企业如何打造多品牌服务器运维监控
摘要
本文主要讲解服务器基础知识,接口协议、以及运维中使用这些协议的场景。侧重讲解Redfish协议产生背景、具体原理,并通过PowerEdge演示如何与Zabbix进行集成,让大家快速的建立多品牌服务器的集中运维监控,提升我们的运维效率。
远程管理卡
大部分服务器都配有远程管理卡(又叫远程管理口或带外管理卡/口):DELL名称iDRAC(Integrated Dell Remote Access Controller),HUAWEI名称iBMC(Intelligent Baseboard Management Controller),HPE名称iLO(Integrated Ligths-out),LENOVO名称IMM(integrate management module),INSPUR名称BMC(Baseboard Management Controller )其他不再一一举例。
远程管理卡内置芯片和迷你操作系统,只要服务器通电,并将远程管理卡联网就可以远程控制这台服务器,实现服务远程安装操作系统,软件升级,开关机等操作,避免人工去机房进行现场操作。
远程管理卡协议
远程管理卡常见的运维管理协议包含:ICMP-PING,SNMP-Get,SNMP-Trap,Syslog,HTTP-REST/Redfish,Telemetry,IPMI,CLI等;协议常见用途如下:
ICMP-PING:可以通过此协议探测远程管理卡存活状态;此管理卡宕机不代表服务器宕机,但是为了运维管理必须要保证它运行正常。
SNMP-Get:通过此协议,外部监控系统主动到带外管理卡获取服务器的信息,常见的CPU/内存/磁盘/电源/风扇/温湿度都可以通过此协议获取,可以作为入门级别的服务器监控方案,简单、易用; Zabbix用户可以在share.zabbix.com下载到众多厂商的监控模版。
SNMP-Trap/Syslog:此两种协议都是带外管理卡主动的向外部发送告警信息,和邮件告警异曲同工的作用。数据中心的硬件有可能不支持SNMP-Get协议,但是通常都支持SNMP-Trap/Syslog/Email的告警外发。此类协议接入成本极低,辅助运维监控价值高,通过1分钟的简单配置,就可以实现所有硬件故障告警,如果必要还能收集审计日志做UEBA。
HTTP-REST/Redfish:当前最新的主流的服务器运维管理协议,以HTTP/JSON的方式提供,非常方便开发人员进行基础架构即代码编程(IaC)。也是我们非常推荐使用的协议,后面侧重进行细讲。
Telemetry:遥测协议,当前CNCF主推协议。外部监控系统订阅特定组件,服务器将此部件信息进行主动外发,监控指标间隔可以精确到毫秒,捕获性能毛刺数据;非常适合银行/证券对监控指标采样周期有非常高的业务场景;但是在服务器领域支持比较少,服务器DataCenter版本有非常细的支持,后续会在为大家进行此协议专门分享。此当前用的少,监控工具支持的少,落地实施难度高。
IPMI:此协议服务器厂商基本上都支持,上一代的服务器管理标准协议,此协议不仅能够做监控而且能够进行自动化操作。但是由于功能缺失,性能损耗高,安全漏洞多等众多问题IPMI也在2015年公布2.0 v1.1标准后,不再更新,被Redfish永久代替,Intel也宣布不再维护,号召大家转战Redfish。
CLI:命令行管理接口,通常做服务器批量配置,做监控巡检的时候使用;但是如果通过此协议和Zabbix等外部监控系统集成监控,技术难度高,安全隐患也多,不推荐使用。
Redfish协议:
1、协议产生背景
随着时代发展,IPMI规范的局限性也越发明显。由于IPMI更多的是单点的服务,所以其扩展性(Scale Out)较差,由于此协议在非常早年代制定,这导致其在开始设计的时候受限于当时的现状,对安全性考虑有所欠缺。在爆出安全漏洞后,IPMI2.0增加了增强身份认证(RAKP+、SHA-1等),但其后更多别的漏洞爆出。业界呼唤一种新的,重新设计的新标准,能一劳永逸的解决这些问题,于是Redfish应运而生,IPMI也在2015年公布2.0 v1.1标准后,不再更新,被Redfish永久代替,Intel也宣布不再维护,号召大家转战Redfish。
2、Redfish®协议简介
协议官方原文:DMTF’s Redfish® is a standard designed to deliver simple and secure management for converged, hybrid IT and the Software Defined Data Center (SDDC). Both human readable and machine capable, Redfish leverages common Internet and web services standards to expose information directly to the modern tool chain.
