
“城商行核心业务系统实现同城双活建设及双活切换难点活动”24个典型问题总结
前言
众所周知,双活数据中心并不是一个行业标准或者规范。行业的标准是对RTO和RPO约束,银监局和中国人民银行对商业银行业最严格的要求标准是5级容灾标准:RPO=15分钟,RTO=30分钟。而根据国际标准Share78,六级容灾标准是:RPO=0,RTO=分钟级;七级容灾标准是RPO=0,RTO近似为0。因此双活的概念也就由此而来,为了达到国际最高标准。那么决策是否建设双活数据中心的依据也就在于此,首先确定自己企业合适的目标,是不是所有业务都必须追求这个目标?如果不是那么首先要对企业业务进行细分并详细规划每一个业务的容灾目标。这将决定要不要建设双活数据中心以及建设什么样的双活数据中心。
而银行业的核心系统就是这样一个追求极致RPO和RTO的容灾目标,它是银行最为重要的系统,是生命线和底线,一旦信息科技风险越过了这条底线,银行的整个金融信息系统将全面瘫痪,后果不堪设想。所以为了牢牢守护住这条命脉,银行一直在不断的寻求更好的技术和更优的解决方案,来对核心系统的优化之路进行探索,这其中之一便是核心系统的同城双活建设。从核心系统的业务层面来看,能够实现核心系统业务在双活数据中心进行分发且自动切换从而保障业务的连续性。那么我们认为这样的目标就实现了应用级别的双活。基本上能够达到6级标准或是我们所述的应用级双活,这其中需要基础架构层面很多关键技术体系的支撑,同样也会有很多的关键问题需要解决。在这样的背景下,twt社区邀请到了浪潮商用机器的专家以及全国各地20余名银行IT技术专家和架构师们线上分享了他们的实践经验,大家互问互助,共同答疑解惑,可谓十分精彩,感谢这些专家嘉宾的精彩分享,现在我就大家提出的宝贵问题进行一个全面的梳理和总结,希望对大家有所帮助和借鉴。
一、核心系统双活方案下的建设思路和方法论方面
【Q1】双活方案思路之技术方案如何选择 ?需要考虑哪些点?
【A】lnasman 行业架构师 , 浪潮商用机器企业云创新中心
谈到双活就必须要从IT业务连续性管理这个话题谈起。只有从根上我们知道这个需求以及技术方案是怎么生长出来的,我们才能够彻底搞清楚,用户在什么情况下适合什么样的解决方案,以及未来技术解决方案的走向。为了保证IT系统对业务支撑的连续性,在HA高可靠方案的基础上,生长出来了DR的概念。即如果由于某些不可抗力原因,如火灾、地震、公共卫生安全事件、或其他原因,导致单数据中心整个出现问题,如何能够保证IT能够继续有效运行。在这个概念下提出了RTO以及RPO的概念。所谓的双活方案就是在这样的概念下生长出来的。及如果RTO和RPO都双双等于零,那就是所谓的双活方案。针对应用服务器场景,由于Load balance解决方案(这里又分为有状态和无状态两种)已经非常成熟了。因此一直以来应用服务的双活方方面面的都问题不大( 老旧应用改造除外 )。核心需要解决的问题一直是数据库层面上的双活问题。目前针对数据库双活的解决方案有很多种。总的来说分为两大类:原生数据库双活(多活)方案以及传统数据库的双活方案。 1.原生数据库双活(多活)方案。目前新型的分布式NewSQL数据库,在系统设计方面就充分考虑到了双活/多活的需求。因此原生满足。目前对于这类数据库典型的实现方式有两种: 方法1:在数据库底层建立统一的分布式存储系统,数据库实例写下来的数据同时写多副本。这些副本可以分布在多个数据中心上。在数据库实例端,可以做多个集群多实例方案,或者也可以做快速服务切换方案。因此任何一个数据中心出现问题,都不会影响。这里典型的方案如巨杉数据库。
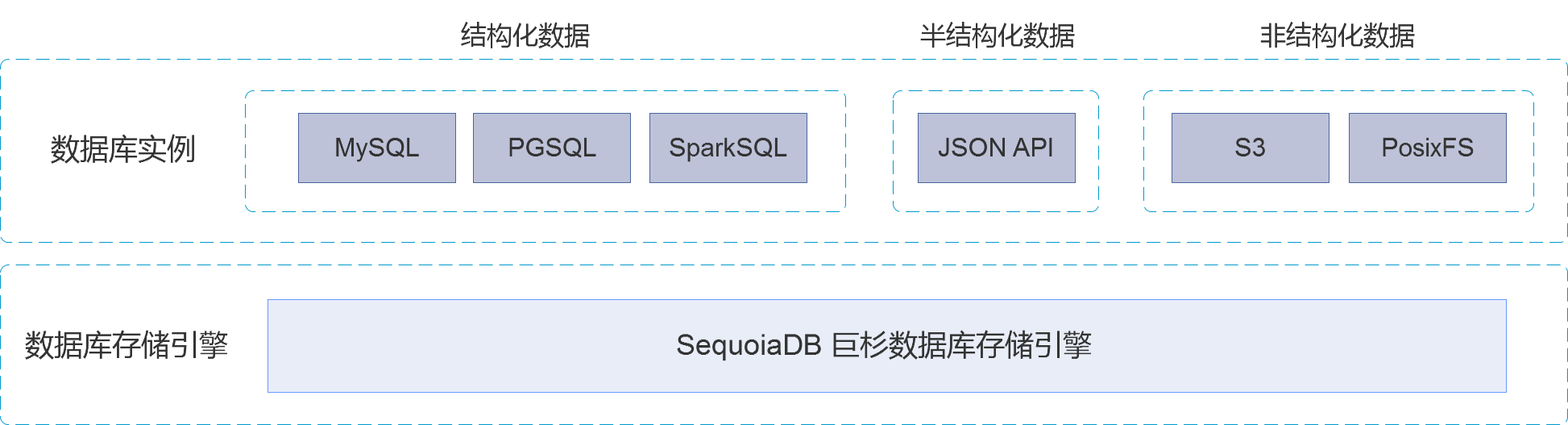

方法2:在数据库底层建立统一的KV数据库集群(目前用RockDB的居多)来解决数据文件跨节点,跨数据中心存储的问题,并通过Raft机制来实现数据同步和跨数据中心切换。数据库实例层的设计方式和方法一类似。这里典型方案如TiDB。

综上所述的两种方法来看,其实原生的数据库双活解决方案也没有太多神秘,基本的解题思路依然是在分布式存储层来解决问题。只是实现的技术路径不同而已。 2. 传统数据库的双活方案:这里讲的传统数据库如Oracle, DB2,Informix等。由于这些数据库本身并没有在原生状态下考虑双活问题。因此双活方案都是在原生体系外面通过附加解决方案来构建的。这类解决方案基本上也都是在解决一个问题:就是如何将多块部署在不同数据中心上的数据盘(数据块)逻辑上merge成一个。从接替思路上基本上有两种: 方法1: 通过存储设备层实现。如EMC的vplex解决方案,IBM的SVC解决方案,IBM的HyperSwap解决方案,浪潮存储双活方案等。都是通过存储层来实现的。

方法2:通过分布式文件系统实现。例如题主在问题里讲到的GPFS解决方案,就是属于这一类。通过GPFS分布式文件系统的Failure Group功能,将另一份双活数据同步地写到另一个数据中心去。
以上是对目前市面上的一些双活方案的技术总结。下面再来谈谈双活方案的优缺点。先来谈谈优点:数据中心切换时间短:这个优点是必然的,虽然在技术上无法实现完全的RTO=0,但是基本上可以控制在秒级。这已经非常不错了,无论是在银行、证券。还是在社保、公安户政、交警、这个级别的可靠性保证妥妥地没问题。数据中心故障切换自动化:自动化切换是切换时间短的技术性保证。没有自动化切换是不可能做到这么短的切换时间的。再来谈谈缺点:建设代价高:为了保证RTO和RPO同时为0,需要满足的条件是非常苛刻的。1) 是两个数据中心的距离必须要短,最好在5公里以内。否则的话数据在两个数据中心间的同步会拖慢整合业务系统。让用户感知下降,这个是我们最不希望看到的。2) 网络链路要求高:网络链路延迟必须要低,并且不能有网络抖动现象。最好是有单独独立的光纤。3) 建设费用高:即使是只有上述两点要求,这个建设的费用也是相当不低了。运维代价高:如果从应用系统级别就要实现双活的话,那么就设计到应用服务器集群双活、数据库双活、网络双活的多个方案集成。这个集成的复杂度,光想想看心里基本上就有点数了。因此对运维团队的考验是相当大的。最后的建议:双活虽好,是不是和每个客户的场景,这个问题就见仁见智了。个人认为,适合自己的才是最好的,不一定非要追求指标。即使是追求双活,也可以从一个层面上去考虑,简化技术架构,做好高可用,减少低级错误,有的时候比双活对用户更有意义。
