Hadoop MapReduce作业长时间卡死问题解决方法
作者:农行研发中心 孟洋
1. 问题描述
当前,我们通过编写 Hadoop MapReduce 程序对来自上游的源数据文件进行贴源预处理加工。源数据文件发到 Hadoop 集群后,我们的预处理程序会对源数据进行编码转换、数据去重、加时间拉链、数据清洗、错误数据处理等操作,生成贴源的 ODS 层数据,供上层建模使用。
一直以来系统运行稳定,未出现过问题。但一段时间以来部分源文件的预处理作业频繁出现作业长时间卡死的问题,导致 Hadoop 集群资源被长时间占用,其他作业因资源不足而无法正常调起,影响了预处理加工的时效性。对此我们从各方面进行了分析和处理,具体过程如下。
2. 问题分析
2.1. 数据倾斜可能性分析
当问题出现时,我们首先考虑到可能是因为数据倾斜问题导致了作业长时间卡死的现象。于是我们首先检查 YARN 控制台的作业信息如图 2-1 :

图 2-1 YARN 控制台 reduce 任务运行情况
从上图可以看到有大量的 reduce 任务长时间运行,而非少部分 reduce 任务长时间运行。数据倾斜的典型现象是大部分 reduce 任务执行时间较短,只有很少的 reduce 任务长时间运行,可以说上图反映的情况与数据倾斜并不完全相符,同时,我们也对 MR 程序处理的源数据文件进行了按 Key 值分组计算,发现并未有数据分布不均衡的情况,因此我们排除了因数据倾斜导致作业卡死的可能性。
2.2. Hadoop 集群组件状态分析
通过查看 Hadoop 集群 UI 页面上各组件状态以及查看 NameNode 、 DataNode 、 ResouceManager 等系统服务日志信息,可以确认集群及各组件没有问题,运行正常,从而排除因集群本身问题导致作业卡死。
2.3. 日志分析
我们发现这些长时间运行的作业都是卡死在 reduce 阶段,有大量 reduce 任务卡在 27%-30% 进度不再运行,如图 2-1 所示。同时也有部分 map 任务和 reduce 任务失败。于是我们查看了该作业的如下日志信息:
1 )通过 yarn -logs 获取的 job 日志:
2019-03-23 03:39:36,727 INFO [communication thread] org.apache.hadoop.mapred.Task: Communication exception: org.apache.hadoop.ipc.RemoteException(java.io.IOException): com.google.protobuf.UninitializedMessageException: Message missing required fields:
at com.google.protobuf.AbstractMessage$Builder.newUninitializedMessageException(AbstractMessage.java:770)
at org.apache.hadoop.yarn.proto.YarnProtos$ApplicationIdProto$Builder.build(YarnProtos.java:2750)
at org.apache.hadoop.yarn.api.records.impl.pb.ApplicationIdPBImpl.build(ApplicationIdPBImpl.java:72)
at org.apache.hadoop.yarn.api.records.ApplicationId.newInstance(ApplicationId.java:52)
...
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2049)
at org.apache.hadoop.ipc.Client.call(Client.java:1475)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.WritableRpcEngine$Invoker.invoke(WritableRpcEngine.java:242)
at com.sun.proxy.$Proxy11.statusUpdate(Unknown Source)
at org.apache.hadoop.mapred.Task$TaskReporter.run(Task.java:762)
at java.lang.Thread.run(Thread.java:745)
