金融业分布式数据库:SequoiaDB、GoldenDB、OceanBase等原理、POC性能对比及选择是怎样的?
以上三种数据库大家都多少有了解,也是在金融业都有实践的,可能很多金融业朋友选择分布式数据库的时候都会接触以上三个数据库中的一个或几个。
不知道是否有银行通过POC测试测试过其中的数据库?测试数据又是怎样的呢?还望不吝讲解一番,一下几点我想是有不少人所关心的问题:
1、分布式的实现,是通过中间件实现分布式,还是源码级别引入分布式算法实现的?
2、分布式事务支持以及在超大事务下的性能下降幅度?
3、大查询(亿级)下各数据库的性能如何?
4、对于从Oracle平迁至分布式数据库,除去存储过程等力不可抗拒因素外,其他的难度如何?有无便于使用的平迁工具?
5、分布式部署的高可用性:节点挂掉的数量对整个集群的服务能力、处理性能影响是怎样的?
6、集群增加节点后,对于整个集群的影响有哪些?增加节点后的数据平迁是否会对业务造成较大的影响?
7、搭建完成后,对于DBA运维来讲,各家有无工具能便于运维的条件?
若有实践过的,遇到同样问题的朋友,还望不吝赐教,感谢,感谢。
10同行回答

谈谈个人对分布式数据库选型的理解吧。我觉得使用分布式数据库的根本原因就两点。
一是高可用,数据分片后不容易出现全局故障,即便有单点故障,顶多影响部分数据和业务。另一个是性能扩展,因为单点性能容量有限,面对互联网交易,手机交易的大并发访问,单点数据库可能会遇到性能问题。
然而对于金融行业来说,为了这两点选择的分布式数据库,还得具备单数据库的基本功能,例如pitr,分布式事务,读写一致性等。而这些基本功能,众多分布式数据库基本都是通过设置全局事务号来搞定的。如果是基于客户端的分布式数据库,其实是做不到这一点的。所以基于客户端的分布式数据库只能应用在有限的场景下,需要应用开发支持才行。而也正因为如此,基于客户端的分布式性能是最好的,基本没有损耗。
客户端模式局限多不适合,那么就要考虑这些国产的分布式数据库产品了,我想把这些归为中间件式的分布式数据库。例如华为高斯,阿里ob,antdb,巨杉,tidb等等。这些数据库功能最齐全,支持强一致性的话都设置了全局控制组件,例如gtm,全局事务管理器,然后一大堆的数据节点,加上提供链接的协调节点。几乎所有这些分布式产品都是这么干的。也有些另类的例如基于分布式一致性协议,但是性能和整体功能兼容性都会差很多。
我们测了很多分布式数据库产品,结果在这里暂时不能透露,只说说我们测试会关注的点。一是高可用,关注每个组件故障回复时间,尤其是全局影响时间。还有就是单点事务性能和分布式的跨节点事务性能,读写强一致性。这个方面数据库差异特别大,因为有全局组件的原因,分布式数据库处理能力最终上限也会出现在这里,不可能无限扩展的,这与我们需要的性能扩展是相悖的,有些产品甚至还不如单机性能好。最后是混合型场景htap。因为任谁也不能保证自家的应用就是oltp没点复杂查询什么的,因此复杂查询的支持也需要验证。我想大家在测试的时候把这几点测到,基本上就有答案了。
分布式数据库属于新产品,尤其是集群类型的,虽然测好了单点故障,但是全局故障会不会有问题谁也说不好。因此pitr必须得有,额外保护也得考虑。建议将数据想办法同步一份到集群外面来,以防万一。
最后说说迁移。几乎所有的分布式数据库在做产品的时候都会考虑兼容性,但是事实上都做不到百分百的兼容。因此工作量还是有的,既然选择了,就不用太考虑工作量。平时也是做好对数据库告警功能或者特色功能使用的控制,尽量只使用数据库的基本功能,不要写一堆存储过程什么的,减少对数据库产品的依赖性。
谈点个人理解:
1)POC测试:
SequoiaDB、OceanBase在金融行业都已经有大量用户了。
2)分布式数据库技术发展体系对比:
SequoiaDB和OceanBase都是原生分布式数据库。GoldenDB是MySQL基础之上自研分布式中间件。
3)分布式事务及性能:
对于分布式数据库,分布式事务支持都是难点和重点。
SequoiaDB和OceanBase作为原生分布式数据库,对于分布式事务支持比较好。GoldenDB作为分布式中间件,对于分布式事务支持比较难,特别是强一致性的支持比较难以做到,效率和性能更是问题。
SequoiaDB和OceanBase都有事务开关,可以参数化配置。
对于分布式事务的性能,一般都是通过底层数据布局来把控的。如果分布式事务涉及的数据在同一个数据节点或者相邻数据节点,分布式事务性能就比较好。所以,结合业务特点来合理规划和设计底层数据布局很重要。
