技术抽丝剥茧|为什么 Redis 内部使用不同编码?
某个周末的 晚上突然收到一波耗时上升报警,仔细一看报警消息,原来是出现了慢查请求导致集群耗时大幅 上升,此时业务 同学也收到上游服务受影响报警。在处理问题 过程中,运维同学 发现 Redis 集群中只有部分实例出现 cpu 利用率上升,慢查日志也集中在这几个 实例,而上游业务此时没有上线或是业务模型变化。因为是少量热 key 访问导致部分 Redis 实例负载高,执行限流对业务有损,执行扩容也无法达到快速止损的目标,幸好业务侧有提前制定的降级预案,快速沟通后采用了业务侧降级方案进行了止损。
案例回顾
虽然故障通过业务侧降级预案及时止损, 但作为 Redis 服务提供方,进行复盘弄清问题根因,制定预案是必须要做的工作,这样才能避免问题再次发生或是发生时更快止损。通过了解业务场景,发现是因为城市A大雨,排队订单上升3倍。咦?这个情景有点熟悉,以前也是这个城市在大雨时出过这个问题,这也是为什么业务侧会有一个降级预案存在。了解背景后,接下来就要接受业务同学们的灵魂拷问了。
- 为什么昨天同一时间段,该集群 QPS 更高但是没有出现类似问题?
这个集群存储了多个城市的数据,为什么只有城市A这个城市下大雨会出问题,而别的城市没有问题,难道是别的城市不下大雨?或是大家不用排队功能?
答案显然不是,一定还有技术层面的问题没有搞明白,接下来带大家回顾当时我们的排查问题思路。
首先从观察故障期间的一些现象入手,我们发现如下几个现象:
- 当时出现了5个热 key,都属于同一个城市A,该城市因为当天晚上大雨导致排队订单量超过平时3倍;
- 这5个热 key 都是 hash 数据结构,里面存储的每个 key 有400多个元素;
- 同样的业务逻辑,另外一个城市B,也是5个 hash 表,QPS 比城市A这个城市高,key 中的元素数量也比城市A要高,但是城市B反而并没有出现耗时高的问题;
在出现问题的时刻,这5个热 key 上大部分命令都是 HEXISTS(作用是查看某个 field 是否在 hash 表中),此命令是O(1)复杂度。
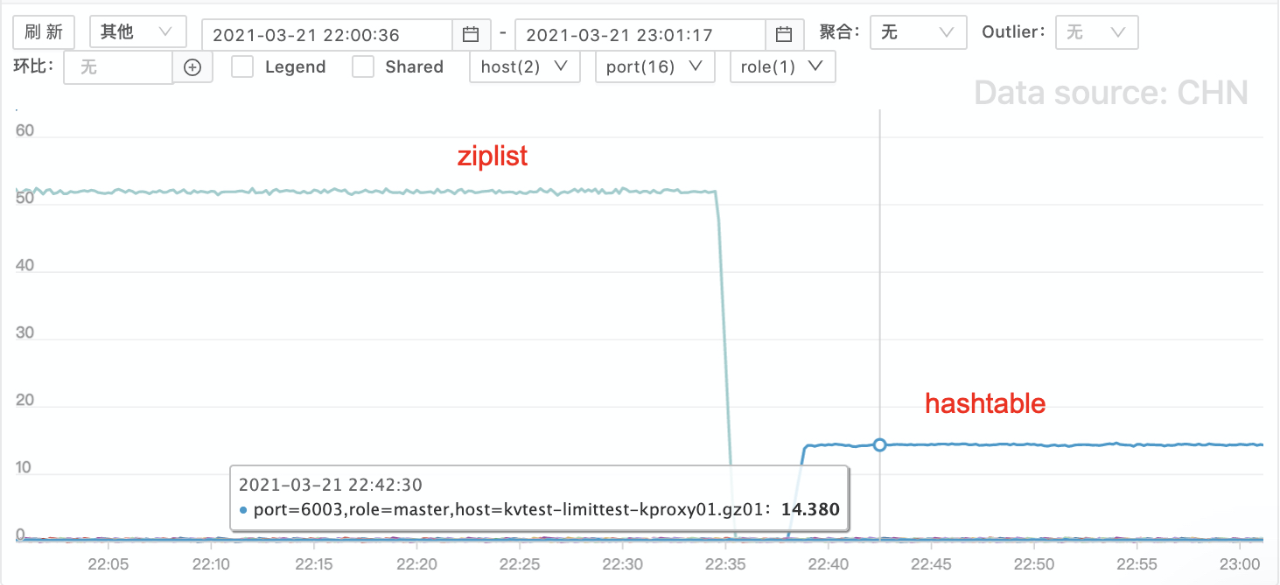
此时脑中灵光一现,在查看热 key 的 meta 信息时,发现城市A的这5个 key 使用的内部编码是 ziplist,此时再对比一下城市B的5个 key,发现使用的 hashtable 编码,这个发现让我们似乎看到解决问题的曙光,这是目前发现的城市A和城市B最大的不同之处,后续的分析也证明了这个方向是正确的。
哈希(hash)对象的两种内部编码对比
为什么 Redis 的 hash 数据结构会采用两种不同的编码方式,不同编码方式又会带来什么样的不同后果呢?