2019-03-23 04:25:36,892 WARN [communication thread] org.apache.hadoop.yarn.util.ProcfsBasedProcessTree: Error reading the stream java.io.IOException: 没有那个进程
2019-03-23 05:42:00,214 WARN [communication thread] org.apache.hadoop.yarn.util.ProcfsBasedProcessTree: Error reading the stream java.io.IOException: 没有那个进程
2 ) job 对应的容器日志为如图 2-2 和图 2-3 所示

图 2-2 异常作业容器信息 1

图 2-3 异常作业容器信息 2
3) 失败 map 任务日志: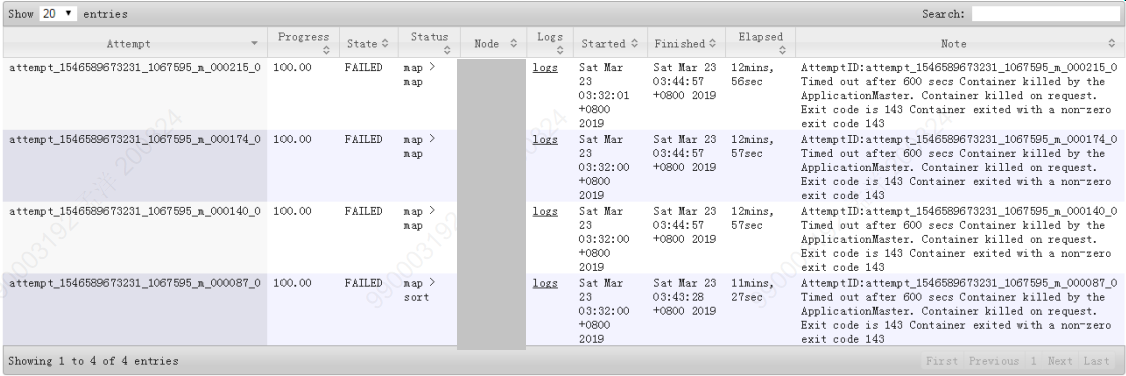
图 2-4 失败 map 任务日志
4) 失败 reduce 任务日志: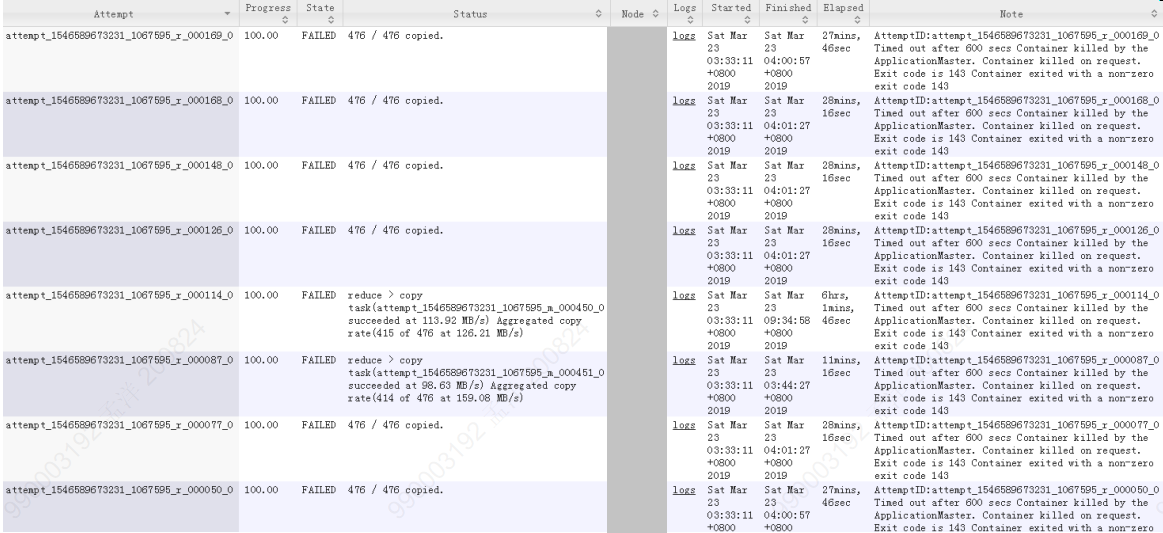
图 2-5 失败 reduce 任务日志
5) 长时间卡死的 reduce 任务的 syslog 日志:
2019-03-23 05:46:00,502 WARN [communication thread] org.apache.hadoop.yarn.util.ProcfsBasedProcessTree: Error reading the stream java.io.IOException: 没有那个进程
6) 长时间卡死的 reduce 任务的 syslog.shuffle 的日志 :
2019-03-23 03:33:50,005 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1546589673231_1067595_r_000184_0: Got 2 new map-outputs
2019-03-23 03:33:50,006 INFO [fetcher#22] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: assigned 1 of 1 to HQxPSL-nDBRS-D24:13562 to fetcher#22
2019-03-23 03:33:50,006 INFO [fetcher#25] org.apache.hadoop.mapreduce.task.reduce.Fetcher: for url=13562/mapOutput?job=job_1546589673231_1067595&reduce=184&map=attempt_1546589673231_1067595_m_000445_0 sent hash and received reply
2019-03-23 03:33:50,007 INFO [fetcher#22] org.apache.hadoop.mapreduce.task.reduce.Fetcher: for url=13562/mapOutput?job=job_1546589673231_1067595&reduce=184&map=attempt_1546589673231_1067595_m_000449_0 sent hash and received reply
2019-03-23 03:33:50,008 INFO [fetcher#25] org.apache.hadoop.mapreduce.task.reduce.Fetcher: fetcher#25 about to shuffle output of map attempt_1546589673231_1067595_m_000445_0 decomp: 3352710 len: 1064843 to MEMORY
2019-03-23 03:33:50,009 INFO [fetcher#22] org.apache.hadoop.mapreduce.task.reduce.Fetcher: fetcher#22 about to shuffle output of map attempt_1546589673231_1067595_m_000449_0 decomp: 3108180 len: 905688 to MEMORY
