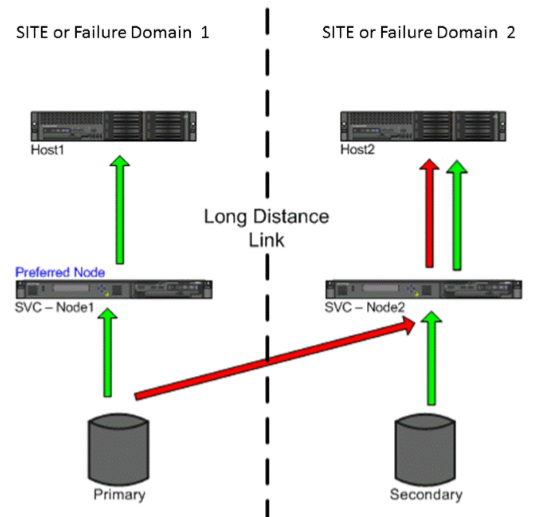
1、 SVC ESC 方案读 I/O :针对数据读场景,两个站点的主机对本站点 SVC
节点和底层存储节点的读 I/O 可以实现就近本地读能力,如下图所示,无需跨站点读其他 SVC 节点和存储节点,避免了跨站点往返时延消耗,性能较单站点存储节点直接读取,性能几乎一致;当某个站点的存储出现故障时,该站点的 SVC 节点将激活和另一个站点的存储路径,切换读取该存储的数据。
2 、 SVC ESC 方案写 I/O :针对数据写场景, SVC ESC 的方案和 SVC Local 方案略有区别, SVC Local 由一组 I/O Group ,两个 SVC 节点组成,对于存储 LUN 而言,其必然从属于其中一个 SVC 节点,称为优先节点。存储 LUN 的访问只能由优先节点提供;而 SVC ESC 同样是一组 I/O Group ,其两个 SVC 节点的角色是一致的,摒弃了优先节点的概念,主机、 SVC 节点和底层两个存储 LUN 具备站点属性, LUN 优先从属于本站点的 SVC 节点,优先被本站点主机访问。这样则实现了两个站点主机并行写本站点的 SVC 节点和对应的底层存储节点,即本地写的能力。其写 I/O 流程步骤如下:
( 1 )本地 SVC Local Cluster 写 I/O :
a 、主机发送写 I/O 请求至 SVC I/O Group , SVC 优先节点反馈主机写已就绪,随后主机将写数据发送至优先的 SVC 节点(图示步骤 1 );
b 、优先的 SVC 节点将 I/O 写入缓存,并镜像同步至同一 I/O group 的另一个 SVC 节点(图示步骤 2 );
c 、该节点收到写 I/O ,将其写入本地缓存,并回反馈至优先的 SVC 节点(图示步骤 3 );
d 、优先的 SVC 节点收到反馈后,向主机回反馈,主机端的写 I/O 周期结束(图示步骤 4 );
e 、待优先的 SVC 节点缓存达到一定高水位,将所有写 I/O 刷入后端存储 LUN (图示步骤 5 )。
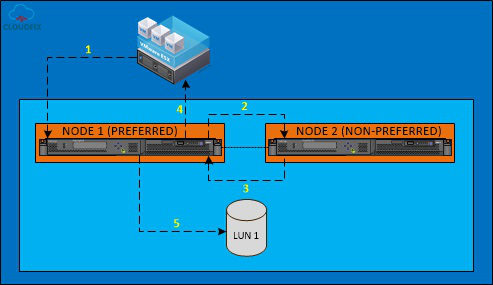
( 2 ) SVC ESC Cluster 写 I/O :
a 、主机发送写请求至本地 SVC 节点, SVC 节点反馈主机写已就绪,随后主机发送写数据至本地 SVC 节点(图示步骤 1 、 2 、 3 );
b 、本地 SVC 节点将 I/O 写入缓存,并将写缓存数据镜像到远端 SVC 节点(图示步骤 4 );
c 、远端 SVC 节点反馈本地 SVC 节点写完成标识(图示步骤 5 ) ;
d 、本地 SVC 接收到远端反馈后,反馈写完成标识给本地主机(图示步骤 6 ) ;
e 、待本地和远端 SVC 节点写缓存达到高水位,开始刷数据至后端存储,首先发送写请求给后端存储,后端存储反馈 SVC 节点写已就绪, SVC 开始发送写数据(图示步骤 7 、 8 、 9 );
f 、待写数据全部刷入,后端存储分别反馈写完成标识给本地和远端 SVC 节点(图示步骤 10 );
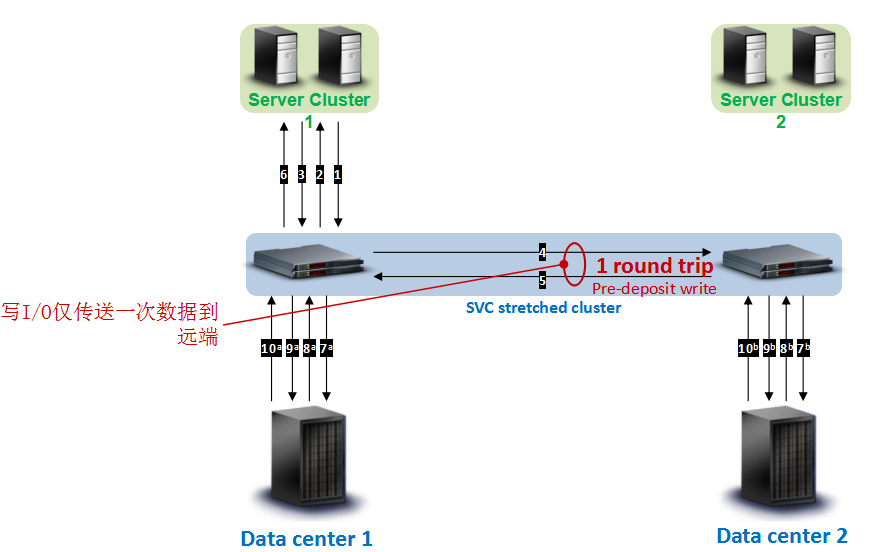
