从实测出发,掌握 NebulaGraph Exchange 性能最大化的秘密

自从开发完 NebulaGraph Exchange,混迹在各个 NebulaGraph 微信群的我经常会看到一类提问是:NebulaGraph Exchange 的性能如何?哪些参数调整下可以有更好的性能?…索性来一篇文章从实测出发,和大家讲讲如何用好这个数据工具。在本文你将获得 NebulaGraph Exchange 的最佳使用姿势。
## 01. 环境准备
硬件:
- Spark 集群:三台机器,每台 96 core,256 G 内存
- NebulaGraph 集群:三台机器,每台 128 core,252 G 内存,SSD,双万兆网卡
- 数据:LDBC sf100 数据
软件:
- Spark 版本:2.4.4
- NebulaGraph 版本:3.3.0
## 02. NebulaGraph 优化配置
在进行大批量数据导入时,可以调整 NebulaGraph Storage 服务和 Graph 服务的配置,以达到最大导入性能。请根据 NebulaGraph 的配置描述和你的实际环境资源进行参数调整。
在本次实践中,NebulaGraph 的集群配置针对以下几个配置项进行了修改,其他均采用默认配置:
"storaged":
--rocksdb_block_cache=81920,
--heartbeat_interval_secs=10,
--reader_handlers=64,
--num_worker_threads=64,
--rocksdb_db_options={"max_subcompactions":"64","max_background_jobs":"64"}
"graphd":
--storage_client_timeout_ms=360000,
--session_idle_timeout_secs=2880,
--max_sessions_per_ip_per_user=500000,
--num_worker_threads=64
### NebulaGraph Storage 服务优化
在这里简单讲一下几个 Storage 服务优化配置项:
--rocksdb_block_cache数据在内存缓存大小,默认是 4 MB,大批量数据导入时可以设置到当前内存的 1/3;--num_worker_threadsstoraged 的 RPC 服务的工作线程数量,默认 32;--query_concurrently为true表示 storaged 会并发地读取数据,false表示 storaged 是单线程取数;--rocksdb_db_options={"max_subcompactions":"48","max_background_jobs":"48"}:可用来加速自动 Compaction 过程;--rocksdb_column_family_options={"write_buffer_size":"67108864","max_write_buffer_number":"5"},在刚开始导入大量数据时可以将disable_auto_compaction选项设置为true,提升写入的性能;--wal_ttl=600在大量数据导入时,若磁盘不充裕,那么该参数需调小,不然可能会因为产生大量的 wal 导致磁盘空间被撑满。
### NebulaGraph Graph 服务优化
再简单地罗列下 Graph 服务相关的一些优化配置项:
--storage_client_timeout_ms为 graphd 与 storaged 通信的超时时间;--max_sessions_per_ip_per_user是单用户单 IP 客户端允许创建的最大 session 数;--system_memory_high_watermark_ratio设置内存使用量超过多少时停止计算,表示资源的占用率,一般设置为 0.8~1.0 之间;--num_worker_threads为 graphd 的 RPC 服务的工作线程数量,默认 32。
## 03. NebulaGraph DDL
下面,我们通过这些语句来创建下 Schema 方便后续导入数据:
CREATE SPACE sf100(vid_type=int64,partition_num=100,replica_factor=3);
USE sf100;
CREATE TAG IF NOT EXISTS `Place`(`name` string,`url` string,`type` string);
CREATE TAG IF NOT EXISTS `Comment`(`creationDate` string,`locationIP` string,`browserUsed` string,`content` string,`length` int);
CREATE TAG IF NOT EXISTS `Organisation`(`type` string,`name` string,`url` string);
CREATE TAG IF NOT EXISTS `Person`(`firstName` string,`lastName` string,`gender` string,`birthday` string,`creationDate` string,`locationIP` string,`browserUsed` string);
CREATE TAG IF NOT EXISTS `Tagclass`(`name` string,`url` string);
CREATE TAG IF NOT EXISTS `Forum`(`title` string,`creationDate` string);
CREATE TAG IF NOT EXISTS `Post`(`imageFile` string,`creationDate` string,`locationIP` string,`browserUsed` string,`language` string,`content` string,`length` int);
