城商行核心存储系统升级改造和统一存储监控实现实践分享
作者简介: 李军华,攀枝花市商业银行,系统网络中心主任,主要负责操作系统管理、数据库管理、存储管理,全行容灾体系建设。擅长领域: Oracle 数据库、操作系统、双活架构、云计算
摘要:本文主要介绍了中小银行存储升级和改造实践,主要分为架构选型、迁移实施、集中监控探讨三大块。架构选型从稳定方面考虑,结合我行实际情况,选择EMC高端存储;迁移实施从ORACLE数据库迁移、GPFS集群文件系统迁移、VMware虚拟机迁移、物理设备迁移四个方面做了介绍;集中监控主要是基于Zabbix+Grafana开源软件构建分布式监控平台,列举了SAN网络、数据库统一监控及展示以及未来统一监控平台建设思路。
一、项目背景
近年来双模 IT 已经从预测变为了现实,以大数据、人工智能为代表的新型技术的涌现,给金融科技注入新鲜活力的,吸引了大部分行业同仁的目光。传统金融 IT 架构以稳态为主,随着利率市场化的经济政策成为国内金融环境的基调, FinTech 时代已经伴随着 IT 技术的飞速发展骤然而来,各类新技术在特定业务场景下的应用不断推陈出新,必将大幅提升金融服务品质,并助力金融行业实现新的利润增长点,真正发挥“科技引领”的作用。但是,敏态系统是以数据为基本原料的,敏态业务的发展,带来了更多的数据调用和交互,银行内最为关键、调用最为频繁的数据,还是核心业务系统的数据,承载核心系统的传统稳态 IT ,也面临快速增长的数据访问压力。保障核心系统的稳健,不仅关系到传统业务的顺利开展、关系到监管要求的顺利达标,更是为新兴的敏态系统及时获取数据提供基础架构的支撑。
根据人民银行《关于进一步加强和完善地方性银行业金融机构灾难备份体系建设的指导意见》中 “最小必须业务集系统”同城应用级灾备规范的要求,我行多年前就构建了同城双活异地容灾的“两地三中心”容灾架构。同城两个数据中心分别在我行攀枝花总部机房和中国联通公司攀枝花分公司仁和机房,其中,我行攀枝花总部机房为主生产中心,联通机房作为我行同城应急灾备数据中心。同城两个数据中心,通过波分实现两个数据中心网络互通,通过 EMC VPLEX VS2 存储虚拟化双活网关实现了生产中心多套存储设备和同城灾备中心多套存储设备之间的数据双活。同城两份数据实时同步,故障时自动切换,实现了物理故障的 RPO=0 和 RTO ≈ 0 。通过 EMC RecoverPoint 实现生产中心核心数据的本地连续数据保护(为减少对生产系统影响,采用异步拆分策略,逻辑错误 RPO ≈ 0 ),再通过 EMC RecoverPoint 的 CRR 异地复制功能实现与异地灾备中心数据同步( RPO<10 分钟)。
设备更新前,我行存储设备多为中端存储,主要包括 EMC VNX 、 Unit 系列存储和 VPLEX 存储虚拟化双活网关。其中 VNX 系列存储和 VPLEX 均已上线运行 6 年以上,数据处理能力已经出现明显瓶颈,主要表现在 CPU 利用率长期处于较高水平,数据访问延迟明显增大。同时,电子设备进入生命周期尾声后,硬件故障特别是硬盘的故障率开始上升,对业务的健康稳定运行构成了威胁。
本项目目标: 1 、基于 VMAX250F 、 VPLEX VS6 部署双活存储; 2 、迁移现有中端存储数据至 VMAX250F ; 3 、构建我行开源监控平台,实现存储等资源的集中监控。
二、数据中心核心存储架构选型
数据中心核心存储阵列承载着行里最关键的数据,是整个数据中心的命脉。如果设计数据中心核心存储架构有五条经验,那么,第一是稳定、第二是稳定、第三还是稳定。这里稳定重复三遍,并不是重要的事情说三次那么简单,而是我们认为确实至少有三个方面的保障才能保证稳定。