【Q2】如何从整体上考虑核心系统同城双活?核心系统同城双活,极大缩短了核心系统故障恢复时间,提高业务系统连续性,如何从整体上考虑核心系统同城双活,如主机,存储,数据库,负载设备,共享文件系统,网络,应用程序等。
【A1】ZTC 售前技术支持 , 浪潮商用机器企业云创新中心
我觉得主要从以下几个层面考虑:1. 从整体架构上来看,通常关注网络层、应用层、数据库层和存储层这几个层面,对于网络层要求双中心间二层打通,实现双中心间业务引流;对于应用层,采用GTM & LTM 联动技术实现跨数据中心保护;对于数据库层,采用跨数据中心集群部署,系统保留ADG等类型的复制模式;对于存储层,通过各家厂商的存储双活技术实现跨数据中心集群部署。2.从成本角度考虑,主要包含设备购买成本、建设成本、运维成本。这块比较难估算,因为不同地域,不同公司资源的情况下成本会有较大出入。设备的购买成本主要包含应用主机、存储、核心以太交换机等;建设成本包括前期规划、实验室确认参数、业务场景下业务测试、安装调试、真实环境压力测试、切换演练等方面,以上均需要人员成本的投入;运维成本取决于自动化程度的高低,通常情况下如果各节点完全可实现自动切换,相对的复杂度也有所提高,对于运维人员的技术要求有一定限制。3.从技术成熟度和方案及方案健壮性方面来看,刚才在上面第一点中提到的四个层次所使用的关键技术,目前已经非常成熟,各厂商均有成熟的解决方案。使用如Power上的双活方案,基于存储的双写复制的技术,数据库的基于事务日志回放的数据技术,以及基于系统级逻辑卷镜像技术,这些技术均有成熟的方案,在很多银行也有实际落地的案例,并且已经稳定运行了好多年;4.需要充分的风险评估,比如要解决数据库和存储仲裁不一致,集群发生脑裂的问题,如何解决应用负载会话一致性的问题,如何解决I/O时延,如何应对光纤抖动,如何解决资源高度冗余导致资源浪费问题。这些都需要在企业架构范围内考虑,也并不是所有问题都能在技术层面解决;5.除此之外,还需要考虑功能拓展性问题,对于功能的拓展性,以业务功能拓展性来说,当前设计的双活架构应不仅仅适用于核心系统,也适合支持未来其他重要的业务系统使用。
【A2】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
这问题比较宏观,同城双活概况上来讲要考虑的层次有:1、网络层;2、应用层;3、数据库层 - 存储层。这几层的实现难度是不同的,通常网络层和应用层比较容易实现,成熟的产品和方案也比较多,因为这两层只分发请求,不处理请求,比较容易横向扩展,也基本不存在相互间需要同步数据的问题。问题中的负载均衡设备,网络DNS调度、应用横向部署等基本都在这层解决。 数据库层双活,就涉及到问题中提到的数据库和共享文件系统等问题,这些也有成熟的解决方案,比如数据的Extend RAC、分布式文件系统、GPFS等数据同步,但从这层开始就设计节点间数据同步的问题了,就需要根据实际的需求和成本的评估进行技术的取舍。比如线路不稳定、带宽不够等因素就不适合做同步双活和复制。 存储层的数据复制,在各厂家的中高端存储中是都能实现的,也要根据线路,距离等因素抉择复制的方式。
【Q3】同城双活建设在技术选型,双活系统规划,双活切换以及双活能力评估上是怎么落地的?
【A1】zzy3620 系统环境管理 , 北部湾银行
这个问题也在于双中心硬件投入上的规划,如果双中心能做到1:1或者2:1的资源投入,那么就具备做真正双活中心的基础,如果只有5:1或者10:1甚至更少的资源配置,那同城数据中心在独立运行时都不具备完全承载业务的可能性,也可以选择将一部分系统做双活规划,部分系统作互备模式或者主备模式。
【A2】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
数据中心的双活,不同的客户有不同的理解,通常的理解是指两个数据中心均处于运行状态,可以同时承担一定的业务能力。但根据备中心能够承载的业务能力来区分,又可以分为以下几种:主备模式:即生产中心完全承载主生产任务,备中心只是进行数据的同步或异步复制,保证灾难时备中心的数据完整性。互备模式:企业的业务按照策略,一部分业务在A中心部署生产,B中心部署备份。另一部分业务正相反,在B中心生产,在A中心备份。准双活模式:两个中心在业务和应用层均有部署,且可以通过负载均衡从前端分别向两边分发业务请求。但两边均访问主中心的数据库和存储设备,数据仅仅是通过同步或异步方式备份到备中心来保证备中心有一份完整的数据。双活模式:双中心同时提供应用层、数据库层和存储层的访问能力,应用层均衡地提供业务的接入能力,数据库和存储层的数据实时同步,两边的数据实时完全相同。从实践来看,主备和互备模式的实现相对简单,这两种模式也都是数据级的双活能力。准双活和双活对技术要求较高,对两中心间的线路要求也较高。企业如果进行双活建设,要想好自己期望实现的双活模式,同时综合衡量数据中心环境和成本。
【Q4】俗话说:“三分技术,七分管理”,在规划、架构核心系统同城双活时,对运维、管理人员有哪些要求?
【A1】light_hu86 系统工程师 , 某省金融
在技术转为自动化、智能化的今天,对人员要求也是越来越高,虽然部分工作机器能进行替代,但无法全部替代,因此对于运维、管理人员来说,明确此趋势,还是要从以下几点进行考虑: 1、明确队伍组成,分工、人才储备、确定管理人员,一个队伍合适的管理是关键;2、技术的储备,运维人员从运维出发,相关的技术都需要了解,以及快速处理相应的故障;管理人员则需对顶层规划、业务流程、相关技术进行了解,把握趋势;3、排好计划,什么时间点做什么事情,进行相应的时间和进度管理。
【A2】zzy3620 系统环境管理 , 北部湾银行
对于管理人员,需要根据项目的时间要求做好任务的分配和实施进度的把控,尽量让自己的人能做到技术上集体讨论,群策群力,不区分专业全流程参与。建议运维的人从架构设计的时候就全程参与,包括后续的详细规划例如分区的安装、网口和网络的规划、操作系统数据库的安装,参数优化,容量的规划,只有对架构和实施都比较熟悉的人,才能做好整体的运维,临危不乱。
【Q5】双活的平衡点?双活带来连续性提升的同时,可能某些场景下降低系统可用性,同时增加系统复杂性和提供运行成本。双活如何建设,如何拿捏好各系统平衡点?
