王豪迈的GTC 2024 火线评论:GPU 的高效存储利用
编者按:英伟达2024 GTC 大会近日正在美国加州召开中,星辰天合 CTO 王豪迈在大会现场参与了 GPU 与存储相关的最新技术讨论,发回了本篇评论文章。
随着 GPU 单卡算力的不断提升,以及 GPU 集群规模的扩大,伴随着 Scaling Law (规模法则) 的信仰, 对于 AI 基础设施带来两个不言而喻的趋势:规模化的数据集和集群扩展 。 最近的热点主要围绕 LLM (大型语言模型)为主,但实际上 AI 在不同行业的应用场景丰富,带来了多样化的数据访问需求。
大数据集的挑战
同样对于非 LLM 的场景来说,在不断扩展的数据集下,GPU 不仅是计算“怪兽”,也是一个针对细粒度数据的高强度存储访问引擎。我们过去在互联网经常谈到 100K 问题,意味着要提供面向 10 万用户(客户端)的并发访问能力,但对于 GPU 计算场景来说,特别是每年都实现算力指数级增长的情况下,单一 GPU 集群提供 10 万的并发能力会成为常态,不管是计算和存储都会面对。
可以通过 Nvidia 对于 GPU 应用的分类来了解相应的数据集情况: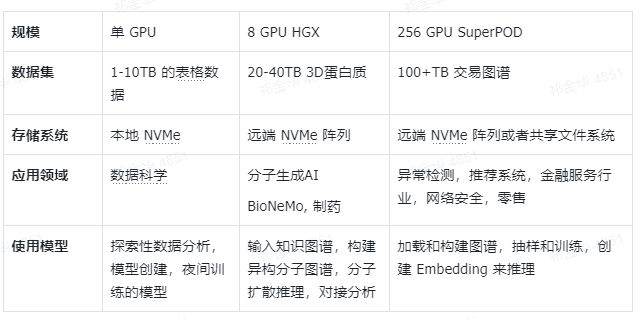
在单机 CPU/GPU 内存足以容纳的数据,在规模化数据集面前已经无法被内存容纳后,意味着每个大规模数据集的集群都需要面对大数据集的分区、缓存和节点通讯协同问题,更不用提其中的错误处理,意味着要像传统大数据系统一样构建(但完全不同的性能需求)。
GPU 的存储访问
在数据访问上,在几年前就拥有了 GPUDirect Storage,意味着 GPU 可以直接通过 NVMe over Fabric 协议访问存储,而不需要通过 CPU 参与并带来额外的内存拷贝。在去年开始,GPUDirect Async Kernel Initiated Storage (GPUDirect 异步内核启动的存储)技术更进一步减少了 CPU 和 GPU 的同步开销,使得 GPU 可以直接向内核发起请求,而不需要 CPU 代理发起。因此, GPU 对存储的单次访问来说,已经非常高效 。
