Zabbix+MatrixDB大规模监控与分析解决方案详解(含PPT)
首先,谢谢原作者:(此文为转载的文章,现将原地址贴出如下:以下文章来源于yMatrix,作者MatrixDB团队Zabbix+MatrixDB大规模监控与分析解决方案详解(含PPT))
更多精彩Zabbix文章、技术交流、免费技术培训加微号NateIT,免费获取zabbix安装、配置、优化技术培训视频
官网: http://ywzs.hanyunintel.com
30秒执行摘要:
- Zabbix存储常用单机PostgreSQL/MySQL和InfluxDB。在数据量小的情况下,表现还不错,但随着监控的设备量、系统和应用指标越来越多时,数据量往往会很大,单机方案存在插入慢、单机储存瓶颈及查询慢的问题。
- 传统做法是采用分区表的方式进行储存,剥离一段时间以前的数据,带来的问题是监控数据储存不集中,无法提供统一的服务。
- 另一种做法是采用部署多套Zabbix监控系统解决,带来的问题是无法提供统一的监控、告警。
- 目前监控系统已经走向精细化、多样化、平台化、统一化。甚至,走向监控智能化,这就需要统一的储存、计算平台。
- MatrixDB采用MPP架构,支持大规模数据储存、高性能计算,为Zabbix走向监控智能化、统一化、趋势化预测提供坚实底座
一、背景
本文章为2021年8月6日Zabbix大会分享的内容,转为文字进行分享。

目前Zabbix官方支持的MySQL和PostgreSQL储存方案都是单机,扩展性不够,而且监控设备、系统指标多了之后,插入性能也会是个问题。数据量大的情况下,查询性能也比较差,直接影响Zabbix可用性和告警及时性。
传统的做法是对MySQL和PostgreSQL做分表处理,同时剥离一段时间以前的数据,保留最小需要的数据。其次,就是部署多套Zabbix系统,分别储存不同的监控数据。带来的问题是监控数据储存不集中,无法提供统一的告警服务、监控管理平台、二次分析聚合困难、架构复杂以及成本高。
目前监控系统的建设目标已经走向精细化、多样化、平台化、统一化、智能化,甚至走向趋势化预测。大规模监控的数据具有具有强时间序列、高并发插入以及数据量大的特点。为了Zabbix能支持大规模设备、应用、中间件的监控、告警。急需一款能支持高速插入、横向扩展、高性能查询、分析聚合、甚至支持库内分析挖掘的底层分布式数据库。以满足统一监控、全链路追踪、告警的需求。
MatrixDB是超融合时序数据库,将交易型数据库(OLTP)、分析型数据库(OLAP)和时序数据库能力融为一体,且以分析见长。采用MPP架构,支持大吞吐量数据高速写入;同时,产品具有良好的线性扩展性,可以通过添加节点的方式,线性提升系统的写入速度、计算能力;MatrixDB支持在线横向扩容,不中断服务;支持海量数据存储和计算,满足大数据量高速写入和高效查询。
