Redis module功能介绍
一、redis module简介
大多数场景下,人们都是将redis用作一个存储数据库(尤其是kv存储和hash存储),但其实redis还有很多有趣的、强大的功能等待被发现和使用。在redis4.0版本,redis增加了module功能,该功能可以允许用户自定义扩展模块,在redis内部实现新的数据类型和功能,使用统一的调用方式和传输协议格式扩展redis的能力。
redis module是一种动态库,可以用与redis内核相似的运行速度和特性来扩展redis内核的功能;在redis中使用lua脚本只是组合Redis内核的现有功能,但是redis module则可以给redis内核添加新的功能。redis module可以将很多重复性的工作独立出来,交给特定的团队进行开发和维护,能够减少程序之间的耦合性;同时也能极大的提高开发效率,降低程序的维护开销。
二、redis module的“hello world”
redis module不依赖于redis或者其他的一些库,也不需要特定的redis版本。为了简化redis module的开发,redis的作者们在内部做了很多的工作,使得开发工作结构化。
开发者要创建一个新的module模块,只要从源码中拷贝redismodule.h,并链接开发者自己需要的库,实现两个钩子函数xxx_RedisCommand和RedisModule_OnLoad即可。xxx_RedisCommand函数是具体的命令执行函数,类似于redis内部的各种command函数;而RedisModule_OnLoad则是进行参数校验并将模块注册到redis的server中。加载函数将告诉redis内核该module模块的名字、版本指定api和一些参数,然后将命令和参数注册到redis-server命令字典中。如下图所示,是一个简单的redis模块开发实例,当通过客户端给redis发送“helloworld.rand”命令,可以接收到一个rand()产生的随机数。
include "redismodule.h"
include
int HelloworldRand_RedisCommand(RedisModuleCtx ctx, RedisModuleString *argv, int argc) {
RedisModule_ReplyWithLongLong(ctx,rand());
return REDISMODULE_OK;
}
int RedisModule_OnLoad(RedisModuleCtx ctx, RedisModuleString *argv, int argc) {
if (RedisModule_Init(ctx,"helloworld",1,REDISMODULE_APIVER_1)
== REDISMODULE_ERR) return REDISMODULE_ERR;
