布隆过滤器(Bloom Filter)原理和应用浅说(一)
缘起
1970 年 7 月, Burton Howard Bloom 在《 Communications of the ACM 》上发表了名为“ Space/Time Trade-offs in Hash Coding with Allowable Errors ”的论文。在这篇文章中, Bloom 提出了一种新的方法,用于判断一个元素是否在某个集合里面。这种新方法后来被称为布隆过滤器( Bloom Filter )。布隆过滤器有两个基本特点,其一是节省存储空间,或者反过来说就是在相同的内存空间里可以查询更多的数据集;其二是查询结果具有一定的概率性。这两个特点看似有些平淡无奇,实际却威力巨大,布隆过滤器(及其变体)成为人们应对海量数据高速查询的利器,广泛应用于各种应用软件和系统软件中。
下图是我在网上找的一个 Bloom 先生的照片。
从一个简单问题开始
我们首先看一个简单的问题,查找一个元素是否在一个集合中。具体问题如下:
问题一:有 A,B 两个文件,各存放 500 条 URL ,每条 URL 占用 64 字节,找出 A,B 文件共同的 URL 。
这个问题的解法很容易,只要将 A,B 文件读入内存,然后将 A 文件中的每个 URL 和 B 文件中的进行比较。所需比较次数为 25 万;所需内存约为 64KB 。这个计算量和内存需要对计算机是小菜一碟。
如果把文件的 URL 条目增加一些,变为如下问题:
问题二:有 A,B 两个文件,各存放 500 万条 URL ,每条 URL 占用 64 字节,找出 A,B 文件共同的 URL 。
这个问题采用和问题一同样的方法,所需比较次数为 25 万亿;所需内存约为 640MB 。这个计算量和内存需求就有点大了,但还能忍受。
如果把文件的 URL 条目再增加一些,变为如下问题:
问题三:有 A,B 两个文件,各存放 500 亿条 URL ,每条 URL 占用 64 字节,找出 A,B 文件共同的 URL 。
对此问题还是采用相同的方法,此时所需比较次数为 25 万亿亿,所需内存约为 6400GB 。这个计算量和内存需求量已经超出了普通服务器的能力。当然,我们可以采用分而治之的方法,由多个服务器来完成计算任务,但需要消耗更多的资源。那么,有没有什么方法能在使用较少的计算量和内存情况下完成问题三呢?
强大的 HASH 方法
谷歌技术大牛 Steve Yegge 说,“哈希表可以说是人类已知的最重要的数据结构”( Hashtables are arguably the single most important data structure known to mankind )。
对于问题三,我们首先想到的就是利用哈希表的方法。哈希表是根据键值 (Key value) 而直接进行访问的数据结构。它利用一个函数把键值映射到索引数组中一个特定位置来访问记录,并以此加快查找的速度。这个映射函数叫做哈希函数,存放记录索引的数组叫做索引表。问题三中, URL 就是 Key value ,我们可以将文件 B 中的所有 URL 读出,利用哈希函数生成索引表。然后读取文件 A 中的每个 URL ,利用同样的 HASH 函数计算出索引值,直接查找索引表的对应位置来确定这个 URL 是否在 B 文件中(索引表中存储的是指向 Entries 的指针,如果对应位置的指针为空,则说明 B 中不包含此 URL ;如果非空,则访问指针指向的 Entry 进行比对以确定是否有相同的 URL )。利用这样的方法,我们可以把查找对比所需的计算量从 O(N2) 降低到 O(N) 。其示意图如下:

利用哈希表方法, B 文件生成的索引表需要保存在内存中,我们估计一下索引表需要的内存大小。为了将索引表中冲突项的比例控制在一定范围,我们将索引表数组大小设置成文件 URL 数目的 1.5 倍,即数组长度为 750 亿,此时占用的内存空间为 600GB 。这个空间占用还是有点大,有什么方法能减小索引表的大小呢?