本篇博文将详细介绍Zabbix大会的分享内容,包括架构及单机储存方案缺点,MatrixDB的介绍及Matrixdb适配Zabbix,并且对Zabbix进行了两种方案的性能压测。
二、Zabbix架构介绍
Zabbix是一款功能强大的开源监控软件,它操作简单,适用于多种平台,能够支持虚拟化、云环境等多种场景的监控,且提供开放的、通用的API接口,在各行业都有广泛的使用。
Zabbix整体架构图如下:

Zabbix单机方案不足
从Zabbix的架构图中,我们可以看到,Zabbix常用的储存方案是PostgreSQL和MySQL,但目前中大型公司,有几百台,甚至上千台、万台机器,对于有精细化监控需求的场景,每台机器上百个指标,还有各种应用、中间件、网络设备等需要监控。这么多监控数据需要采集、插入、储存、展示。单机方案在面临数据高速插入时,往往也会成为瓶颈,更别提高效查询和分析处理了。如果有突发性的事件,后台负载过高,单机算力不足,往往会有大量的告警延迟、展示缓慢等问题。
所以,一种方案是剥离固定时间以前的数据,只保留部分数据,但因为审计或需要查询历史数据时,又需要很繁琐的数据数据迁移整合。另一种方案是采用部署多套Zabbix的方式解决。部署多套Zabbix确实部分缓解了海量数据插入和查询的问题,但监控数据需要涉及上下游的排查、回溯、根因分析等,需要把数据统一汇聚到一个库,做问题排查与分析,这时又带来了数据汇聚的难题,同时也增加了架构复杂度和机器数量、提升了总体成本及管理复杂度。
对于想建设一体化的监控平台、达到监控智能化的目标、实现问题根因分析甚至进行趋势预测的企业来说,单机方案的储存、算力和功能都明显不足。这时就急需对Zabbix的底层存储进行适配新的方案。
三、MatrixDB架构介绍
MatrixDB是超融合数据库,将交易型数据库(OLTP)、分析型数据库(OLAP)和时序数据库能力融为一体的超融合型分布式数据库产品,具备严格分布式事务一致性、水平在线扩容、安全可靠、成熟稳定、兼容PostgreSQL/Greenplum协议和生态等重要特性。为万物互联的智能时代提供坚实、简洁的智能数据核心基础设施,为物联网应用、工业互联网、智能运维、智慧城市、实时数仓、智能家居、车联网等场景提供一站式高效解决方案,MatrixDB为公司自主研发的国产数据库,公司拥有该产品全部知识产权。
产品的架构如下:

3.1 产品具备如下亮点:
MatrixDB不但对经典的Greenplum数据仓库场景进行了大幅增强,而且可以极佳的支持大规模时序数据处理、支持时空数据、结构化数据和半结构化数据,一套数据库解决各种数据类型,避免为了处理不同类型数据引入不同类型的产品。实现提高开发运维效率、提升系统性能、降低整体成本的目标。

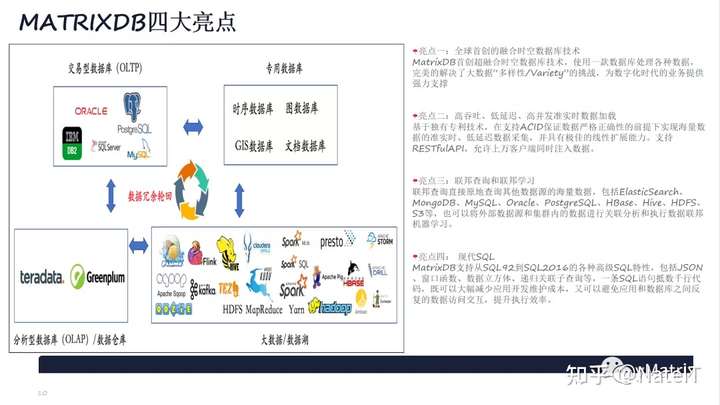
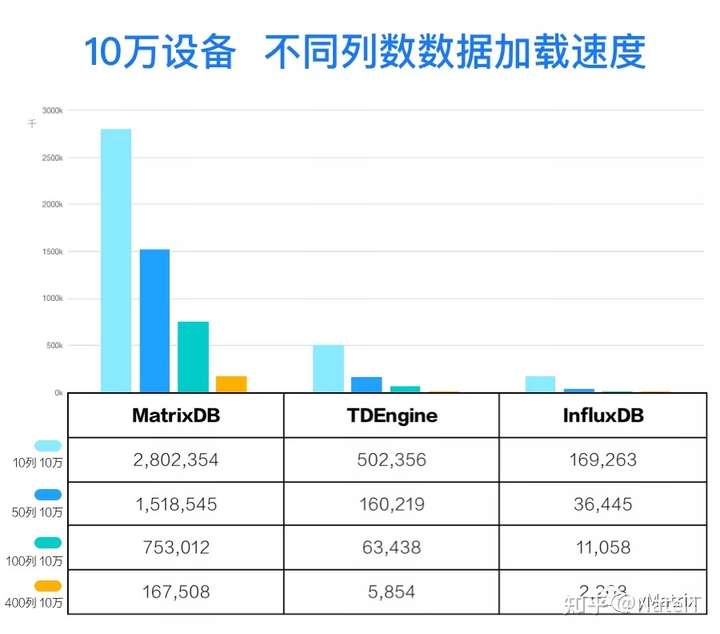
