分布式数据库切片布局自动化管理工具 - Akkio
## 1. 背景介绍
偶尔读到 OSDI 一篇关于 Akkio的 文章,了解到这个工具的具体作用和它如何在脸书粉末登场并发挥着巨大的作用,并帮助解决了脸书多数据中心架构下的数据局部热点问题,并且帮助脸书降低了 50%的用户访问延迟,减少了50%的跨数据中心流量,降低了40%的存储空间等 。既然这个工具有如此之巨大历史贡献,本人怀着浓厚的兴趣翻阅了相关的资料,记录了一些笔记,现在我想将其整理出来分享给大家。
2. Akkio是什么
Akkio本身是一个介于分布式数据库和应用客户端之间的组件,它是用来帮助分布式数据库实现何时、何处、如何迁移数据并且最终帮助数据库实现用户访问低延迟的工具。关于它的细节认识,我们将从以下几个部分来展开说明。
2.1 Akkio & Facebook
2014年,Akkio开始在Facebook的生产环境启用,主要应用于ZippyDB, Cassandra以及其他三种分布式数据库系统 ,管理着100PB数量级的数据 。那么为什么Facebook会在2014年的时候选择了这个工具呢 ,是什么样的背景呢 ?
首先,Facebook是以分布式数据库为其基本的数据存储架构,数据库是以切片的形式存在于世界各个不同数据中心内。Facebook有很多重量级的数据访问是以较高的更新比例(60%写比例)为基础的,这样的话就会造成它的多个数据中心之间进行数据复制,从而消耗大量的带宽和存储资源,同时大量的跨数据中心的数据访问成为必然,最终导致用户访问的延迟。
显然,对于这个问题采取更多副本的策略固然可以降低用户访问延迟的问题,但是带来更大的问题就是跨数据中心流量的暴增和存储空间的暴增。因此,Facebook急需要一种工具可以根据数据访问的热点程度来选择什么样的数据迁移到哪一个数据中心更适合大量热点用户的访问。
于是,Facebook选择了Akkio,那么接下来我们看看Akkio在服役期间的表现如何?
从数据库服务指标上来看,读的延迟降低到原来的50%,写的延迟降低到原来的50%以下,跨数据中心的横向数据复制流量减少到原来的50%以下,用来存全量副本的存储空间减少到原来的40%。从扩展性角度来看,Facebook业务系统整体的处理能力具备了十亿级用户并发处理能力,每秒处理能力达到数千万。
2.2Akkio的历史使命及适合的场景
从 Akkio在Facebook服役的过程,我们基本可以看到Akkio的贡献,也就明白了它的历史使命。
其实,除了Facebook这样的业务场景需要它,还有很多场景也需要它,总结来看我们可以认为有以下几个场景非常适合Akkio的功能展示(前提是适合分布式数据库的场景基础之上)。
- 云数据中心架构下的运营成本。减少数据副本数、存储空间和跨数据中心的横向数据通讯 ;
- 数据局部热点频繁变化的场景。 访问请求会不断 发生 变换,每个用户访问的数据也会不断变化;
- 数据库读写特点以读写均衡或者写比例相对较高的场景,帮助减少大副本复制 ;
- 分布式缓存效率低 ,无论读写,如果分布式缓存的命中率很低,势必产生大量的跨数据中心读写;
- 数据类型及大小更适合 Akkio的分布式数据库(下问会讲到Akkio对数据的管理) 。
3. Akkio架构设计及原理
3.1 Akkio组成
Akkio是属于客户端和分布式数据库之间的中间层,主要包括DPS(Data Placement Service)、Access DB、Location DB、Client SDK等几个组件 。 具体如图 3.1所示。
图3.1 Akkio 架构原理图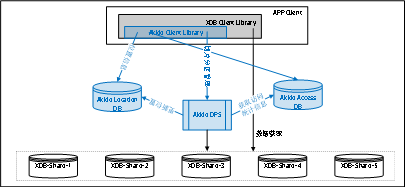
结合图3.1,我们来看Akkio架构组成当中的各个主要组件的功能:
l Client SDK:它是被安装集成在分布式数据库客户端组件当中的插件,负责与Akkio其他核心组件模块进行控制信息以及数据信息的交互。
l Location DB:它是分布式数据库在Akkio逻辑视图上的元数据,主要记录数据切片的位置信息。