Redis 为什么内部使用不同编码?
Redis 使用对象来表示数据库中的键和值, 每次当我们在 Redis 的数据库中新创建一个 键值对时, 我们至少会创建两个对象, 一个对象用作键值对的键(键对象), 另一个对象用作键值对的值(值对象)。例如:SET mykey "HelloWorld"这个命令会创建两个 Redis 对象,一个字符串对象"mykey"做 key,一个字符串对象"HelloWorld"作为 value。Redis 对象的结构体如下:
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
// ...
} robj;
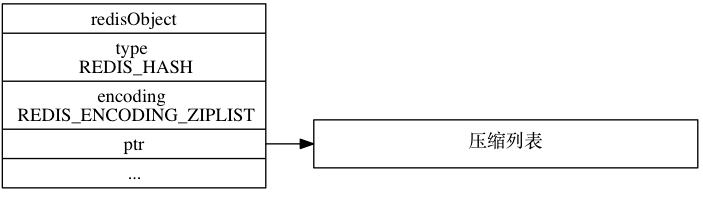
一个 Redis 对象可以有多个类型(type), 如字符串、列表、哈希、集合、有序集合等,同时每种类型也可以设置为不同的编码方式(encoding):int、 hash(ht)、zipmap、ziplist、intset、skiplist、embstr、quicklist、 stream。通过 encoding 属性来设定对象所使用的编码, 而不是为特定类型的对象关联一种固定的编码, 极大地提升了 Redis 的灵活性和效率, 使得 Redis 可以根据不同的使用场景来为一个对象设置不同的编码, 从而优化对象在某一场景下的效率。
两种编码方式的数据结构
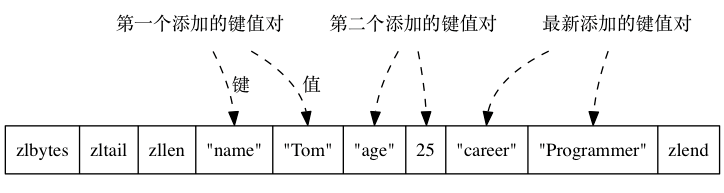
编码方式1: ziplist
< zlbytes > < zltail > < zllen > < entry > ... < entry > < zlend >
编码方式2: hashtable 编码

为什么要使用 ziplist 编码?