3.1.1 大规模实时/准实时数据采集
基于独有专利技术,在支持ACID保证数据严格正确性的前提下实现海量数据的准实时/低延迟数据采集,并具有极佳的线性扩展能力,支持RESTful API,允许上万客户端同时注入数据。

大规模数据量的插入速度:
3.1.2 高效数据存储
- 支持多种压缩方式,压缩比可以多达15:1,有效降低存储开销。
- 基于独创索引技术,在保证效率的情况下,大大降低索引占用空间。
- 支持多态存储,为不同特征的数据采用最佳访问模式,在存储空间和访问时间中取得最佳平衡。
3.1.3 10X-100X 查询性能提升
- 相比于常用时序系统,可以实现高达10倍-100倍以上的性能提升
- 原生支持时序操作函数,大大简化应用开发,提升效率
- 支持高级分析能力
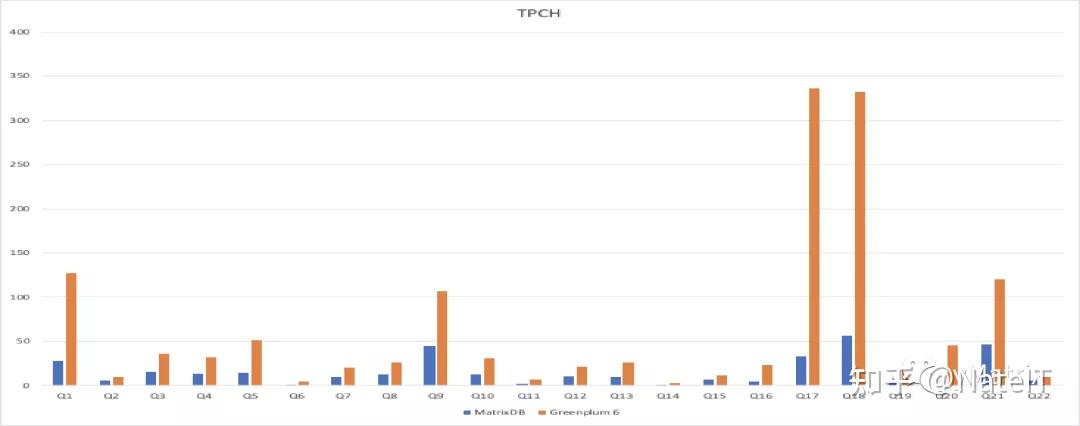
分析型查询性能:国际TPCH基准测试 多核并行技术充分利用CPU算力,相比Greenplum总体提升TPC-H 22条查询提升4倍,相比Hive等快100倍
3.1.4 内置机器学习和人工智能算法
MatrixDB内置60+常见的机器学习算法(包括监督学习、无监督学习、图算法等)和人工智能算法库(包括Tensorflow、Keras等),采用先进的计算贴近海量数据架构,避免了传统机器学习数据贴近计算的束缚,在全量数据上并行训练数据模型,可以大幅提升模型精度和训练速度,实现数据+智能闭包。
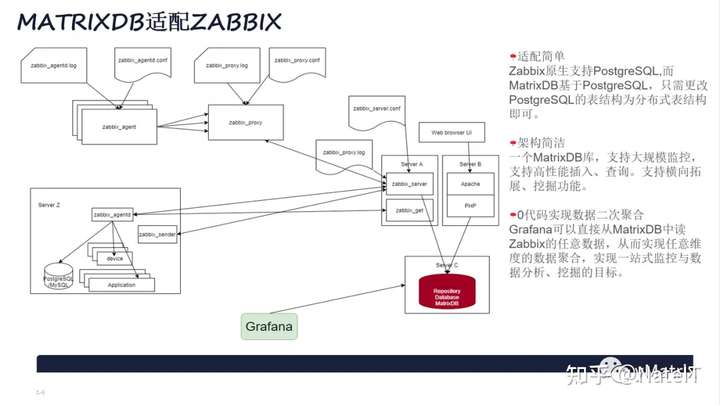
3.2 MatrixDB适配Zabbix方案
MatrixDB和PostgreSQL高度兼容,但具备分布式架构、支持横向扩展、海量数据储存、计算。适配Zabbix,需要把表结构改为分布式的表结构。
四、Zabbix性能压测
4.1 压测方案一
4.1.1 采用zabbix-server-stress-test库及方法压测
拉取并安装zabbix-server-stress-test库,按照如下方式进行安装
1 server下载
2 wget https:// cdn.zabbix.com/zabbix/s ources/stable/5.0/zabbix-5.0.12.tar.gz
3 tar -zxvf zabbix-5.0.12.tar.gz
4 cd zabbix-5.0.12
5 ./configure --enable-agent
6 mkdir src/modules/zabbix_module_stree
7 cd src/modules/zabbix_module_stree
8 wget https:// raw.githubusercontent.com /monitoringartist/zabbix-server-stress.