CREATE TAG IF NOT EXISTS `Tag`(`name` string,`url` string);
CREATE EDGE IF NOT EXISTS `IS_PART_OF`();
CREATE EDGE IF NOT EXISTS `LIKES`(`creationDate` string);
CREATE EDGE IF NOT EXISTS `HAS_CREATOR`();
CREATE EDGE IF NOT EXISTS `HAS_INTEREST`();
CREATE EDGE IF NOT EXISTS `IS_SUBCLASS_OF`();
CREATE EDGE IF NOT EXISTS `IS_LOCATED_IN`();
CREATE EDGE IF NOT EXISTS `HAS_MODERATOR`();
CREATE EDGE IF NOT EXISTS `HAS_TAG`();
CREATE EDGE IF NOT EXISTS `WORK_AT`(`workFrom` int);
CREATE EDGE IF NOT EXISTS `REPLY_OF`();
CREATE EDGE IF NOT EXISTS `STUDY_AT`(`classYear` int);
CREATE EDGE IF NOT EXISTS `CONTAINER_OF`();
CREATE EDGE IF NOT EXISTS `HAS_MEMBER`(`joinDate` string);
CREATE EDGE IF NOT EXISTS `KNOWS`(`creationDate` string);
CREATE EDGE IF NOT EXISTS `HAS_TYPE`();
## 04. LDBC sf100 数据集的数据量
该表展示了各类点边的数据量
| Label | Amount |
|---|---|
| Comment | 220,096,052 |
| Forum | 4,080,604 |
| Organisation | 7,955 |
| Person | 448,626 |
| Place | 1,460 |
| Post | 57,987,023 |
| Tag | 16,080 |
| Tagclass | 71 |
| CONTAINER_OF | 57,987,023 |
| HAS_CREATOR | 278,083,075 |
| HAS_INTEREST | 10,471,962 |
| HAS_MEMBER | 179,874,360 |
| HAS_MODERATOR | 4,080,604 |
| HAS_TAG | 383,613,078 |
| HAS_TYPE | 16,080 |
| IS_LOCATED_IN | 278,539,656 |
| IS_PART_OF | 1,454 |
| IS_SUBCLASS_OF | 70 |
| KNOWS | 19,941,198 |
| LIKES | 341,473,012 |
| REPLY_OF | 2,200,960,52 |
| STUDY_AT | 359,212 |
| WORK_AT | 976,349 |
## 05. NebulaGraph Exchange 配置
重点来了,看好这个配置,如果下次还有小伙伴配置配错了导致数据导入报错的话,我可是要丢这篇文章的链接了。app.conf 如下:
{
# Spark 相关配置
spark: {
app: {
name: Nebula Exchange
}
}
# NebulaGraph 相关配置
nebula: {
address:{
graph:["192.168.xx.8:9669","192.168.xx.9:9669","192.168.xx.10:9669"] //因为实验环境是集群,这里配置了 3 台机器的 graphd 地址
meta:["192.168.xx.8:9559"] //无需配置多台机器的 meta 地址,随机配一个就行
}
user: root
pswd: nebula
space: sf100 // 之前 Schema 创建的图空间名
# NebulaGraph 客户端连接参数设置
connection {
timeout: 30000 //超过 30000ms 无响应会报错
}
error: {
max: 32
output: /tmp/errors
}
# 使用 Google 的 RateLimiter 限制发送到 NebulaGraph 的请求
rate: {
limit: 1024
timeout: 1000
}
}
# 这里开始处理点数据,进行之前的 Schema 和数据映射
tags: [
{
name: Person // tagName 为 Person
type: {
source: csv //指定数据源类型
sink: client //指定如何将点数据导入 NebulaGraph,client 或 sst
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/person.csv" // 数据文件的所在路径,如果文件存储在 HDFS 上,用双引号括起路径,以 hdfs:// 开头,例如 "hdfs://ip:port/xx/xx"。如果文件存储在本地,用双引号括起路径,以 file:// 开头,例如 "file:///tmp/xx.csv"。
fields: [_c1,_c2,_c3,_c4,_c5,_c6,_c7] // 无表头,_cn 表示表头
nebula.fields: [firstName,lastName,gender,birthday,creationDate,locationIP,browserUsed] // tag 的属性映射,_c1 对应 firstName
vertex: _c0 // 指定 vid 的列
batch: 2000 // 单次请求写入多少点数据
partition: 180 // Spark partition 数
separator: | // 属性分隔符
header: false // 无表头设置,false 表示无表头