在 Nvidia CUDA 生态中,已有 NVSHMEM(如下图所示)实现了 GPU 之间的内存数据通信,屏蔽了 NVLink/PCI/Infiniband/RoCE/Slingshot/EFA 的具体传输实现,极大帮助了 GPU 集群协同计算的效率,而在存储方面仍旧没有对应的 API 和实现,使得 GPU 总要面对十分具体的存储传输和协同。 这意味着需要提供一套新的 API 来处理大数据集的访问问题。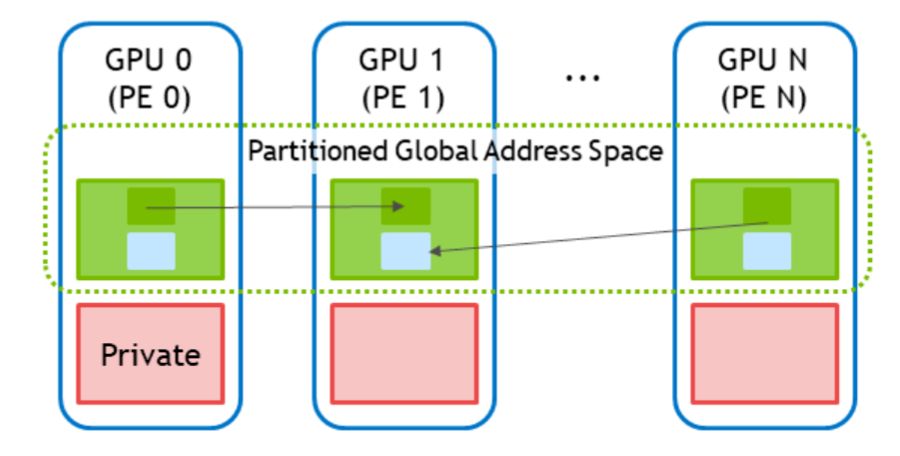
每个 GPU 线程都是存储访问的单元,意味着随着 GPU 并发度的不断提高,在一些场景,例如目前 GPU 已经直接支持的基于图的数据节点遍历,通过 PCIe 的存储 IO 处理需要高效的手段才能应对。
GNN 训练的限制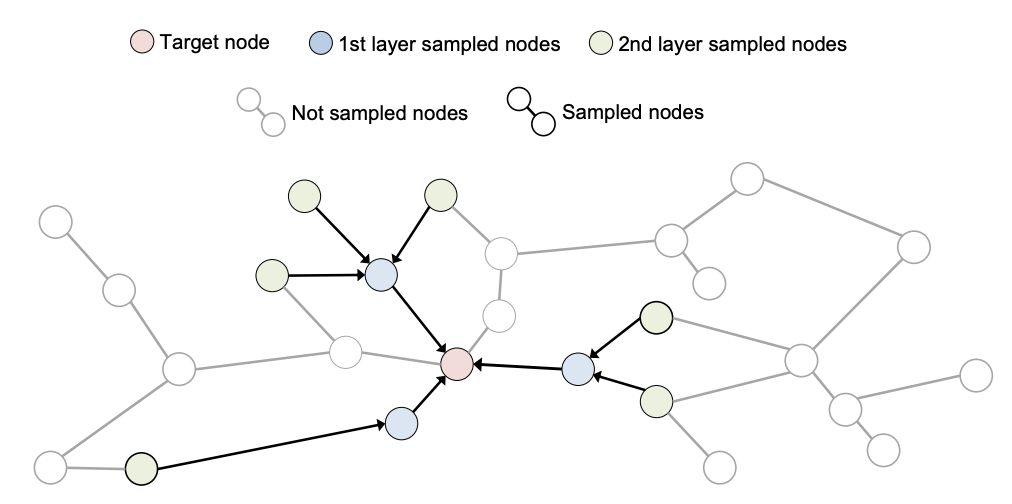
例如现有的 GNN 框架在遇到无法完全放入内存的数据集时,会直接通过内存映射特征向量文件到 CPU 虚拟地址空间,提供一种无限虚拟内存的概念,使得 CPU 上的节点特征聚合计算可以在所请求的特征向量不在 CPU 内存中时触发 page fault。如下图所示,在节点特征聚合阶段,CPU 访问映射在其虚拟内存空间的节点特征,当这些特征不在 Page Cache 中时,OS 会从存储中将包含被访问特征的页面带入 CPU 内存。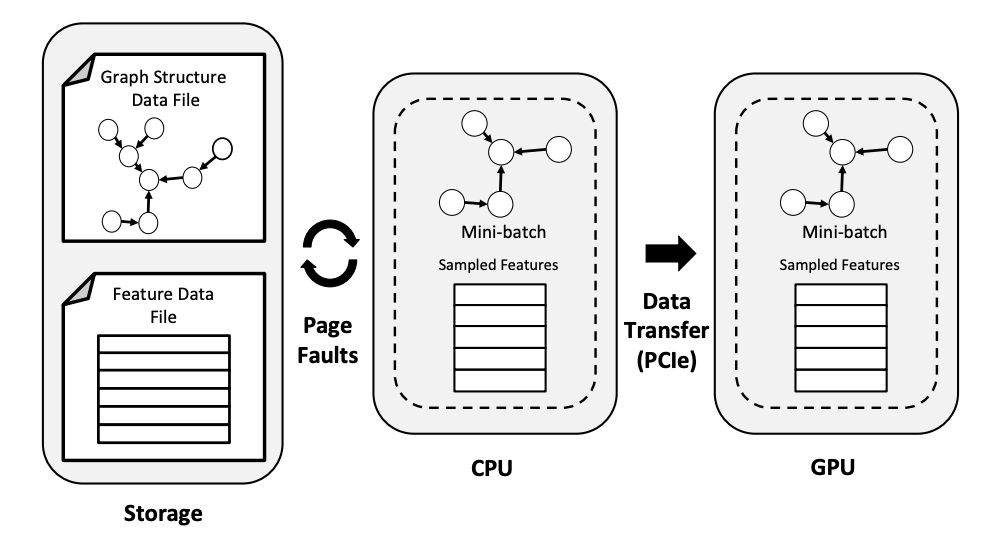