l Access DB:它是数据访问的一个统计信息数据库,根据它来决定数据如何迁移。
l DPS:它是Akkio的核心组件,主要负责数据的迁移以及迁移之后的位置信息更新。
在了解了以上各个核心组件的基础之上,我们来看在这个架构下的数据的访问获取流程:**
- 应用客户端发起数据访问请求getdataBy(key,Value)。
- Akkio Client SDK 将数据访问请求getdataBy(key,Value)转化为getdataBy(µ-shard-id,key,Value)。这个µ-shard-id就是真正的数据所在的切片位置信息,只不过这个切片µ-shard是经过Akkio根据自己的视图逻辑划分的更小的数据库切片。
- Akkio Client SDK 首先访问Location DB Service,以获取µ-shard-id。
① 如果获取到µ-shard-id,那么返回并执行第4步。
② 如果没有获取到µ-shard-id,那么它会通知DPS进行切片的信息更新,然后重复执行。 - Akkio Client SDK 告诉分布式数据库客户端去哪个DB Shard当中去获取数据。
3.2Akkio & µ-shards
Akkio的历史使命就是优化数据的布局以降低用户访问延迟、减少跨数据中心流量、降低存储空间等。那么如何达到对数据布局的优化呢?这就一定会涉及到数据的逻辑视图问题,也就是它对数据如何定义、划分、组织等一系列问题。这就涉及到一个非常重要的概念μ-shard。
l Akkio 将原来分布式数据库非常大的切片(Shard),分割为非常小的切片单元( μ-shard )。
l Akkio Client SDK来决定 μ-shard的创建,不是分布式数据库。
l μ-shard的大小通常为几十K到几百K,不超过M。
l Akkio 将 μ-shard与分布式数据库切片的映射关系存储在Location DB当中。
l Akkio Client 数据访问统计信息是以对 μ-shard的访问频度进行统计的,并记录在AccessDB。
l 当新的 μ-shard 分片被 Akkio Client 创建时,通常情况下会在距离请求的客户端最近的数据中心选择副本存储数据并在相邻的数据中心中选择负载较轻的作为备份。也可以直接使用简单的哈希函数来决定数据存储的数据中心。
3.3Akkio工作原理
关于Akkio的工作原理,其实主要要搞清楚3个关键问题:Akkio何时决定要迁移数据?Akkio如何决定数据的迁移方式?Akkio如何保障迁移过程当中的数据一致性?
- Akkio何时决定要迁移数据?
当Akkio Client 访问数据的时候,如果它发现获取到的μ-shard-id是在远方数据中心的DB-Shard当中,那么它会通知到DPS,这个时候DPS会检查是否需要进行μ-shard的迁移。这是主动的触发,另外一种就是Akkio DPS在后台的异步检查被动触发。
- Akkio如何决定数据的迁移方式?
很显然在这个问题当中,我们首先需要找到要迁移的对象,然后需要找到迁移的目的地。如何找到这两个核心参数,Akkio主要是要依靠Access DB当中的统计信息以及分布式数据库的实例统计信息,在Access DB当中记录着客户端发起的对不同的μ-shard的访问信息。
Akkio以每一个μ-shard为单位,也就是说在主动触发的场景当中,Akkio通知DPS的那个没有从就近获取到的μ-shard数据就是我们可能要迁移的数据对象。针对这个数据对象μ-shard,Akkio会计算不同的数据中心针对这个μ-shard可以得到的加权分,得分最高的数据中心就是这个μ-shard数据的迁移目标,同等得分情况下,Akkio会根据数据中心资源的情况再进行筛选,例如CPU、Memory、IO等统计信息。
关于数据中心的得分情况,主要是参考两个指标:数据被访问的次数、请求的远近程度。访问的次数越多得分越多,访问距离本数据中心越近权重越高。
- Akkio如何保障迁移过程中的数据一致性?