【A1】zzy3620 系统环境管理 , 北部湾银行
双活带来连续性提升的同时,往往因为需要对远端进行数据复制造成一定的性能损耗,这个性能损耗视不同的复制方式会有区别,如果采用异步模式则基本可以忽略。对于重要的应用系统,需要把数据安全性和系统连续性摆在第一位的,宁愿多花一些成本去强化硬件平台、优化软件设计和代码以提高系统性能,补足双活带来的性能消耗。
【A2】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
双活是一个建设目标,但从城商行用户的实现角度来看,并不是一步到位的。平衡点一方面是建设和维护成本与希望达到的RTO和RPO间的平衡,另一方面是技术复杂性带来的衍生不确定性增多和人为可控之间的平衡。目前看,双中心实现数据级主备中心 或者 双中心在不同业务上互为主备实现起来相对成熟,成本也可控。真正的业务层面双活,对业务读写比类型以及线路要求都较高,客户处于探索阶段的比例较大。
【Q6】核心业务系统同城双活建设如何解决业务高并发与双活带来的性能影响之间的矛盾?
如题,核心业务系统日间高峰期业务并发高,压力大,响应时间要求高,日终批量业务对数据库的增删改操作多,如果建设了核心业务系统双活,势必带来一定的性能影响,如何有效解决或者缓解该问题是建设核心业务系统同城双活的重要问题。
【A1】zzy3620 系统环境管理 , 北部湾银行
双中心架构如果采用extend rac,则关键在于减少跨中心节点间的gc,要做好应用功能的区分,尽量避免出现应用向两个不同数据中心rac节点读写同一张表的的情况。对于跑批类的应用,应当尽量指定连接固定的vip,而不是scan ip,这样能提高跑批的效率,也能避免出现gc,从而提高整体响应速度。
【A2】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
考虑业务建设双活架构,有几个需要注意或规避的问题,其中之一就是写操作特别多的业务是不太适合做双活的。至少在当前普遍的线路成本和线路质量的条件下,不是很适合。 大量频繁的写操作,在双活的需求下需要实时同步到同城中心,即使是在线路带宽够的情况下,临时的抖动也会因为对端确认不及时带来业务的响应时效增加而性能下降,这个问题非常依赖于稳定的线路质量。
【Q7】分布式架构的系统如何双活?随着互联网业务的发展,分布式架构在银行业信息系统应用越来越广泛,分布式架构双活如何考虑?单套扩展还是双套并行,单套扩展是否会有网络流量压力,并行如何解决缓存问题等等
【A1】light_hu86 系统工程师 , 某省金融
双机房网络质量还是需要保障的,目前我中心双机房为80-100公里,延时大概为5毫秒左右,相应的双活如对延时比较敏感,实现效果较差。
【A2】zzy3620 系统环境管理 , 北部湾银行
个人感觉一套还是两套运行,主要需要考虑的还是网络质量,如果网络质量有保证,单套扩展的架构属于双中心的紧耦合架构,架构上比较简单清晰,双中心间的业务分发策略、业务间的访问关系配置也相对比较简单,但是单集群的风险在于如果网络出现明显抖动,可能带来的是整个集群的性能下降或者卡顿。双中心松耦合,部署两套集群的缺点就在于部署比较麻烦,双中心的业务间访问关系配置较为复杂,负载均衡分发策略相对复杂,优势就在于即使一个集群出现问题,也还有一个集群能继续提供服务。
【A3】李松青 软件架构设计师 , 浪潮商用机器企业云创新中心
分布式架构下,多副本数据读写各节点之间传输本身会有很大的网络传输要求。所以一般分布式建设双活时,也是建同城双活,把其中1个或少数副本 同步到双活备中心,同城备中心一般只承载少量查询业务。你说的双套并行 一般是一套主生产中心,远程建一套异步(非同步)复制的容灾环境。分布式国产数据库如巨杉数据库、中兴GoldenDB、腾讯TD-SQL等都有双活及两地三中心方案:

【A4】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
分布式架构的双活,目前看更多的还是依赖于其自身的多副本部署策略。看各家的方案中,单套拉伸距离进行扩展的居多。对两中心之间的网络质量需求比较高。
二、核心系统双活方案下的数据保护和存储层复制方面
【Q8】核心数据的的保护方案?如何实现核心系统数据库层面的跨数据中心保护? 包括访问连续性保护和数据本身的保护?数据库又如何切换至同城数据中心?
【A1】 summit 系统架构师 , 城商行
首先这个问题标题覆盖不全。1、首先数据库的保护无非几种,1)通过备份软件进行数据定期备份。2)通过存储底层数据复制进行灾备数据保护。3)通过数据库本身的备份机制进行数据保护(比如oracle ADGOGG,mysql的副本方式)。4)数据库双活灾备保护(此方式不能防止数据库逻辑损害,一般结合备份进行数据保护)。2、切换同城数据中心(你的核心是双活或者读写分离还是主备方式,这个很重要,不同的应用灾备方式切换的步骤都不一样)结合应用和数据库部署方式有N种组合和切换步骤。
【A2】fengjian 系统工程师 , 浪潮商用机器企业云创新中心
以PowerHA SystemMirror HyperSwap双活方案为例:PowerHA SystemMirror 企业版提供 HyperSwap 功能实现数据中心双活功能。 PowerHA HyperSwap 是基于 POWER 平台及 DS8K Metro Mirror 同步复制技术,当主存储系统不可访问时 ,AIX 透明地将磁盘 I/O 切换到备存储 , 并且不影响正在运行的应用,从而提供数据中心之间 ( 或数据中心内 ) 存储高可用及应用高可用的一种容灾方案 , 也是 POWER Active-Active 解决方案的重要组成部分。PowerHA HyperSwap 能与 OracleRAC 完美结合,实现数据库无中断的快速切换,与传统解决方案相比,其切换更加自动化、 RTO 更短, RPO 为 0 。PowerHA HyperSwap 双活解决方案具有明显的优势: 监控从应用到存储各个层面,并提供每个层面故障处理方案; 结合 DS8K Metro Mirror, 保证高性能及数据传输稳定可靠; 支持部署 Oracle Extend RAC ,实现真正意义的双活中心; 充分利用双中心的服务器、存储资源; RTO 为秒级, RPO=0; 一键完成高端存储容灾演练,应用不受影响; 可设置当脑裂或站点故障发生时自动响应或人为干预策略。
【A3】邓毓 系统工程师 , 江西农信
1、核心系统数据库层的跨数据中心保护要建立全面多层次的保护,包括底层存储级复制、数据库级复制、数据备份,三位一体,防范各种类型的故障。2、连续性数据保护又叫CDP,属于数据备份的一种,通过一次性全量同步底层存储数据和实时增量捕获数据来实现小间隔时点数据的恢复,这是一般的备份做不到的,一般的备份RPO太大,满足不了小间隔时点的恢复要求,这时就要用到CDP去做。3、数据库切换按照数据复制的方式不同而不同,若是底层存储级复制,必然是要经历生产端先停止应用和数据库、卸载存储盘、等待生产和同城数据完全一致、复制关系反转、同城端挂载存储盘、启动数据库和应用等过程;若是数据库级复制,则要经历停应用、切换数据库主从关系、挂载对外服务IP、启动应用等过程。
【Q9】存储数据实时复制技术?如何实现核心系统存储层面的跨数据中心复制? 采用什么样的复制模式? 采用什么样的复制技术等?