}
{
name: Place
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/static/place.csv"
fields: [_c1,_c2,_c3]
nebula.fields: [name, type, url]
vertex: _c0
batch: 2000
partition: 180
separator: |
header: false
}
{
name: Organisation
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/static/organisation.csv"
fields: [_c1,_c2,_c3]
nebula.fields: [name, type,url]
vertex: _c0
batch: 2000
partition: 180
separator: |
header: false
}
{
name: Post
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/post.csv"
fields: [_c1,_c2,_c3,_c4,_c5,_c6,_c7]
nebula.fields: [imageFile,creationDate,locationIP,browserUsed,language,content,length]
vertex: _c0
batch: 2000
partition: 180
separator: |
header: false
}
{
name: Comment
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/comment.csv"
fields: [_c1,_c2,_c3,_c4,_c5]
nebula.fields: [creationDate,locationIP,browserUsed,content,length]
vertex: _c0
batch: 2000
partition: 180
separator: |
header: false
}
{
name: Forum
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/forum.csv"
fields: [_c1,_c2]
nebula.fields: [creationDate,title]
vertex: _c0
batch: 2000
partition: 180
separator: |
header: false
}
{
name: Tag
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/static/tag.csv"
fields: [_c1,_c2]
nebula.fields: [name,url]
vertex: _c0
batch: 2000
partition: 180
separator: |
header: false
}
{
name: Tagclass
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/static/tagclass.csv"
fields: [_c1,_c2]
nebula.fields: [name,url]
vertex: _c0
batch: 2000
partition: 180
separator: |
header: false
}
]
# 开始处理边数据
edges: [
{
name: KNOWS //边类型
type: {
source: csv //文件类型
sink: client //同上 tag 的 sink 说明
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/person_knows_person.csv" //同上 tag 的 path 说明
fields: [_c2] //无表头的,设定 _c2 为表头
nebula.fields: [creationDate] // 属性值和表头映射,这里为 KNOW 类型边中的 creationDate 属性
source: {
field: _c0 // 源数据中作为 KNOW 类型边起点的列
}
target: {
field: _c1 // 源数据中作为 KNOW 类型边终点的列
}
batch: 2000 // 单批次写入的最大边数据
partition: 180 //同上 tag 的 partition 说明
separator: | //同上 tag 的 separator 说明
header: false // 同上 tag 的 header 说明
}
{
name: LIKES
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/person_likes_comment.csv"
fields: [_c2]
nebula.fields: [creationDate]
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: LIKES
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/person_likes_post.csv"
fields: [_c2]
nebula.fields: [creationDate]
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: HAS_TAG
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/forum_hasTag_tag.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: HAS_TAG