9 wget https:// raw.githubusercontent.com /monitoringartist/zabbix-server-stress.
10 make
11 gcc -fPIC -shared -o zabbix_module_stress.so zabbix_module_stress.c -I../../
12 [root@sdw4 zabbix_module_stree]# ls
13 Makefile zabbix_module_stress.c zabbix_module_stress.so
14
15 [root@sdw4 zabbix_module_stree]# sudo cp zabbix_module_stress.so /etc/zabbix
16 [root@sdw4 zabbix_module_stree]# ls /etc/zabbix/modules/
17 zabbix_module_stress.so
4.1.2 修改配置文件
上传zabbix模板出错,模板大小超过ngnix的默认上传容量大小,修改为50m
1 vim /etc/opt/rh/rh-nginx116/nginx/nginx.conf
2 nginx client_max_body_size默认只有1MB,修改为如下大小
3 client_max_body_size 50m;
4
5 php参数修改
6 报错 413 Request Entity Too Large
7 vim /etc/opt/rh/rh-php72/php.ini
8 upload_max_filesize = 50M
4.1.3 agent配置
1 vim /etc/zabbix/zabbix_agentd.conf
2 LoadModulePath=/etc/zabbix/modules
3 LoadModule=zabbix_module_stress.so
用2台机器,每台机器拉起200个agent,主动模式推数据到Zabbix server,配置的模板是1000个ping指标,这个方案没有实际的数据写入数据库,只是用ping检测Zabbix agent到Server的连通性,不具有实际场景的价值。
4.2 压测方案二
采用两台机器,每台机器配置200 个代理,共400个代理。Agent设置为主动模式,主动将数据推送到 Zabbix Server。每个代理配置了Zabbix自带的主动模式的Linux监控模板,有41个指标。所有指标均调整为每秒采集一次。我们没有在两者之间部署任何 Zabbix 代理。在Web设置自动注册和关联模板。
4.2.1 Zabbix agent配置
4.2.1.1 Zabbix主动模式配置
1 [root@sdw3 data]# ls /data/zabbix1/
2 modules zabbix_agentd.conf zabbix_agentd.d zabbix_agentd.log zabbix_agent
3 [root@sdw3 data]# cat /data/zabbix1/zabbix_agentd.conf
4 PidFile=/data/zabbix1/zabbix_agentd.pid
5 LogFile=/data/zabbix1/zabbix_agentd.log
6 LogFileSize=0
7 Server=192.168.100.14
8 ListenPort=10051
9 ServerActive=192.168.100.14
10 Hostname=sdw3_10051
