Statistics In PostgreSQL
本文是类似源码阅读的一篇文章,初步对 PostgreSQL 统计信息模块进行了一些简单的介绍。这里选择 PostgreSQL 而不是其他数据库的原因是在各种论文中看到一些设计估算的比较时,PostgreSQL 总是会在论文中有一个不错的表现。
PG 中收集的统计信息
在 PostgreSQL 中,收集的统计信息分为三类:为一张表收集的统计信息,为一个列收集的统计信息,以及为了一组列收集的统计信息。
为表收集的统计信息
为表收集的统计信息主要是记录了这个表有多少行、有多少页(disk pages)。这两个信息也会为每个索引进行维护,同一个表的索引它的行数虽然一样,但是页数显然会不同。

为单列收集的统计信息
为单列收集的统计信息会大致描述这个列的数据分布以及数据大小。在 PostgreSQL 中,它为每个列收集了如下的信息:
- Histogram:直方图,这个数据结构用来描述数据的分布,在 TiDB 源码阅读 统计信息(上)中也对这个数据结构做了比较详细的描述,有兴趣的同学可以在这篇文章中看到更详细的介绍。
- Most common values: 出现次数最多的一组值。将它们踢出直方图可以减少极端值造成的估算误差。
- Distinct Number: 即这一列一共有多少个不同的值。值得注意的是 PostgreSQL 并没有为直方图的每个 bucket 维护一个 bucket 本身的不同的值。
- NULL values: 有多少行的值为 NULL。因为 NULL 是一个非常特殊的值,所以也会将 NULL 单独拿出来进行维护
- Average value width in bytes: 列平均长度,记录这个值可以用来对 SQL 使用的内存大小进行估算,以及对 IO 开销进行更细致的估算。
- Correlation: 索引和主键(或者说 row id)之间的顺序相关程度。比如一个时间索引总是插入最新一天的数据,那么它和主键的相关顺序就会很高。得到了顺序相关程度之后,我们就可以估算一次索引回表读会造成多少 random IO。并且对于
where index col = xxx order by primary_key limit y这样的查询我们也可以更准确的决策是选择读索引还是选择直接读表。
为多列收集的统计信息
PostgreSQL 没有直接为索引收集统计信息,而是需要通过语句来为某几个列收集统计信息。这里它收集了 Functional Dependency 和 Multivariate N-Distinct Counts。下面我们分别介绍一下两种统计信息。
Functional Dependency
在数据库课程中我们学到过当列 A 取某个值时,列 B 总是会取一个相同的值,则存在列 B 对列 A 的函数依赖。在实际的数据库中,我们很难找到非常严格的函数依赖,因此 PostgreSQL 这里也是记录了函数依赖的程度。在维护这个值之后,PG就可以减少依赖列之间由于独立不相关假设造成的估算误差。
如 where zip_code = … and province = ... 这里邮编和省份显然并不是完全独立的,这时如果我们维护了函数依赖的信息,那么我们就可以在做估算时不用假设邮编和省份是独立不相关的了。
PostgreSQL 中对于给定的 n 列,使用的是如下的简单算法维护 n 列跟前 n-1 列之间的依赖性:
- 基于采样数据计算函数依赖,因为中间会进行多次排序等操作,全量数据会过于耗时;
- 首先枚举所有可能列之间的排列;
- 对每组排列,我们都按照对应的顺序进行排序;
- 排序之后,我们按照前 (n-1) 列进行分组;