4)大查(亿级)下各数据库的性能:
传统集中式数据库在大查(亿级)下各数据库的性能都是很好的,关键看你的数据库逻辑设计和物理设计的如何。
分布式数据库大查(亿级)下各数据库的性能应该更好,同样关键看你的数据库逻辑设计和物理设计的如何。
从数据库引擎设计来看,SequoiaDB对于非结构化数据的查询性能应该很好。
5)对于从Oracle平迁至分布式数据库:
OceanBase正在研制Oracle兼容性,OceanBase团队也请了Oracle出来的一些技术人员在专门搞这个兼容性和迁移。
从理论和实践来看,Oracle数据迁移到OceanBase应该没有问题,但是Oracle存储过程迁移到OceanBase应该比较难。当然,我们也可以变换一个角度来思考这个问题,为什么一定要原样迁移,毕竟是2套完全不同技术系统的东西,能够做到数据迁移就足够了;代码迁移必然遇到sql语法兼容性问题,即便没有sql语法兼容性问题,访问计划也是必然是不同的,从而运行效率也无法保障。
6)分布式部署的高可用性、集群增加节点等都是分布式本身要解决的核心问题,所以SequoiaDB和OceanBase等原生分布式数据库都能够比较好的解决这些问题。不过,不同分布式数据库产品之间可能存在成熟性的差异,相对来说,OceanBase这些方面会做得比较成熟。
7)DBA运维工具:这个方面,SequoiaDB应该更胜一筹,SequoiaDB应该具备工业级(industry-level)运维工具。
8)中国自研分布式数据库比较多,例如:SequoiaDB、OceanBase、GAUSSDB、TIDB、GoldenDB、HOTDB等等。
9)从分布式数据库的研发团队和技术基因来看,SequoiaDB、OceanBase、GAUSSDB都是未来前景很好的原生分布式数据库。
收起1、分布式的实现,是通过中间件实现分布式,还是源码级别引入分布式算法实现的?
解答:
(1) 分布式数据库 是至少由 计算节点、存储节点、管理平台、备份还原程序 四个部分组成,从数据库系统理论知识上说分成:全局自治 和场地自治 ,也粗略认为: 全局可理解为计算节点、场地可理解为存储节点
(2)这个问题的标题 “中间件实现分布式 还是源码级别引入分布式算法” 这个说法存在误导性,修改为 : 存储节点自主研发数据库存储引擎 还是采用 市场上存在的数据库产品为数据库存储引擎。只要知道通信协议,存储节点可以是任何集中式数据库产品
(3)存储节点自主研发:SequoiaDB、OceanBase 是属于自主研发数据库存储引擎
(4)存储引擎采用已有数据库产品:TiDB(存储引擎是开源KV的RocksDB)、HotDB(MySQL开源数据库,从知识产权能看寻到自主研发的存储引擎HotDB Engine)、GaussDB T(PostgreSQL开源数据库)、GoldenDB( MySQL开源数据库 )、TDSQL( MySQL开源数据库 )
2、分布式事务支持以及在超大事务下的性能下降幅度?
解答:
(1) 超大事务下的性能下降幅度
采用sysbench的方式太简单了,意义不大。这个问题需要采用相同的硬件环境、数据环境、业务场景,对比测试才能回答。信通院正组织厂商在测试模拟银行传统核心业务场景的性能测试。另外,从网络上拿到的信息:6000万账户基础数据、每笔业务96条SQL(也即一个数据库事务是96条SQL组成)、随机两个账户转账,HotDB 能做到 12000笔 转账业务 /秒、平均响应时间 78毫秒/笔转账业务、成功率100%;TiDB能做到 2200笔 账业务 /秒、平均响应时间 315毫秒/笔转账业务、成功率99.3%
( 2) 分布式事务支持
分布式事务支持分成两块:采用NOSQL架构的 乐观锁 还是 集中式数据库的 悲观锁、分布式事务等同集中式数据库的能力。如下:
(2.1) 采用NOSQL架构的 乐观锁 的产品:SequoiaDB、GoldenDB、TiDB
(2.2) 采用 集中式数据库的 悲观锁 的产品:OceanBase、HotDB、GaussDB T
(2.3) 分布式事务等同集中式数据库的能力 : OceanBase和 HotDB 完全等同 集中式数据库 的事务能力,其他产品都需要借助 “管理协调节点”来完成,所以在事务透明、实时一致等方面存在困难,还无法等同。
3、大查询(亿级)下各数据库的性能如何?