不幸的是,MMAP 方法使得特征聚合成为整个训练流程中最糟糕的瓶颈。针对 GNN 训练执行的每个阶段的性能分析显示,迭代时间明显受到节点聚合阶段的限制,正如下图所示。例如在评估中使用的最大的两个图—— IGB-Full 和 IGBH-Full,其训练阶段几乎看不见。这是因为对于大规模图,OOM 的额外成本加剧了数据准备吞吐量和模型训练吞吐量之间的差距。因此, 改善 GNN 训练性能的关键是大幅加速特征聚合阶段(即数据准备阶段) 。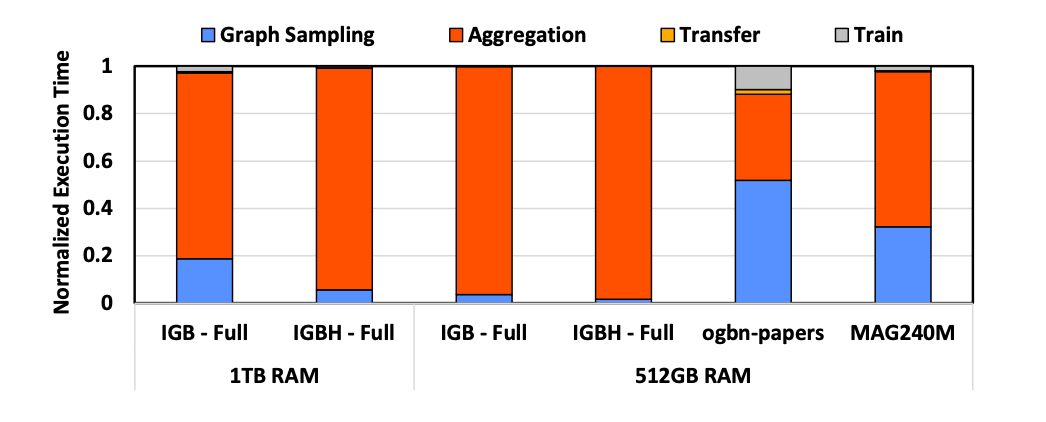
随着新兴的应用领域拓展,更多的应用场景都在面对类似的问题:
- GNNs 中的 图和特征的存储
向量搜索/向量数据库中的存储
- NeMo Retriever,NVIDIA RAFT in RAG-LLM
- 在万亿级 token 的 LLM 预训练上进行数据去重
- LLM 微调与 GNN Embedding 的联合也需要大量的 KV 存储
- cuGraph 中图分析 API
这些应用都形成了共同的需求: - 管理/避免 OOM 带来的开销
- 需要缓存、数据分区、多节点通信能力的支持
- 每个应用都需要针对性创建,缺乏共同的基础设施

SCADA 项目的提出
基于此, Nvidia 在 2022 年开始,基于大内存和存储系统的联动,提出了 SCADA(Scaled accelerated data access ) 系统,面向 GPU 应用的大规模数据集访问需求而设计 。
SCADA 的设计面向以下四个原则: - 大规模的访问 :意味着这个 API 需要应对在单个节点上处理 10TB级别的数据集。同时也不用担心 OOM 问题。无论数据的大小或计算的复杂性如何,API 都能够处理
- 高度抽象 :在这个 API 集的前端部分,需要有一个处理特定数据集的接口。这个接口可以有效处理数据局部性、分片和阶段性处理后的复杂性。在后端部分,我们为应用程序提供直接访问数据集的能力,而无需了解数据的局部性和分片问题。这个 API 还可以高效利用 GPU 线程、内存管理和拓扑优化通信来处理数据
- 易于启用 :不需要改变现有应用程序
