一文读懂基于eBPF自动化可观测平台 - DeepFlow
今天我们来聊一下云原生生态核心技术——基于 eBPF 全链路自动化可观测性。当我们真正融入到云原生生态场景中时,我们将会深切地体会到:“全链路可观测性”的价值所在~
在过去,要以安全、非侵入的方式从整个系统收集遥测数据通常较为困难,我们需要许多产品、应用程序级代理和复杂的配置操作。然而,随着基于 eBPF 的项目数量不断增加,现代基础设施为中心的云原生社区对其产生了极大的兴趣,使得 eBPF 在 2022 年和 2023 年经历了巨大的增长。
这种增长促使一些最优秀的软件工程公司聚集在一起成立了 eBPF 基金会,以致力于引导和维护 eBPF 标准和愿景的技术。因此,eBPF 正在迅速成为现代软件基础设施领域中日益普遍的技术,其中可观测性领域是其主要用例之一。
什么是 eBPF 以及为什么需要?
在之前的文章中,我们针对 eBPF 的概念及体系有过简要的解析,大家有兴趣可参考如下文章:

eBPF, (全称为 “extended Berkeley Packet Filter”)是一种内核技术,可以使用户空间程序在不需要修改内核代码的情况下,通过加载 eBPF 程序来拦截和处理内核事件。这种技术可以用于实现各种功能,例如网络过滤、性能分析、安全审计等。
历史上,由于内核具有监控和控制整个系统的特权能力,操作系统一直是实现可观测性、安全性和网络功能的理想场所。然而,由于操作系统内核的核心地位以及对其稳定性和安全性的高要求,其演化难度较大,导致与操作系统外部实现的功能相比,操作系统级别的创新率传统上较低。
因此,eBPF 技术的出现为内核级别的可观测性、安全性和网络功能提供了一种全新的方法。通过 eBPF,用户可以在运行时向内核注入代码,并在内核中运行,从而实现高效的监控和诊断功能,而且无需修改内核源代码或加载内核模块。这为操作系统的可观测性、安全性和网络功能提供了更高的灵活性和创新性,从而推动了操作系统级别的创新和发展。
什么是 eBPF 可观测性 ?
eBPF 作为一种可观测性工具,具有突出的优势,因为可以在不更改源代码的情况下,执行程序并从内核中获取监控数据。eBPF 的可观测性非常安全、隔离且非侵入性,同时还可以导出到集中式平台。通过提供基础设施和网络事件的大量可见性、上下文和准确性,eBPF 增强了可观测性的能力。
那么,eBPF 是如何工作的呢?通常,eBPF 程序是用 Rust 或 C 编写的,并通过即时(JIT)编译器编译和验证代码,并将其加载到内核中。一旦程序加载到内核中,就必须将其附加到内核函数或事件上。
在每次执行相应的函数或事件时,eBPF 程序将会运行。eBPF 程序可以附加到许多事件上,例如跟踪点、函数的进入和退出、perf 事件(用于收集性能数据)、Linux 安全模块(LSM)接口、网络接口、网络套接字等等。通过这些事件,eBPF 程序可以实时收集系统的各种指标和事件,并将其导出到集中式平台,以进行进一步的分析和处理。
因此,eBPF 作为一种可观测性工具,具有强大的监控和诊断能力,并且不会对系统性能和稳定性产生负面影响。这使得 eBPF 成为现代软件基础设施领域中不可或缺的技术之一。
在可观测性方面,eBPF 可以用于实现自动化的可观测性。通过在内核中运行 eBPF 程序,可以实时收集各种内核事件的信息,并将其传输到用户空间,以便进行处理和分析。这种技术可以用于实现各种监控和诊断功能,例如网络流量分析、系统性能分析、安全审计等。
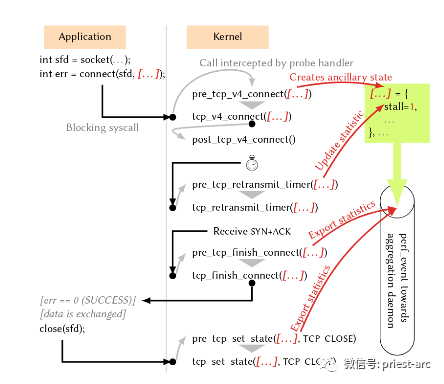
通常情况下,使用 eBPF 实现自动化的可观测性有以下优点:
1、高效性:eBPF 程序在内核中运行,可以避免用户空间和内核空间之间频繁的上下文切换,从而提高监控和诊断的效率。
2、灵活性:eBPF 程序可以捕获各种内核事件的信息,用户可以自定义eBPF程序以实现其特定需求。
3、安全性:eBPF 程序可以通过内核验证机制进行验证,从而避免恶意程序的运行。
4、可扩展性:eBPF 程序可以根据需要动态加载和卸载,从而可以在不需要重启系统的情况下进行监控和诊断。
总之,eBPF 是一种非常有用的技术,可以用于实现自动化的可观测性,从而提高系统的可靠性、可维护性和安全性。
什么是 DeepFlow ?