解答:这个看是否复杂JOIN,还只是简单SELECT,对于基于NOSQL技术架构的TiDB、 SequoiaDB在数据分析方面占优,OceanBase、HotDB、 GoldenDB等其他产品基本上只专注OLTP业务场景。
4、对于从Oracle平迁至分布式数据库,除去存储过程等力不可抗拒因素外,其他的难度如何?有无便于使用的平迁工具?
解答:主要是要修改只有Oracle才有的SQL特性、函数等,现在 GoldenDB在做深入兼容Oracle,HotDB、 GoldenDB能兼容函数、序列等基础SQL语法而已。
5、分布式部署的高可用性:节点挂掉的数量对整个集群的服务能力、处理性能影响是怎样的?
解答:分布式数据库产品的高可用性 需要看这个产品由那几部分组件构成及参与业务系统的数据服务的组件模块,例如如下
(1)HotDB:参与业务系统的数据服务必备组件为 计算节点(负责全部的SQL语句执行、事务控制、存储节点存活探测、高可用切换、死锁检测、死锁解除等)、存储节点(负责数据存储、场地SQL执行)
(2)GoldenDB:参与业务系统的数据服务必备组件为 计算节点 (负责全部的SQL语句执行 )、存储节点 (负责数据存储、场地SQL执行) 、管理协调节点(负责分布式事务等)、管理节点(负责存储节点存活探测、高可用切换等)
(3)TiDB: 计算节点 (负责全部的SQL语句解析、转发 等)、存储节点 (负责数据存储、场地SQL执行) 、管理协调节点(负责分布式事务、 存储节点存活探测、高可用切换 等)