大概意思就是它是一个标准、简单、安全的管理现代化数据中心协议。这个协议不仅机器能懂,管理机器够用;而且方便人去阅读、使用这个协议。
Redfish 规范的第一个版本于2015年8月由分布式管理任务组( Distributed Management Task Force,DMTF )发布,此协议是一个开放的行业标准规范,为可扩展平台硬件提供简单,现代和安全的管理功能。它是一个超媒体API,所以它能够通过一个一致的接口来表示各种实现。它有管理数据中心资源、处理事件、长期任务和发现的机制。基于Redfish统一的管理接口规范普及之后,未来能够有效减少不同服务器硬件管理接口带来的大量适配开发和测试工作。目前,Redfish标准由DMTF组织的SPMF论坛维护。
Redfish是一种基于HTTPs服务的管理标准,利用RESTful接口实现设备管理。每个HTTPs操作都以UTF-8编码的JSON格式(JSON是一种key-value对的数据格式)提交或返回一个资源或结果,就像Web应用程序向浏览器返回HTML一样。该技术具有降低开发复杂性,易于实施、易于使用而且,提供了可扩展性优势,为设计灵活性预留了空间。 Redfish = REST API + 软件定义的服务器(数据模型)。
Redfish 在标准订立之初,就设定了以下目标:
(1)安全
(2)高可扩展管理(Scalable)
(3)人类可读数据界面(Human readable data)