2019-03-23 03:33:50,017 INFO [fetcher#25] org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput: Read 3352710 bytes from map-output for attempt_1546589673231_1067595_m_000445_0
2019-03-23 03:33:50,017 INFO [fetcher#25] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 3352710, inMemoryMapOutputs.size() -> 417, commitMemory -> 39475529, usedMemory ->45936419
2019-03-23 03:33:50,017 INFO [fetcher#25] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: HQxPSL-nDBRS-D87:13562 freed by fetcher#25 in 12ms
2019-03-23 03:33:50,017 INFO [fetcher#22] org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput: Read 3108180 bytes from map-output for attempt_1546589673231_1067595_m_000449_0
7) 长时间卡死的 reduce 任务的进程栈
Thread 77915: (state = BLOCKED)
- java.lang.Object.wait(long) @bci=0 (Interpreted frame)
- java.lang.Object.wait() @bci=2, line=503 (Interpreted frame)
-org.apache.hadoop.ipc.Client.call(org.apache.hadoop.ipc.RPC$RpcKind, org.apache.hadoop.io.Writable, org.apache.hadoop.ipc.Client$ConnectionId, int, java.util.concurrent.atomic.AtomicBoolean) @bci=91, line=1466 (Interpreted frame)
-org.apache.hadoop.ipc.Client.call(org.apache.hadoop.ipc.RPC$RpcKind, org.apache.hadoop.io.Writable, org.apache.hadoop.ipc.Client$ConnectionId, java.util.concurrent.atomic.AtomicBoolean) @bci=7, line=1412 (Interpreted frame)
-org.apache.hadoop.ipc.WritableRpcEngine$Invoker.invoke(java.lang.Object, java.lang.reflect.Method, java.lang.Object[]) @bci=61, line=242 (Interpreted frame)
- com.sun.proxy.$Proxy11.getMapCompletionEvents(org.apache.hadoop.mapred.JobID, int, int, org.apache.hadoop.mapred.TaskAttemptID) @bci=35 (Interpreted frame)
- org.apache.hadoop.mapreduce.task.reduce.EventFetcher.getMapCompletionEvents() @bci=33, line=120 (Interpreted frame)
- org.apache.hadoop.mapreduce.task.reduce.EventFetcher.run() @bci=56, line=66 (Interpreted frame)根据上述日志进行如下分析:
( 1 ) job 日志中异常 1 : [communication thread] org.apache.hadoop.mapred.Task: Communication exception 。这个是任务的一种状态报告机制,当出现异常时会有重试机制(默认为 3 次)。后续没有出现异常,则说明已恢复正常,不需要关注 .