if (RedisModule_CreateCommand(ctx,"helloworld.rand",
HelloworldRand_RedisCommand, "fast random",
0, 0, 0) == REDISMODULE_ERR)
return REDISMODULE_ERR;
return REDISMODULE_OK;
}
同其他原生的redis命令类似,直接使用命令所对应的指令,即可调用modules的功能并返回结果;在集群模式、主从复制模式下,只要加载了相同的模块的redis都可以正确的传输数据;AOF功能(如果开启的话)也能正确的加载和写入。命令的传输和解析与原生的命令没有变化,同时不同redis版本编译出来的动态库可以互相兼容,进行热拔插。

如上图所示,是redis启动的基本流程(省去了一些与redis module无关的细节)。redis首先申请一大块内存,然后开始使用配置文件或者默认值初始化配置,接着在初始化服务前,先将module功能模块初始化并将一些module注册到redis内核中,然后进行相关服务的初始化并紧接着检查日志和aof文件,将redis数据库状态恢复,最后开启事件循环开始对外提供redis的相关服务。这些流程保证了使用module功能的redis在发生宕机或者其他问题的时候,再次启动后能够保证数据的持久性。
在redis中,和modules模块相关的代码一般放在module.c和module.h中,如果要使用redis内部的数据结构和方法,可以使用modules模块提供的API。redis的modules模块提供了两种API:一种是高级的API,该族函数可以模拟lua脚本调用redis原生的命令并得到返回结果;另一种是低级的API,直接操作redis的键值obj指针。Redis低级API的速度接近Redis原生命令的速度,但高级API则更常被开发者所使用,因为Redis的瓶颈在于处理数据而不是访问数据。
在内存回收上,module使用了自定义的内存分配函数zmalloc封装了原生的c语言内存分配函数(c语言原生的内存分配对于redis来说是透明的,因此redis通过zmalloc通过定义的宏,封装了很多与内存功能相关的函数,在不同的硬件平台和操作系统中选择在该环境下最优的的内存分配函数,redis的高性能与这个模块息息相关,有兴趣的读者可以查找一些相关的文章,这里不做赘述)。使用这些方法分配内存的时候,可以直接将数据分配填充到数据结构中,减少了数据的复制,同时也会报告给redis的内核并且触发redis内部的内存机制(比较重要的是引用计数和惰性删除)。
redis可以使用两种方式来进行redis的module模块加载:第一种方式是在redis的配置文件中配置,并使用该配置文件启动redis;第二种方式是在命令行启动redis的时候,通过命令行参数加载加载。在加载的时候可以传递参数,并被module模块接收处理和使用。# 三、经典的redis module模块
