Keepalived -混沌测试
1. 实验背景
1.1. 什么是高可用
高可用性 HA ( High Availability )指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。 HA 系统是目前企业防止核心计算机系统因故障停机的最有效手段。
实现 HA 的方式,一般采用两台或者多台机器同时完成一项功能,比如数据库服务器,平常只有一台机器对外提供服务,另一台机器作为热备,当这台机器出现故障时,自动动态切换到另一台热备的机器。
1.2. 什么是 Keepalived
Keepalived 软件起初是专为 LVS(Linux Virtual Server) 负载均衡软件设计的,用来管理并监控 LVS 集群系统中各个服务节点的状态,后来又加入了可以实现高可用的 VRRP (Virtual Router Redundancy Protocol , 虚拟路由器冗余协议)功能。因此, Keepalived 除了能够管理 LVS 软件外,还可以作为其他服务(例如: Nginx 、 Haproxy 、 MySQL 等)的高可用解决方案软件。
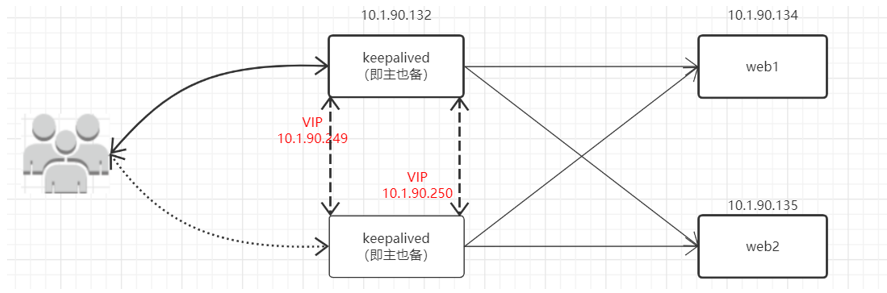
1.3. Keepalived 工作原理
Keepalived 对高可用服务之间的故障切换转移,是通过 VRRP 来实现的。在 Keepalived 服务正常工作时,主 Master 节点会不断地向备节点发送(多播的方式)心跳消息,用以告诉备 Backup 节点自己还活着,当主 Master 节点发生故障时,就无法发送心跳消息,备节点也就因此无法继续检测到来自主 Master 节点的心跳了,于是调用自身的接管程序,接管主 Master 节点的 IP 资源及服务。而当主 Master 节点恢复时,备 Backup 节点又会释放主节点故障时自身接管的 IP 资源及服务,恢复到原来的备用角色。
Keepalived 的作用是检测服务器的状态,当服务器宕机或工作出现故障, Keepalived 将检测到并将服务器集群中剔除,选择其他服务器代替该服务器的工作;当服务器恢复工作正常, Keepalived 检测到自动将服务器加入服务器集群。