(4)基于现有硬件可实现
DMTF官网上面主流的服务器厂商都在积极响应这个协议,但它毕竟是一个协议和标准,具体的实现、支持程度还非常依赖具体的服务器厂商。目前很多服务器厂商支持,但是支持的颗粒度不够,标准实现也存在非常多的不规范问题。
3、Redfish协议结构: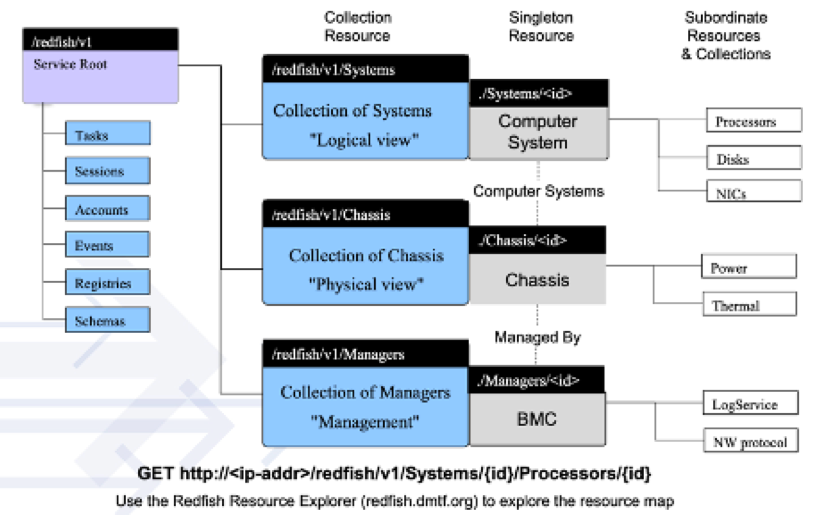
DMTF组织定义的Redfish资源示意图,我们可以看到3大分支:
(1)Systems(系统的逻辑视图)
(2)Chassis(系统的物理视图)
(3)Managers(BMC功能)
其实就是在HTTP-Restful的基础上在进一步强制定义特定的URL路径和参数约定固定服务器对象。
以iDRAC远程管理卡为例,Redfish仅需要一个有登录权限的账号,直接通过浏览器访问iDRAC管理地址对应的URL路径即可(监控的时候推荐使用只读账号)。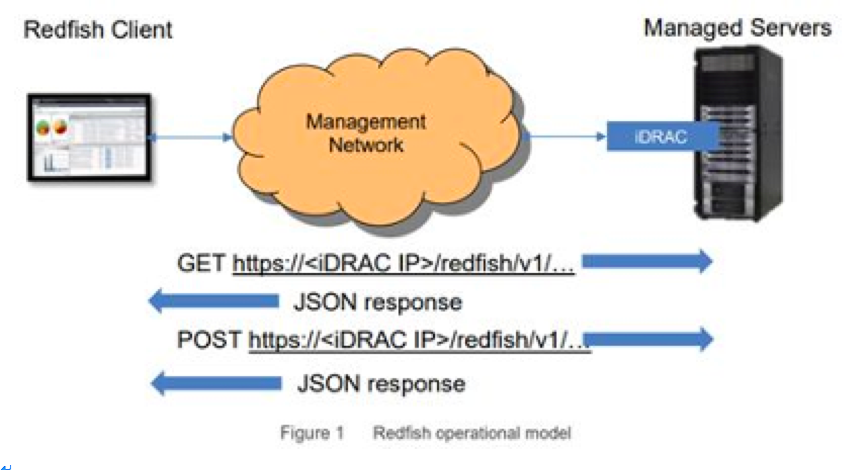
部分常见场景的API示例如下: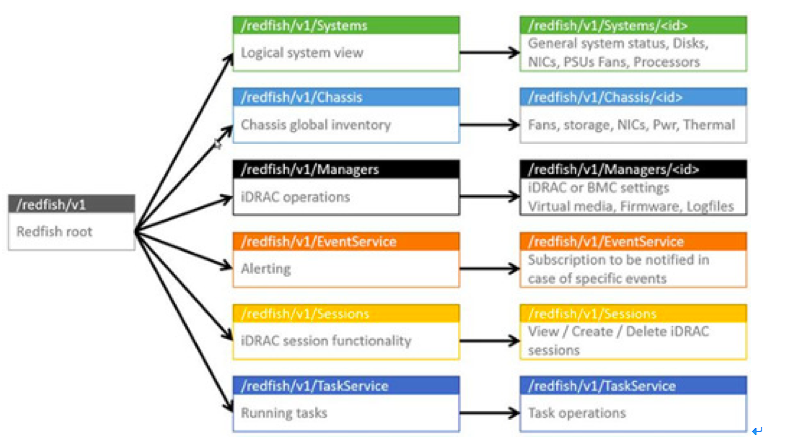
物理服务器运维监控建议
服务器领域有众多的厂商,同一个厂商有不同的型号,即使同一厂商/同一型号,也会因为不同的出厂时间,有不同版本的维码。监控领域的监控指标兼容性、颗粒度问题和其他领域一样,问题严峻,即使在这个细分垂直领域,没有“银弹”,没有完美的监控系统。我们在落地服务器领域监控的时候,需要对不同的厂商、设备旧新程度、监控协议的支持程度、项目落地时间长短、企业愿意投入的人员/经费等多方面进行考量。