11 Include=/data/zabbix1/zabbix_agentd.d/*.conf
4.2.1.2 批量拉起agent的脚本
1 [root@sdw3 data]# cat moreagent.sh
2 #!/bin/bash
3 # 批量拉起200个agent并启动
4 for i in {1..200}
5 do
6 echo $i
7 port=$[ 10050+${i} ]
8 echo $port
9 mkdir /data/zabbix${i} -p
10 cp -r /data/zabbix1/* /data/zabbix${i}/
11 #rm -rf /data/zabbix${i}/*.log
12 #rm -rf /data/zabbix${i}/*.pid
13 sed -i 's/10051/'${port}'/g' zabbix${i}/zabbix_agentd.conf
14 sed -i 's/zabbix1/'zabbix${i}'/g' zabbix${i}/zabbix_agentd.conf
15 chown zabbix.zabbix -R /data/zabbix${i}/
16 zabbix_agentd -c /data/zabbix${i}/zabbix_agentd.conf
17 done
4.2.2 Zabbix server配置
1 [shidb@sdw4 ~]$ sudo cat /etc/zabbix/zabbix_server.conf |grep -v '^_#'|grep -v "^$"_
2 ListenPort=10051
3 SourceIP=192.168.100.14
4 LogFile=/var/log/zabbix/zabbix_server.log
5 LogFileSize=0
6 DebugLevel=3
7 PidFile=/var/run/zabbix/zabbix_server.pid
8 SocketDir=/var/run/zabbix
9 DBHost=sdw7
10 DBName=zabbix
11 DBUser=zabbix
12 DBPassword=123456
13 DBPort=5432
14 StartPollers=50
15 StartPollersUnreachable=10
16 StartTrappers=500
17 StartPingers=10
18 StartDiscoverers=50
19 StartAlerters=30
20 VMwareCacheSize=1024M
21 SNMPTrapperFile=/var/log/snmptrap/snmptrap.log
22 MaxHousekeeperDelete=100
23 CacheSize=2048M
24 StartDBSyncers=10
25 HistoryCacheSize=1024M
26 HistoryIndexCacheSize=400M
27 TrendCacheSize=1024M
28 ValueCacheSize=2048M
29 Timeout=30
30 TrapperTimeout=300
31 UnreachablePeriod=45
32 UnavailableDelay=60
33 UnreachableDelay=15
34 AlertScriptsPath=/usr/lib/zabbix/alertscripts
35 ExternalScripts=/usr/lib/zabbix/externalscripts
36 FpingLocation=/usr/sbin/fping