- 总拥有成本(TCO) :大量的数据意味着大量的内存,对应大量成本,如果能够降低存储和处理大规模数据集的内存就意味着降低了成本
针对这些方面,SCADA 主要实现了创新的数据加载和管理机制,这里有几个关键因素: - 直接存储访问 :通过通过允许 GPU 直接从 NVMe SSDs 读取数据,GPUDirect Async Kernel Initiated Storage 减少了传统的数据加载流程中 CPU 的介入。这种直接访问机制避免了数据在 CPU 和 GPU 之间的不必要拷贝,从而节省了大量的内存空间,并减少了访问延迟
- 软件定义的缓存和窗口缓冲 :利用 GPU 内存作为一个软件定义的缓存,配合窗口缓冲机制,有效地管理即将被处理的数据。这种策略使得系统能够在有限的 GPU 内存中存储最频繁访问的数据,同时直接从 SSD 加载其他数据,从而扩展了数据处理的能力,超出了物理内存的限制
- 高效的数据预取和管理 :通过智能的数据预取和管理策略,能够确保 GPU 在需要数据时能够迅速获取,从而最小化了 I/O 开销和等待时间。这种策略进一步提高了数据加载的效率,使得可以在不受物理内存大小限制的情况下处理大规模数据集
- 减少 I/O 开销 :通过合并多个数据请求和优化数据访问模式,显著减少了对 SSD 的 I/O 请求,这不仅提高了数据访问速度,还降低了对存储设备的负载。这意味着系统可以更有效地利用存储资源,处理更大的数据集
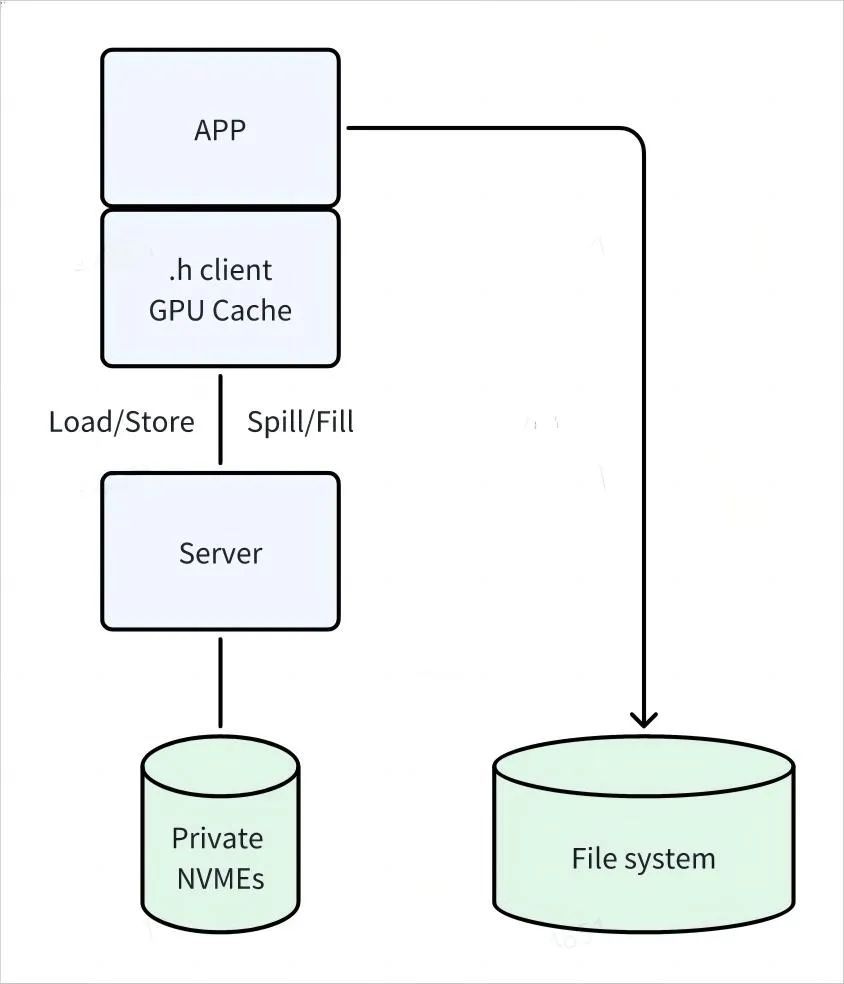
上图是整个 SCADA 的服务逻辑,首先 SCADA 会根据提供的头文件里的数据结构来初始化,目前支持 C++ 模版方式定义数据结构,同时由应用自己来管理内存,SCADA 提供分配和释放数据结构的 API。CPU 上的应用读取所有数据,再通过 GPU 线程写数据到私有的 NVMe。SCADA 会提供连续数组 API 来供应用读取这些数据。