.............................其他类似
所以一款产品每个组件都必须无单点,且确认组件是否属于有状态的,对有状态的组件因涉及全局信息同步故是要特别对待的,例如:HotDB的计算节点是有状态、 TiDB 管理协调节点 PD 是有状态 等
6、集群增加节点后,对于整个集群的影响有哪些?增加节点后的数据平迁是否会对业务造成较大的影响?
解答:
(1) TP业务 跟AP业务在集群增加存储节点 对业务的影响是不同,或 增加计算节点类似
(2 ) TiDB、 SequoiaDB、OceanBase、HotDB、 GoldenDB在增加计算节点时对业务无影响
(3) TiDB、 SequoiaDB、OceanBase 、 HotDB 在增加存储节点时对业务无影响, GoldenDB 暂不清楚
7、搭建完成后,对于DBA运维来讲,各家有无工具能便于运维的条件
解答:从各家对外发布的信息看,HotDB产品在运维工具方面或者说产品化方面做最好,其次是 OceanBase .....微信群里看到的两张HotDB产品截图如下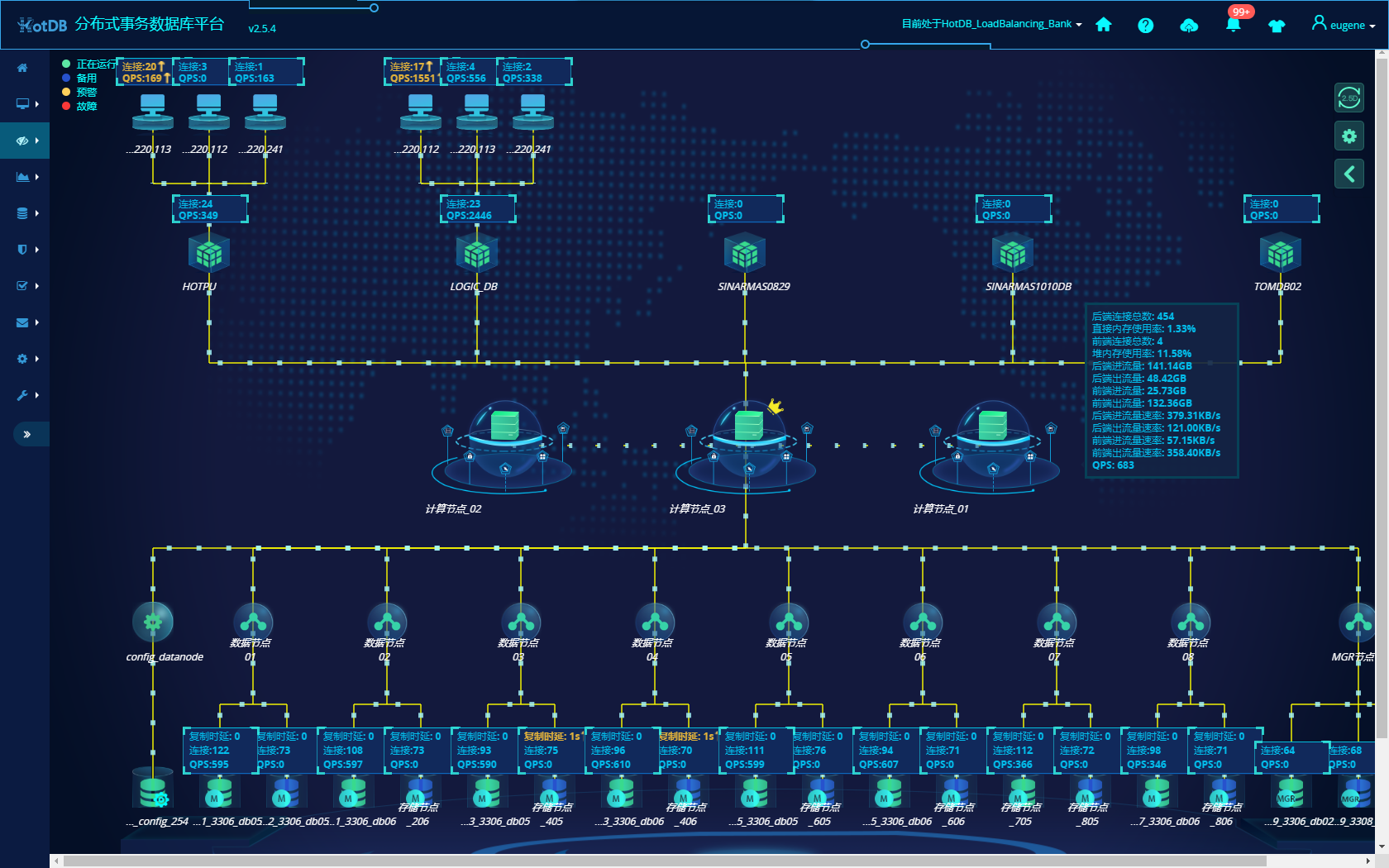
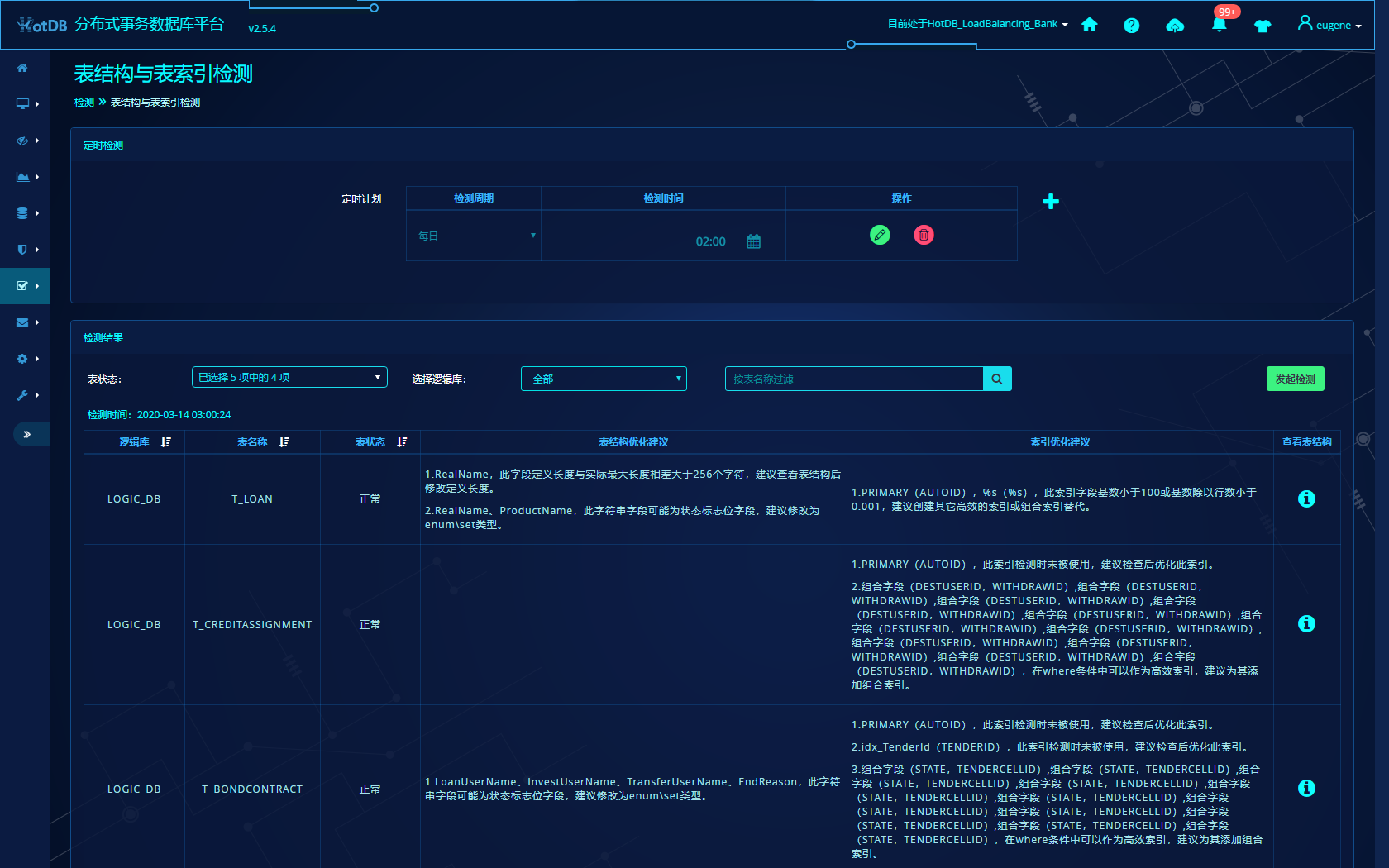
一.说一下产品概述
1)SequoiaDB:创始团队主要来自 DB2,原定位于非结构化数据, 更多案例是 OLAP,最近几年开始研发 OLTP
2)GoldenDB:和中信银行联合研发,基于 MySQL + 中间件的模式
3)OceanBase:阿里完全自研的代码
二.问题解答