从整个 SVC ESC 方案的写 I/O 流程可以看出,步骤 1 至 6 对主机写 I/O 时延有影响,但写 I/O 仅传送一次数据到远端,相比本地直接写 I/O ,增加了 1 倍的跨站点往返时延。另外,步骤 7 至 10 是异步操作,对主机时延无影响。
3 、 SVC HyperSwap 方案读 I/O :假设初始化后, Site1 的卷为 Master 卷,
Site2 的卷为 Aux 卷,这种情况下 Site1 和 Site2 卷的读 I/O 流程是不一样的,如下图所示,其流程步骤如下:
( 1 ) Site1 主机读 I/O (本地 =Site1, 远端 =Site2 ):
a 、 Site1 主机向本地 SVC I/O Group1 的任意一个 SVC 节点发送读请求;
b 、本地 SVC I/O Group1 将读请求透传至本地 Storage Pool1 ;
c 、本地 Storage Pool1 反馈读请求,并将读数据传至本地 SVC I/O Group1 ;
d 、本地 SVC I/O Group1 将数据结果反馈至 Site1 主机;
( 2 ) Site2 主机读 I/O (本地 =Site2, 远端 =Site1 ):
a 、 Site2 主机向本地 SVC I/O Group2 的任意一个 SVC 节点发送读请求;
b 、本地 SVC I/O Group2 将读请求转发至远端 SVC I/O Group1 ;
c 、远端 SVC I/O Group1 将读请求透传至远端 Storage Pool1 ;
d 、远端 Storage Pool1 反馈读请求,并将读数据传至远端 SVC I/O Group1 ;
e 、远端 SVC I/O Group1 将数据结果反馈至本地 SVC I/O Group2 ;
f 、本地 SVC I/O Group2 将数据结果反馈至 Site2 主机。

从整个 SVC HyperSwap 方案的读 I/O 流程来看, Site1 主机是本地读,直接透穿 SVC I/O Group 读本地底层存储,读性能几乎和主机直接读后端存储一致; Site2 主机的读 I/O 需要通过本地 SVC I/O Group 跨站点转发至 Site1 的 SVC I/O Group ,再读远端的后端存储,因此额外增加了 1 倍的跨站点往返时延。
4 、 SVC HyperSwap 方案写 I/O :假设初始化后, Site1 的卷为 Master 卷,
Site2 的卷为 Aux 卷,这种情况下 Site1 和 Site2 卷的写 I/O 流程也是不一样的,如下图所示,其流程步骤如下:
( 1 ) Site1 主机写 I/O (本地 =Site1, 远端 =Site2 ):
a 、 Site1 主机向本地 SVC I/O Group 节点发送写 I/O 请求和数据;
b 、本地 SVC 节点将写 I/O 写入本地写缓存;
c 、本地 SVC 节点将写 I/O 同步至同 I/O Group 的另一 SVC 节点缓存,并通过 SVC Metro Mirror 发送写 I/O 至远端 SVC I/O Group 节点;