【A1】summit 系统架构师 , 城商行
这个问题有点不好回答,主要不特别具体。存储数据复制技术基本无外乎三种同步、异步和双活。如果要建双活的话就采用存储双活架构(SVC或者vplex等虚拟化引擎),但是的结合应用和数据库部署方式进行选择。并且要结合双活建设的目标来制定相应的方案。
【A2】邓毓 系统工程师 , 江西农信
1、核心系统存储层面的复制根据所用存储厂商的不同而不同,知名的复制方案有:EMC的SRDF,华为的 HyperMetro、IBM的MetroMirror、HDS的TrueCopy、NetApp的SyncMirror。2、实时复制那就只能是同步模式。
【A3】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
核心系统存储的跨中心复制,通常是中高端存储都会包含的功能。我理解问题中的复制模式,是指同步或异步。 根据客户两中心间的线路质量情况、线路带宽情况以及想实现的RTO、RPO不同,来决定是同步还是异步。在各厂商存储的中的命名可能会不同,但基本功能是类似的。
【Q10】同城双活核心系统数据一致性宜采用数据库同步模式还是底层存储同步模式?是否有必要同时采取两种模式?
【A1】李松青 软件架构设计师 , 浪潮商用机器企业云创新中心
个人完全同意前面专家们的说法,同城双活核心系统有必要同时采取数据库同步和存储底层同步两种模式。也还要看数据中心所具备的条件和人员技术储备情况,来选择具体方案。1. 如果具有同城几十公里内非常稳定且带宽足够的网络条件,那可以按照一步到位的真正A-A双活、同城数据中心同时读写(Extended RAC or PureScale GDPC) 各承担一部分业务来建设。这种情况下,可以优先考虑数据库同步模式的数据库双活方案。而底层存储同步模式作为更远距离的备份容灾方案,至于是做成同步还是异步的存储级备份容灾方案,同样取决于传输延迟和带宽条件(当然这里用DG或HA/DR等数据库方案取代底层存储复制也是可行的)。 当然数据库上drop table, delete数据误操作之类的逻辑错误,首先得靠制度保障,其次得依赖数据库层面的闪回技术来做为一道保障。2. 如果同城带宽和延迟 达不到生产数据库高峰时产生日志和变化数据量需求,那应该优先选择存储底层同步技术,主生产中心负责全部业务,同城中心作为备中心随时待命 准备接管可能发生故障的生产中心。此时数据库同步技术也可以做为辅助手段(DG 或 HA/DR),多做一个数据库同步或者准同步的日志备份,万一底层存储复制技术因为数据逻辑一致性问题(出现概率低,但理论上有潜在可能),可以用作第3个应急接管预案。
【A2】zzy3620 系统环境管理 , 北部湾银行
发表一下个人见解,数据库同步和存储同步虽然说都是双中心复制的可用方案,但是从技术稳定性来说,存储的同步复制以及存储双活相比数据库的复制更为成熟,只是存储的复制在切换时,切换操作要复杂的多,可能导致RTO时间变得很长。在核心这样的业务系统上面来看,双中心其实最为基础的需求还是要保存一份完整的数据,因此,存储的同步是保证双中心数据完全一致的最后底线。在far sync架构下,只有在主数据中心运行该套rac的服务器存储以及运行far sync的服务器存储同时宕机的情况下,才会可能发生主备数据中心间同步数据丢失的情况,通常意义这意味着主数据中心整体掉电或者发生主数据中心的整体灾难。在这种情况下,存储的复制是仍然会保证数据的一致性的。因此,对于核心这种关键系统,还是有必要同时采取两种模式的复制的。
【A3】邓毓 系统工程师 , 江西农信
作为银行的核心系统,我觉得完全有必要同时采取两种模式 1、底层存储同步是块数据的物理一致性保证,保证了数据级容灾需求。但同城端的这份数据不可读不可写,要利用起来需要再对该数据卷进行快照挂载使用。2、数据库同步模式是通过事务日志的方式再写一份日志到同城端,保证了数据的逻辑 一致性,且在同城端是可读的,这也是数据读写分离的经典方式。3、块数据的物理一致性无法保证数据的逻辑一致性,真正面向业务的数据必须是逻辑一致性的,所以为了最大限度的保障数据安全性,有必要再做一份数据库级的同步。4、数据库级的复制覆盖面不全,只能涉及到事务级别的数据,其他文件系统中的文件数据覆盖不了,所以这部分数据就必然要用到底层的块数据同步。5、数据库级的复制需要消耗一定的主机性能,而且实施起来麻烦,需要停机。而底层存储复制实施比较简单,可在线实施,不消耗主机性能。
【A4】bbaimm88 系统架构师 , 银行
对于核心级别数据库,强烈建议多种方式保护数据,核心一致性对于全行业务极其重要,但不要仅仅局限于一致性,核心其安全性与可用性也非常重要,比如在数据不丢失情况下,发生机房级别故障,恢复时间过长,可用性大大降低,肯定不可取,又比如有删库或者破坏力的DDL、DML造成数据不可逆,其安全性也大大降低,以上两种都是致命的。因此,你要业务连续性来考量,不要过于集中技术层面定位。既要解决数据一致性,也要解决安全性,可用性。1从高可用层面解决数据库高可用,数据库集群。2容灾保护做好数据复制(数据库级别复制,存储级别复制;同步异步都可选,根据你们机房距离来定,存储双活解决方案多, 数据库双活目前仅Extend RAC【不讨论分布式】)3最后一道防线 备份系统要上,很多人吧数据库复制当做最后一道防线是存在误区的, 一个DDL、DML 的drop delete 一下就洗白数据。 备份频率一定要高1小时至少一次以上。 备份在手,不跑删库跑路【分权管理,禁止一人管理】数据同步有多重解决方案,1存储同机房双活,异步到灾备,2 直接跨机房双活一步到位,数据库亦如此。各有难易点,根据你行系统人员与DBA人员 技术贮备来定。 不要道听途说。 那个实力强就选那个。
【A5】张鹏 技术总监 , 中国金融电子化公司
如果将底层存储理解为物理层的数据块同步复制,将数据库理解为逻辑层的数据块同步复制。个人认为两种方式可以互为补充,同时采用。存储厂商一定会强调,通过底层物理数据块的同步复制是可以保证数据一致性的,但是实际的应用环境中,确实出现过物理数据块和逻辑数据块不一致的情况。这的确是一种小概率事件。如何规避这种问题呢,简单方式是采用定期验证的方式,在灾备环境中通过快照等技术验证灾备数据是否可用,以及数据的一致性和完整性。如发现这种情况,采用全量或者增量比对,追补等方式修正异常数据块。存储技术其实最大的好处,就是屏蔽了逻辑层事务逻辑不一致的问题,用户获得的是某一个时间点的物物理磁盘状态,不用关心上层逻辑。而采用数据库层面的复制,虽然逻辑块的故障能够及时的发现,但是需要关注的是事务的一致性。
【Q11】生产同城相距30公里,数据库层,能否实现双中心同时读写一体化?
