
如何在不影响Oracle生产库性能的评估整库大小
【引言】 最近碰到一个小问题:一TB级的 Oracle生产 库,因为要走数据迁移,需要先行评估整个库的迁移数据量大小,但又不得影响生产库运行性能。如何搞?大家都知道, expdp 数据泵有两个很好用的参数 ESTIMATE 和 ESTIMATE_ONLY ,此两个参数可以保证在不真正发起逻辑备份的情况下评估整个迁移生产库的大小。今天念叨下这个小问题。
这里使用$ expdp -help先看 expdp 的 ESTIMATE 和 ESTIMATE_ONLY 两个参数的介绍:
ESTIMATE
默认: blocks
指定计算每张表使用磁盘空间的方法 ESTIMATE=[BLOCKS | STATISTICS]
1.BLOCKS - 通过块数和块大小计算 2. STATISTICS - 每张表的统计信息计算
Expdp 可计算导出数据大小容量,一种是通过数据块数量、一种是通过统计信息中记录的内容估算。通过 expdp 的参数 ESTIMATE_ONLY 和 ESTIMATE 来评估导出的性能, ESTIMATE_ONLY 仅作评估不会导出数据,通过 ESTIMATE 参数指定 statistics 和 blocks 参数来测试两者的差异。
以下是 Oracle 11.2.0.4 中的测试数据输出,在此版本中,我们来看下 ESTIMATE 的 statistics 和 blocks 两个参数各自评估大小和用时。
两条命令如下:

具体执行如下:

如上可以看出,使用 ESTIMATE=blocks 评估出来的大小为 2599. GB,耗时:00:02:50;
接下来再看 ESTIMATE=statistics 方式。命令如下:
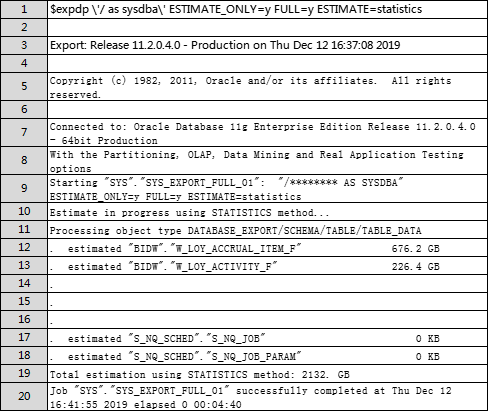
如上,使用ESTIMATE=STATISTICS 评估出来的大小为 2132. GB,耗时:00:04:40;
可以看出,两种方式统计的大小不一样,为啥?
分析推断:
ESTIMATE的默认方式是 blocks 。个人理解为: Oracle 的块大小默认为 8KB ,直接对库使用的块数计算使用量,简单明了,但考虑到块有高水位线、碎片等因素,故统计不精确。而 STATISTICS 方式因计算的是对 每张表的实际使用情况,故更为精确。
但STATISTICS 的方式也非很精确,原因为: 1. 该方式只是对表做统计,没有对索引、列、系统做统计, 2. 一个表中被修改的行数超过 stale_percent( 缺省值 10%) 时才会认为这个表的统计数据过时,需要重新搜集。
注意:
如果压缩了表,那么使用 ESTIMATE=BLOCKS 计算的值时不准确的,这个时候就应该使用 ESTIMATE=STATISTICS 。
推荐:
使用 ESTIMATE 的默认方式 blocks 进行估算,原因很简单,估值按最大值估算申请空间更靠谱。
为了加深理解,这里介绍下Oracle 统计信息收集
大家都知道,Oracle较优执行计划的挑选是基于 CBO ( cost based optimized )判断,而 CBO 对哪个执行计划较优的判断是基于统计信息。优化器统计范围包含:
- 表统计:行数,块数,行平均长度;
all_tables: NUM_ROWS , BLOCKS , AVG_ROW_LEN ;
- 列统计:列中唯一值的数量(NDV), NULL 值的数量,数据分布;
DBA_TAB_COLUMNS: NUM_DISTINCT , NUM_NULLS , HISTOGRAM ;
- 索引统计:叶块数量,等级,聚簇因子;
DBA_INDEXES: LEAF_BLOCKS , CLUSTERING_FACTOR , BLEVEL ;
- 系统统计:
I/O性能与使用率;
CPU性能与使用率;
存储在aux_stats$中,需要使用 dbms_stats 收集, I/O 统计在 X$KCFIO 中;
查询表上一次收集统计信息的时间:
SQL> select owner,table_name,last_analyzed from dba_tables where owner='SCOTT';
Oracle 中如何搜集统计信息?主要有2种方法:
方式1:analyze语句
analyze 可以用来收集表,索引,列以及系统的统计信息和直方图,以下为一些典型用法:
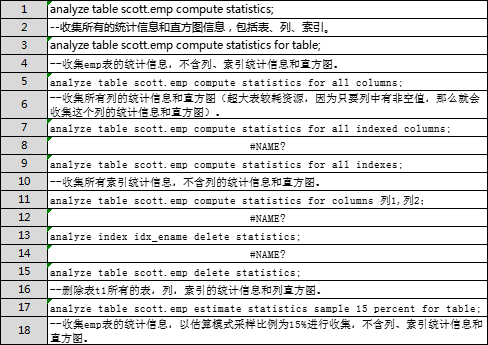
从语法可以看出,只有指定列统计信息收集时,才会收集相关列的直方图,此外收集直方图时 for 子句还可以加 size 子句, size 的取值范围是 1-254 ,默认值是 75 ,表示直方图的 buckets 的最大数目。 而dbms_stats 包的 size 选择则有: 数字|auto|repeat|skewonly 选项,但 analyze 的 size 只能是数字。
关于直方图介绍:
A histogram is a special type of column statistic that provides more detailed information about the data distribution in a table column. A histogram sorts values into "buckets," as you might sort coins into buckets.
直方图就是一种特殊的列统计信息,只有列才有直方图。
用于查看 analyze 后统计信息的 SQL;