DeepFlow 是一个面向云原生开发人员的开源高度自动化的可观测平台,是专为云原生可观测应用开发者打造的全栈、全跨度、高性能的数据引擎。DeepFlow 借助eBPF、WASM、OpenTelemetry 等新技术,创新性地实现了AutoTracing、AutoMetrics、AutoTagging、SmartEncoding 等核心机制,帮助开发者提高代码注入的自动化水平,降低可观测平台的维护复杂度。
借助 DeepFlow 的可编程性和开放 API,开发人员可以快速将其集成到他们的可观测性堆栈中,从而实现可观测性体系的建设与推进。
基于 DeepFlow 自动化可观测平台分布式链路调用鸟瞰图,可参考如下所示:
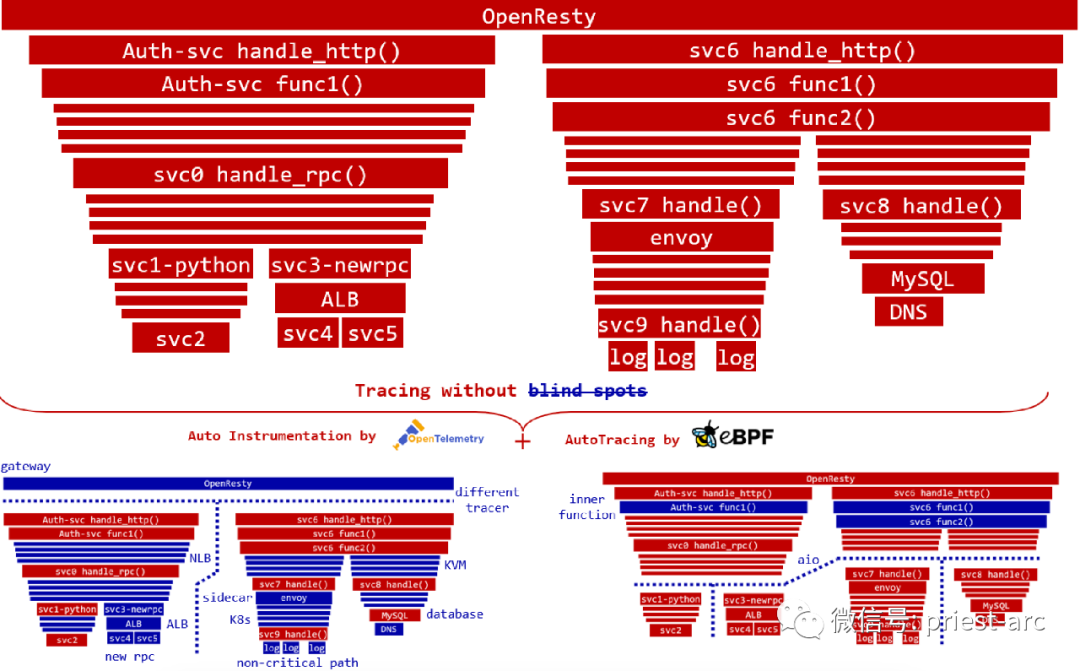
那么,与传统的可观测性平台相对比,DeepFlow 具备哪些核心优势呢?具体如下所示:
1、堆栈中立
在传统的获取性能指标的方法中,通常通过 SDK、字节码增强或手动嵌入等方式主动插入统计代码,这给需要适应各种开发语言和框架的应用开发者带来了沉重的负担。特别是在云原生环境中,手动插入代码的方式面临着更多的挑战。因为任何应用程序的调用都必须经过来自微服务、Sidecar、Iptables/Ipvs 容器网络、虚拟机Vswitch、云网络和 NFV 网关等复杂路径。
因此,在云原生环境中,建设可观测性需要覆盖从应用程序到基础设施的全栈。为此,DeepFlow 基于 eBPF 的 AutoMetrics 能力应运而生。它可以自动获取系统调用、应用函数和网络通信的性能数据,并通过 BPF 和 AF_PACKET/Winpcap 将这些能力扩展到更广泛的 Linux 内核版本和 Windows 操作系统。
DeepFlow 的 AutoMetrics 能力基于 eBPF 技术,可以在不影响系统性能和稳定性的情况下,实现自动化的性能指标收集和监测。相比于传统的手动插入统计代码的方式,这种自动化的方法可以大大减轻应用开发者的负担,同时也可以更加准确地收集性能指标,从而提供更好的可观测性和诊断能力。
总之,基于 eBPF 的 AutoMetrics 能力是一种创新的、高效的性能指标收集和监测方法,可以为云原生环境中的可观测性建设提供强有力的支持。
2、全链路
DeepFlow 不仅仅是基于 eBPF 技术。同时,通过一系列技术创新,将 eBPF Event、BPF Packet、Thread ID、Coroutine ID、Request 到达时序、TCP 发送时序等关联起来,实现高度自动化、分布式的调用链 AutoTracing 能力。
目前,AutoTracing 支持所有同步 Blocking-IO (BIO) 场景、部分同步 Non-blocking-IO (NIO) 场景,并支持内核线程调度(kernel-level threading)场景,支持追踪任意服务组成的分布式调用链。此外,通过解析请求中的 X-Request-ID 等字段,还支持 NIO 模式(如Envoy)跟踪网关前后的调用链。