- 对于每一组,我们检查最后一列是不是只有一种值存在。如果是,那么 successfulSize += currentGroupSize;
- 最后函数依赖的程度为 successfulSize / totalRows。
Multivariate N-Distinct Counts(MCV)
PostgreSQL 维护的这个信息大致上可以认为是多列上的 Most Common Values。由于比直方图来说结构上更加松散,因此可以用来估计
- (a = 1) and (b = 2)
- (a < 1) and (b >= 2)
- (a is null) or (b is not null)
- (a < 1) or (b >= 2)
等各式各样的谓词的过滤率,而不需要总是在前缀列总是等值条件的情况下才可以估算下一列。
PostgreSQL 计算 MCV的方式也和函数依赖比较相似。比较特殊的是,它并不只是简单的记录了最常出现的那些值的 frequency(出现次数/总行数),还记录了如果这些列之间是完全不相关时的 frequency。这里的逻辑比较复杂,本文不对这里进行详细的解释。
PG 如何使用统计信息对单表进行估算
clauselist_selectivity
PostgreSQL 对统计信息的入口是函数 clauselist_selectivity
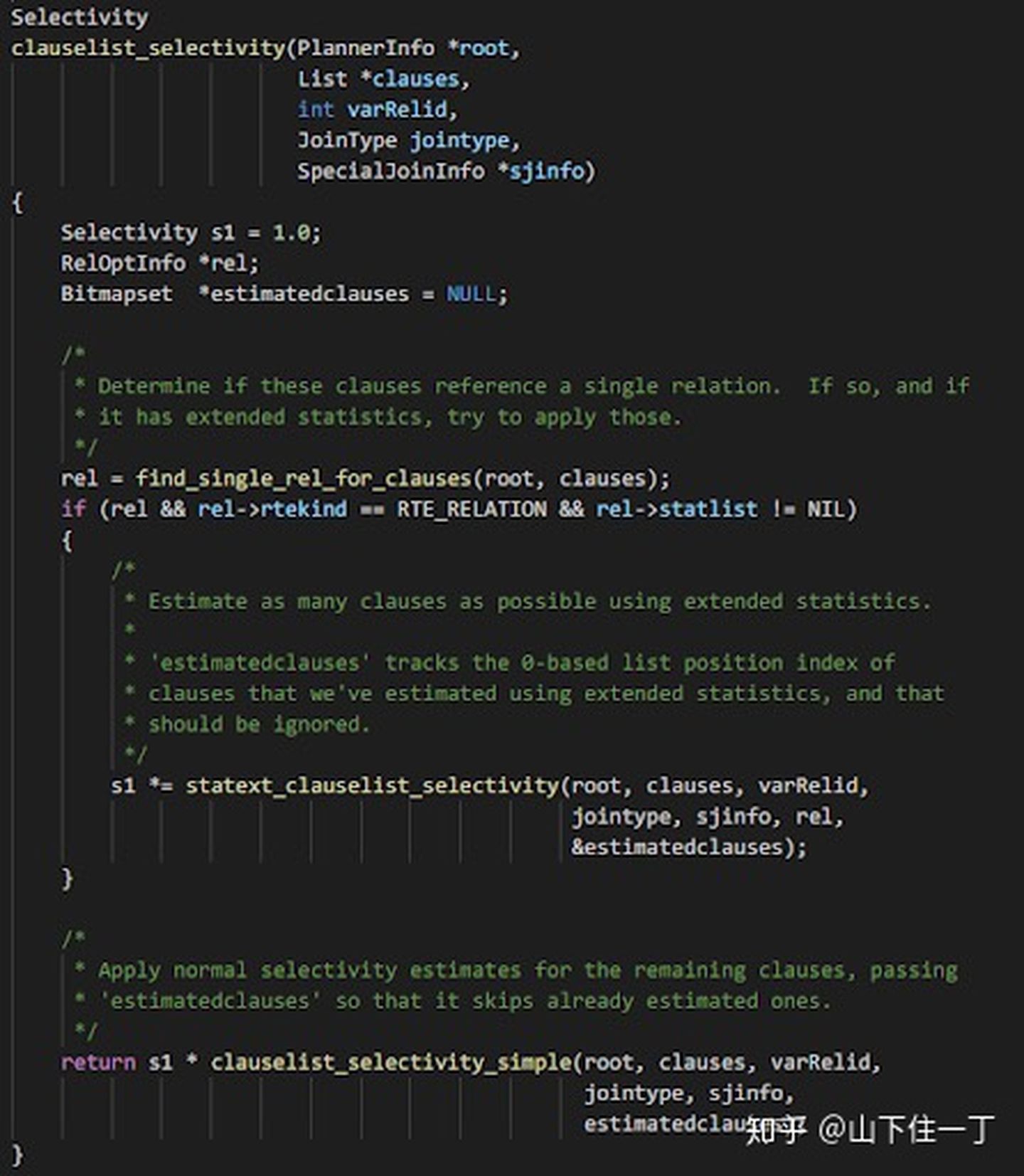
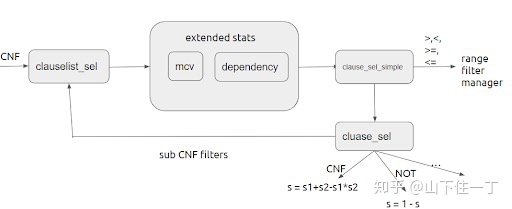
这个函数会接受 CNF 形式的谓词数组(由 AND 连接数组中的各个谓词)。首先它会尝试使用 extended statistics (即多列统计信息)对谓词进行估算,然后对剩余的谓词使用单列统计信息进行估算,两个入口分别是 statext_clauselist_selectivity 和 clauselist_selectivity_simple。
statext_clauselist_selectivity
在 statext_clauselist_selectivity 中首先会使用 MCV 进行估算,这里 PostgreSQL 只会使用一个它认为最优的 MCV 进行估算,而不是使用多个 MCV 再根据独立不相关假设进行估算。在判断哪个 MCV 最优时,它是使用了一个简单的贪心算法,即看这个 MCV 覆盖了多少谓词。有关 MCV 的逻辑,在函数 statext_mcv_clauselist_selectivity中。
dependencies_clauselist_selectivity
在使用了 MCV 处理后,它会开始使用函数依赖对谓词进行进一步的过滤,对于两列的函数依赖 P(a, b) = P(a) (f + (1-f) P(b)) 这里 f 即是 (a, b) 之间的函数依赖程度。对于多列的函数依赖,通过 P(a, b, c) = P(a, b) (f + (1-f) P(c)) 来归化成 P(a, b) 与 P(c) 之间的计算。这部分逻辑在函数 dependencies_clauselist_selectivity 中。
在使用完两种多列统计信息后,便是使用剩余的单列统计信息在基于各列/谓词之间独立不相关假设进行的估算。
clauselist_selectivity_simple
函数 clauselist_selectivity_simple 是一个简单的 wrapper,主要是对单列上的范围谓词做了处理,防止独立假设造成的误差。即对于 a > 100 and a < 1000 它会为 a 维护一个区间信息,当所有谓词都处理完之后,再根据区间信息对这个列进行估算。对于不需要维护区间信息的其他谓词,它会直接使用函数 clause_selectivity 进行估算。