下图展示了一个利用 SCADA 的系统整体架构示例,通过 cuGraph 适配了 SCADA 框架,无需修改应用。整个训练数据无论大小都可以得到执行,且无需管理内存、缓存、分区等问题。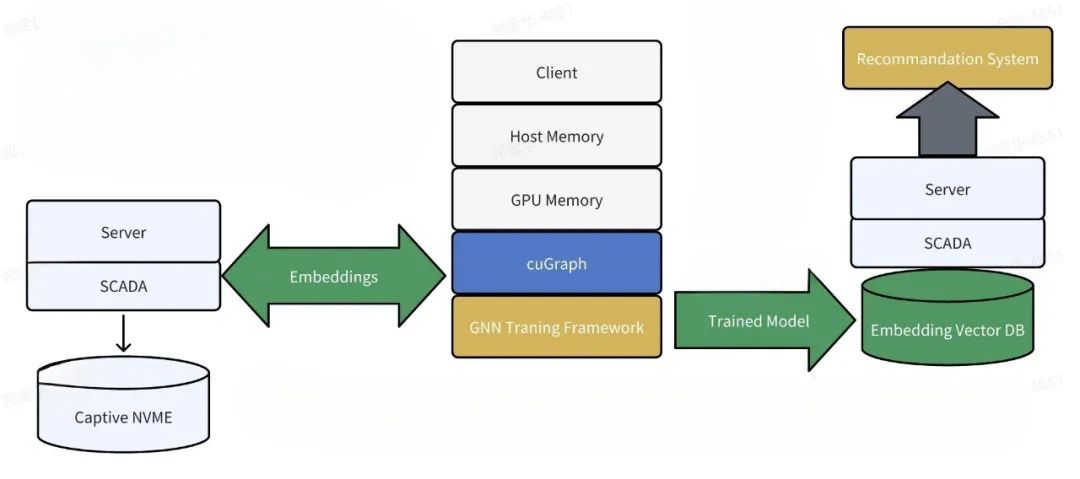
性能评估
在一个基准测试中,对比 MMAP 方法,启用 SCADA 后,整体性能提升达到了 26 倍以上。同时, 相比之前 CPU 驱动的 IO 并发度,SCADA 极大提升了针对存储设备的并发 10-100X,甚至达到了 10000 的 IO 并发度 。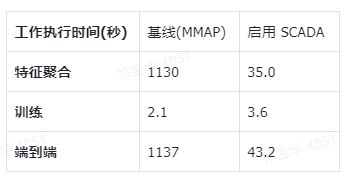
从 IO 角度来分析,下表展示了通过 SCADA 的缓存和 IO 汇聚成果,成功将瓶颈从存储 IO 能力转移到了 GPU 节点本身: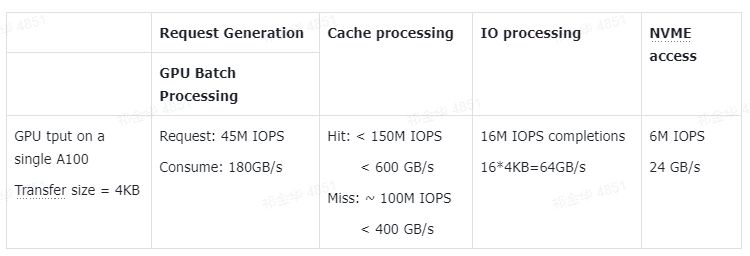
XSKY 观点
SCADA 目前仍然是 Nvidia CUDA 体系的实验性项目,正在跟应用开发者协作更多的数据结构,如 KV、VectorDB、dataframe。在存储方面,通过 SCADA 带来了更高并发 IO 后,可以提供更高效和细粒度的事务支持。另外,块和文件系统的统一使用也成为必需,灵活运用块的高性能 IO 和文件系统的共享能力使得 GPU 应用的大数据集问题大大缓解。另外,SCADA 实际上是过去 Big Memory 的 GPU 场景衍生,其差异是充分考虑了 GPU 的生态能力,使得跟 GPU 应用结合后会有更显著的性能提升。
这些对于 XSKY 的全共享架构(XSEA)都是极好的匹配,更好的支持 GPU 的高并发、大带宽的场景需求 。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 0 · 赞 1
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论