
Oracle ADG同步技术,DBA必备的一种“后悔药”
【引言】 所有高可用性方案的本质就是 “冗余”,当然预算开支也会随着高可用性要求的提升而变得异常昂贵。
大家在构建数据库架构的时候,在不考虑预算限制的前提下,往往都内含满足这么几个要求:高可用性、支持高并发、支持负载均衡、具有可扩展性, SLA 会要求满足 99.99% 、 99.999% 或者更高逼格的 99.9999% 。在这几个要求中,个人认为高可用性是首要满足的,该要求可保障数据库架构中某台服务器异常不能正常提供数据服务时,数据库层面仍可提供稳定的数据服务。
Oracle层面的高可用性架构为 RAC ,熟悉此架构的朋友都知道, RAC 能满足高可用性、高并发访问的要求,但这只体现在计算资源的冗余,数据源还是一个,当数据源出现损坏或异常时,便不能提供数据服务。此情况的一个解决方案是:使用 RAC+ADG 架构,通过构建 ADG standby 库来保障数据层面的冗余。
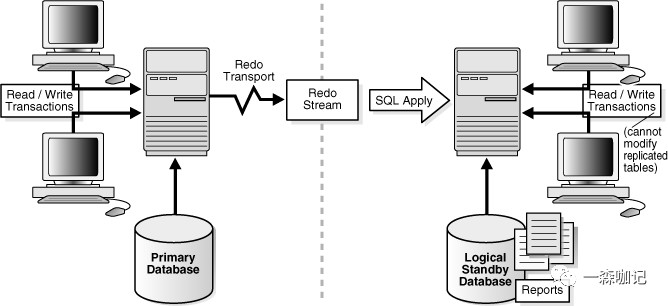
根据自己的使用经验,接下来本文大致介绍 ADG 常用的 2 种用法:
- 主库异常下的高可用性切换
- 人为误操作下的数据恢复方法
ADG 用途 1 :主库异常下的高可用性切换
- 此架构可满足当 RAC 主环境出现异常不能提供数据服务时,切换至 ADG 同步库以保障最短时间内恢复业务使用。常规切换时间大致在分钟级别,但这个时候需要更改应用程序的数据库连接;大部分应用程序为 java 开发,使用 jdbc 连接数据库的示例如下:
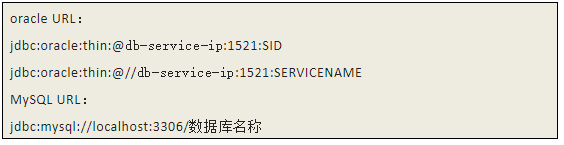
如上,连接数据库实例需要三个信息:库服务器 ip 、库端口号、实例名 /service 。
当 RAC 环境异常需要切换至 ADG 库后,如 RAC 和 ADG 的实例名称配置不变的前提下,
应用程序链接数据库的信息由原来的 RAC 的 service-ip/scan-ip 更改为 ADG 的 ip 地址即可。此情况下, java 程序中如有多处连接库的语句,可把 db-service-ip 设置为应用程序全局变量,此时只改 db-service-ip 的参数即可。但修改应用程序连接库配置后往往需要重启应用程序,从而导致业务中断时间包含:库的切换时间 + 应用程序修改库连接配置和重启时间,业务中断时间较长。
一个问题:这种情况下,如何缩短业务中断时间?
答案是:可以在 ADG 服务器上启动一个 vip ,此 vip 是 RAC 的 service-ip/scan-ip ,这样可省去应用程序修改库连接配置和重启的时间,大大缩减业务中断时长。具体在 ADG 服务器启动 vip 的命令如下:

其中, enp4s0f1为网卡信息,可在 ADG 服务器上通过命令 ip a 或者 /etc/sysconfig/network-scripts/ 路径下网卡信息来查看; vip 设置为和 RAC 的 service-ip/scan-ip 一致。
ADG 用途 2 :人为误操作下的数据恢复方法
数据库在上述客观因素下,还有一个常犯的主观因素导致库异常:人为操作失误。这种情况下有常规的 3 种常用方法:
- 在另一个环境中做库恢复,恢复到事故点前一刻,找到正确的数据后,把数据导入到生产环境中;在数据库较小,业务中断时间较短的情况下,可以采用此方案;
- 使用 Oracle Flashback 进行恢复, Oracle Flashback 是一组 Oracle 数据库特性,闪回允许你 查看过去一个时间数据库对象的状态,或者不借助数据库恢复,就可以恢复数据库对象到之前的一个时间状态 ;
- 使用 logminner , LogMiner 是 Oracle 公司从产品 8i 以后提供的一个实际非常有用的分析工具,使用该工具可以轻松获得 Oracle 在线 / 归档日志文件中的具体内容,特别是该工具可以分析出所有对于数据库操作的 DML 和 DDL 语句。该工具特别适用于调试、审计或者回退某个特定的事务。
上述三种情况要么恢复时间长;要么额外占用存储空间;要么人为分析复杂;比如 Flashback/Logmnr( 如果是 DML 类,可以使用闪回查询或者 logmnr 挖掘 ; 如果是 drop ,可以使用 flashback table ,但若是字段的更改或者 truncate 等操作,上述就无法起到作用了 ) 。
这里抛出一个问题 :
在库到了 T 级别,业务不允许过长或不允许中断的情况,如何办?
一个方案:这种场景下就可以借助 ADG 端恢复。有同学问 ADG 不是实时同步吗,怎么能恢复到人为误操作前的数据, ADG 有个参数为 delay ,利用延迟应用日志时间差,来迅速将 standby recover 到故障时间点之前,然后利用逻辑 exp&imp 来实现表级恢复。
操作步骤如下:
- 使用如下命令延迟同步库日志应用
在备库指定 delay 属性 , 备库延迟 6 0 分钟应用主库日志

此参数单位为分钟,这里示例同步库与主库有 60分钟的数据更新间隔,即有 60 分钟的“后悔药”;当然,也可以设置为任何时间段,恢复时间 / 日志应用时间和 standby 端口服务器性能、日志量有关。举例,我处管理的一个 T级别的数据库,全备恢复为 16 个小时,我处设置的 delay 间隔一天为 60*24=1140 。
- 需要恢复数据库时,使用如下步骤:

- 然后主库恢复原有时间间隔

【总结】
- 本文重点引出了 Oracle 的一种高可用性架构 RAC+ADG ,点出 RAC 的局限性,描述了 ADG 的 2 种用途,简单一句话就是借助 ADG 构建的一份“数据冗余”,在 RAC 环境异常的情况下,提供一种短时间内恢复业务使用的方法;
- 同时, ADG 也是一种“后悔药”,在人为误操作又不对主库操作的情况下,以最小代价恢复错误操作;
- 后续本公众号将给出具体的一个操作案例。
To be continued.
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3作者其他文章
评论 0 · 赞 3
评论 0 · 赞 2
评论 1 · 赞 2
评论 0 · 赞 2
评论 0 · 赞 2
添加新评论0 条评论