- 在哈希对象包含的元素比较少时, Redis 使用压缩列表作为列表对象的底层实现,因为压缩列表比双端链表更节约内存,并且在元素数量较少时,在内存中以连续块方式保存的压缩列表比起双端链表可以更快被载入到 CPU 缓存中;
- 随着列表对象包含的元素越来越多,使用压缩列表来保存元素性能就会变差,Redis 就会把这个列表对象在底层从压缩列表编码转成 hashtable 编码,hashtable 编码是一个更适合保存大量元素的双端链表。
命令执行时对两种编码结构处理逻辑
当执行 hset/hmset 命令时,代码中会去检查哈希的对象编码以及相关条件来判断该采用哪种编码方式,大致流程如下:
1、检查 value 大小
先是在 hashTypeTryConversion() 中检查,当编码是 OBJ_ENCODING_ZIPLIST,并且写入的 value > server.hash_max_ziplist_value(我们线上默认设置为64 Bytes),会执行转码函数 hashTypeConvert()
2、检查 field 的个数
在 hashTypeSet() 中,如果编码是 OBJ_ENCODING_ZIPLIST,并且元素个数 >server.hash_max_ziplist_entries(我们线上默认设置为512个),就会执行转码函数 hashTypeConvert()
3、hashTypeConvert() 函数实现
在 hashTypeConvert()中 会调用 hashTypeConvertZiplist() 函数,先创建一个字典 dict,然后逐个复制 ziplist 中的 field 和 value 并创建对应 Redis 对象后放入 dict 中,在 ziplist 中的数据全部复制并加入 dict 后,释放原来的 ziplist,然后把 key 指向这个 dict,这样这个哈希对象的编码就从 ziplist 转换成了 hashtable。这个过程是阻塞式的,直到 hashTypeConvert 函数执行完毕,hset/hmset 命令才算完成。
源码如下:
void hashTypeConvertZiplist(robj *o, int enc) {
serverAssert(o->encoding == OBJ_ENCODING_ZIPLIST);
if (enc == OBJ_ENCODING_ZIPLIST) {
/* Nothing to do... */
} else if (enc == OBJ_ENCODING_HT) {
hashTypeIterator *hi;
dict *dict;
int ret;
hi = hashTypeInitIterator(o);
dict = dictCreate(&hashDictType, NULL);
while (hashTypeNext(hi) != C_ERR) {
robj *field, *value;
field = hashTypeCurrentObject(hi, OBJ_HASH_KEY);
field = tryObjectEncoding(field);
value = hashTypeCurrentObject(hi, OBJ_HASH_VALUE);
value = tryObjectEncoding(value);
ret = dictAdd(dict, field, value);
if (ret != DICT_OK) {
serverLogHexDump(LL_WARNING,"ziplist with dup elements dump",
o->ptr,ziplistBlobLen(o->ptr));
serverAssert(ret == DICT_OK);
}
}
hashTypeReleaseIterator(hi);