读写一体双活,拿oracle来做解释,是oracle中大家比较熟悉的oracle extend RAC。这种方案很多存储厂商曾经推广过,oracle厂商最近很少推荐。这种方案也被很多用户认为是一种理想化的双活解决方案。很多人认为这才是真正意义上的“双活”。人民银行发布“金融行业信息系统信息安全等级保护实施指引”中对于三级等保的系统提出了: 对于同城数据备份中心,应与生产中心直线距离至少达到30公里,可以接管所有核心业务的运行;对于异地数据备份中心,应与生产中心直线距离至少达到100公里; RTT:光被目的端 “镜子”反射回源端的延时。相对论定律:宇宙最高速度——真空光速恒定30万公里。 光纤折射率1.5,光纤光速 = 300,000 / 1.5 = 200,000公里/秒。30公里光纤RTT = 2X30 / 200,000 = 0.3ms,此延时受物理定律限制,不可缩短,和钱无关,和技术进步无关。我们通过oracle 数据库环境下的测试可以发现,oracle数据库中,链路每增加0.5ms的延迟,查询会增加4倍差距。拿oracle 远距离集群举例: oracle集群远程双活部署会引起“块争抢”的问题:一个块含很多记录,即便两节点(服务器)同时访问不同记录,也可能出现访问同一个块的“块争抢”,引起锁、等待、块属主变更、更新本地缓存等操作。节点和存储分布在远程时,网络延时1ms数量级,争抢解决慢,影响性能非常大。(若节点和存储都在本地,网络延时0.01ms数量级,争抢影响性能小) 通常通过“分割”解决“块争抢”,例如: 常用分割方法是按应用或表分割。 每个站点只访问自己的数据,减少块争抢。但是这并不能完全避免争抢问题 通常为提高可用性oracle厂商推荐“读写分离双活”的方案,把所有数据在每个站点本地存放一份,更新本地数据,并在另一站点复制出副本。这样,一站点故障,另一站点都能迅速负担全部负载。副本数据可以用于且仅用于读取。例如ADG,OGG等方案,目的是各部分松耦合,简洁,可用性和性能易于管理。远程不同于本地,本地集群部署的成功案例比比皆是,但是远程并行集群通过集群信息连续同步复制,将遥远的东西紧耦合,复杂,可用性和性能难于管理,可靠性低于本地并行集群。光速有限,造成:同步复制 + 远程 = 慢动作,所以能否实现远程“读写一体双活”呢?
【A1】李松青 软件架构设计师 , 浪潮商用机器企业云创新中心
完全赞同您说的“ 光速有限,造成:同步复制 + 远程 = 慢动作 ”说法。人民银行这个三级等保的系统要求,同城数据备份中心至少30公里, 异地数据备份中心与主生产至少100公里,也许正式是考虑到这方面因素。让大家可以有这样的可行方案选择: 同城几十公里距离内,建真正双活数据中心。其中查询业务可以利用数据库双活方案中优先读本地存储的亲和性策略,从哪侧发起的SQL查询就从哪一侧存储上查询数据;但增/删/改因为是同步写双中心,必然后链路距离影响,但从今年已实施案例来看,30-70公里距离的居多,写延迟带来的交易延迟也一般也在可接受范围内;异地(>100公里)建议异步备份容灾中心,利用数据库日志异步复制的方式,或者底层存储同步方式,复制到远端。为降低对主生产中心的冲击,可以考虑从同城备中心异步复制到异地中心。
【A2】bbaimm88 系统架构师 , 银行
生产相距30公里了, 光纤挖地施工长度肯定远大于30公里吧,(沿路街道、桥梁),传统数据库真心做不好 双活。Extend RAC 更新频繁情况下 集群cache 太难受了; 长距离很难避免链路抖动,频繁抖动DBA只能被动挨打,难一体化读写。 分布式数据库二阶段提交完全可能。长距离 Extend RAC 我的构想是主中心 两个节点 通过负载均衡来写,主中心 加的是写锁 , 备中心节点 仅做做读取,备中心加的是读锁 。这种伪双活可以尝试。长距离是个难活的生意。
【A3】zzy3620 系统环境管理 , 北部湾银行
当数据库节店之间出现较多gc等待事件的时候,表现慢的不光是跨节点访问的那些表,数据库的整体表现都是受影响的。因此在extend rac架构下即使一边是纯写入操作,另一个中心纯粹的读操作,如果造成的gc很高的话,仍然是会有数据库性能下降的问题的。。之前有运营商的朋友用过类似架构,后面改成直接关闭另个一中心的数据库,减少跨中心gc,这个架构主要就用于做切换演练的时候用了。
【A4】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
您说的非常对,光速有限。完全的读写双活一体,是应用双活+数据库双活+数据存储双活,目前影响这种架构实现的比较大的困难就是数据库双活和数据存储双活。距离过远,即使线路稳定,也会有较大的延时,就会对数据库的双活造成影响,也会对读写一体双活造成影响。
【Q12】在不使用分布式数据库的前提下,那些措施可以扩展数据库的读写性能?
目前银行新建分布式核心系统是大势所趋,但是在最关键的数据库环节对分布式架构的数据库依然持观望状态,仍然以db2/oracle等企业级数据库为首选。请问,在使用传统数据库,且实现应用架构分布式的前提下,哪些措施有可以用来扩展数据库的读写性能?
【A1】zzy3620 系统环境管理 , 北部湾银行
在比较良好的心跳交换网络架构下(例如infiniband),可以较好的降低Oracle rac节点的gc等待,这种情况下横向扩展rac节点可以扩充数据库吞吐能力。其次,提高数据库本身的硬件配置,例如后端存储从机械盘迁移到闪存盘,提高数据库服务器的计算能力可以提升性能。第三,对于应用,做好拆分,尽量让应用对于数据库中一个表的读和写操作都落在一个节点上,减少数据库跨节点访问数据,提高数据库响应速度。第四,adg或者利用第三方工具配置读写库和读库,实现读写分离,横向扩展读能力。
【A2】bbaimm88 系统架构师 , 银行
1、是应用改造,支持读写分离,数据库采用多从节点部署,比如mysql一主多从,或者组复制,oracle 有farsync;2、采用负载均衡来分流读负载,主库只用于写服务;3、优化写库的性能,配置最好的IO设备,内存尽量最大化利用;4、可以采用 PCIE闪存卡,并行,IO杠杆的。(价廉物美,适用非核心)
【A3】light_hu86 系统工程师 , 某省金融
传统的数据库,如db2和oracle目前已经能满足数据库性能,对应相应的数据库调优,优化数据库查询语句,索引优化等都能满足读写性能,特别是如db2的多分区表也能加快读写。对于分布式数据库来说,本行已进行分布式核心改造,采用mysql分库分表的形式进行部署,一主一备两从的形式确保读写分离以及高可用性。
三、核心系统双活方案下的链路及负载引流方面
【Q13】同城双活链路抖动的时候会不会丢数据? 如何解决这个问题?