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/comment_hasTag_tag.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: HAS_TAG
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/post_hasTag_tag.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: HAS_TYPE
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/static/tag_hasType_tagclass.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: HAS_MODERATOR
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/forum_hasModerator_person.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: HAS_MEMBER
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/forum_hasMember_person.csv"
fields: [_c2]
nebula.fields: [joinDate]
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: HAS_INTEREST
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/person_hasInterest_tag.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: HAS_CREATOR
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/post_hasCreator_person.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: HAS_CREATOR
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/comment_hasCreator_person.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: IS_PART_OF
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/static/place_isPartOf_place.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: CONTAINER_OF
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/forum_containerOf_post.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: IS_LOCATED_IN
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/person_isLocatedIn_place.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: IS_LOCATED_IN
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/post_isLocatedIn_place.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: IS_LOCATED_IN
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/comment_isLocatedIn_place.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: IS_LOCATED_IN
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/static/organisation_isLocatedIn_place.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: REPLY_OF
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/comment_replyOf_comment.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: REPLY_OF
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/comment_replyOf_post.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: STUDY_AT
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/person_studyAt_organisation.csv"
fields: [_c2]
nebula.fields: [classYear]
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: WORK_AT
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/dynamic/person_workAt_organisation.csv"
fields: [_c2]
nebula.fields: [workFrom]