1.4. 实验对象:
Keepalived 高可用中间件
2. 实验 内容
2.1. 停止服务故障
2.1.1. 实验场景:
某业务中,有一部分使用 keepalived+LVS 的高可用群集,调度器两台, web 站点采用 Nginx 搭建,共有两台 web 节点,与其它服务互相有依赖关系
2.1.2. 实验 目的 :
注入故障停止 keepalived ( 主 )的 服务,验证 VIP 是否能够 自动漂移, 来检测服务的韧性
2.1.3. 实现原理:
通过同创永益混沌工程平台注入 OS 停止服务故障并关联稳态指标(模拟流量)致使 keepalived ( 主 ) 服务停止工作,停止后通过平台指标监控查看流量请求是否中断,错误率是否增加,服务对外提供是否停止
2.1.4. 实验过程:
通过同创永益混沌工程平台,新建场景,配置演练计划参数,对 keeplived 服务做停止的动作
添加场景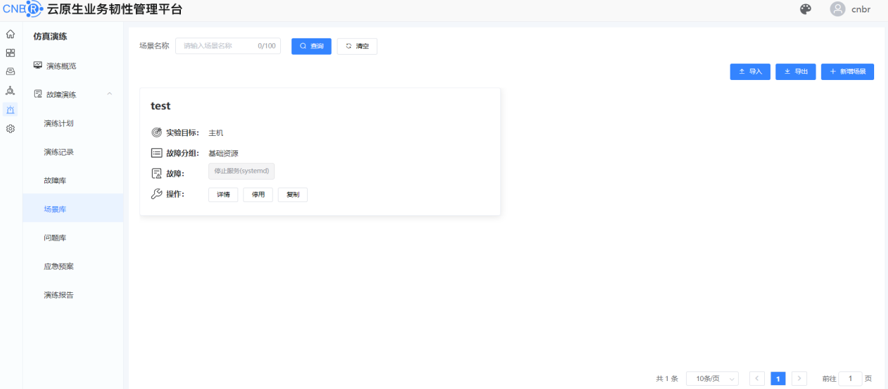
演练计划信息配置:
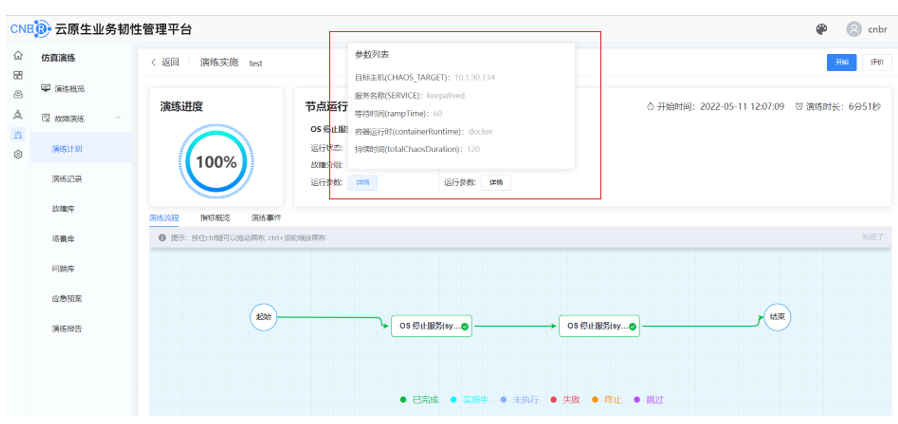
2.1.5. 实验结果
后台 VIP 漂移到另一台机器上,服务访问未中断
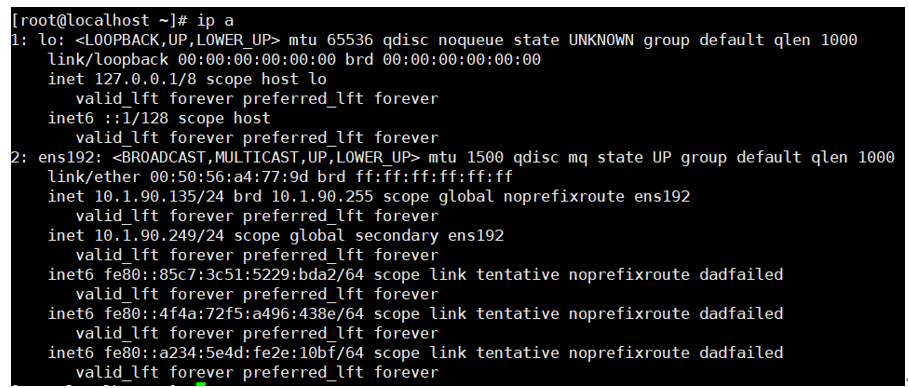
页面访问:

2.2. 网络抖动故障
2.2.1. 实验场景:
网络中断 10 秒,中断间隔 1 秒,并关联稳态指标(模拟请求量),故障持续时长 200 秒
2.2.2. 实验 目的 :
通过注入网络中断,验证高可用服务是否可以正常对外提供服务,在中断过程中, VIP 会不会漂移从节点继续对外提供服务,是否会出现脑裂情况,并且验证网络带宽、网速、硬件设备等额外因素对服务造成多大影响
2.2.3. 实验 原理:
主节点通过心跳检测方式向备告知自己还存活,高可用模式继续提供业务的稳定,通过同创永益混沌工程平台注入 OS 网络抖动故障,致使网络中断 10 秒,期间主与从节点断开联系,从节点无法获取主节点信息,就不能判断主节点是否存活,这一情况下会发生诸多问题,例如脑裂、 VIP 漂移失败等情况
2.2.4. 实验过程:
编辑场景模板