【A1】zzy3620 系统环境管理 , 北部湾银行
这个要看采用的是什么复制技术,比较成熟的例如存储间复制,或者adg的复制,链路的抖动都会带来复制的卡顿和延迟,但是不会造成数据的丢失,在链路恢复正常后,延迟同步的数据还是会继续同步到备库或者存储的目的端去的。链路抖动比较严重时,反应在数据库的主库或者存储主节点上,可能会出现无法写入的情况,从某种程度上来说,系统管理员在遇到链路的抖动的时候宁愿选择直接把复制链路断开,变成异步复制模式,来换取主库或者存储读写节点的平安。
【A2】 ZTC 售前技术支持 , 浪潮商用机器企业云创新中心
抖动通常是不可避免的,即便是运营商提供质量再好的裸光纤连接,还是或多或少会存在抖动。如果频率不是很高,不至于引起网络长时间超时的话,都属于在可控范围内。理论上每100KM距离,RTT往返延迟为1MS,但一次通讯,往往会存在多次RTT,所以带来的延迟是不可避免的。网络上最好还是基于TCP协议的数据同步,利用重传机制,保证数据的在一定时间窗口还是能够传输过去。
【A3】 杨宇 系统架构师 , 浪潮商用机器企业云创新中心
存储复制过程中链路的抖动不会丢数据,抖动结束后数据会追齐!
【Q14】双活环境DWDM配置经验,如何配置防止运营商线路抖动影响波分承载线路?
【A】zzy3620 系统环境管理 , 北部湾银行
关于DWDM配置没法阐述的很细致,大体方案有两个,如下图:
【Q15】双中心如何解决脑裂问题,有哪些常用的措施?
【A1】zzy3620 系统环境管理 , 北部湾银行
不管是数据库集群脑裂还是存储集群脑裂,所有的脑裂主要都是把握好仲裁方案,比较笨的办法就是在面临有风险的仲裁决策时,强制指定其中一边为主,并且完全关闭另外一边,强制所有的应用都连接到被强制设置为主服务的节点。另外一边关闭后断开网络修复,等确保完全修复后才开启网络。
【A2】fengjian 系统工程师 , 浪潮商用机器企业云创新中心
为了避免双活数据中心产生脑裂(Split Brain)或场地分割(site isolation) 状况,需要提供有效的仲裁方式来保证数据完整性,通常是建立第三个中心作为仲裁。 有部分双活方案中可以设置当脑裂或站点故障发生时的自动响应或人为干预策略,比如PowerHA SystemMirror 企业版提供 HyperSwap 功能。PowerHA HyperSwap 基于 POWER 平台及 DS8K Metro Mirror 同步复制技术,提供数据中心之间 ( 或数据中心内 ) 存储高可用及应用高可用的一种容灾方案 , 也是 POWER Active-Active 解决方案的重要组成部分。
【Q16】同城双活网络架构设计?目前我们比较关心的其实是同城双活的网络架构设计,现在目前市面上比较成熟的方案都是打通大二层,而我们的情况是传统的思科7-5-2架构,设备都使用5年以上,如何替换现有架构,或者平滑过渡,是我们最关心的事情。有没有比较好的建议。
【A】zzy3620 系统环境管理 , 北部湾银行
同城双活打通大二层是一个比较常用的解决方案也是一个比较成熟的方案,但是对双中心的网络的稳定性依赖比较高,目前建议双中心的松耦合的方案越来越多,通过全局负载均衡以及dns来实现双中心的系统访问。但是网络是个基础设施,要做基础网络架构调整最好还是借助核心系统重建、数据中心搬迁或者新建等大型项目改造的机会,不建议在单独调整网络基础架构,可能工作量会非常大并且风险较大。
【Q17】如何实现核心系统网络层面的双中心引流架构?故障场合下如何将核心外围渠道或应用系统访问核心切换或引流到同城数据中心?
【A1】light_hu86 系统工程师 , 某省金融
目前核心一般都为主备方式,前台的应用可以实现双活,通过流量分发的形式实现双机房流量的引流,当某一机房发生问题时可将相应的流量引流至另一机房,实现业务的无感。
【A2】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
我理解这个问题有两种可能:第一,对于任意一个应用系统而言,都仍然是部署在一个中心,另一个中心是数据或应用级的备份。这样的话,是通过故障时DNS的重新指向引流到备中心的,或手工或通过策略。第二,如果应用层已经是双中心部署,同时对外提供服务。则是利用GTM根据负载和设置的策略进行双中心的导流。
【A3】zzy3620 系统环境管理 , 北部湾银行
可以通过跨中心的负载均衡GTM实现,策略配置成双中心的应用同时双活或者配置成本中心的应用全部故障时将业务转发到同城的应用服务器上。
【Q18】在双活建设中,DNS和负载均衡设备应如何协调配合?在同城双活建设中,一般会配备DNS和负载均衡,这两种设备应该如何配合工作?或者说各自负责什么样的工作才能发挥其最大作用?
【A1】匿名用户
DNS的强项是做静态解析,负载均衡的强项在于动态解析,基于后端服务能力探测的分发、基于源IP的分发、基于报文内容的分发,类似这些带一定条件的转发,都建议在负载均衡上实现。DNS对于静态地址解析的并发响应能力远远高于负载均衡,对于客户端、应用、数据库服务器上的大并发的域名解析,都还是有dns来完成。
【A2】bbaimm88 系统架构师 , 银行
DNS与负载均衡 能自动联动是一种很完美的方式。减少DNS手工维护。每当vs变更时候,DNS很快自我学习过去。DNS主要作用是应用 解析IP,起一个导航指路的角色,并能够轻易解决夸区域,夸站点的切换难题。负载均衡主要负责流量控制,应用健康反馈,多节点间流量分配。
四、核心系统双活方案下的服务器选型及Power平台优势方面
【Q19】如何考量核心系统服务器层面的跨数据中心部署架构和服务器选型?