数据迁移的过程当中可能会遇到两种情况,一种就是在迁移的过程当中,μ-shard同时获得了更新的请求处理。另外一种就是在迁移的过程当中获得了其他读的请求。对于Facebook的ZippyDB的解决方案来讲,它是通过锁权限控制来实现的。
(1). 获取 μ-shard上的锁权限,并标记为迁移列表中的元素;
(2). 将迁移原数据μ-shard以及迁移目标μ-shard都设置为只读权限;
(3). 从源数据中心将μ-shard迁移到目标数据中心;
(4). 更新Location DB信息;
(5). 删除源数据中心当中的μ-shard,将μ-shard从迁移列表释放,并且释放锁信息;
当然,这里也可以通过源数据μ-shard和目标数据μ-shard同步接受更新的方式来保持数据的一致性。
4. Akkio如何完成其使命
4.1 用户访问延迟
我们通过对Facebook的数据了解到:Akkio的应用使得Facebook的用户访问延迟降到了原来的50%。那么从理论上来讲,增加了Akkio之后,数据访问的深度加了一层,数据映射增加了( μ-shard-DB Shard )维度,而且增加了数据寻址的复杂度,数据访问的延迟应该是增加了啊 。
但是我们通过DPS的迁移,将热点的 μ-shard数据迁移到客户访问相对最近的数据中心,那么数据在从分布式数据库存储系统到客户端这个过程却是避免很多的远距离传输,将大部分的跨数据中心远距离传输转化为大部分的就近访问,这部分节省下来的时间相对于寻址复杂化来讲要可观的多,尤其是在海量数据多数据中心的云架构当中。
另外,数据中心之间的数据流量减少必然会改善通道传输质量,少数跨中心访问也会比原来好很多。
4.2 跨数据中心横向流量
我们知道分布式数据库的副本数是根据数据库的整体策略制定的,用户数据是一定的,数据副本的绝对数量也是一定的,为什么在Facebook的数据当中会减少50%的跨数据中心横向流量呢?
其实分布式数据库进行数据副本的复制的时候,一般都是日志回溯的模式,也就是说在数据中心之间传递的应该是一些事务日志,并不是大量的用户数据。所以真正占用跨数据中心带宽的还是客户端请求的用户数据,正因为Akkio具备将数据以 μ-shard为单元进行优化布局的能力,才减少了大量的跨数据中心请求,最终导致跨数据中心横向流量的减少。
因此,这个问题与4.1当中的问题其实是一个问题。
4.3 存储空间
假定我们把分布式数据库的副本数看成是一个固定的数字,比如是3。那么在这个前提条件下,大家可能无论如何都不觉得Akkio能带来存储空间的节约。因为无论如何去切分数据,数据副本数都是3,怎么可能节约存储空间呢?
但是我们从另外一个角度来看,Facebook的业务横跨全世界的很多数据中心,如果仅仅是基于高可用或者容灾角度的三副本机制,那么随着业务的不断扩展,用户访问体验必然越来越差。因此提高数据的副本数是在没有Akkio的场景下,提升用户访问体验的一种手段,副本数越多,意味着用户访问的平均路径会短,延迟就会低。但是这样解决问题意味着要以倍数的程度投入存储资源。
所以从这个意义上来讲,原来10个副本才能实现的用户体验,用了Akkio之后,可以以5个副本的策略达到同样的用户访问延迟,那么存储空间是不是节约了一半?
5. 总结展望
Akkio 从2014年进入Facebook ,管理 着 100PB的数据量。 帮助Facebook 减少了高达50%的访问延迟、高达50%的跨数据中心流量和高达40%的存储占用空间。 本文 通过对Akkio 架构、原理以及它如何实现它的目标 , 可以知道 Akkio 通过合理利用用户的访问 统计信息 , 优化 数据 动态 布局 ,使得数据更加 贴近用户, 不仅提高用户体验,而且节约IT运营成本 。 看起来,这是一个非常有意义的工具。但是 Akkio并不适用于所有 的场景 。 因此,基于此类思路的启发,在今天的多云分布式环境下找到更多适合的场景,那将是非常有意义的事情。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1作者其他文章
评论 5 · 赞 4
评论 10 · 赞 17
评论 2 · 赞 14
评论 0 · 赞 10
评论 7 · 赞 1
添加新评论0 条评论