d 、本地和远端所有 SVC 节点陆续反馈写 I/O 同步已完成;
e 、本地 SVC 节点反馈 Site1 主机写完成;
f 、待本地和远端 SVC 节点写缓存达到高水位,分别将写缓存数据刷入各自站点的后端存储中。
( 2 ) Site2 主机写 I/O (本地 =Site2, 远端 =Site1 ):
a 、 Site2 主机向本地 SVC I/O Group 节点发送写 I/O 请求和数据;
b 、本地 SVC 节点将写 I/O 转发至远端 SVC I/O Group 节点;
c 、远端 SVC 节点将写 I/O 写入写缓存中;
d 、远端 SVC 节点将写 I/O 同步至同 I/O Group 的另一 SVC 节点缓存,并通过 SVC Metro Mirror 发送写 I/O 至本地 SVC I/O Group 节点;
e 、本地和远端所有 SVC 节点陆续反馈写 I/O 同步已完成;
f 、远端 SVC 节点反馈本地 SVC 节点的转发响应;
g 、本地 SVC 节点反馈 Site2 主机写完成;
h 、待本地和远端 SVC 节点写缓存达到高水位,分别将写缓存数据刷入各自站点的后端存储中。

从整个 SVC HyperSwap 方案的写 I/O 流程来看, Site1 主机是本地写,直接写 SVC 节点缓存,并同步至两个站点所有 SVC 节点。相比直接存储写 I/O ,增加了一倍的跨站点往返时延; Site2 主机的写 I/O 需要通过本地 SVC I/O Group 跨站点转发至 Site1 的 SVC I/O Group ,该步骤增加了一倍的跨站点往返时延。写到 Site1 的数据必须同步回 Site2 ,来保证两个站点数据一致性,这个步骤又额外增加了一倍的跨站点往返时延,因此,相比直接存储写 I/O ,总共额外增加了 2 倍的跨站点往返时延。
四、 HDS GAD
HDS GAD 的读写 I/O 流程受 GAD 卷的状态所影响, GAD 卷由 PVOL 和 SVOL 成对组成,其状态分为已镜像、正在镜像、暂停、阻塞。在不同状态下,两个站点的主机对 PVOL 和 SVOL 的读写 I/O 步骤和性能是不一样的。
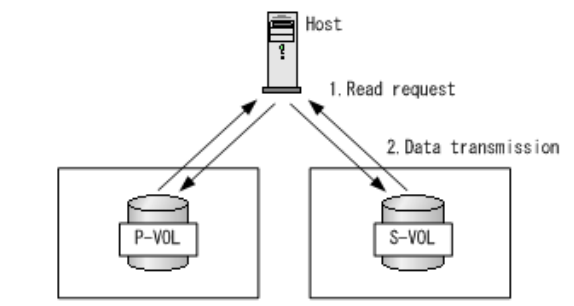
1 、主机写 I/O ( GAD 状态为: Mirrored ):当 GAD 卷的状态为已镜像时, PVOL 卷和 SVOL 卷的 I/O 模式为镜像。主端和从端都可以进行写操作,正常情况下,任意端存储接收到写 I/O 请求后,都执行双写,待两端存储全部写入成功后,再回复主机写成功,完成写 I/O 周期。如下图所示,其详细写 I/O 步骤如下:
(1) 主机可通过 HDLM 多路径软件来配置优选路径为本地的存储卷,首先发起写 I/O 请求,对 GAD 卷的写数据将写入本地存储卷;
(2) 本地存储卷将接收到的写 I/O 同步镜像至远端存储卷;
(3) 远端存储卷收到写 I/O 后,完成写 I/O ,并反馈结果至本地存储卷;
(4) 两端存储卷全部双写完成后,由本地存储卷反馈主机写完成。
其中,步骤 2 、 3 将引入 1 倍的跨站点往返时延。