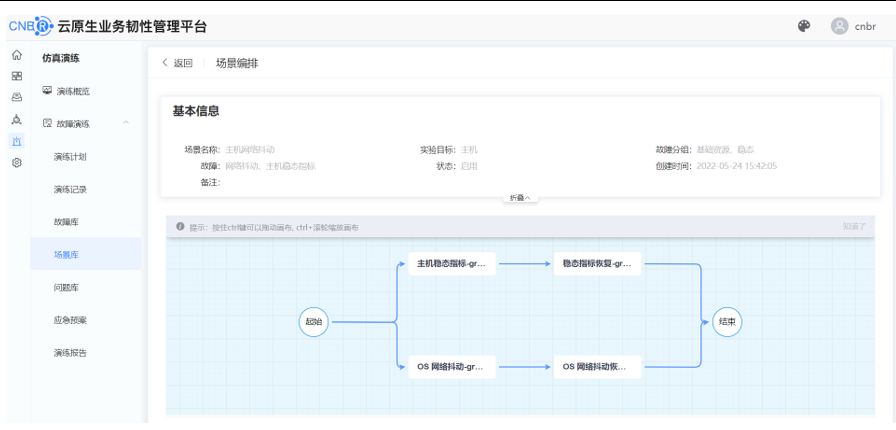
编辑演练计划

演练过程指标信息
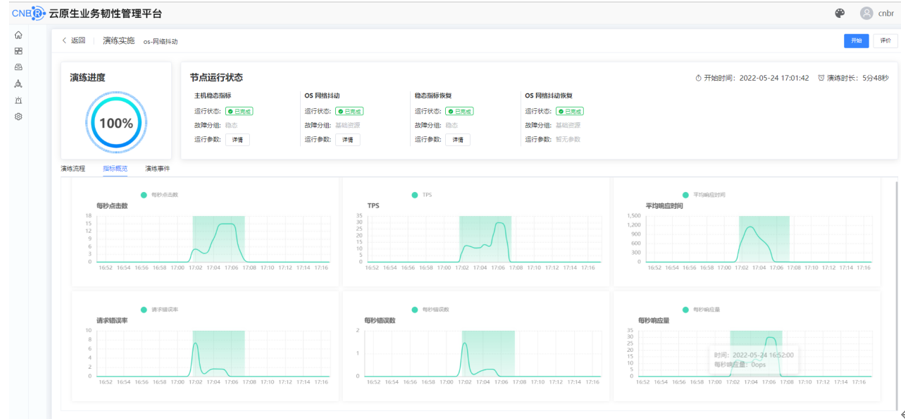
2.2.5. 实验结果
通过故障注入后,访问页面与命令行 ping 主机 IP ,发现页面访问出现卡顿, ping 时间增长,但 VIP 没有漂移,服务未受影响,依然可以提供对外服务,但通过中断说明虽然可以对外提供服务,但页面缺出现卡顿情况,需要优化服务

2.3. 网络包损坏
2.3.1. 实验场景:
网络包损坏 80% ,排除掉默认登录端口( 22 ),并关联稳态指标(模拟请求量),故障持续时长 200 秒
2.3.2. 实验 目的 :
通过注入网络包损坏 80% ,查看服务之间请求时,会不会因为包被破坏导致服务中断,致使 VIP 漂移到从节点
2.3.3. 实现原理:
在保证主节点是否存活的情况下,网络间通信可能会出现丢包、损坏等情况,通过同创永益混沌工程平台注入 OS 网络包损坏,破坏除登录默认端口( 22 )的其他所有端口,来验证是否会影响从节点的自动切换机制, VIP 无法漂移则导致服务可能会中断对外提供服务,影响范围较大
2.3.4. 实验过程:
编辑场景模板
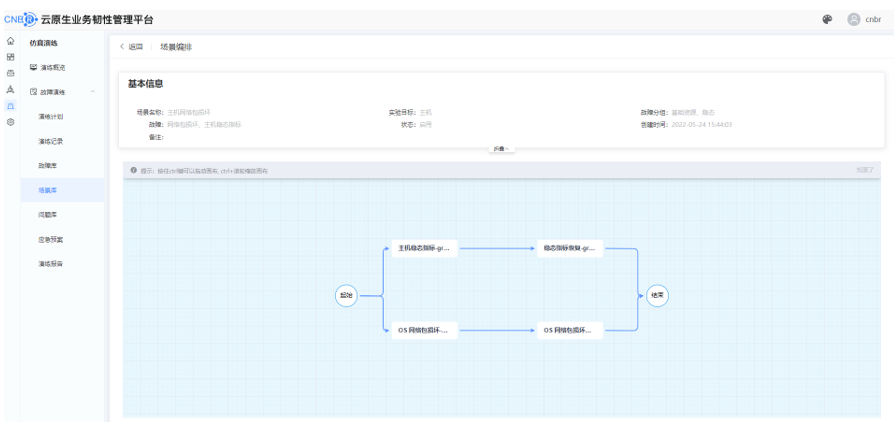
编辑演练计划
演练过程指标信息

2.3.5. 实验结果:
通过注入网络包损坏 80% 故障后,访问页面并未受到影响, VIP 没有漂移,对外正常提供服务 (通过指标、点击率、错误率等)
3. 实验总结
通过模拟停止服务、网络抖动、网络包损坏故障,模拟服务非人为性停止、网络不稳定或者遭到攻击,验证服务本身的高可用性,在此期间是否可以正常对外提供服务, VIP 是否会漂移,业务中断后的影响范围有对大,并且从中发现因业务调用关系、配置参数、代码层面等一些未知问题,对这些未知问题提前发现并解决,防止在生产环境中造成不可挽回的损失,多次进行不同的故障注入后,会更好的完善业务的稳定性,为整体业务的韧性保驾护航。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0
添加新评论0 条评论