( 2 ) job 日志中异常 2 : [communication thread] org.apache.hadoop.yarn.util.ProcfsBasedProcessTree: Error reading the stream java.io.IOException: 没有那个进程。 出现该异常信息后,任务持续卡住长达 11 小时,在任务界面上依然是 running 状态,原因不明。
( 3 )失败 map 任务和失败 reduce 任务日志显示 任务超时,容器被 killed ,对应的进程退出码为 143 。 从 UI 日志截图显示的任务超过 10 分钟无响应(对应 yarn 容器配置中 mapreduce.task.timeout=10 分钟 ) 而被 kill 掉。该情况通常发生在任务高并发、 IO 竞争激烈的场景下,考虑优化超时时间、容器内存配置等参数。但该问题不是导致作业卡死的原因,如果超长 reduce 任务可以超时被 kill 也不会出现本文之前描述的情况。
( 4 )对于 长时间卡死的 reduce 任务的 syslog 日志中“ IOException: 没有那个进程”异常,一般是读取“ /proc/meminfo ”、“ /proc/cpuinfo ” 等本地文件时出现,正常情况下任何用户都可以访问这些文件,初步诊断为可能是没有更多的文件描述符来打开 /proc/ 下对应进程文件的信息。 通过“ ulimit -n ”查询发现所有的节点配置所有用户对应的打开文件数为 100000 ,在系统繁忙时可能有些偏少,后续考虑提升至 150000 。但这不是导致作业卡死的原因。
( 5 )通过查看 长时间卡死的 reduce 任务的 syslog.shuffle 日志,可以发现对应的 shuffle 任务在较短的时间内就处理了大量的 map 结果,但是 shuffer 任务本身日志中并没有报错,呈现任务卡死现象,原因不明。
( 6 )因上述日志没有查到任务长时间卡死的线索,我们又查了卡死 reduce 任务进程的堆栈信息,从堆栈信息中,我们发现 reduce 任务获取 map 任务完成事件的线程状态是阻塞,也就是说 reduce 任务在等待 map 任务完成的信号但一直没收到,而事实上该 job 的所有 map 任务都已经完成,这导致整个作业卡死,在高并发情况下会偶现这种情况。之所以 reduce 没有触发超时 kill 机制是 reduce 任务的 ping 心跳发送本身并没有异常,而事件获取线程也并未退出(若因异常退出,会直接导致 reducetask 异常而重跑任务)。我们进一步查了 job 的如下三个参数:
ipc.client.ping=true
ipc.ping.interval=60000
ipc.client.rpc-timeout.ms=0
因设置了基于 TCP 的 Socket 的网络超时时间,当任务节点读取数据时发生 SocketTimeoutException 时,会自动的向服务器端发送 ping 包,来测试当前客户端与服务器端的连接是否正常,对应的参数为 ipc.ping.interval (默认为 60000ms) 。 ipc.client.rpc-timeout.ms 是 RPC 客户端等待相应的超时时间值,当参数的值为 0 时,在远程方法调用没有接受到数据的情况下,只要 ping 服务正常,就不会超时,而只会按 ipc.ping.interval 时间间隔不停发出 ping 服务,如果有 ipc.client.rpc-timeout.ms>0, 该时间内未收到远程方法返回的数据即超时,随即停止发送 ping 服务,从而可以有效避免卡死。当前集群 ping 发送机制是打开的,每 1 分钟定期向服务器发送 ping 服务,但是超时时间设置为 0 ,即永不超时,会一直处于读取 map 数据的阶段,这也就是 AM 一直认为该 reduce 任务还活着而没有按照任务超时机制将其 kill 。这样问题的核心原因基本找到了。