37 LogSlowQueries=10000
38 StartProxyPollers=100
39 ProxyConfigFrequency=3600
40 StartLLDProcessors=10
4.2.3 Zabbix Web UI配置
4.2.3.1 设置自动发现规则
在Configuration->Discovery处设置

其中IP range为你服务的ip范围,192.168.100.10-17,代表从10到17共计7台。
4.2.3.2 设置自动注册名称及条件
在Configuration->Actions处设置
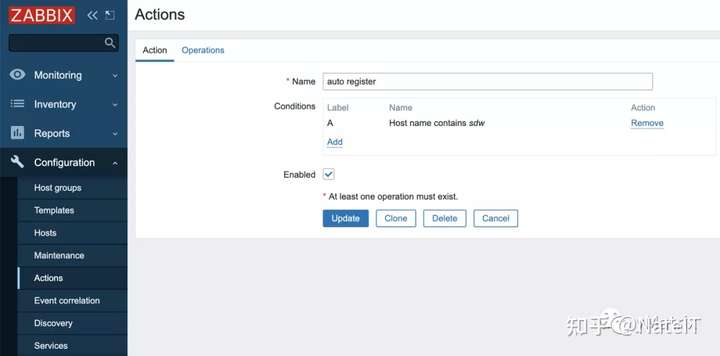
Condition这里,我的主机名是按sdw开头进行命名的,所以填写主机名包含 sdw。
4.2.3.3 设置自动注册的操作
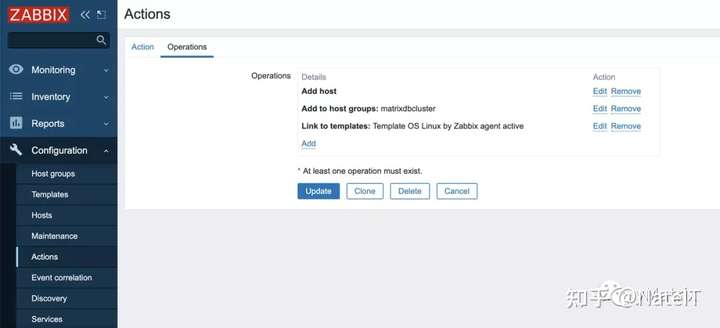
- 添加主机
- 添加主机组matrixdbcluster
关联到Zabbix自带的 Template OS Linux by Zabbix agent active模板
4.2.3.4 完成自动注册
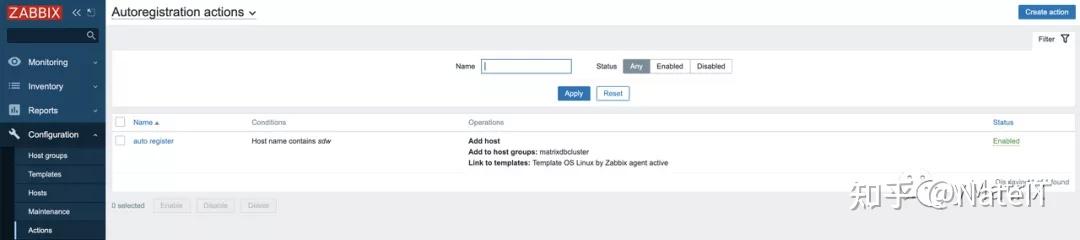
状态这里,一定要开启
4.2.3.5 自动注册结果
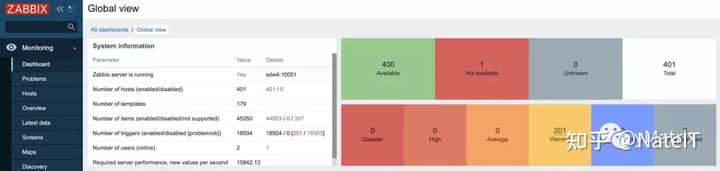
后台每次启动100个agent,每台机器启动200个agent。2台机器,共计400个agent,加上Zabbix server自己的监控,一共是401个agent。
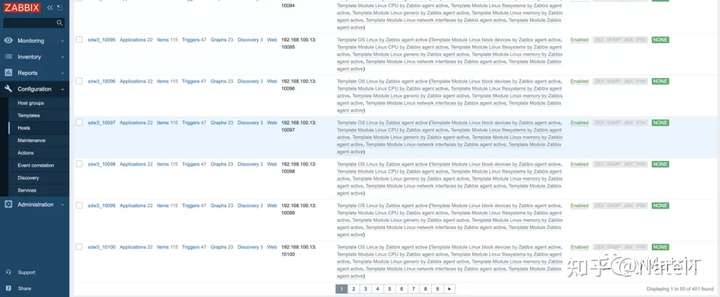
这时,我们就能看到所有已经完成自动注册的agent了。
4.2.3.6 修改采集频率
修改模板的采集频率

4.3 Matrixdb作为后台储存
4.3.1 Matrixdb参数调整
1 gpconfig -c log_min_duration_statement -v 2000 -m 2000
2 gpconfig-c log_statement -v ddl -m ddl
3 gpconfig-c shared_buffers -v 2GB -m 2GB
4 gpconfig-c enable_nestloop -v on -m on
5 gpconfig-c log_duration -v off -m off
6 gpconfig-c shared_buffers -v 2G -m 2G
7 gpstop-M fast -ar
4.4 监控性能数据查看
4.4.1 首页概览
点击Monitoring->Dashboard,查看目前的主机数及运行信息。
点击Monitoring->Hosts
name输入框输入server,点击Apply

4.4.2 查看NVPS
NVPS代表每秒钟的处理指标数,值越高代表性能越好。

4.4.3 Zabbix server进程压力
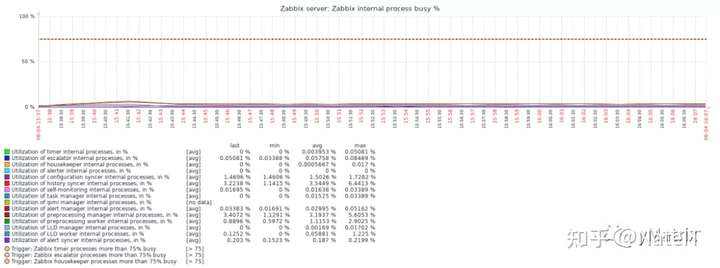
4.4.4 数据收集进程压力

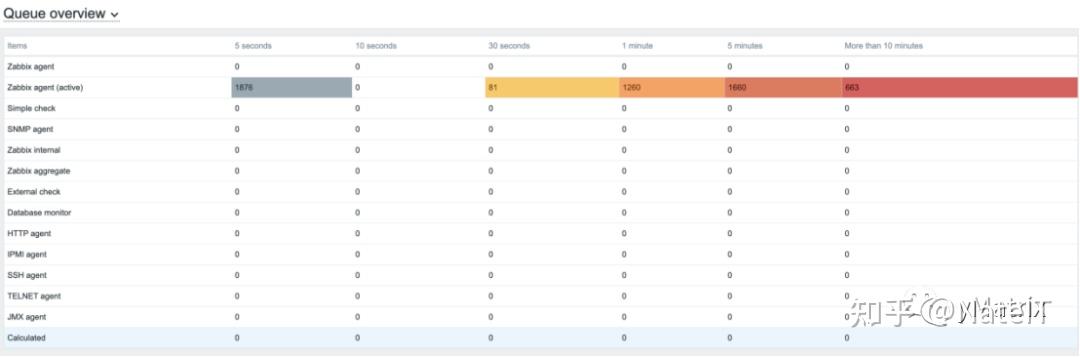
4.4.5 queue队列
4.4.6 队列详情
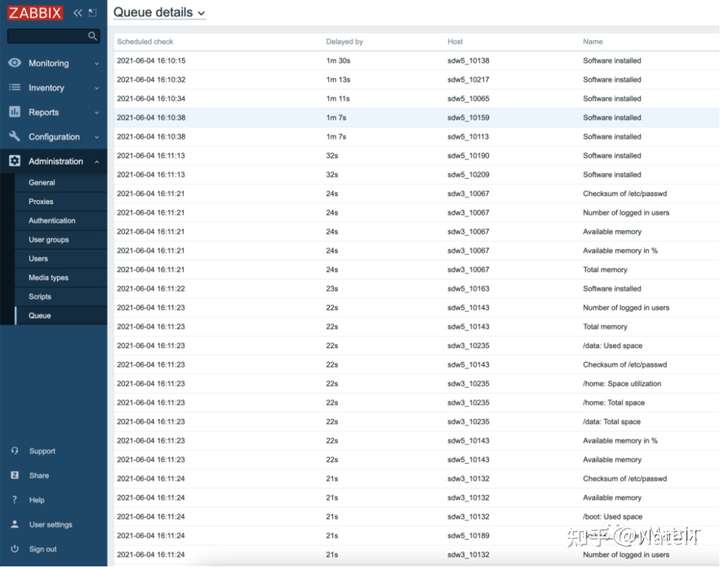
这个方案是Zabbix默认监控linux主机的模板,具有一定的代表性,证明MatrixDB作为Zabbix底层库,能顺利运行。用2台机器,每台拉起200个agent时,发现MatrixDB适配十分简洁,发现少些问题,但都有方案解决,详见第五部分。
