求助HADOOP集群上线运行数个月后,任务运行变慢的重启之外的解决方案?
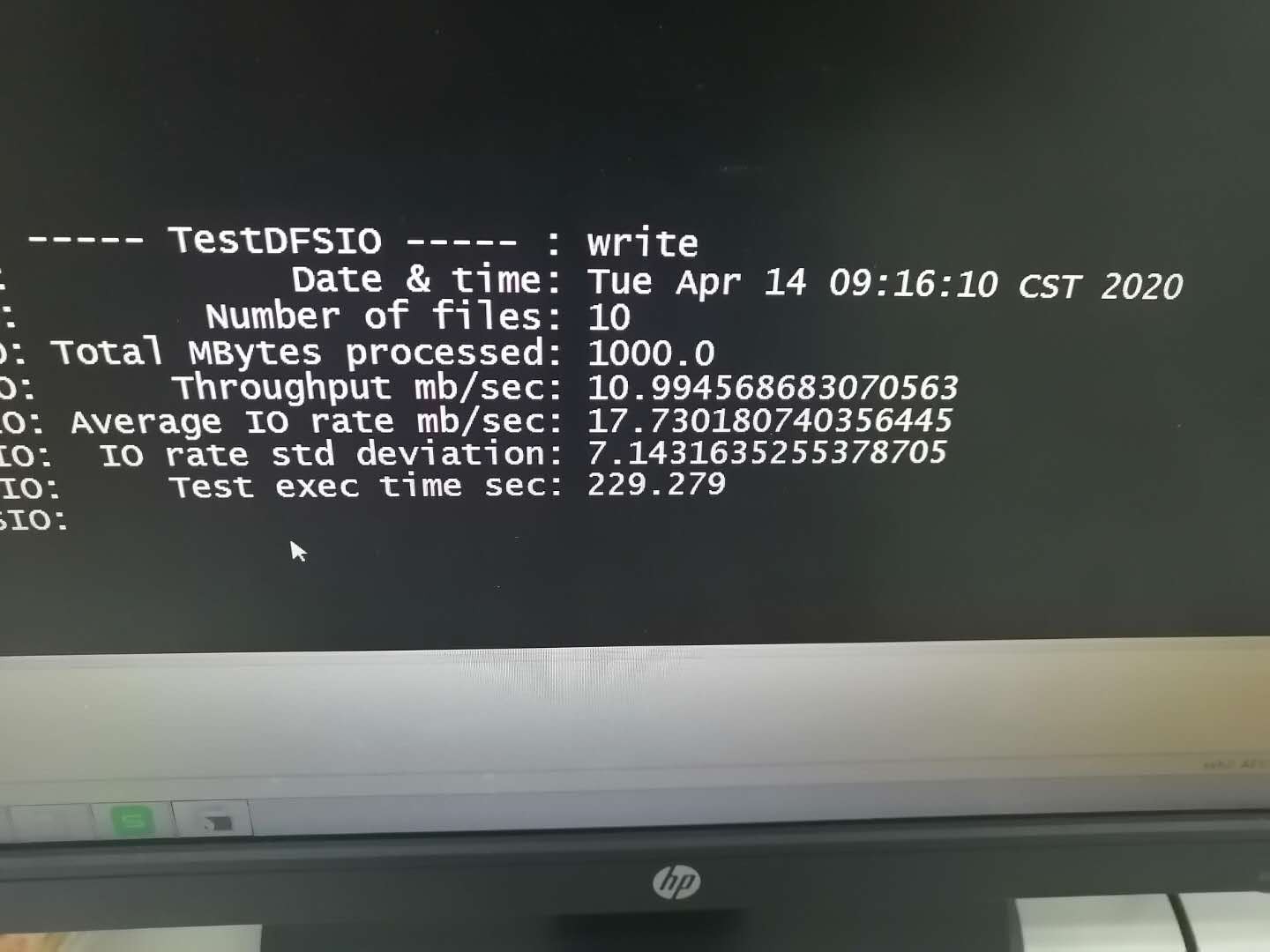
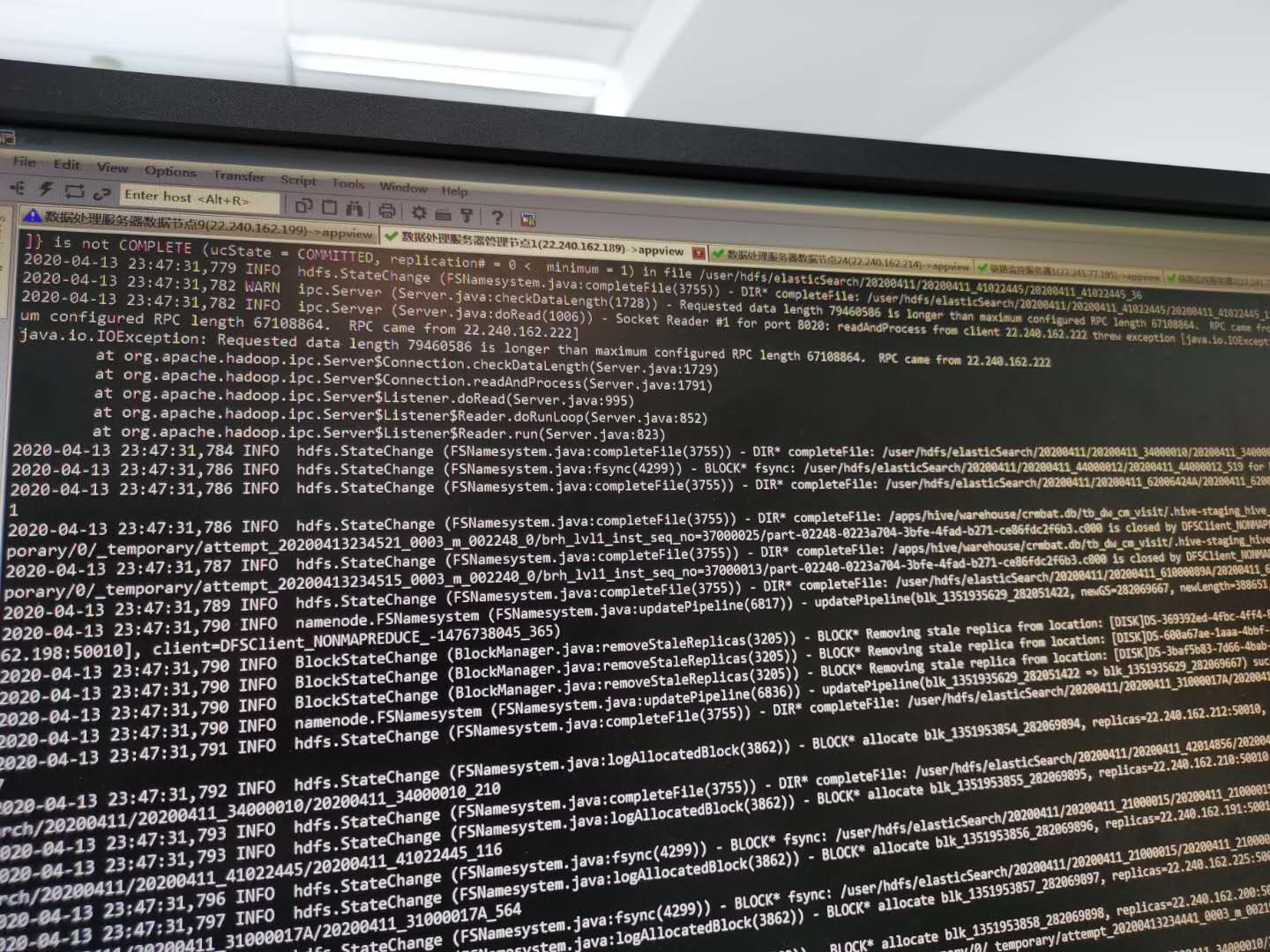
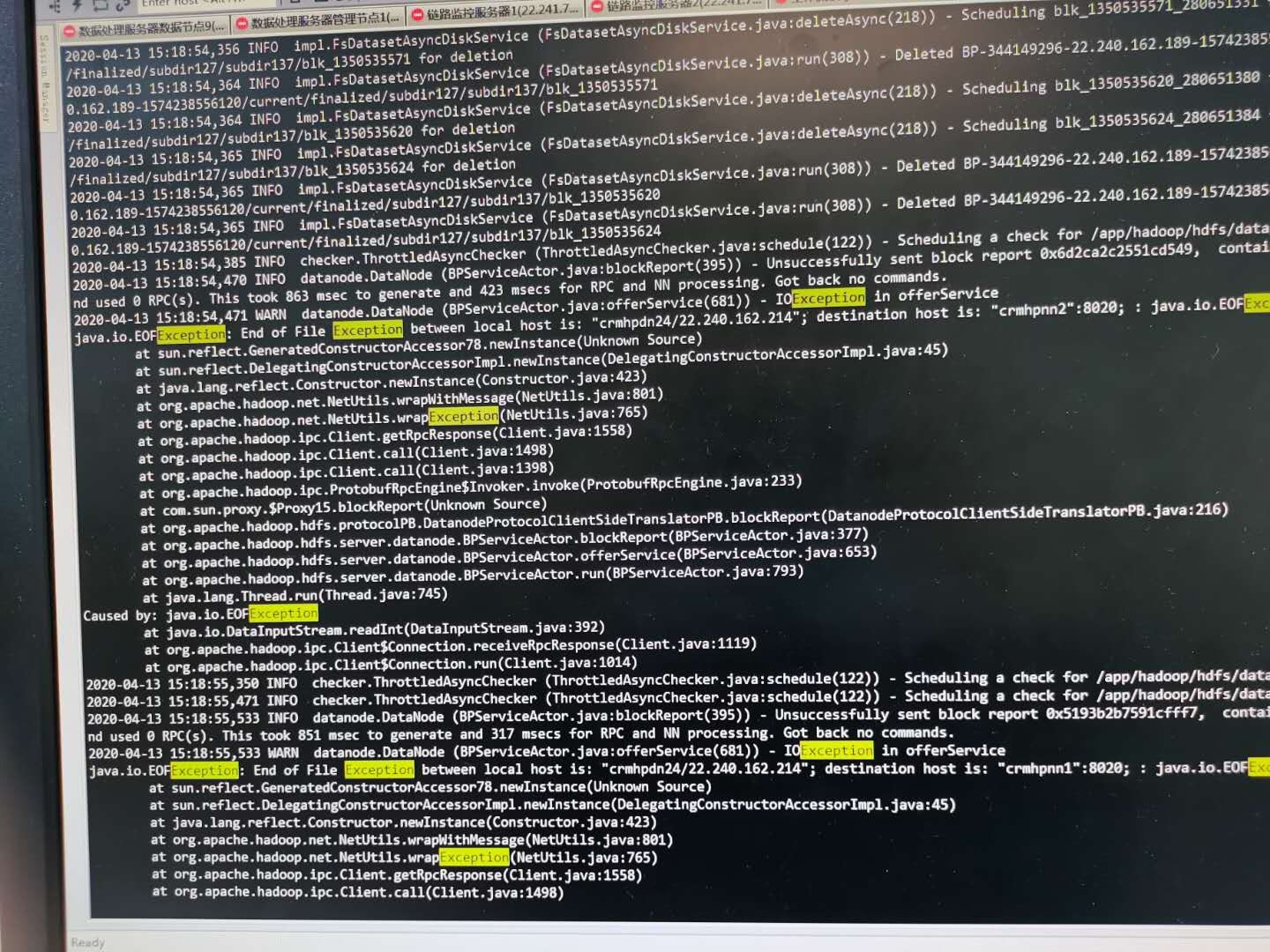
HADOOP集群上线运行数个月后,运行变得很缓慢。(集群配置 万兆网, 万兆交换机, 2个NAMENODE 33个DATANODE 2个客户端 ,机器配置 512GB,128CORE。 整个集群YARN资源 12.8TB内存,1800CORES)。 之前运行1分钟的任务,需要运行超过10分钟才能结束。甚至更长时间。对集群的IO进行了测试,发现平均IO非常的慢,只有17M。 同时在日志中发现大量的RPC消息超长。于是重启了HDFS.YARN 以及修改了 ipc.maximum.data.length的值为128M后。发现系统又恢复了正常的速度。但是不知道是不是这样就是正规的解决方式,还是只是因为重启缓解了问题,后面问题依旧还有。 求助大家给点思路。