1、布隆过滤器 RedisBloom(KCC平台已上线)
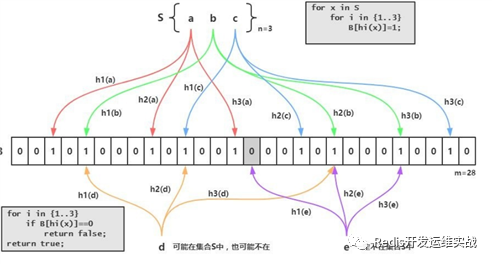
布隆过滤器(Bloom Filter)是1970年由布隆提出的,它实际上是一个很长的二进制向量和一系列随机映射函数,可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,但是有一定的误识别率且无法删除元素。
当尝试通过网络或磁盘搜索查询时,可以先查询BloomFilter,它肯定地告诉我们要查找的元素是否可能存在(然后可以继续进行查找)还是不存在(此时可以放弃查询直接回复不存在,节省查询资源)。尽管可以使用其他数据结构(例如哈希表,集合,树)来执行此操作,但布隆过滤器具有更高的速度和极为出色的空间效率。布隆过滤器在网页去重,数据查询和广告投放中经常被使用;新业务上线前,增加布隆过滤器也是一个很有效解决缓存击穿的有效手段。
布隆过滤器有一个多位的数组,当元素被“添加”到布隆过滤器时,首先将元素进行hash散列并对数组长度取余,然后将相应的位设置为1,这种方式和哈希表中存储区的映射方式非常相似。为了检查布隆过滤器是否存在某项值,可以计算哈希值然后查看过滤器是否设置了相应的位——如果该位置被设置为1则元素可能存在,如果为0则一定不存在。然而这很容易发生冲突,假设布隆过滤器的长度是m,为了保证99%的准确率,则至多只能使用m/100个位,这显然是十分低效的。为了降低发生冲突的风险,对过滤器进行改造使得一个key可以使用多个位,每次进行插入时,都要使用多次的hash函数进行计算,并对多个位置进行设置。查询时,只要有一次哈希计算的结果对应为0,则该元素一定不存在;反之则可能存在。通常每个元素的位数越多,误报的可能性越低。假设插入的元素个数为n个,布隆过滤器数组的长度为m,一共有k个函数,则误判率p可以通过公式计算:

在客户端使用该过滤器的方法与普通的redis命令使用方法相同。redisbloom除了对于原生的c/c++具有成熟的连接库之外,对于其他各种语言的客户端,目前也已经有很好的支持。
2、布谷鸟过滤器 CuckooFilter
Bloom Filter 可能存在误报并且无法删除元素,因此近些年来有一些学者提出了Cuckoo hash(布谷鸟哈希算法)。Cuckoo hash算法的哈希函数是成对的(具体的实现可以根据需求设计),每一个元素都有两个哈希函数用来分别映射到两个位置,其中一个是记录的位置,另一个是备用位置,这个备用位置是处理碰撞时用的。
布谷鸟过滤器源于布谷鸟Hash算法,布谷鸟Hash表有两张,分别对应两个Hash函数,当有新的数据插入的时候,它会计算出这个数据在两张表中对应的两个位置,这个数据一定会被存在这两个位置之一(表1或表2)。一旦发现其中一张表的位置被占,就将该位置原来的数据踢出,被踢出的数据就去另一张表找对应的位置。通过不断的踢出数据,最终所有数据都找到了自己的归宿。但仍会有数据不断的踢出,最终形成循环,总有一个数据一直没办法找到落脚的位置,这代表布谷Hash表走到了极限,需要将Hash算法优化或Hash表扩容。