五、问题及解决办法
5.1 后台数据库错误日志
1 2021-06-18 10:48:20.644735 CST,"zabbix","zabbix",p33198,th-1770440576,"192.168.100.14","20100",2021-06-18 10:48:19 CST,0,con9558
2 1 0xd3ada3 postgres errstart (elog.c:498)
3 2 0xe036d9 postgres cdbmutate_warn_ctid_without_segid (cdbmutate.c:323)
4 3 0xa3fe2b postgres make_one_rel (allpaths.c:376)
5 4 0xa75e5c postgres query_planner (planmain.c:306)
6 5 0xa7cb3c postgres (planner.c:2493)
7 6 0xa7f68f postgres subquery_planner (planner.c:1286)
8 7 0xa80959 postgres standard_planner (planner.c:524)
9 8 0xa8159d postgres planner (planner.c:317)
10 9 0xb80edc postgres (postgres.c:1013)
11 10 0xb83680 postgres PostgresMain (postgres.c:5273)
12 11 0x6c6e5b postgres (postmaster.c:4620)
13 12 0xade2bf postgres PostmasterMain (postmaster.c:1594)
14 13 0x6cc949 postgres main (discriminator 17)
15 14 0x7f2e93185555 libc.so.6 __libc_start_main + 0xf5
16 15 0x6d846f postgres + 0x6d846f
这是housekeeper在执行逐行删除数据的操作,通过禁用housekeeper解决,使用MatrixDB自动化分区管理功能,可以定期自动将整个过期分区删除,高效简洁。
5.2 慢查询问题
1 select distinct d.triggerid_down,d.triggerid_up from trigger_depends d,triggers t,hosts h,items i,functions f where t.triggerid=d.triggerid_down and t.flags<>2 and h.hostid=i.hostid and i.itemid=f.itemid and f.triggerid=d.triggerid_down and h.status in (0,1);2
3 190375:20210604:171847.981 slow query: 25.379318 sec, "update ids set nextid=nextid+1 where table_name='hosts' and field_name='hostid'"
4
5 190780:20210604:172526.128 slow query: 117.019717 sec, "update ids set nextid=nextid+2where table_name='applications'and f