【A1】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
目前我们看到城商行级别最核心的一类和二类服务器,选择成熟稳定UNIX小型机的用户还是占大多数。原因在于小型机架构部署核心应用,安全稳定且成功案例丰富。考虑到跨数据中心的容灾和双活,小型机配合存储及数据库层的解决方案也众多,可以比较全面地满足用户从本地高可用、到数据同步、再到应用双活的需要。从性能和稳定性上来说,小型机也都优于X86或主机的Linux平台。
【A2】fengjian 系统工程师 , 浪潮商用机器企业云创新中心
核心系统特别是核心数据库对业务连续要求高,建议考虑两地三中心方案,有条件的话采用同城双活,但是注意同城中心间的网络延迟和稳定性,延迟高会影响性能,另外要防范脑裂,建议有第三中心作为仲裁。不具备条件或不需要双活的,可以做站点间的互备,提高资源利用率。服务器选型上来说,核心系统对性能、高可靠性都有比较高的要求,这方面K1 Power比X86还是有明显优势的,另外Power上的高可用、容灾方案比较多,案例也多,更成熟可靠
【A3】 ZTC 售前技术支持 , 浪潮商用机器企业云创新中心
Power 架构经过几十年的不断完善,目前已经形成了以 PowerHA SystemMirror 和 VM Recovery Manager 为基础,兼顾关键业务和非关键业务的高可用 / 灾备解决方案。PowerHA SystemMirror , Power 平台上稳定、可靠的 HADR 方案,可满足多种高可用、容灾需求(主备 / 同城异地容灾 / 双活)。适用于关键工作负载。Power 平台上支持 PowerHA HyperSwap 、 DB2 purescale GDPC 、 Oracle Extend RAC 、基于存储的双活、 IBM Db2 Mirror for i 等多种成熟的双活方案。 都有实际落地的案例可以供其他银行参考。
【A4】zzy3620 系统环境管理 , 北部湾银行
主要是考虑清楚平台的选择,是unix还是linux,如果是linux,可选择面很广例如普通X86和数据库一体机都可以,如果追求稳定性,建议就在中端小型机里面选择,故障率相对还是低一些。银行业的核心数据库服务器,还是建议选择比较稳定的平台,少折腾。
【A5】 bbaimm88 系统架构师 , 银行
你这个要的结合你的核心应用来定。核心是单体的,还是集群的,或者分布式。单体集中式架构,就选Unix 平台吧,稳定性好,非集中式的架构,你的数据库建议选高端服务器, 应用可选性比较强了,在X86平台,可以物理机堆叠部署, 也可以虚拟化部署, 应用调度上建议上负载均衡,能够很轻松实现切换调度
【Q20】Power平台在建设核心业务系统同城双活方案中有何独特优势?Power平台的方案,相较于非Power平台的方案,在应用层、数据库层、虚拟化资源池层或者与存储的相互结合方面,有何独特的优势所在。
【A1】ZTC 售前技术支持 , 浪潮商用机器企业云创新中心
PowerHA SystemMirror 企业版提供 HyperSwap 功能实现数据中心双活功能。 PowerHA HyperSwap 是基于 POWER 平台及 DS8K Metro Mirror 同步复制技术,当主存储系统不可访问时 ,AIX 透明地将磁盘 I/O 切换到备存储 , 并且不影响正在运行的应用,从而提供数据中心之间 ( 或数据中心内 ) 存储高可用及应用高可用的一种容灾方案 , 也是 POWER Active-Active 解决方案的重要组成部分。PowerHA HyperSwap 能与 OracleRAC 完美结合,实现数据库无中断的快速切换,与传统解决方案相比,其切换更加自动化、 RTO 更短, RPO 为 0。
PowerHA HyperSwap 双活解决方案具有明显的优势:
监控从应用到存储各个层面,并提供每个层面故障处理方案; 结合 DS8K Metro Mirror, 保证高性能及数据传输稳定可靠; 支持部署 Oracle Extend RAC ,实现真正意义的双活中心; 充分利用双中心的服务器、存储资源; RTO 为秒级, RPO=0; 一键完成高端存储容灾演练,应用不受影响;可设置当脑裂或站点故障发生时自动响应或人为干预策略。
【A2】zzy3620 系统环境管理 , 北部湾银行
应该说power平台目前最为适合还是在数据库层使用,关键优势是其稳定性,小型机内关键组件的在线维护能力,相比x86服务器还是高出不少,故障率相对较低,并且多数故障可以在线维护,降低停服风险。应用层面现在使用x86进行虚拟化后部署集群已经是非常成熟的方案了。
【A3】 light_hu86 系统工程师 , 某省金融
一般power平台主要用在数据库上,优势主要体现在:1、节省设备上,之前power主备两台实现数据库,现在换成x86需一主一备两从的方式,还要分库分表,一下子设备就上去了,带来的管理和维护的难度加大;2、设备稳定上,相比x86来说,power设备较稳定,出现故障几率也较小。
【A4】 杨宇 系统架构师 , 浪潮商用机器企业云创新中心
可以参照下图,Power平台无论在单数据中心内的高可用,还是双中心容灾,以及双中心双活架构下,都有众多的解决方案。在虚拟化和云的方案中,VM Recovery Manager方案可定制事件触发的自动化脚本,实现自动处理。Live Partition Mobility 和 Remote Restart的结合,可以全面实现计划内和计划外的停机保护,实现RTO为0,RPO秒级。

【Q21】Power HA切换过程中与数据库如何配合?
【A1】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
将数据库的启停命令分别写到启动脚本和停止脚本中,在PowerHA中调用启停脚本来执行数据库的启停。
【A2】ZTC 售前技术支持 , 浪潮商用机器企业云创新中心
一般是配置PowerHA的启停脚本,另外PowerHA也支持通过monitor脚本对数据库和应用的状态进行监控,当发现异常时也可以进行切换。
【A3】 zzy3620 系统环境管理 , 北部湾银行
个人认为只要应用支持短连接或者自动重连,数据库的RAC方案在连续性方面相对优于HA,HA切换必然有数据库的关闭和启动过程,特别是对于体量比较大的数据库,重启一次可能时间会更长
【A4】邓毓 系统工程师 , 江西农信
PowerHA切换过程中在释放资源组前后,可以通过设置停止脚本和启动脚本,脚本里分别编写停止和启动数据库的命令,并在POWERHA的应用资源中设置好启停脚本的路径等内容,这样在POWERHA切换时,就会按照运行停止脚本,释放资源组,切换资源组,接管资源组,运行启动脚本的步骤,和数据库完美衔接。
【A5】light_hu86 系统工程师 , 某省金融
对于PowerHA结合db2数据库来说,将启停应用的步骤进行脚本化,并将脚本路径配置在HA之中,一旦发生切换会结合脚本进行相应的应用启停。
【Q22】请专家详细介绍一下Power平台下的GDR方案的原理、架构和适用场景等
【A1】ZTC 售前技术支持 , 浪潮商用机器企业云创新中心