zfree(o->ptr);
o->encoding = OBJ_ENCODING_HT;
o->ptr = dict;
} else {
serverPanic("Unknown hash encoding");
}
}
**两种编码的时间复杂度对比
说完了一些背景知识,下面该进入真正的主题了,为什么城市A这次热 key 问题会造成业务影响,首先我们来看一下哈希对象使用 ziplist 和 hashtable 两种编码不同命令的时间复杂度:
| 命令 | ziplist 编码实现方法 | hashtable 编码的实现方法 |
| HSET | 首先调用 ziplistPush 函数, 将键推入到压缩列表的表尾, 然后再次调用用ziplistPush函数, 将值推入到压缩列表的表尾。时间复杂度:O(1) | 调用 dictAdd 函数, 将新节点添加到字典里面。时间复杂度:O(1) |
| HGET | 首先调用 ziplistFind 函数, 在压缩列表中查找指定键所对应的节点, 然后调用 ziplistNext 函数, 将指针移动到键节点旁边的值节点, 最后返回值节点。时间复杂度:O(N) | 调用 dictFind 函数, 在字典中查找给定键, 然后调用 dictGetVal 函数, 返回该键所对应的值。时间复杂度:O(1) |
| HEXISTS | 调用 ziplistFind 函数, 在压缩列表中查找指定键所对应的节点, 如果找到的话说明键值对存在, 没找到的话就说明键值对不存在。时间复杂度:O(N) | 调用 dictFind 函数, 在字典中查找给定键, 如果找到的话说明键值对存在, 没找到的话就说明键值对不存在。时间复杂度:O(1) |
| HDEL | 调用 ziplistFind 函数, 在压缩列表中查找指定键所对应的节点, 然后将相应的键节点、 以及键节点旁边的值节点都删除掉。时间复杂度:O(N) | 调用 dictDelete 函数, 将指定键所对应的键值对从字典中删除掉。时间复杂度:O(1) |
| HLEN | 调用 ziplistLen 函数, 取得压缩列表包含节点的总数量, 将这个数量除以 2 , 得出的结果就是压缩列表保存的键值对的数量。时间复杂度:O(1) | 调用 dictSize 函数, 返回字典包含的键值对数量, 这个数量就是哈希对象包含的键值对数量。时间复杂度:O(1) |
| HGETALL | 遍历整个压缩列表, 用 ziplistGet 函数返回所有键和值(都是节点)。时间复杂度:O(N) | 遍历整个字典, 用 dictGetKey 函数返回字典的键, 用 dictGetVal 函数返回字典的值。时间复杂度:O(N) |
注:字典 dict 结构的操作,可以简单认为是O(1),虽然如果 hash 有冲突时会多个 key 放到链表,相应的很多操作 就需要遍历这个链表, 但是一般这个链表不会太大,跟整个 hash 表大小比较来说可以认为O(1)。
从上面的对比不难看出:HEXISTS 命令使用 hashtable 时间复杂度为O(1),而使用 ziplist 编码为O(N),当出问题时,城市A存储的 hash 表元素为400个(采用 ziplist 编码),而城市B的 hash 表元素个数超过了512个(采用hashtable编码),这就解释了为什么访问城市A的 key 性能更差。
理论联系实际之测试验证
测试方案
讲完了理论,接下来就需要用实际测试来证明上面的推论( 这里仅针对 HEXISTS 一个命令做性能测试说明)。
测试方法如下:
- 在同一个 Redis 实例分别生成两个 hash 对象:mykey001 和 mykey002,同样都是500个 filed,每个 value=60B;