这是因为数据库中缺乏统计信息,执行计划不准导致,通过手工执行vaccum analyze,加上定时任务每天凌晨定期收集,就可以解决慢查询的问题。
5.3 连接数问题
报连接数不足,可以使用下述命令调整MatrixDB的max_connections1 [mxadmin@sdw7 log]$ gpconfig -c max_connections -v 2000 -m 1000
2 [mxadmin@sdw7 log]$ gpconfig -s max_connections
3 Valuesonall segments areconsistent
4 GUC : max_connections
5 Mastervalue: 1000
6 Segmentvalue: 2000
5.4 queue队列等待很高
我们可以看到刚开始NVPS最高值是可以达到7.2k的,但是一段时间后,因为queue队列堵塞,nvps迅速下降。
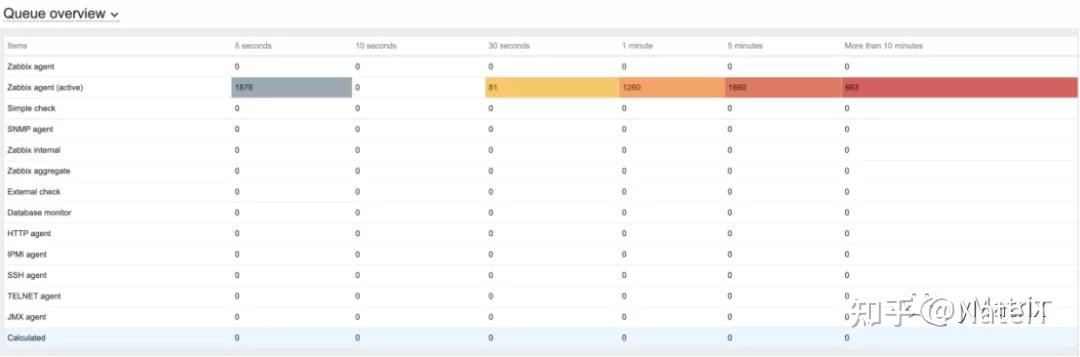
尝试调Zabbix server的参数,但还是没能将queue队列降下去。后台数据库切换为PostgreSQL也存在同样的问题,如果有专家能解决,欢迎交流。
六、结论
MatrixDB将交易型数据库(OLTP)、分析型数据库(OLAP)和时序数据库能力融为一体。采用MPP架构,支持大吞吐量数据高速写入;同时,产品具有良好的线性扩展性,可以通过添加节点的方式,线性提升系统的写入速度、计算能力;MatrixDB支持在线横向扩容,不中断服务;支持海量数据存储和计算,满足大数据量高速写入和高效查询。同时支持大规模时序场景的数据处理,可以完美的满足Zabbix大规模监控与分析的需求。
pdf下载链接:
https:// matrixdb-public.oss-cn-beijing.aliyuncs.com /pdf/zabbix_solution.pdf
搭建Zabbix并适配MatrixDB请参考如下blog:
https:// ymatrix.cn/blog/2021081 2-MatrixDB-zabbixadaptor


更多精彩Zabbix文章、技术交流、免费技术培训加微号NateIT
Zaibbix监控MySQL数据库
Zaibbix监控MS SQL SERVER数据库
Zaibbix监控ORACLE数据库
Zaibbix监控Linux、Windows、AIX、HP-UX、Solaris操作系统
Zaibbix监控中间件
Zaibbix监控网络设备
Zaibbix监控存储设备
葡萄运维助手(英文为 Netpod )是一款新一代IT监控系统,具有成本低、技术门槛低,容易上手的特点,适用于传统型的数据中心、机房、私有云、公有云场景,快速实现各行各业IT系统高效、便捷运维的能力。
运维助手提供对服务器、虚拟化、云主机、网络设备、存储设备、数据库、中间件、业务系统的报警、性能、配置监控,提供Web端的监控大屏以及APP客户端,让你在办公室中享受运维监控大屏,在会议中、出差中、家中以及其它场合中通过APP随时、随地掌控IT系统的运行情况,并且通过运维助手APP轻松实现远程IT系统监控、工单创建、知识查询、业务控制、数据备份、日志查询等工作。
官网: http://ywzs.hanyunintel.com

故障报修
工单处理

如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 4 · 赞 8
评论 1 · 赞 5
评论 0 · 赞 1
评论 0 · 赞 1
评论 0 · 赞 1
添加新评论0 条评论