2 、主机读 I/O ( GAD 状态为: Mirrored ):针对读 I/O 场景,两个站点主机可分别读取本站点的主存储和辅助存储系统的数据,主机服务器通过优选路径读取本地存储卷,然后发送到服务器。该场景下,主存储系统和从存储系统之间没有任何通信发生。
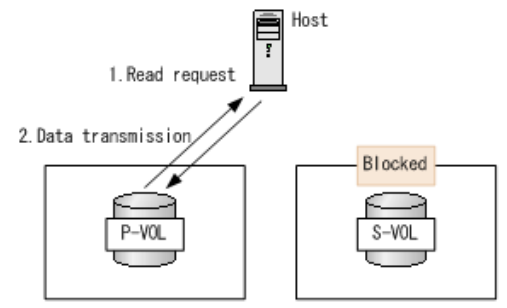
3 、主机写 I/O ( GAD 状态为: Mirroring ):当 GAD 卷状态为正在镜像同步时, PVOL 的 I/O 模式为镜像, SVOL 的 I/O 模式为阻塞。写请求被写入两个对卷,然后写完成的反馈返回到服务器。因为 SVOL 的 I/O 模式是阻塞的,所以它不接受来自服务器的任何 I/O ,但是写入 PVOL 的数据也会由主存储系统同步写入 SVOL ,待 SVOL 写入完成反馈后,才反馈服务器写周期完成,因此本地主机的写 I/O 引入了 1 倍的跨站点往返时延,如下图所示。而远端主机在 SVOL 阻塞时,需要通过多路径跨站点访问 PVOL ,额外又引入了 1 倍的跨站点往返时延。

4 、主机读 I/O ( GAD 状态为: Mirroring ):正在镜像的主从存储系统,从 SVOL 无法提供访问 I/O 服务,读取请求全部由 PVOL 提供,然后将读取结果反馈到主机。该场景下,主存储系统和从存储系统之间也没有任何通信发生。远端主机需要跨站点访问 PVOL ,引入 1 倍的跨站点往返时延。
5 、主机写 I/O ( GAD 状态为: Suspended ):当 GAD 卷的状态为暂停时,并且 PVOL 上有最新的数据时, PVOL 的 I/O 模式为本地, SVOL 的模式为阻塞;当 SVOL 上有最新的数据时, PVOL 的 I/O 模式为阻塞, SVOL 的模式为本地。当 PVOL 上有最新的数据时,写入请求被写入 PVOL ,然后写入完成后反馈返回到主机,如下图所示。此时, SVOL 的 I/O 模式是阻塞的,因此它不接受来自服务器的 I/O ,而 PVOL 的 I/O 模式是又本地的,因此写入 PVOL 的数据也不会同步写入到 SVOL 。该状态下,本地主机是本地写,远端主机需要跨站点写,引入了 1 倍的跨站点往返时延, PVOL 和 SVOL 间的数据差异也将累积变大。

6 、主机读 I/O ( GAD 状态为: Suspended ):当 GAD 卷的状态为暂停时,从 SVOL 无法提供访问 I/O 服务,读取请求全部由 PVOL 提供,然后将读取结果反馈到主机。该场景下,主存储系统和从存储系统之间没有任何通信发生。远端主机需要跨站点访问 PVOL ,引入 1 倍的跨站点往返时延。
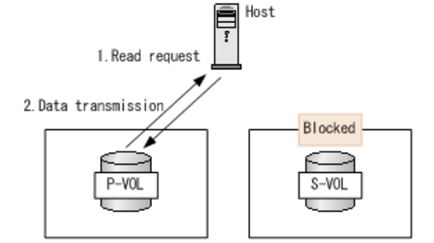
7 、主机读写 I/O ( GAD 状态为: Blocked ):当 GAD 状态为阻塞时, PVOL 和 SVOL 的 I/O 模式全部为阻塞。两个卷都不接受读 / 写处理,主机存储 I/O 中断。
8 、 HNAS+GAD 写 I/O :如下图所示, HAS 的两个节点 Node1 与 Node2 组成一个 HAS 集群, HNAS 需结合 GAD 双活实现文件系统双活,且 HNAS 节点只有一个主节点提供文件系统读写,其写 I/O 步骤如下:
( 1 )本地 HNAS 客户端将 I/O 写入到本地 HNAS 节点的 NVRAM 中;
( 2 )本地 HNAS 节点将 NVRAM 中的写 I/O 镜像到远端 HNAS 节点的 NVRAM 中;
( 3 )远端 HNAS 节点反馈本地 HNAS 同步完成;
( 4 )本地 HNAS 反馈本地客户端写 I/O 完成,完成本次写 I/O 周期;
( 5 ) 1-6 秒内,本地 HNAS 节点将 NVRAM 里的数据刷到本地后端 GAD 存储, HNAS 节点通过多路径优先选择 PVOL 下盘,实现本地直接下盘操作;
( 6 )本地存储通过 True Copy 同步将数据镜像到 SVOL ;
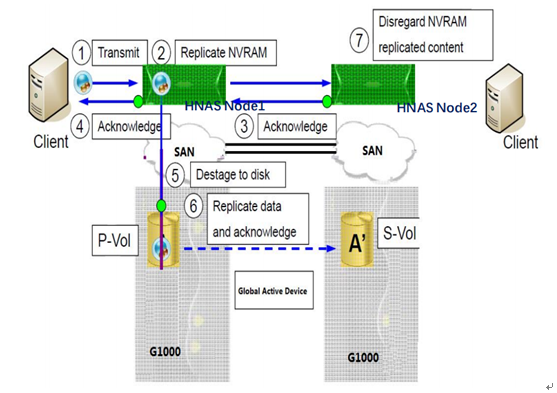
从整个 HNAS+GAD 写 I/O 流程来看,本地站点的 HNAS 客户端能够读写本地 HNAS 和底层 GAD 双活存储,且写 I/O 会引入 2 倍的跨站点往返时延, 1 倍为两个 HNAS 节点 NVRAM 镜像所引入, 1 倍为 PVOL 和 SVOL 的双写 I/O 所引入。而远端站点的 HNAS 客户端则需要跨站点访问 HNAS 节点,并下盘到 PVOL 所在存储,因此将引入 3 倍的跨站点往返时延。
五、 NetApp MetroCluster
1 、读 I/O :针对数据读场景, NetApp MetroCluster 架构下,站点 A 的主机会优先从本地 Plex0 ( A_LOCAL )中读数据,远端的 Plex1 ( A_REMOTE )的读权限需要命令打开(切换场景),默认情况下,远端 Plex1 ( A_REMOTE )不提供读业务;站点 B 的主机会优先从本地 Plex0 ( B_LOCAL )中读数据,远端 Plex1 ( B_REMOTE )默认时不提供读业务。如下图所示:
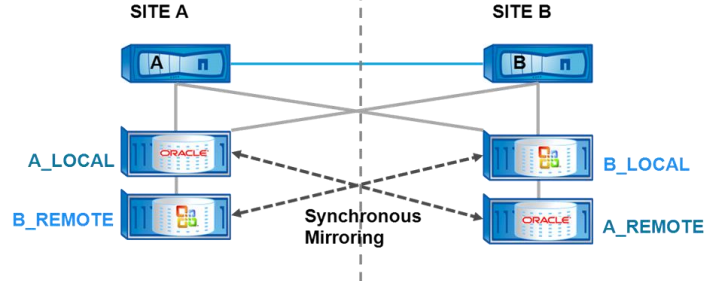
1、 写 I/O :针对数据写场景, MetroCluster 使用 SyncMirror ,它可以对集
群的两端进行同步写入。作为写入过程的一部分, NVRAM 还在集群互连上进行镜像,以确保不会丢失数据,并且所有写入都将提交到磁盘,以确保在中断期间不会丢失数据。由于该机制, MetroCluster 提供真正的同步写入。这两次写入均由一个控制器执行,它不会将写入传递给远程节点以在该站点执行写入。因此,可以理解为 NetApp MetroCluster 分以下两个同步动作分别实现两个站点控制器和后端存储阵列的写数据一致性:
( 1 )第一个同步动作是所有控制器的 NVRAM 数据同步。每个控制器的 NVRAM 都分成 4 个区域,当新请求写操作时,先写到本地 NVRAM ,再同步到本地 HA Pair 的 NVRAM ,以及远端的 DR Pair 的 NVRAM 后,返回成功。对本站点主机而言,同步 NVRAM 将引入 1 倍的跨站点往返时延,对于远端主机而言,远端相同的 Plex 不提供写业务,需要跨站点写至本地 NVRAM ,再同步至 HA/DR Pair 的 NVRAM 中,因此需额外再引入 1 倍的跨站点往返时延。