需要注意的一点是for table选项并不只收集表统计信息,将列和索引的统计信息一块收集了。
oracle会监控所有表的 DML 活动并在 SGA 中进行记录。监控的信息会定时的刷新到磁盘且可以通过 *_tab_modifications 视图来查看。
可调用 dbms_stats.flush_database_monitoring_info 过程来手动刷新这些数据 。 如果想在查询时得到最新信息 ( 在所有统计数据收集之前内部监控数据会被刷新 ) 。可通过查询 user_tab_statistics 视图中的 stale_stats 列来查看哪个表的统计数据过时。表的 stale_stats 被设置为 NO, 统计数据是最新的。表的 stale_stats 被设置为 YES, 统计数据是过时的 , 表的 stale_stats 没有被设置说明丢失统计数据。
方式2:调用dbms_stats包
dbms_stats 中负责收集统计信息的几个存储过程:
GATHER_DATABASE_STATS
--This procedure gathers statistics for all objects in the database.
GATHER_DICTIONARY_STATS
--This procedure gathers statistics for dictionary schemas 'SYS', 'SYSTEM' and schemas of RDBMS components.
GATHER_FIXED_OBJECTS_STATS
--This procedure gathers statistics for all fixed objects (dynamic performance tables).
GATHER_INDEX_STATS
--This procedure gathers index statistics. It attempts to parallelize as much of the work as possible. Restrictions are described in the individual parameters. This operation will not parallelize with certain types of indexes, including cluster indexes, domain indexes, and bitmap join indexes. The granularity and no_invalidate arguments are not relevant to these types of indexes.
GATHER_SCHEMA_STATS
--This procedure gathers statistics for all objects in a schema.
GATHER_SYSTEM_STATS
--This procedure gathers system statistics.
GATHER_TABLE_STATS
--This procedure gathers table and column (and index) statistics. It attempts to parallelize as much of the work as possible, but there are some restrictions as described in the individual parameters.
具体使用案例:
- EXEC DBMS_STATS.GATHER_SCHEMA_STATS('SCOTT',estimate_percent=>80,method_opt=>'FOR ALL COLUMNS SIZE AUTO',degree=>4,cascade=>TRUE);
- EXEC DBMS_STATS.GATHER_TABLE_STATS('SCOTT','EMP',estimate_percent=>80,method_opt=>'FOR ALL COLUMNS SIZE AUTO',degree=>4,cascade=>TRUE);
- EXEC DBMS_STATS.GATHER_INDEX_STATS('SCOTT','PK_EMP',estimate_percent=>80,degree=>4);
dbms_stats与analyze的区别:
- analyze 收集系统内部对象会报错,而 dbms_stats 不会 ;
- analyze 不能正确的收集分区表的统计信息,而 dbms_stats 可以通过指定粒度来实现( granularity )。
- analyze 不能并行的收集统计信息,而 dbms_stats 可以(可以加上 degree=>4 来实现并行度为 4 的收集)。
- Oracle 推荐使用 dbms_stats 来收集统计信息, analyze 将会被逐渐抛弃。
【总结】
- 本文介绍了在不影响生产库运行性能的前提下。使用expdp数据泵参数 ESTIMATE 和 ESTIMATE_ONLY ,在不真正发起逻辑备份的情况下,可以评估整个迁移生产库大小的用法和差别及分析;
- 同时介绍了Oracle的 CBO ,统计信息、直方图,如何收集统计的两种方法调用 dbms_stats 包和 analyze 两种方式,推荐使用调用dbms_stats包;
- 使用expdp评估库大小时,推荐使用 ESTIMATE 的默认方式 blocks 进行估算,原因很简单,估值按最大值估算申请空间更靠谱。
【参考】https://docs.oracle.com/cd/B19306_01/appdev.102/b14258/d_stats.htm#CIHBIEII
【参考】 https://docs.oracle.com/cd/B12037_01/server.101/b10759/statements_4005.htm#i2150533
【参考】 https://docs.oracle.com/database/121/TGSQL/tgsql_histo.htm#TGSQL36
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3本文隶属于专栏

作者其他文章
评论 0 · 赞 3
评论 0 · 赞 2
评论 1 · 赞 2
评论 0 · 赞 2
评论 0 · 赞 2
添加新评论0 条评论