- 当压测 mykey001 时,hash-max-ziplist-entries 参数=512,编码将会使用 ziplist,压测 mykey002 时 hash-max-ziplist-entries 参数=256,因此编码为 hashtable;
- 每轮发送相同的压力,这里测试时为2万 QPS,命令为 HEXISTS。
测试数据: - 两轮测试 QPS 是相同的
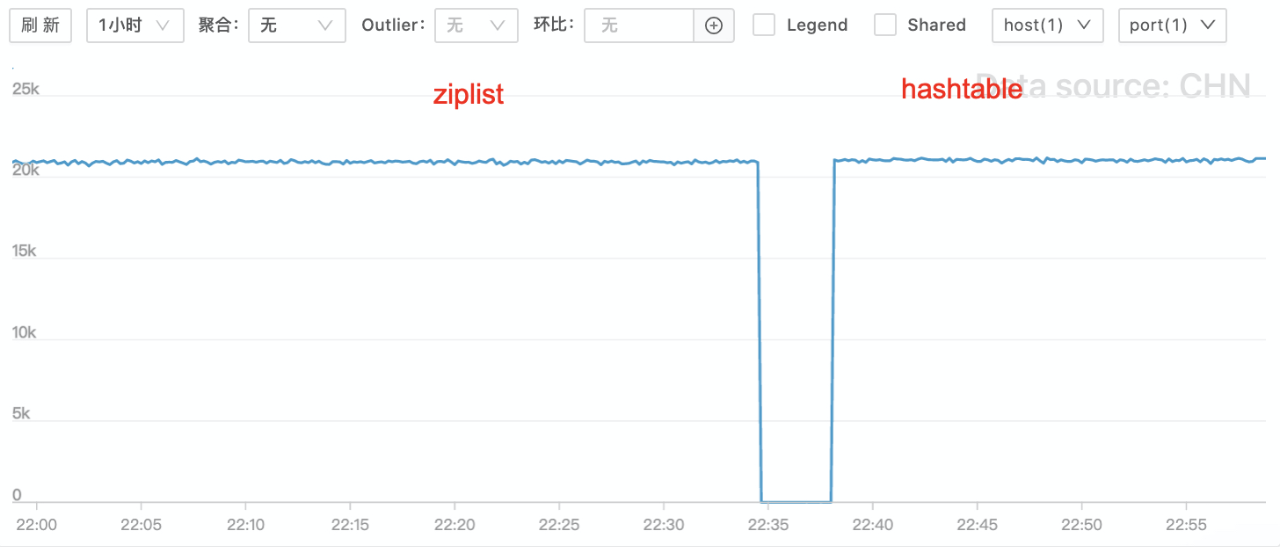
- P99耗时对比
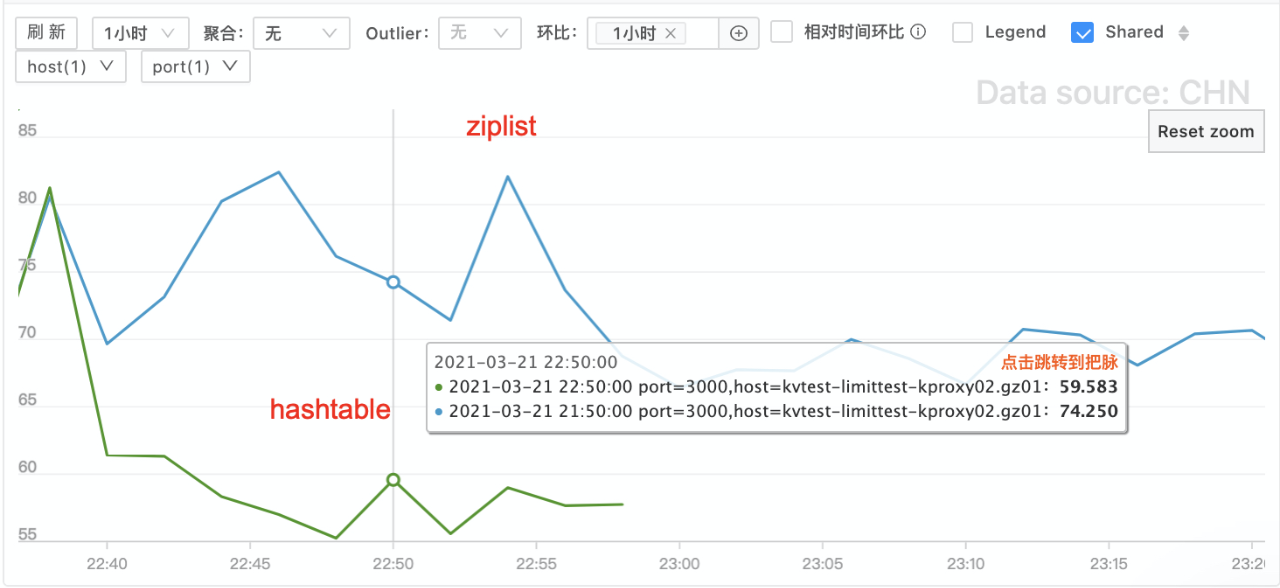
- cpu 利用率对比
- 哈希对象占用内存对比
| 编码方式 | 500个元素 |
| ziplist | 4.3MB |
| hashtable | 19.6MB |
测试结论
- hashtable 编码时(HEXISTS命令)的P99耗时下降14%(70us -> 60us)
- hashtable 编码时(HEXISTS命令)Redis 的 cpu 利用率下降72%(50% vs 14%)
hashtable 编码的内存占用是 ziplist 的4.6倍
补充说明:
- 每个哈希对象存储500个 field,每个 field 长度8个 Byte, 每个 value 是一个整数类型的时间戳
内存占用通过查看 info 中 used_memory_rss 指标统计的。这个指标其实从 /proc/$pid/stat 采集的,应该是最精确的内存占用数据了。单个对象是通过 debug object 查看,这个不太精确。
一个小插曲,之前测试时,使用 debug object 在获取 key 的内存占用量,忽略一个问题,这个命令是复用了 rdbSaveObject 这个函数,在这个函数中计算Redis 对象的长度时,如果系统参数 rdbcompression 设置为 yes,且长度超过20B就进行压缩,就导致了 debug object 输出的 serializedlength 值失真,在3.2.8版本上 ziplist 在 rdbSaveObject 函数中会进行压缩,hashtable 不会做压缩,因此 ziplist 编码时产生的 rdb 文件会小很多。在3.2.8之后的版本针对 hashtable 在 rdbSaveObject 函数中也做了压缩,产生的 rdb 文件大小相差就没那么大,这里只针对该case跑的3.2.8版本做了测试。
使用ziplist编码
redis-cli -p 5555 config set hash-max-ziplist-entries 512
OK
redis-cli -p 5555 config set rdbcompression yes
OK
redis-cli -p 5555 debug object mykey002
Value at:0x7fdf72868d40 refcount:1 encoding:ziplist serializedlength:3692 lru:5959713 lru_seconds_idle:35
redis-cli -p 5555 config set rdbcompression no
OK
redis-cli -p 5555 debug object mykey002
Value at:0x7fdf72868d40 refcount:1 encoding:ziplist serializedlength:34585 lru:5959713 lru_seconds_idle:35
使用ht编码
redis-cli -p 5555 config set hash-max-ziplist-entries 256
OK
redis-cli -p 5555 hset mykey002 mykey000000000000000000000001500 8c1dfc543d72c0826fc0968276932c88af7ed1deebd74d9c95c129fe6371500