布隆过滤器的基本思想
哈希表数组之所以较大,一方面是因为数组比较大(减少冲突概率),另一方面就是数组的每一项需要 8 个字节(存放指向 Entry 的指针,从而可以索引到实际数据)。如果我们放弃对数据项的索引需求,只是概率性地判断某个元素是否在一个集合中,则可以使用位图( bitmap )的方法,把哈希表数组换成具有同样索引数目的位图,则此时内存占用就变成了原来的 64 分之一。换成位图后, B 文件中每个 URL 通过 HASH 函数计算出索引值后,把相应的 bit 位置成 1 。此时如果还是按照上文中的 HASH 方法判断文件 A 中的 URL 是否存在于 B 文件中(对应的哈希函数值所在的 bit 位为 1 就判定存在,为 0 则判定不存在),则由于哈希冲突的存在,一定存在较高的误判率。那么如何降低误判率呢?一个直观的想法就是采用多重检验,即采用多个独立的哈希函数同时比对!这就是布隆过滤器的基本思想。布隆过滤器的基本过程如下:
1, 初始化数组:开辟一个固定长度为 m 的位数组,并将数组的元素( bit 位)都置成 0 。
2, 向数组中添加元素:向布隆过滤器数组中增加任意一个元素 x 时候,我们使用 k 个独立的哈希函数得到 k 个哈希值,然后将这些哈希值在数组中对应的比特位设置为 1 。注意,如果一个位置多次被置为 1 ,那么只有第一次会起作用,后面几次将没有任何效果。示意图如下:
3, 判断某个元素是否在集合中:在判断 y 是否属于这个集合时,我们只需要对 y 使用 k 个哈希函数得到 k 个哈希值,如果这些 hashi(y) 的位置存在 0 值,则 y 一定不在集合中(如下图中的 y1 );如果 k 个位置都被设置为 1 了,那么 y 可能在集合中,也可能不在集合中。示意图如下:
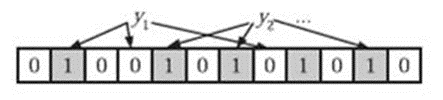
对于 k 个位置都是 1 ,但 y 实际不在集合中的情况,我们称之为 false positive (假阳性)。
通过以上过程我们看到,布隆过滤器可以以较少的内存空间,高效地,概率性(允许一定的误判率)地判断一个元素是否在某个给定的集合中。在实际应用中,不仅要有定性判断,还要有定量结果:对于给定元素数量的集合,在一定误判率的要求下,到底需要多大的内存,需要多少个哈希函数。
先说结论。假定位数组的长度为 m ,集合元素个数是 n ,哈希函数个数是 k ,误判率是 f 。则:
1 :在 m 、 n 、 k 固定的情况下,
2 :在 m 、 n 固定的情况下,要使 f 取得最小值,最佳的哈希函数个数 k = ln2*(m/n)
3 :在给定 n , f 的情况下,位数组的最小长度 m = n ln(f)/ ln(0.6185)
简要写一下推导过程,不关注的读者请略去。

在由 m 个 bit 组成的数组中,在对元素 x 进行一次 hash 后,某个特定的 bit 不被置成 1 的概率是: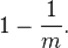
假定共有 k 个 hash 函数 , 那么这特定的一位不被置成 1 的概率就是: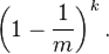
假定总共要插入 n 个元素,则这特定的一位不被置成 1 的概率是:
从而,这特定的一位被置成 1 的概率就是:
考虑如下的集合 S :这个集合的元素由除了这 n 个元素之外的所有数所组成。现在,用此集合中的元素进行 bloom filter 检验。这个集合中的任何一个元素在 k 次 hash 后形成的位置向量中,任何一个特定的 bit 位已经被置成 1 的概率如上所述,利用乘法原理, k 个位置都被置成 1 的概率就是: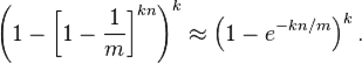