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
{
name: IS_SUBCLASS_OF
type: {
source: csv
sink: client
}
path: "hdfs://192.168.xx.2:9000/ldbc/sf100/social_network/static/tagclass_isSubclassOf_tagclass.csv"
fields: []
nebula.fields: []
source: {
field: _c0
}
target: {
field: _c1
}
batch: 2000
partition: 180
separator: |
header: false
}
]
}
在上面的第一次配置 tag 和 edge 的时候,我增加了一些字段说明,具体的大家可以翻阅下 NebulaGraph Exchange 的文档来获得更详细的说明: https://docs.nebula-graph.com.cn/3.3.0/nebula-exchange/use-exchange/ex-ug-import-from-csv/
## 06. Spark 提交参数配置
Spark 集群有三个节点,每个节点配置为 96 core, 256 G 内存。

配置的 Spark 提交命令如下:
spark-submit --master "spark://127.0.0.1:7077" \\
--driver-memory=2G \\
--executor-memory=30G \\
--total-executor-cores=120 \\
--executor-cores=10 \\
--num-executors=3 \\ // 对 standalone 模式无效
--class com.vesoft.nebula.exchange.Exchange \\
nebula-exchange_spark_2.4-3.3.0.jar -c app.conf
## 07. 测试结果
在测试中,我们修改了 NebulaGraph Exchange 配置文件中的 batch 数、 partition 数和 spark-submit 提交命令中的 total-executor-cores 数来调整导入的并发度,导入结果如下:
| Dataset | Data Amount | NebulaGraph storaged.conf: max_subcompactions | NebulaGraph storaged.conf: disable_auto_compaction | Spark: total-executor-cores | Spark:executor-cores | Spark:executor-memory | Exchange conf : batch | Exchange conf: partition | duration |
|---|---|---|---|---|---|---|---|---|---|
| LDBC sf100 | vertex:282,386,021,edge:1,775,513,185 | 4 | FALSE | 120 | 10 | 30 G | 2,000 | 360 | 1.9 h |
| LDBC sf100 | vertex:282,386,021,edge:1,775,513,185 | 64 | FALSE | 120 | 10 | 30 G | 2,000 | 360 | 1.0 h |
| LDBC sf100 | vertex:282,386,021,edge:1,775,513,185 | 64 | FALSE | 180 | 10 | 30 G | 2,000 | 360 | 1.1 h |
| LDBC sf100 | vertex:282,386,021,edge:1,775,513,185 | 64 | FALSE | 180 | 10 | 30 G | 3,000 | 360 | 1.0 h |
| LDBC sf100 | vertex:282,386,021,edge:1,775,513,185 | 64 | FALSE | 90 | 10 | 30 G | 2,000 | 180 | 1.1 h |
当 max_subcompaction 为 64 时,NebulaGraph 机器的磁盘和网络 io 使用情况(时间 15:00 之后的部分)如下:

在进行导入时,storaged 服务的 max_subcompaction 配置对导入性能有很大影响。当 NebulaGraph 机器的 io 达到极限时,应用层的配置参数对导入性能影响甚微 。
## 08. 关键性能字段
这里,再单独拉出来关键字段来讲下,大家可以根据自身的数据量、机器配置来调整相关参数。
### NebulaGraph Exchange 的 app.conf
这里需要重点关注前面两个字段,当然后面的字段也不是不重要:
partition, 根据 Spark 集群的机器核数决定 partition 配置项的值 。partition 的值是 spark-submit 命令中配置的总核数的 2-3 倍,其中:总核数 = num-executors * executor-cores。batch,client 向 graphd 发送的一个请求中有多少条数据。在该实践中采用的 LDBC 数据集的 tag 属性不超过 10 个,设置的 batch 数为 2,000。 如果 tag 或 edgeType 属性多且字节数多,batch 可以调小 ,反之,则调大。nebula.connection.timeout,NebulaGraph 客户端与服务端连接和请求的超时时间。若网络环境较差,数据导入过程出现 "connection timed out",可适当调大该参数。(read timed out 与该配置无关)nebula.error.max,允许发生的最大失败次数。当客户端向服务端发送请求的失败数超过该值,则 NebulaGraph Exchange 退出。nebula.error.output,导入失败的数据会被存入该目录。nebula.rate.limit,采用令牌桶限制 NebulaGraph Exchange 向 NebulaGraph 发送请求的速度,limit 值为 每秒向令牌桶中创建的令牌数 。nebula.rate.timeout,当速度受阻无法获取令牌时,允许最大等待的时间,超过该时间获取不到令牌则 NebulaGraph Exchange 退出。单位:ms。