H1(key) = hash1(key)
H2(key) = H1(key) xor H1(key’s fingerprint)
H3(key) = key’s fingerprint = hash(key)
与Cuckoo hash算法不太相同的地方时,布谷鸟过滤器只存储元素的指纹信息(几个bit,类似于布隆过滤器),由于不是存储了数据的全部信息,会有误判的可能。由于布谷鸟过滤器在踢出数据时,需要再次计算原数据在另一种表的Hash值,因此作者设计Hash算法时将两个Hash函数变成了一个Hash函数,第一张表的备选位置是Hash(x),第二张表的备选位置是Hash(x)⊕hash(fingerprint(x)),即第一张表的位置与存储的指纹的Hash值做异或运算。这样可以快速计算出其元素在另一张表的位置。
布谷鸟过滤器在做防缓存击穿时具有很好的表现,与布隆过滤器不同的是,它可以删除元素而不是在误判率到达一定程度时扩建;同时对于很久之前插入的数据,进行删除可以提高缓存的性能;而布隆过滤器只能遍历一遍键,进行重建,开销巨大。
3、支持json的模块 Redisjson
redisjson是一款json的插件,由Rust语言编写,它实现 ECMA-404 JSON数据交换标准作为数据类型。它允许从Redis存储、更新和获取JSON值。虽然redis有hash类型的存储,但是嵌套层数较低,当有复杂嵌套的时候,只能将其存为一个字符串(或者hash field中的value字符串),然后通过获取全量的json在客户端进行操作,有时还要将全量的结果更新回去, 十分的不方便 。而redisjson可以通过在redis服务器本地直接操作部分数据,提高了速度和网络利用率。
- 完全支持JSON标准
- 类似于JSONPath 的语法,用于选择文档中的元素
- 文档以二进制数据的形式存储在树形结构中,从而可以快速访问子元素
所有JSON值类型的类型化原子操作
127.0.0.1:6379> json.set user1 $ '{"last":"Joe", "first":"Mc"}' INDEX person
OK
127.0.0.1:6379> json.set user2 $ '{"last":"Joan", "first":"Mc"}' INDEX person
OK
127.0.0.1:6379> json.index add person last $.last
OK
127.0.0.1:6379> JSON.QGET person Jo*
"{\"user2\":[{\"last\":\"Joan\",\"first\":\"Mc\"}],\"user1\":[{\"last\":\"Joe\",\"first\":\"Mc\"}]}"
