查看其它 1 个回答晓风的回答
高可用架构的设计原则
- 冗余: 单点永远是高可用的最大敌人。任何组件都有可能奔溃,哪怕只是一个简单的执行
ping命令的容器。单点组件一旦奔溃,如果没有后备组件的话,那么这一组件就算是彻底不可用了。为了保证组件的故障不会导致整个系统的故障,我们应当为每一个组件都留有一个到 N 个冗余后备。 - 故障转移: 节点出了故障后,要是请求还在往故障节点上发,那么有再多的冗余节点也是毫无意义的。所以需要自动的检查故障的产生,并将流量转发到冗余中的可用节点上。而想要及时的实现故障转移,我们还需要有健康检查机制去检查服务的状态。
- 异常处理: 如果高可用架构设计完美,那么即使发生故障,用户也很可能永远感知不到。但这并不代表就不需要检查并解决故障了,定期的维护应用可以进一步提高系统的可用性。
- 监控告警: 通过对应用、服务器、系统等多个方向采集资源指标和异常日志等信息,并按时间段和阈值等告警策略来及时通知维护人员对应用进行维护或者自动进行扩展。可以有效减少甚至避免故障带来的损失。
- 可扩展性: 当现有的资源不足以处理现有的任务时,应用的响应就会逐渐变慢直至失去响应。能够对应用通过横向扩展或者纵向扩展为容量进行动态的调整也是维护应用性能和可用性的重要属性。
其他未能提到的机制
对于高可用架构还应当考虑服务分级与降级,灾难恢复与异地多中心等等机制或场景。随着服务规模的不断扩张,保持或提高可用性的成本会以一种夸张的方式上涨。
安装一个高可用的 Kubernetes 集群是保障容器云平台高可用的第一步
Kubernetes高可用架构:
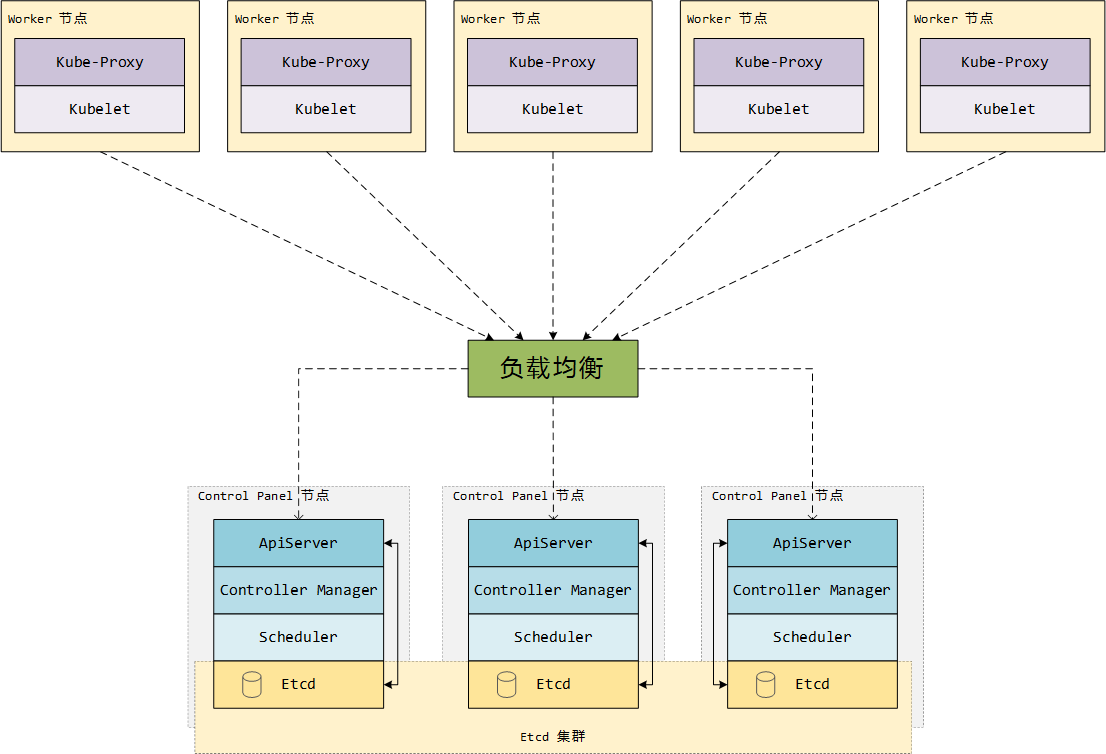
如图所示,我们将一个高可用的 Kubernetes 集群分为了由三种节点组成的集群。这三种节点分别是Control Panel节点、Worker节点、Etcd节点。
虽然我们已经有了一个高可用的 Kubernetes 集群,但是这并不代表我们部署在上面的工作负载也会自动变得高可用。为了能够让我们部署在上面的应用(包括容器云平台这个应用)能够实现高可用,需要了解阻碍我们实现高可用的故障主要都存在于何处,以及如何为 Kubernetes 中的工作负载实现高可用。
通过 Kubernetes 集群创建在集群中高可用的应用。
容器云平台本质上可以视为一个无状态的组件,平台中的数据存储在 Kubernetes 的 Etcd 中。
我们将容器云平台的 Pod 通过 Deployment 的方式部署在 Kubernetes 集群中,并将其 Replicas 设置为一个不小于 1 的数。在通过一个选择器,将这几个 Pod 暴露在同一个 Service 中。这样一来,当我们的任意一个 Pod 如果不再健康了,Controller Manager 就会删除这个 Pod,并部署一个新的 Pod。
对于外界而言,由于这些 Pod 是通过 Ingress 访问 Service 的形式暴露出来的,当有 Pod 没有通过就绪状态检查指针(Readiness Probes)检查的时候,流量便会走向其他通过检查的 Pod 中。整个过程中,用户并不会察觉到应用的不可用,对于他们来说,只需要访问同一个域名,请求就总是会发送到可用的 Pod 中。其容错能力为N - 1(N 为 Pod 数量)。
镜像仓高可用(有状态组件高可用)
镜像仓的高可用方案与容器云平台不同在于,镜像仓中存在多个有状态组件,而且还需要一个网络存储。
很多数据库为了实现高可用与数据一致性,都会给出相关同步方案和主从机制。
不论是有状态的无状态的,还是平台或者应用的高可用架构,本质上其实都是通过增加冗余与故障转移来实现的。而实际上,不同的应用对于可用性的要求不同,甚至会为了性能牺牲可用性,希望能够从业务场景出发,深刻理解需求后,再为应用设计架构。