(integer) 1
redis-cli -p 5555 config set rdbcompression yes
OK
redis-cli -p 5555 debug object mykey002
Value at:0x7fdf72868d40 refcount:1 encoding:hashtable serializedlength:33651 lru:5959748 lru_seconds_idle:0
redis-cli -p 5555 config set rdbcompression no
OK
redis-cli -p 5555 debug object mykey002
Value at:0x7fdf72868d40 refcount:1 encoding:hashtable serializedlength:33666 lru:5959748 lru_seconds_idle:
优化思路
经过上面的测试我们会发现 ziplist 在成本上会有优势,但是对于某些原来是O(1)的操作会变成O(N),如果追求性能,对成本不关注,或是只需对少数 Key 追求性能,可以从以下方面来进行优化:
1、Redis 服务端优化:
通过调整 hash-max-ziplist-entries 或是 hash-max-ziplist-value 配置项,从而控制哈希对象的编码方式,例如把 hash-max-ziplist-entries 从512改成256,那么超过256个 field 就会自动转换成 hashtable,但是要注意,如果你的哈希对象大部分都是超过256个 field,这么修改有可能会造成内存使用量大幅上升的情况,需要注意你的钱包。
2、业务侧优化方式:
在服务端做参数调整虽然简单,但是需要根据业务实际情况确定参数,且实际使用中元素数量会发生变化,调整参数没有可操作的条件,且在 key 数量多的时候还会造成不必要的成本浪费。如果是只有部分哈希对象需要关注性能,可以考虑在业务层针对单个 key 做优化。
- 满足 hash-max-ziplist-value 条件
例如在哈希对象中存入一个特殊 field,让这个 field 的 value 超过64B,这样这个 key 就自动变成 hashtable 编码,但是需要业务能识别这个特殊的 field,避免出现 bug。 满足 hash-max-ziplist-entries 条件
很多业务的哈希对象是经过一次拆分了,通过取模 hash 的方式拆分到多个哈希对象,也可以通过将拆分的哈希对象减少,从而达到满足单个哈希对象中 field 个数超过512个的条件。3、业务使用建议:
- 尽量避免热 key 现象
我们使用的是 Redis 的 cluster 版本,如果把业务的大部分流量都集中在某个或某几个 key 上,就无法充分发挥分布式集群的作用,压力都集中在个别的 Redis 实例上,从而出现热点瓶颈。 使用 list/hash/set/zset 等数据结构时要注意性能问题
需要根据自己的单个 key 中的 field 个数,value 大小,以及使用的命令等综合考虑性能和成本,如果需要了解自己的 key 的实际编码个数可以通过命令:object encoding 查看。总结
通过这次问题分析,我们可以看到 Redis 内部提供的不同编码会带来不同的性能和成本差别,建议大家在使用 Redis 时,也可以多了解自己的访问场景,根据实际情况来做一些调优。同时也提醒我们,时刻保持对问题根因的探究精神,才可以使我们自己的技术和业务能力不断提升。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞4作者其他文章
评论 1 · 赞 8
评论 0 · 赞 0
评论 0 · 赞 3
评论 0 · 赞 4
评论 0 · 赞 3
添加新评论0 条评论