127.0.0.1:6379> json.set user3 $ '{"last":"Joel", "first":"Dan"}' INDEX person
OK
127.0.0.1:6379> JSON.QGET person Jo*
"{\"user2\":[{\"last\":\"Joan\",\"first\":\"Mc\"}],\"user1\":[{\"last\":\"Joe\",\"first\":\"Mc\"}],\"user3\":[{\"last\":\"Joel\",\"first\":\"Dan\"}]}"
127.0.0.1:6379> json.index add person first $.first
OK
127.0.0.1:6379> JSON.QGET person Mc
"{\"user2\":[{\"last\":\"Joan\",\"first\":\"Mc\"}],\"user1\":[{\"last\":\"Joe\",\"first\":\"Mc\"}]}"
127.0.0.1:6379> JSON.QGET person Mc $.last
"{\"user2\":[\"Joan\"],\"user1\":[\"Joe\"]}"
127.0.0.1:6379> JSON.QGET person "@last:Jo* @first:Mc" $.last
"{\"user2\":[\"Joan\"],\"user1\":[\"Joe\"]}"
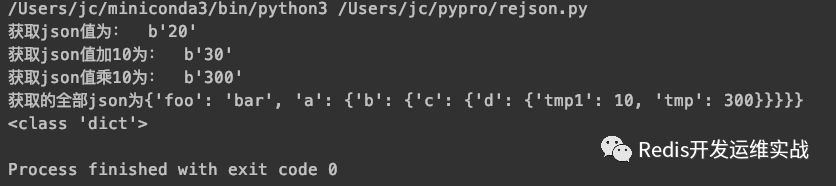
这里作者对python比较熟悉,举一个使用python客户端的例子,如下图所示,不仅可以进行部分json的获取,还可以对json进行一些专属类型的操作(比如数值类型的json进行简单的基本运算),对于那些只需要部分信息进行计算和验证的业务场景,可以极大的提高计算效率和降低网络开销。
import redis
import json
data = {
'foo': 'bar',
"a": {
"b": {
"c": {
"d": {
"tmp1": 10,
"tmp": 20
}
}
}
} }
r = redis.StrictRedis()
r.execute_command('JSON.SET', 'doc', '.', json.dumps(data))
print("获取json值为:", r.execute_command('JSON.GET', 'doc', '.a.b.c.d.tmp'))
print("获取json值加10为:", r.execute_command('JSON.NUMINCRBY', 'doc', '.a.b.c.d.tmp', 10))
print("获取json值乘10为:", r.execute_command('JSON.NUMMULTBY', 'doc', '.a.b.c.d.tmp', 10))