1、分布式的实现,是通过中间件实现分布式,还是源码级别引入分布式算法实现的?
分布式的实现是指什么呢?如果是指技术路线,那么 GoldenDB是“中间件+MySQL”,SequoiaDB和OceanBase是源码级别;
2、分布式事务支持以及在超大事务下的性能下降幅度?
分布式事务的支持是分布式数据库的基本选项,由于涉及多个资源协调必然会下降。但是下降多少,与业务逻辑密切相关。
3、大查询(亿级)下各数据库的性能如何?
大数据是指“单条语句查单条记录”还是“单条语句查多条数据",不论任何情况,肯定是与业务相关。
4、对于从Oracle平迁至分布式数据库,除去存储过程等力不可抗拒因素外,其他的难度如何?有无便于使用的平迁工具?
每家公司都在尽量研发迁移工具,语法不是难度,只是工作量,难度在于数据分布模式的确认,只有合理的分布才可以提升性能,避免数据分布导致的性能下降
5、分布式部署的高可用性:节点挂掉的数量对整个集群的服务能力、处理性能影响是怎样的?
分布式数据库运行在开放平台,每个节点故障的可能性都很大,所以必然是保证功能正常。服务能力的 RTO 一般会分钟级,RPO =0,不影响整个的处理性能
6、集群增加节点后,对于整个集群的影响有哪些?增加节点后的数据平迁是否会对业务造成较大的影响?
增加节点就是为了提升性能,不然没有意义。增加节点后的数据重分布肯定会考虑对业务的影响,一般是在业务低峰期做
7、搭建完成后,对于DBA运维来讲,各家有无工具能便于运维的条件?
由于涉及多个节点,不仅仅搭建完,在整个搭建过程中必须有统一运管平台。