做好服务器的运维管理,不论监控还是自动化,需要对服务器基础知识有个较为全面的了解。可以从服务器基础部件入手,按企业现状逐步建设。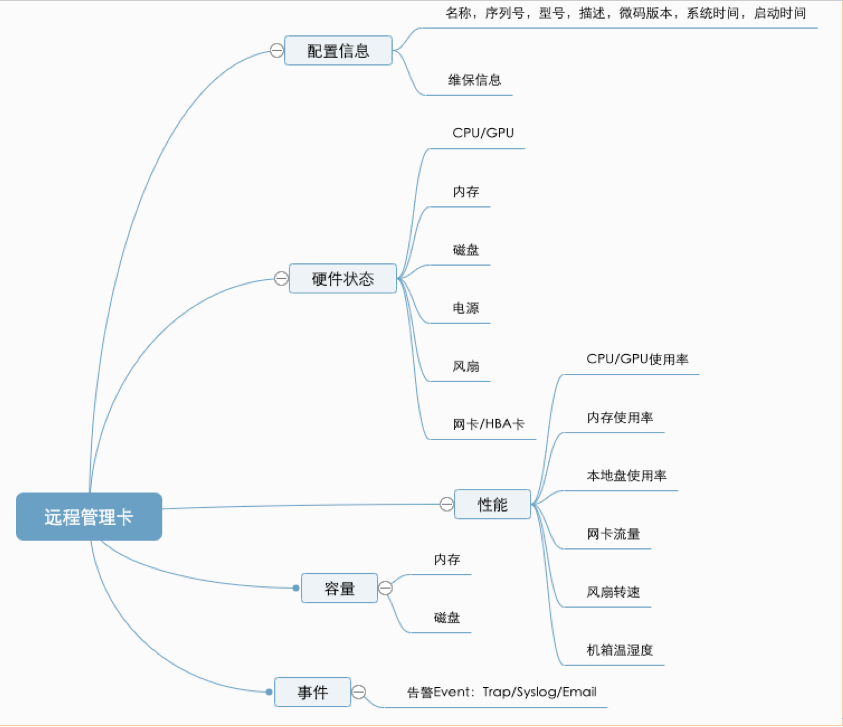
阶段一:如果没有外部独立的监控系统。可以在服务器内部配置邮件告警即可。此方案落地几乎没有任何成本,简单、便捷,可以有效的实现硬件故障告警。此方案有可能因为配置的告警等级较低、告警内容勾选项目较多,导致邮件告警频繁,出现“狼来了”的问题。
阶段二:企业有独立的监控系统。配置SNMP Trap 或者 Syslog,此协议和服务器直接发送邮件告警,内容一致;但是通过此方案,监控系统可以有效的进行告警收敛、屏蔽,告警分析,告警发送,提升告警的认知效率。
阶段三:企业有独立的监控系统,有一定的动手能力。以Zabbix为例,运维人员,可以通过share.zabbix.com下载服务器的SNMP 模版。通过服务器开启SNMP协议,在Zabbix系统创建Host然后挂载模版的方式,就可以快速、免费建立比较专业的服务器监控。
阶段四:企业有独立的监控系统,且动手能力强。可以通过Redfish协议,进行定制开发,实现个性化的运维监控、运维分析。