reply = json.loads(r.execute_command('JSON.GET', 'doc', '.'))
print("获取的全部json为" + str(reply))
print(type(reply))
4、咆哮位图 Redis-roaring
Redis 的位图是密集位图,如果有一个很大的位图,它只有最后一个位是 1,其它都是零,这个位图还是会占用全部的内存空间,因为它的底层是字符串,字符串是连续存储空间,位图会自动扩展。咆哮位图(RoaringBitmap)将整个大位图进行了分块,如果整个块都是零,那么这整个块就不用存了。但是如果位图中的元素比较少且分散,每个块里面都有1,只存储所有位1的块内偏移量(整数),这就是单个块位图的稀疏存储形式 —— 存储偏移量整数列表。只有单块内的位1超过了一个阈值,才会一次性将稀疏存储转换为密集存储。
咆哮位图除了可以大幅节约空间之外,还会降低 AND、OR 等位运算的计算效率。类似的如果单个块所有的位全是零,那么它就不需要存储。某个块是否存在也可以是用位图来表达,当块很少时,用整数列表表示,当块多了就可以转换成普通位图。使用咆哮位图可以有效的节省内存和经费,且在位图所含元素稀疏的情况下有显著的性能提升。
举一个经典的面试题例子,给定很多的数组,里面含有的数据在[0,2**32-1]之间,如何判断一个数字是否在其中。假如使用set集合来进行存储,那么将消耗特别大量的内存(约为15GB),这显然是无法接受的。如果使用redis的位图来表示,则可以极大的节省空间,使用第1bit表示0,第2bit表示1,依次类推,此时共需要512MB的空间,就能完成任务。但是正如前面所说的那样,即使只存储了一个元素,我们也要保存完整的位图,因此在数据稀疏的时候可以使用咆哮位图可以节省空间,从而节省内存的使用量。

5、可用于检索的模块 RediSearch
RediSearch是一个分布式全文本搜索和聚合引擎,作为Redis之上的模块构建, 它使用户能够以极快的方式对其Redis数据集执行复杂的搜索查询,例如精确的词组匹配和文本查询的数字过滤,还有使用Reids自带的GEO命令进行地理过滤,这是传统Redis搜索方法无法实现的。
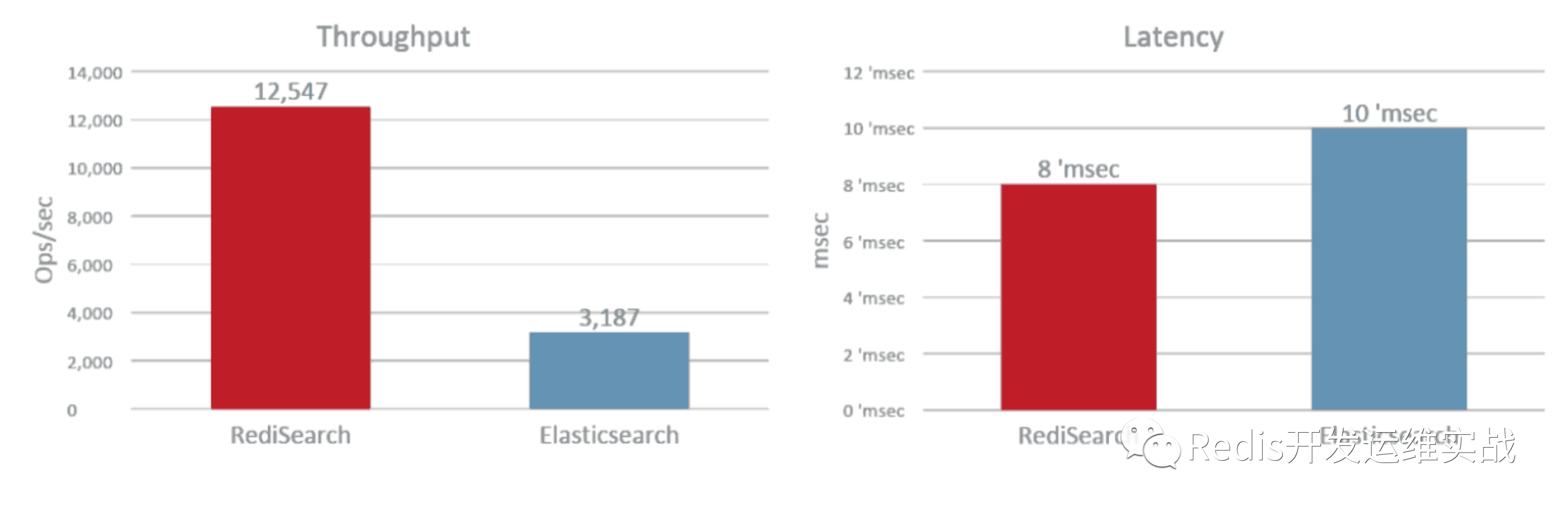
RediSearch的架构是用C编写的,并且完全基于优化的数据结构构建,使其成为市场上其他搜索引擎的替代产品。它非常适合作为用于索引和可搜索数据检索的独立搜索引擎。与其他类型搜索产品不同的是,RediSearch是基于内存的,可以在更短的时间内进行索引的建立和查询,特别适合低延时高吞吐量的索引操作,代价就是使用内存而不是磁盘需要更多的资源。Redis官方使用维基百科数据进行测试(560万文档,共5.3GB),RediSearch的索引建立延时只有ES的57%。
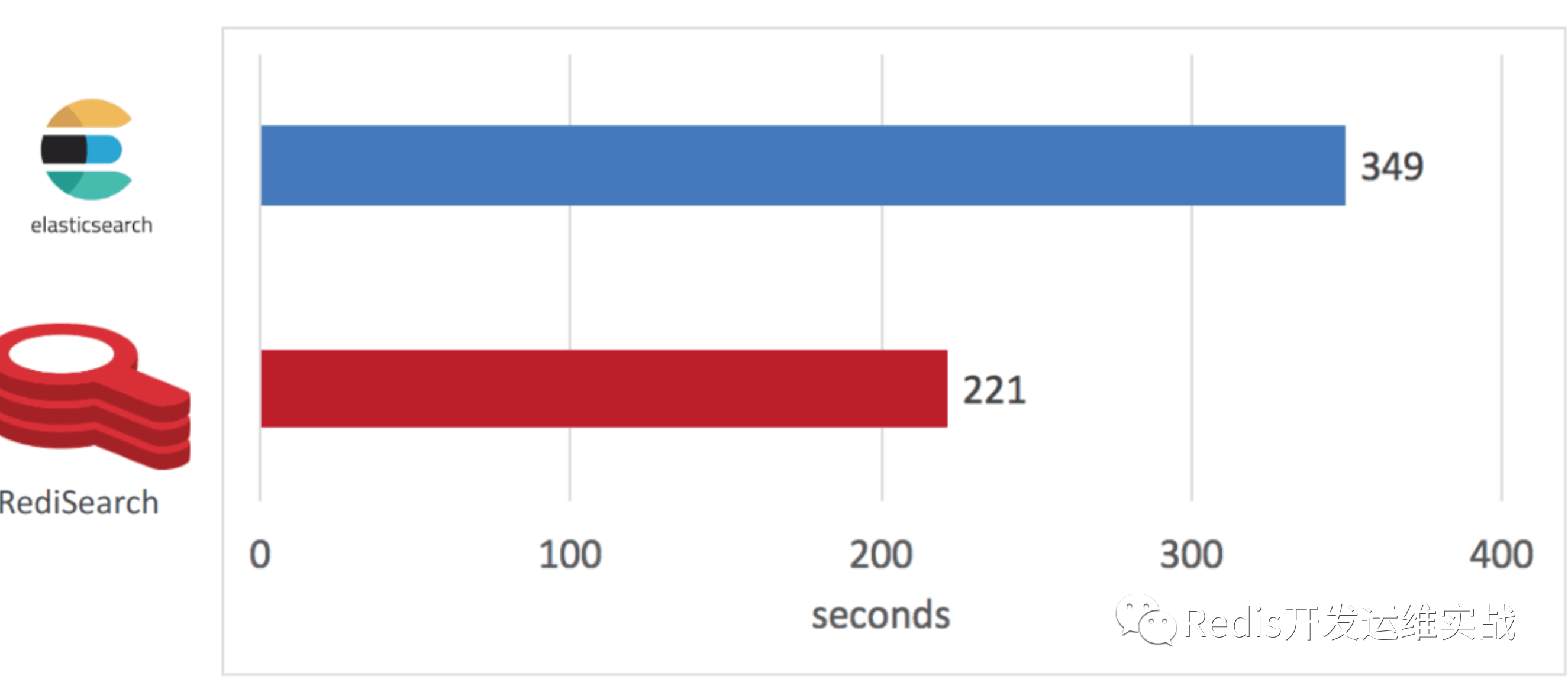