( 2 )第二个同步动作是通过 SyncMirror 在 NVRAM 日志下盘时,实现主从站点的盘的双写。 SyncMirror 工作在 Aggregate 层上,镜像的 Aggregate 由 2 个 Plex 组成,来自本地 Pool0 的 Plex0 和远端的 Pool1 的 Plex1 。当有 NVRAM 日志开始刷盘时,写请求会同时写到本地的 Plex0 和远端的 Plex1, 两边同时写成功以后,返回成功。另外值得注意的是,控制器 NVRAM 下盘需通过独特的 FC-to-SAS 设备实现,带来了额外的协议转换开销,也影响了一定的性能,增加了时延。这是由于控制器与磁盘间,由于 SAS 后端存储不能拉远,为弥补该缺陷引入了新的协议转换设备,数据刷盘时会间接影响控制器一定的工作性能。
为了更好地了解 MetroCluster 如何将数据写入磁盘的整个工作原理。如下图所示中,列举出了写 I/O 请求进入站点 1 中的存储节点的整个步骤过程:
( 1 )本地站点主机发起写请求,并开始将数据写入本地控制器中;
( 2 )主机的写请求被写入控制器的 NVRAM 中;
( 3 )本地控制器将写 I/O 同步至远端集群互连的控制器 NVRAM ,以确保没有数据丢失,该方式由本地控制器驱动,而不是远端控制器驱动,提升了些许性能(第一个同步动作);
( 4 )本地控制器确认 NVRAM 同步完成,反馈写入的主机写周期完成;
( 5 )一旦在本地控制器 NVRAM 中写入了足够多的块,并创建了数据一致性点,数据就会同时写入本地 Plex 中的本地卷和远程站点上的 Plex 镜像,待双刷盘动作完成时,将反馈本地控制器完成写同步(第二个同步动作)。
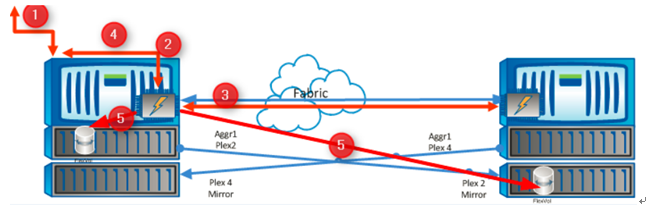
从整个 MetroCluster 方案的写 I/O 流程来看,当 NVRAM 缓存充足时,两个同步动作中,只有 NVRAM 同步过程会对主机写 I/O 性能产生影响( 1 倍 RTT ),但两次同步也带来写数据需要在站点间同步 2 次、数据同步效率不高的影响,并且将占用更大网络带宽;当 NVRAM 缓存出现瓶颈时,两次同步的性能影响将被放大,造成主机写 I/O 2 倍 RTT 以上的性能影响。另外值得一提的是,本地两个 HA Pair 控制器间是走的外部 FC 网络(控制器拉开都是该方式),而不是两个控制器物理封装在一起时,通过高速 PCIE3.0 通道通讯,在极限并发时, FC 网络的带宽将被受考验。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞23本文隶属于专栏


作者其他文章
评论 17 · 赞 79
评论 8 · 赞 42
评论 0 · 赞 2
评论 0 · 赞 1
评论 1 · 赞 1
添加新评论7 条评论
2023-08-23 01:56
2023-08-02 20:25
2020-09-19 10:34
2020-03-20 15:22
2019-07-25 17:40
2019-07-10 12:03
2019-06-27 16:04