譬如通常情况下,通过SNMP Get只能拿到硬件的状态,但是对于SSD,我们不仅需要拿到硬件的状态,还需要知道SSD的厂商、擦写比例,拿到这个数值,才能够对数据中心百台以上规模服务器SSD信息进行批量导出。我们以服务器获取磁盘的Redfish URL举例如下: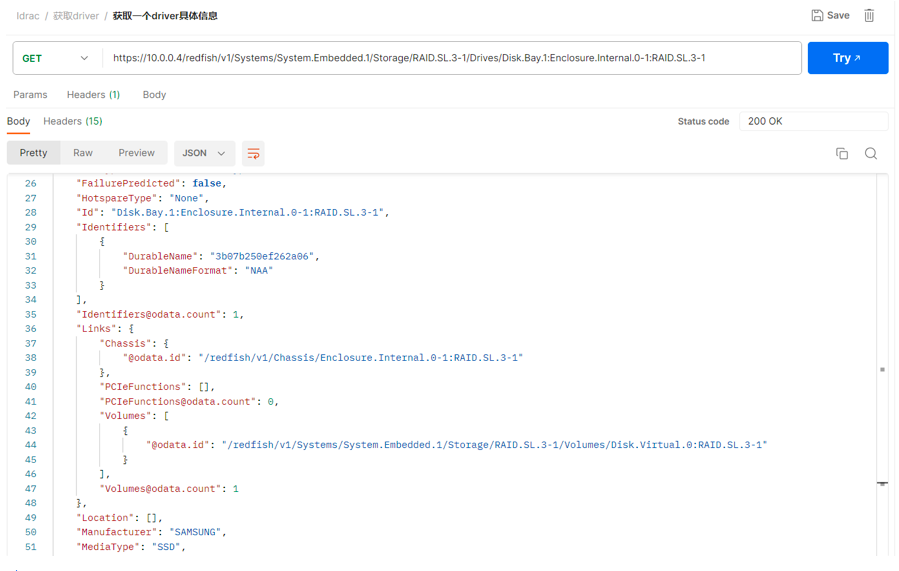
现代化数据中心也讲究“ESG”,也要顺应“碳中和碳达峰”这样的人类宏伟愿景,而不是挂在嘴上和我们一线运维不相关,我们一线技术人员也可以有历史使命感、情怀;那么同样能耗的服务器承载的业务运行密度就是一个非常重要的服务器采购考量指标,尤其是对于中大规模企业,细微的电量消耗节约在数量和时间的累加下必定是一个非常可观的耗电量数字。那么每一台服务器、每个机柜单位的电源功耗就非常有必要把这个指标拿出来,做一个细化的统计分析。我们还是以之前服务器举例,Redfish获取电源功耗指标URL如下: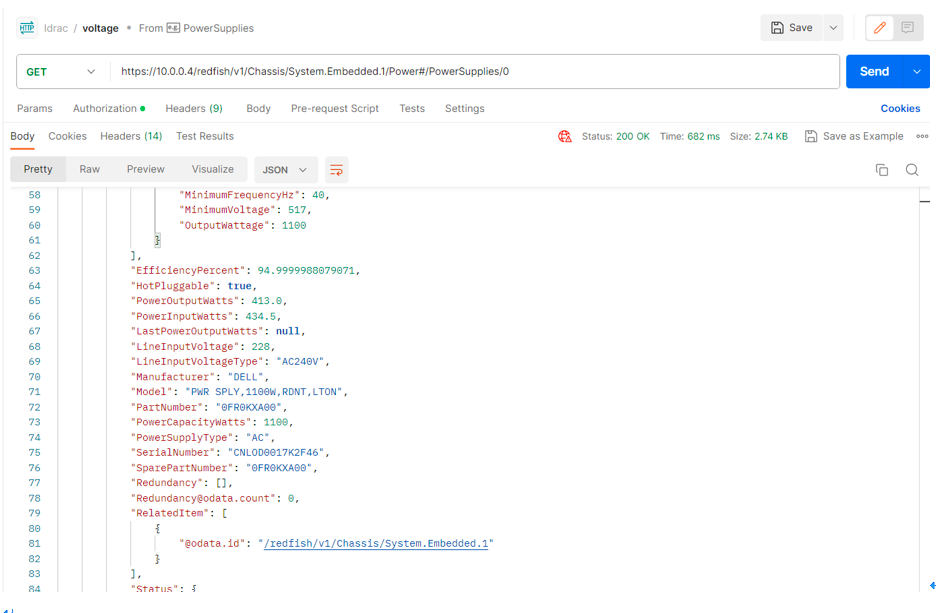
除了我们DIY的方案,那么同一个厂商,针对其自我出厂的多台设备,必然会拥有其原厂专业管理软件方案。但是我们也看到这类原厂方案,往往是收费的,即使不收费,对异构品牌的支持颗粒度比较粗,或者没有。建立一套自主可控的、开放的、向前、向后兼容的运维监控方案是每个企业的理想选择,这里尤其推荐老牌的监控软件Zabbix/ELK;通过Redfish协议主动获取Metrics指标类数据存入Zabbix,将服务器Syslog配置至ELK实现Metrics & Logging双技术栈监控。