当索引建立完成后,使用相同数量的客户端进行请求,RediSearch的吞吐量大约为ES的四倍,平均延时比ES低2ms。
6、支持机器学习的redis RedisML/RedisAI
RedisML是一个Redis模块,它实现了几种使用redis数据类型的机器学习模型。RedisML是用于在生产环境中使用经过训练的模型的统包解决方案,从任何平台加载ML模型,即可立即使用redis的内置数据类型进行预测和评估过程,目前主要包含了决策树算法(主要是随即森林)、逻辑回归、线性回归和一些矩阵操作(正在飞速发展ing)。
RedisAI是用于执行深度学习/机器学习模型并管理其数据的Redis模块。它的目的是为流行的DL / ML框架提供开箱即用的支持和高性能。RedisAI通过利用Redis经过生产验证的基础架构,简化了图形的部署和服务,并通过遵循数据局部性原理最大化了计算吞吐量。
使用redis+RedisML/RedisAI和其他的模型依赖在边缘计算、小型智能设备等领域具有广泛的发展前景,因为高性能内嵌和轻量级可以直接本地运行相关算法,免去了云端计算产生的大量延时,能够具有极高的实时性。
未来展望:在训练神经网络时,通常使用GPU集群进行计算,有时需要保存中间产物(以前的时候保存过GCN的embedding和多层lstm的某些层中间输出),通过内嵌到redis的RedisML和RedisAI可以使用redis自带的持久化,内存管理和释放等功能,使得训练者更专注于模型的实现,而不用考虑中间产物的保存和持久化,提高训练效率,降低开发难度。
7、支持事物处理的模块 RedisGears
RedisGears是一个无服务器引擎,用于在Redis中进行事务,批处理和事件驱动的数据处理。 RedisGears的功能是允许用户构建操作管道,redis中的每个键都将通过该管道。第一个操作的结果将作为输入传递给第二个操作,第二个操作的结果将作为输入传递给第三个操作,依此类推。最后一次操作的结果将作为答复传递给用户。
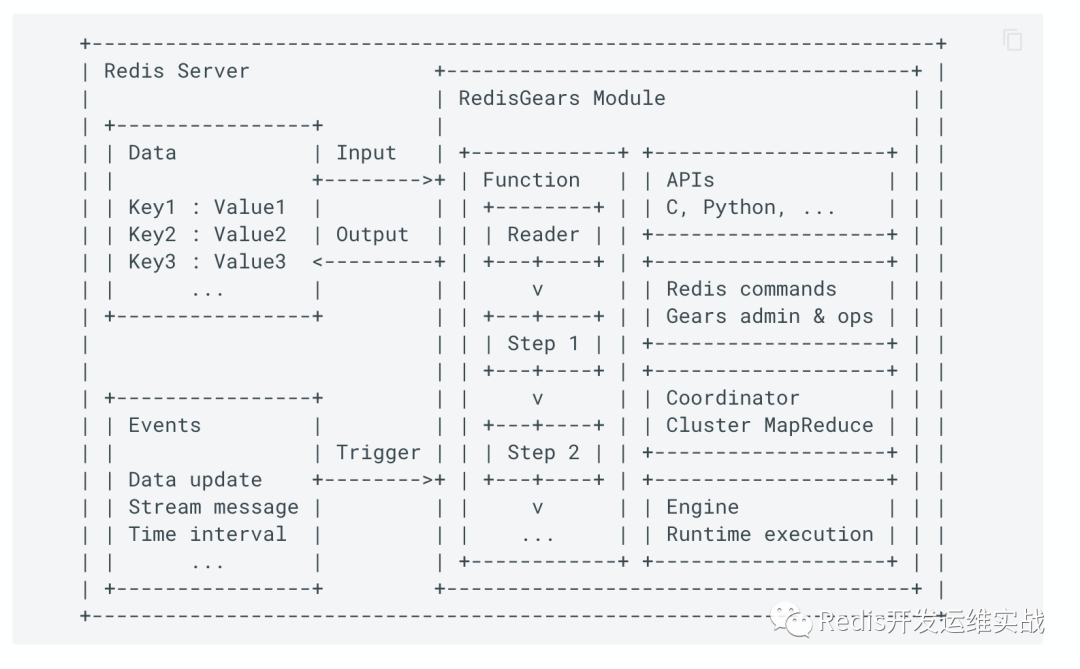
管道可以使用python脚本构建,然后在后台线程中运行, 完成后,结果将返回给用户,类似于mysql中的触发器,当有一些事件发生的时候,会进行相应的处理,这些操作对于用户都是透明的,同时因为靠近redis实例一侧,可以使用redis附近的内存,极大的提高了处理速度。
这个模块作者使用的不多,想要深入了解的老铁可以查看官方博客https://redislabs.com/modules/redis-gears/。
四、其他模块功能
由于篇幅的原因,还有其他很多的功能无法介绍,感兴趣的读者可以参考一下下面的连接。

如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 1 · 赞 8
评论 0 · 赞 4
评论 0 · 赞 0
评论 0 · 赞 3
评论 0 · 赞 4
添加新评论0 条评论