VM Recovery Manager (简称 VMR )是一种基于分区重启技术的灾备及高可用方案,过去曾用名 GDR ( Geographically Dispersed Resiliency for Power System )。VMR 方案提供了一种在灾备站点或者本地站点实现虚拟分区自动重启的能力,并且负责管理相关的硬件复制过程。 VMR 灾备及高可用解决方案易于部署和管理。 VMR 可以管理本地站点或者跨站点的多个虚拟机的恢复。其通过与 HMC 和 VIOS 紧密集成来重新启动 VM 。 VMR 提供了广泛的自动化,这样管理员就可以快速部署 / 配置,并进行故障转移。VMR 方案包含两个版本,主要关注跨站点灾备场景的 VM Recovery Manager for DR( 简称 VMR DR) ,以及主要关注本地站点高可用的 VM Recovery Manager for HA (简称 VMR HA )。如下图所示, VMR DR 技术的基础架构涉及到几个重要的组成部分,分别是:主机,虚拟机, VIOS,HMC, 存储和 K-sys 分区。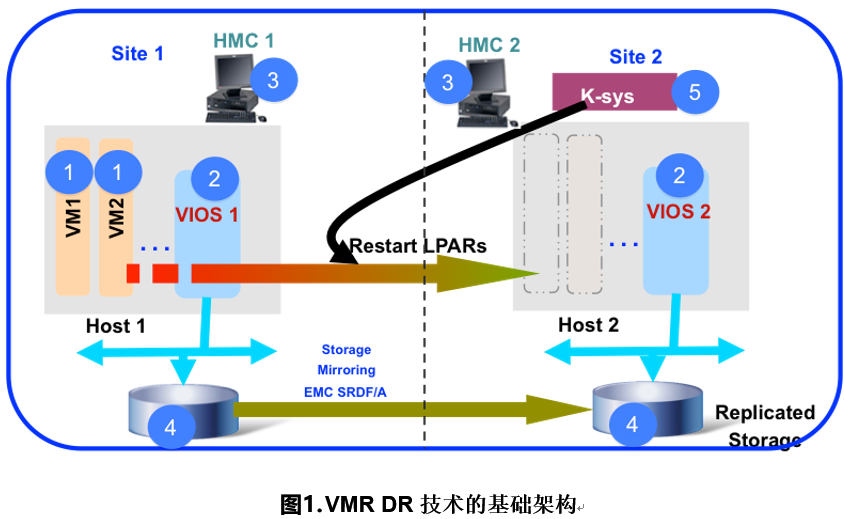
主机是指分布在异地站点上的 Power 服务器物理硬件,作为虚拟机的宿主硬件。虚拟机是指在 Power 服务器上跑的虚拟分区(该分区的所有 I/O 资源必须使用虚拟 I/O 资源),业务负载运行在这些虚拟机上。 VIOS 指的是每一台 Power 服务器部署的虚拟 I/O 服务器( Virtual I/O Server, 简称 VIOS ) , 所有的业务分区的 I/O 资源都由 VIOS 提供,包括:虚拟网络,虚拟光纤通道,虚拟 SCSI 总线等。 HMC 是 Power 服务器特有的硬件管理控制台( Hardware Manage Console ,简称 HMC ),每个站点至少配置 1 台用于管理站点内 Power 服务器。存储负责提供虚拟分区的操作系统盘和数据盘的远程镜像能力。 K-sys 分区是安装在备站点的一个 AIX 分区上的一组文件集( K-sys 本身包含 8 组文件集)。 K-sys 用来管理整个灾备环境。VMR HA 架构中的主要组件与技术与 VMR DR 相同。不同之处在于, VMR HA 架构中的多台主机部署在同一站点,它们共享同样的存储设备,因此不涉及存储间的数据复制。另外的一点不同是, VMR DR 需要管理员介入,主动发起请求,切换才会真正进行,而 VMR HA 包含了完善的虚机监控机制,可以实现虚机的自动迁移。下图为VMR HA的架构: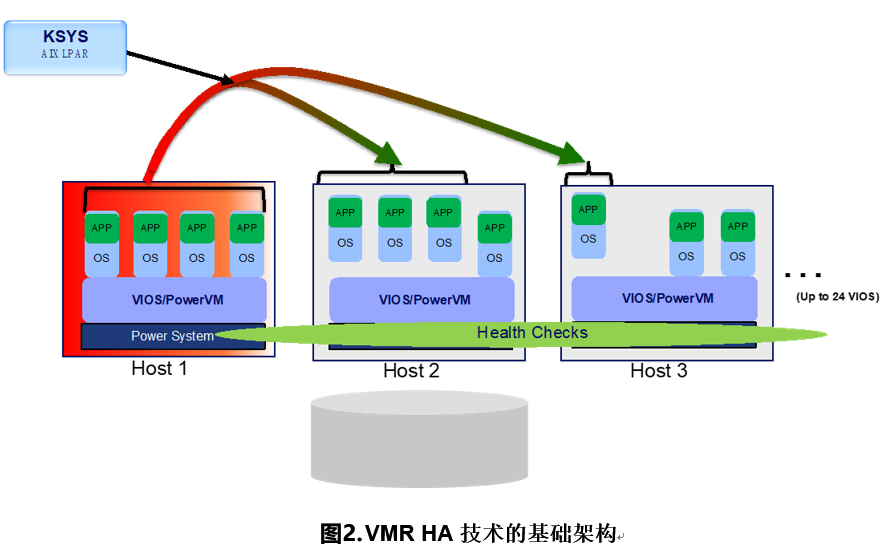
VMR 作为 Power 的新灾备及高可用解决方案,满足客户对于非关键业务的灾备及高可用需求。VMR DR 在计划内容灾演练、计划外容灾切换过程中自动化完成系统级的工作,减少运维人员的工作量,让运维人员把精力放在应用的启动、测试中。VMR DR 可维护性好,平时对生产环境的性能没有影响;也支持在不影响生产环境的情况下,在灾备环境进行演练工作。当部署完之后,不需要更新微码,除非要实现新版本中的功能,新版本又需要有更新微码的支持。 VMR DR 的高级特性包括:非中断容灾演练;灵活的灾备容量管理;基于权重的重启排序;基于主机组的灾备策略; VLan/vSwitch 的站点间匹配;日常自动验证。VMR 的应用场景主要有两大类:跨站点主备模式和同站点主备模式:
跨站点主备模式:主备站点服务器 1 对 1 采用 VMR DR 方案常见于客户新建机房后采购新的 Power 服务器替换原有的 Power 服务器。原有的 Power 服务器作为灾备站点的宿主硬件和新的主站点的 Power 服务器一一配对组成灾备关系。同站点主备模式:为提高同站点系统的高可用性,可将多台 Power 服务器组成资源池,采用 VMR HA 方案统一监控管理各虚机状态,一旦发生服务器整机故障或者单个分区故障的情形, VMR 可以将分区在另外选定的服务器上重启,从而保证业务的可用性。
【A2】zzy3620 系统环境管理 , 北部湾银行
GDR技术是指Power系统的地域分散弹性技术,GDR的跨站点重启,首先需要有一套存储复制,将本地的启动盘数据盘复制到远端,确保操作系统和数据完整的复制到远端的存储。之后使用类似PowerVM里面的Remote Restart技术在远端启动操作系统,但是Remote Restart启动时,两边使用的是同一块光纤引导盘,GDR是允许使用灾备站点使用另一块MM或者GM复制的盘将操作系统拉起。
五、核心系统双活方案下的容灾切换方面
【Q23】两地三中心的自动化切换等易用性方面的实现?相关方案实践除满足了较高的RTO及RPO标准外,还应考虑解决方案再操作方面的易用性,可有效降低客户侧的维护成本及人员级别要求。这方面是否有较好实践,以实现自动化或半自动化的切换。
【A1】zzy3620 系统环境管理 , 北部湾银行
双中心复制技术的选型直接决定了切换的复杂度。采用存储的复制,进行双中心切换的复杂度较高,需要完成在主端停止应用数据库,取消激活vg,并激活备中心的存储磁盘为读写,激活vg以及拉起数据库应用等一系列的操作,切换复杂度极高。如果采用应用双活,数据库adg的方式,双中心的切换操作就只需完成数据库的switchover切换一个步骤,然后等待应用自动连接到备中心的standby库即可。如果是采用应用双活和数据库的extendrac方案,则双中心无需特别的切换操作,只需要将主中心的数据库节点关闭即可。其次,在确定了双中心的灾备方案,固化了切换流程的基础上,也可以通过自动化运维平台,vmware的SRM等进行切换流程编排,提高自动化程度。
【A2】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
理解您的需求是从易用性和可管理性的角度来看切换的解决方案。VM Recovery Manager是个挺好的选择,相对与传统的监控和管理方式,它增加了VM失效检测、跨站点的定制化脚本切换、应用监控和设置多种迁移策略的功能,而且是简洁的图形管理界面。
【Q24】核心业务双活切换需要考虑哪些因素?城商行核心业务切换需要考虑哪些因素?
【A1】zzy3620 系统环境管理 , 北部湾银行
个人理解双中心切换前可能需要注意的点包含如下: 切换的系统范围、网络分发策略、域名解析、安全策略、切换相关系统在切换到后另一个中心后的硬件资源情况、系统并发能力、切换后一些特定的定时任务、备份任务。
【A2】杨宇 系统架构师 , 浪潮商用机器企业云创新中心
您谈到了双活 同时 还有业务切换,那么我理解还是主备的模式,不然完全的双活系统就不存在切换的问题。核心业务切换,前提一定是业务的分级和分组之后的切换,不然只是某个业务切换了,其他的相关业务还留在原中心,这样的切换也没什么意义。至少要保证一组相关的业务一起切换。如果是两中心距离不远,SAN可以直接打通,两边各自可以看到对端的存储。风险把控涉及的方面比较多,如提前准备好必要的切换策略、切换流程、以及切换后验证文档。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞9本文隶属于专栏

作者其他文章
评论 17 · 赞 79
评论 8 · 赞 42
评论 0 · 赞 2
评论 0 · 赞 1
评论 1 · 赞 1
添加新评论2 条评论
2021-03-22 14:08
2020-08-12 12:44
hfboss: @lnasman 牛叉