通过与 OpenTelemetry 等 Span 数据源结合,这样的 AutoTracing 功能将更加完善,并且可以消除分布式调用链中的任何盲点。AutoTracing 功能可以自动收集和分析分布式服务的调用链信息,从而提供全面的可视化和监控能力。通过这种方式,我们可以了解分布式服务的整体性能,并快速识别和解决任何潜在问题,从而提高服务的可用性和稳定性。
3、高性能
DeepFlow 的 Agent 基于 Rust 语言开发,使得在处理海量 eBPF/BPF 数据时可以消耗更少的资源,通常相当于应用程序本身的 1%~5%。Rust 语言具有极高的内存安全性和接近C 的性能,特别是在内存消耗、垃圾回收等方面,比 Golang 具有显着的优势。
DeepFlow 的 Server 使用了 Golang 语言实现,实现了十倍的性能提升,可以显着降低服务器资源的消耗。在每秒写入 1M Flow 的生产环境中,Server 消耗的资源一般只占业务的1%。
总之,DeepFlow 的 Agent 和 Server 使用了不同的编程语言,分别充分利用了 Rust 和 Golang 的优势,从而实现了在处理海量 eBPF/BPF 数据时消耗更少的资源和更高的性能。这些技术手段可以为现代软件基础设施的可观测性建设提供强有力的支持,从而帮助用户更好地监控、调试和优化分布式服务的性能和稳定性。
DeepFlow 架构设计及实现原理
DeepFlow 由两个进程组成,Agent 和 Server。Agent 运行在每个 K8s 节点、虚拟机和物理裸机中,负责服务器上所有应用进程的 AutoMetrics 和 AutoTracing 数据收集。Server 运行在 K8s 集群中,提供 Agent 管理、数据标签注入、数据写入和数据查询服务。
基于其设计原则, DeepFlow 架构参考示意图如下所示:

基于上述参考架构,DeepFlow 使用 eBPF 等技术自动获取任何软件技术栈的 Request-scoped 数据,包括原始数据形式的 Request-scoped 事件、聚合后形成的 Request-scoped 指标以及关联后构建的 Trace。这些数据通常用于绘制原始请求表、服务调用拓扑和分布式调用火焰图。
除了自动获取 Request 范围的观测数据外,DeepFlow 通过 Agent 的开放能力,集成了大量其他开源 SDK 和 Agent 数据源,完全覆盖了可观测性的 Tracing、Metrics、Logging 三大支柱。DeepFlow 并不是简单地整合这些数据。独特的 AutoTagging 和 SmartEncoding 技术可以高性能、自动化地为所有观测数据注入统一的属性标签,消除数据孤岛,释放数据下钻和细分能力。
这种自动化、智能化的观测数据采集和处理方式,使 DeepFlow 可以提供全面而准确的服务性能监测和故障诊断能力。我们可以快速定位和解决任何潜在问题,从而提高服务的可用性和稳定性。同时,我们也提供了丰富的可视化和监控工具,以帮助用户更好地理解和分析观测数据。
以上为 DeepFlow 自动化可观测性平台的相关介绍,更多信息可参考官网所示:
Reference :
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3作者其他文章
评论 2 · 赞 0
评论 4 · 赞 2
评论 4 · 赞 1
评论 1 · 赞 1
评论 6 · 赞 1
添加新评论0 条评论