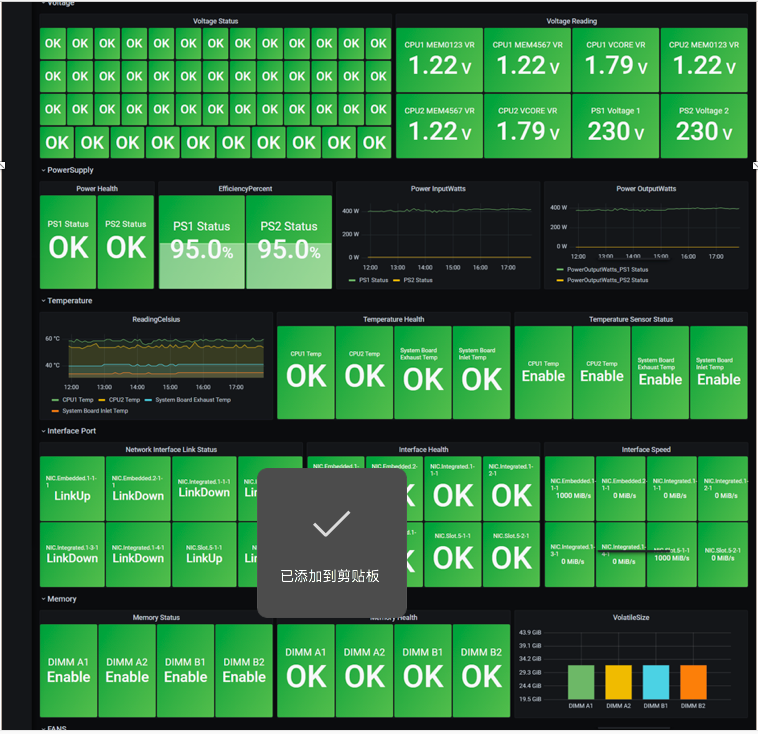
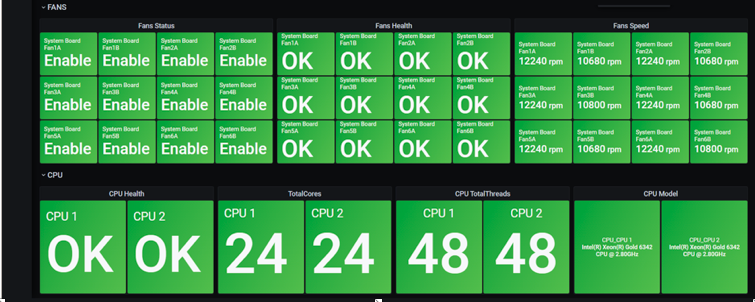
博主团队通过Redfish协议,使用Golang开发的Redfish Exporter,能够同时支持Zabbix & Prometheus,并且能够对不同类型的指标差异化定期抓取;下图是Redfish Exporter获取服务器监控数据存储在Zabbix,并通过Grafana进行展示: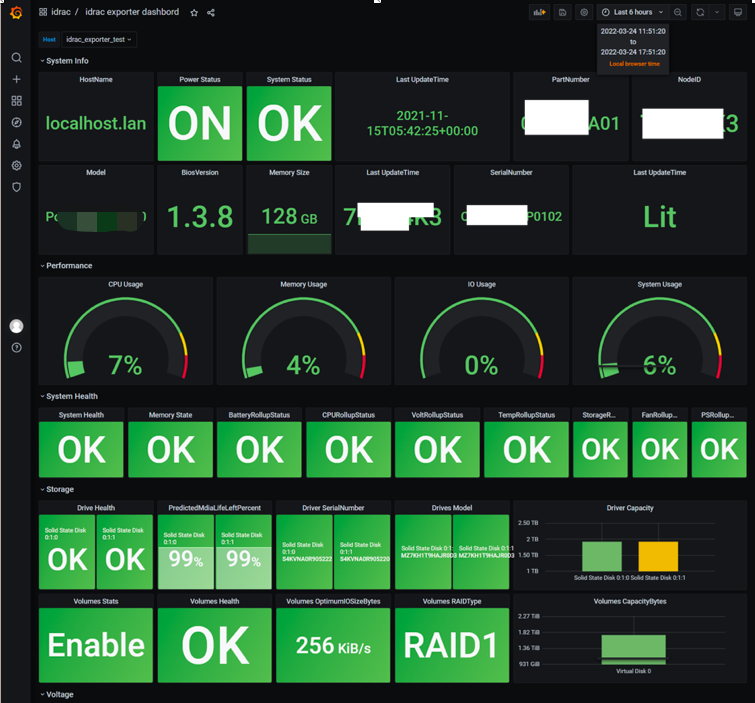
【作者】顾艳军,运维管理领域架构师;通过Zabbix,Prometheus,Grafana,ELK,OTel,Ansible,腾讯蓝鲸等开源工具进行二次开发解决运维领域问题;积极推动CNCF可观测性社区发展。
部分引用:
https://redfish.dmtf.org/
https://www.dmtf.org/standards/redfish
https://www.zabbix.com/integrations
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞12
添加新评论2 条评论
2023-11-14 11:49
2023-11-14 09:54