### Spark 的 spark-submit
这里主要讲下 spark-submit 命令关键性使用指引,详细内容可参考 Spark 文档: https://spark.apache.org/docs/latest/spark-standalone.html
spark-submit 有多种提交方式,这里以 standalone 和 yarn 两种为例:
- standalone 模式:
spark://master_ip:port - yarn 模式:由于 yarn cluster 模式下会随机选择一台机器作为 driver 进行 job 提交。如果作为 driver 的那个机器中没有 NebulaGraph Exchange 的 jar 包和配置文件,会出现 "ClassNotFound" 的异常,参考论坛帖子: https://discuss.nebula-graph.com.cn/t/topic/9766 。所以,yarn 模式下需要在 spark-submit 命令中配置以下参数:
--files app.conf \\
--conf spark.driver.extraClassPath=./ \\ // 指定 NebulaGraph Exchange jar 包和配置文件所在的目录
--conf spark.executor.extraClassPath=./ \\ // 指定 NebulaGraph Exchange jar 包和配置文件所在的目录
除了提交模式之外,spark-submit 还有一些参数需要关注下:
--driver-memory,给 spark driver 节点分配的内存。client 模式(还有 sst 模式)导入时,该值可采用默认值不进行配置,因为没有 reduce 操作需要用到 driver 内存。--executor-memory,根据源数据的 size M 和 partition 数 p 进行配置,可配置成 2*( M/p)。--total-executor-cores,standalone 模式下 Spark 应用程序可用的总 cores,可根据 Spark 集群的总 cores 来配。--executor-cores,每个 executor 分配的核数。在每个 executor 内部,多个 core 意味着多线程共享 executor 的内存。可以设置为 5-10,根据集群节点核数自行调节。--num-executors,yarn 模式下申请的 executor 的数量,根据集群节点数来配置。可以设置为((节点核数-其他程序预留核数)/executor-cores)*集群节点数,根据节点资源自行调节。比如,一个 Spark 集群有三台节点,每节点有 64 核,executor-cores 设置为 10,节点中为其他程序预留 14 核,则 num-executors 可设置为 15,由公式推断而出((64-14)/10)*3 = 15。
### 其他调优
在该实践中,NebulaGraph 除第二步骤提到的优化配置,其他配置均采用系统默认配置,NebulaGraph Exchange 的导入并发度最小为 90,batch 为 2,000。当提高应用程序的并发度时或 batch 数时,导入性能无法再提升。因此可以在优化 NebulaGraph storaged 配置的基础上,适当调整并发度和 batch 数,在自己环境中得到两者的平衡,使导入过程达到一个最佳性能。
关于 Spark 的 total-executor-cores 、 executor-cores 、 num-executors 和配置文件中的 partition 的关系:
- 在 standalone 模式下,启动多少个 executor 是由
--total-executor-cores和--executor-cores两个参数来决定的,如果设定的--total-executor-cores是 10,--executor-cores是 5,则一共会启动两个 executor。此时给应用程序分配的总核数是total-executor-cores的值。 - 在 yarn 模式下,启动多少个 executor 是由
num-executors来决定的,此时给应用程序分配的总核数是executor-cores * num-executors的值。 - 在 Spark 中可执行任务的 worker 一共是分配给应用程序的总 cores 数个,应用程序中的任务数有 partition 数个。如果任务数偏少,会导致前面设置的 executor 及 core 的参数无效,比如 partition 只有 1,那么 90% 的 executor 进程可能就一直在空闲着没有任务可执行。Spark 官网给出的建议是 partition 可设置为分配的总 cores 的 2-3 倍,如 executor 的总 CPU core 数量为 100,那么建议设置 partition 为 200 或 300。
## 0. 如何选择数据导入工具
想必通过上面的内容大家对 NebulaGraph Exchange 的数据导入性能有了一定的了解,下图为 NebulaGraph 数据导入工具的分布图:
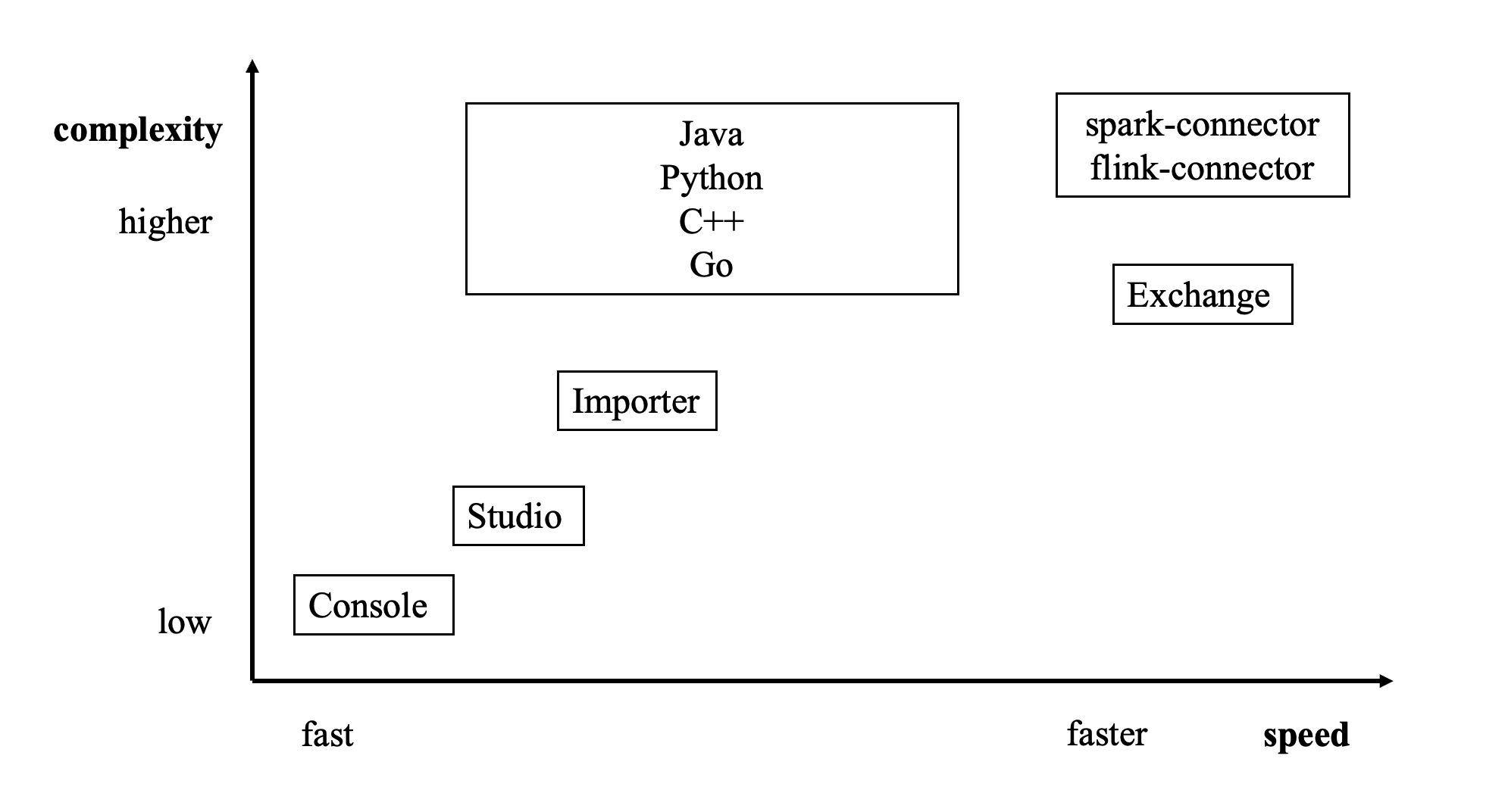
感兴趣的小伙伴可以阅读文档 https://docs.nebula-graph.com.cn/3.3.0/20.appendix/write-tools/ 了解具体的选择事项。
谢谢你读完本文 (///▽///)
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 1 · 赞 1
评论 0 · 赞 0
评论 1 · 赞 1
评论 0 · 赞 0
添加新评论0 条评论