clause_selectivity
在 clause_selectivity 中,则是使用各种假设进行的最粗暴的估算:
- 对于一个 DNF(由 OR 连接各个谓词),使用 s = s1 + s2 - s1*s2 进行估算
- 对于 NOT 表达式,使用 s = 1 - s1 进行估算
- 对于一个 CNF,跳回上层使用 clauselist_selectivity 进行估算
- ….
可以看到这里就是使用独立分布的假设进行估算了。
PG stats 总结
下图表示 PG 整个估算过程:
与 TiDB 的异同
TiDB 目前缺少 PostgreSQL 中拥有的多列统计信息(MCV 和 函数依赖),但是有多列直方图。PostgreSQL 当前并没有为多列维护直方图。PostgreSQL 当前的做法将统计信息和索引进行了解耦这样就可以直接对并不是索引的列组合建立需要的统计信息,某种程度也方便统计信息的维护和管理。
TiDB 目前并没有使用 s = s1 + s2 - s1*s2 来为 DNF 进行估算,而是简单的是用一个 magic number(0.8) 来表示 DNF 的选择率。
其他的流程上,TiDB 和 PostgreSQL 大体上是相同的。
PG 如何使用统计信息对多表进行估算
这里我们主要介绍一下 PostgreSQL 如何对 inner join 进行估算。
PostgreSQL 主要是使用 Most Common Values 对 join 的结果集进行估算。它首先计算如下几部分:
- match_prod_freq:左右表只使用 MCV 得到的选择率,即两边 MCV 中都出现的值的选择率之和;
- match_freq1:MCV 1 中多少值在 MCV 2 中被匹配到了;
- match_freq2:同理;
- unmatch_freq1:MCV 1 中有多少值在 MCV 2 中没有被匹配到;
- unmatch_freq2:同理;
- other_freq1:表 1 中有多少值是没在 MCV 中出现的。
那么完整的选择率便是,MCV 之间计算得到的选择率 + 没有在 MCV 1 中出现的值和 MCV 2 进行匹配的选择率 + 没有在 MCV 2 中出现的值和 MCV 1 进行匹配的选择率 + 没有在 MCV 1 中出现的值和没有在 MCV 2 中出现的值进行匹配的选择率:
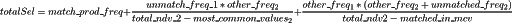
上述式子只有基于表 1 的视角进行计算的结果,再镜像得到一份表 2 视角的选择率便是完整的计算结果。
上述逻辑在函数 eqjoinsel_inner 可以找到。
比较奇怪的是,这里似乎并没有为 join key 是多列的情况进行处理(t1 join t2 where t1.a = t2.a and t1.b=t2.b),正常来说如果完全使用独立不相关假设,估算容易出现较大的偏差,可能这里有一些逻辑被我忽视了,在之后还会考虑使用实际数据对 PostgreSQL 进行 debug 来进一步理解它的估算逻辑。
总结
本文对 PostgreSQL 所维护的统计信息以及进行的估算的框架通过跟随代码进行了简单的介绍,还没有触及其更细节的估算逻辑,之后还会继续对 PostgreSQL 的估算框架进行更细致的考察,看有没有值得借鉴的地方。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 1
添加新评论0 条评论