上式利用了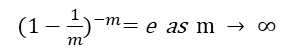
考虑到集合 S 的性质,上式就是误判率!(这块儿需要仔细考虑一下,什么叫误判率,误判率就是说你在集合中,可是你实际不在集合中, S 中的元素就具备这样的性质)。从而  这样,我们就得到了上面结论中的第一个式子。
这样,我们就得到了上面结论中的第一个式子。
下面我们看一下在 m 、 n 固定的情况下,要使 f 最小,所需的哈希函数的个数。我们令  要让 f 取到最小,只要 g 取到最小。令
要让 f 取到最小,只要 g 取到最小。令 则 k=- ( m/n) lnp ,从而 g 可以写成 g = -(m/n)lnp*ln(1-p), 在 m , n 固定时,
则 k=- ( m/n) lnp ,从而 g 可以写成 g = -(m/n)lnp*ln(1-p), 在 m , n 固定时,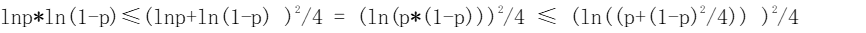 上式两次利用了: a*b ≤ (a+b)^2/4 ,当且仅当 a=b 时,等号成立
上式两次利用了: a*b ≤ (a+b)^2/4 ,当且仅当 a=b 时,等号成立
从而可知:当 p = 1/2 ,也就是 k = ln2 · (m/n) 时, g 取得最小值。就得到了上面结论中的第一个式子。在这种情况下,最小错误率
 最后,我们看一下在给定 n , f 的情况下,位数组所需的最小长度 m 。由上一步中在 m , n 固定下 f 所能取得最小值的公式立即可以得出 m = n ln(f)/ ln(0.6185) ,此即上面结论中的第三个式子。
最后,我们看一下在给定 n , f 的情况下,位数组所需的最小长度 m 。由上一步中在 m , n 固定下 f 所能取得最小值的公式立即可以得出 m = n ln(f)/ ln(0.6185) ,此即上面结论中的第三个式子。
为了对此有些感性认识,我们可以看一些函数关系图。在位数组长度 m 是集合元素个数 n 的 8 倍的假定下,误判率 f 和哈希函数个数 k 的关系图如下:
在上图中,当我们使用 1 个哈希函数时,误判率 f 很高,这也符合直观的感觉。随着哈希函数个数的增加,误判率迅速降低,在哈希函数个数为 5 个时,误判率达到最小。之后,随着哈希函数的增加,误判率又开始上升。这也容易理解,哈希函数过多,会导致位数组中 1 的比例过多,随便一个元素 x 被哈希后判定成 positive 的概率也变大,从而导致 f 值上升。
再看一个误判率 f 和 m/n 比率的一个函数关系图。这个图实际是表示在一定误判率 f 和集合元素个数 n 的假定下,我们需要多大的内存( m )。由上文中的结论 3 可知:

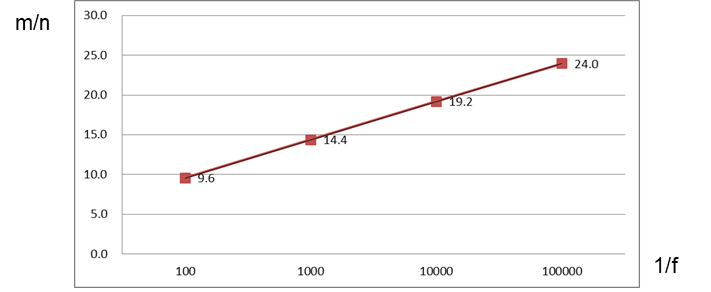
上图中,我们把横坐标取作 f 的倒数。上图意味着,在百分之一的误判率情况下,平均每个元素仅需要 9.6 个 bit ,千分之一误判率下每个元素需要 14.4 个 bit 。布隆过滤器的大小与数据项本身大小(字符串值的长度)无关!
对于本文中的问题三,即 500 亿问题,在误判率为百分之一的情况下,位数组所需内存为 60GB ;在误判率为千分之一的情况下,所需内容为 90GB 。回想采用 HASH 表方法时,哈希索引需要 600GB 的内存空间,布隆过滤器的内存占用的确是少了很多!
未完,待续。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 1 · 赞 2
评论 2 · 赞 4
评论 1 · 赞 3
评论 1 · 赞 1
评论 1 · 赞 1
添加新评论0 条评论