2.4. 作业运行外围情况分析
在分析日志的同时,我们也关注了作业卡死时段的其他外围情况:
1) 有大量作业在该时段被调起;
2) 近期集群进行了扩容,正在进行数据均衡操作中,节点间 IO 竞争激烈;
3) 鉴于 hadoop 的任务分配原则(本地数据优先,计算在数据所在节点上进行的原则),在任务高峰期,某些节点 IO 竞争激烈,会导致任务超时现象发生。
2.5. 分析小结
综上,可以得到如下结论:
1) ipc.client.rpc-timeout.ms=0 参数设置不合理,无超时退出机制,导致在高并发、 IO 竞争激烈的场景下,触发了任务长时间卡死的问题;
2) 节点文件描述符数偏低,导致任务执行中出现“ IOException: 没有那个进程”异常;
3) 超时时间、容器内存配置等参数不够优化,导致部分任务超时失败退出,影响 job 执行;
4) 大量作业并发和数据均衡操作一定程度上加剧了 IO 的竞争程度,间接触发了卡死问题的出现。
其中 1 )是产生问题的主要因素。
3. 问题解决
问题原因找到就好制定处理方案了,我们通过控制作业并发、降低数据均衡操作带宽和调整如下集群参数来解决问题:
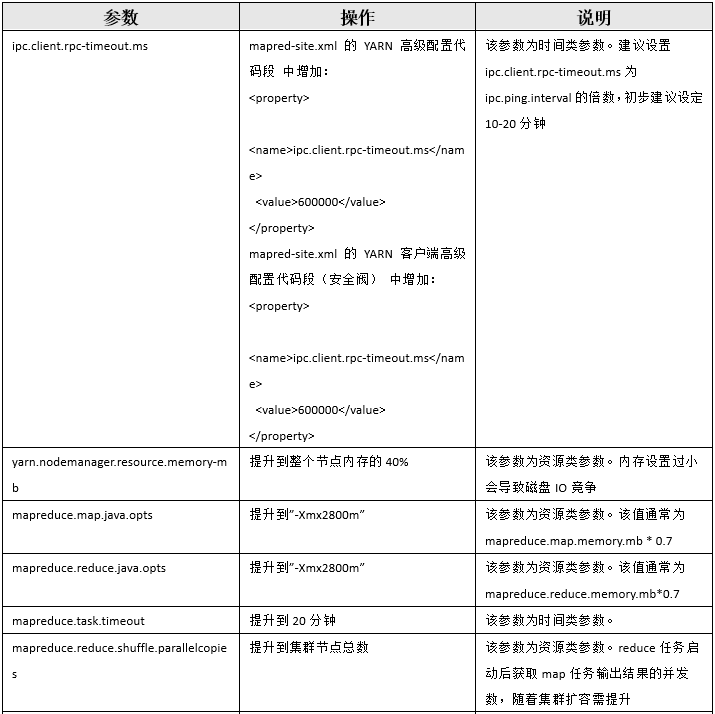
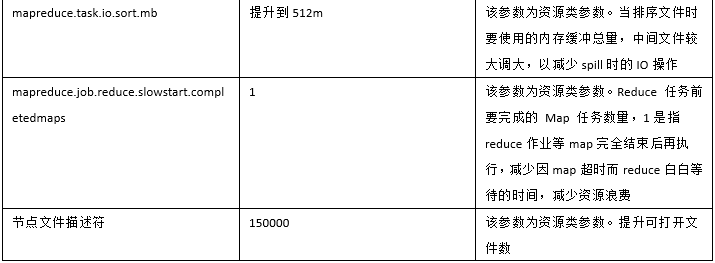
上述操作执行后,问题得到解决。
经过此次问题处理,我们也总结了一套针对 Hadoop 程序长时间执行问题的解决思路:
1 、首先检查是否有数据倾斜,因为大部分情况下是由这个原因引发 Hadoop 程序长时间执行问题。数据倾斜的典型现象是大部分 reduce 任务执行时间较短,只有很少的 reduce 任务长时间运行,同时某个 key 对应的数据比其他 key 对应的数据多很多,一旦出现上述情况就可判断是出现数据倾斜情况,需要对 key 值特别多的数据进行单独处理,比如在 key 上加随机数把数据打散,使得数据尽可能的平均 shuffle 到各 reduce 节点上,充分利用各节点的算力。
2 、如果未出现数据倾斜的情况,那就需要先检查集群各主要组件的运行情况,如 HDFS 、 YARN 、 Spark 、 Hive 等,确认各组件是否正常,有相当一部分 Hadoop 程序长时间执行问题由组件运行问题引起。一般通过查看 Hadoop 集群 UI 页面上各组件状态和查看各组件系统日志来判定组件运行是否有问题。
3 、如果上述两项均无问题,我们就需要针对日志进行更为细致的分析了,重点需要查看 job 日志、容器日志、 map 和 reduce 节点日志、以及 map 和 reduce 任务的进程栈,尤其是任务的进程栈对一些疑难问题的分析解决有很大帮助。一般到这一步引起超时问题的原因就很多了,需要具体问题具体分析,但我们不妨重点检查是否是相关超时参数设置不合理导致,如以下参数
| 参数 | 用途 | 推荐值 |
|---|---|---|
| mapreduce.task.timeout | 当任务既未读取输入值,又未写入输出值,也未更新其状态字符串时即将终止该任务之前的毫秒数。 | 10-20 分钟 |
| ipc.client.rpc-timeout.ms | IPC 服务中等待服务器响应的时间 | 建议设置 ipc.client.rpc-timeout.ms 为 ipc.ping.interval 的倍数,初步建议设定 10-20 分钟,不建议为 0 (永不超时) |
以上思考仅供参考,希望对大家解决问题有所帮助 。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 2
评论 0 · 赞 7
评论 0 · 赞 1
评论 0 · 赞 1
评论 0 · 赞 5
添加新评论0 条评论