第一个稳定,是架构稳定。这个架构,有两个数据中心的设计问题,保证两份数据实施同步,保证故障自动切换。但是最好的情况是设备稳定,不要去切换。也就是单台设备,最好是也是稳定可靠的。通过多年使用中端存储的经验,我们认为最考验单台设备稳定可靠的时候,就是设备微码升级的时候。目前,中端存储微码升级基本都是控制器离线升级,也就是每次升级的时候有一段时间是单控制器运行的,此时所有访问都在一个控制器,虽然每次都是在业务量最小的时候升级,但是心里的忐忑总是难免的。随着 7x24 小时业务增多,我们能够选择的忐忑时间越来越少了。与之比较,业界经典的高端存储,是控制器在线升级,可以保证微码升级过程中的设备冗余性和性能波动,最大限度减少风险。
第二个稳定,是经过广泛验证的稳定。现在描述设备稳定性的术语有很多,有一些厂家说设备可用性,有一些厂家说数据可用性。从实际角度来说,没有存储设备是 100% 可用的,因为存储设备本身就是一个软件和硬件结合的复杂产品,如果哪家说自己的产品没有 BUG ,那一定是假话。有 BUG 其实不可怕,可怕的是不知道 BUG 的存在,不知道如何防范。所以,我们认为要选则同行业案例多的产品,因为使用广泛,盯着这个产品的人就多,有问题被发现的概率就高很多,未知 BUG 就会少很多。而且同行业的业务类似,同行发现的问题对我行会有很好的参照意义。已知的、有规避办法的问题,就不是问题。
第三个稳定,是服务要稳定。产品和方案落地靠的是人,看上去很好很美的方案因为服务不到位落到地上一塌糊涂的事情在 IT 行业有非常多了。要保证服务稳定,一定要选择好服务的人,这包括了服务人员的技术水平、做事风格和同行业口碑。经过多年的了解,我行对主要设备供应商的工程师技术水平有了基本的评估,会要求在我行认可的范围内选择工程师进行服务。
除了稳定性之外,当然要考虑性能。好在目前全闪存阵列基本已经普及, IOPS 基本都是几十万甚至上百万,延迟也都能够控制到 1ms 左右。
在闪存阵列领域,最常见的另外一个话题是数据精简技术,这里边涉及到数据精简配置和数据压缩重删。坦率来说,数据精简配置我们基本是遵循尽量不用的原则,原因也比较简单,应用的数据增量有较大的不确定性,一旦给应用承诺一个很大的空间,应用开发人员突然增加大量数据导致后台容量爆仓,会引起整个存储的保护反应,写入被拒绝,造成业务中断。数据重删和压缩目前有硬件和软件两种实现方式,两种实现方式应该说各有优劣。在核心存储领域,我们更倾向于采用硬件办法实现的重删和压缩,因为核心存储更强调稳定性和性能,软件方式在非核心业务采用,也有不错效果。
基于以上考虑,我行最终建设采用了 DELLEMC 的技术方案。具体方案为 2 套双引擎( 4 控制器)的 VPLEX VS6 存虚拟化网关和 2 套 VMAX250F 高端全闪存阵列。通过将 VPLEX 从 VS2 单引擎(双控制器)升级到 VS6 双引擎( 4 控制器),提升了虚拟化双活网关的可靠性和性能,最大网关的 CPU 利用率从 90% 多降低到了 30% 以下。通过将 VNX 替换为 VMAX250F 实现了底层存储阵列的升级,每台 VMAX250F 配置 1T 高速缓存, 2 块硬件压缩卡,开启压缩时存储底层延迟低于 1ms 。从 VPLEX 端看到的对主机端口的响应来看,读 IO 的延迟在 1ms 以内,写 IO 因为需要在两个数据中心实现双写基本在 2ms 左右。从日常运维中风险最大的微码升级来看, VPLEX 微码升级以控制器为单位进行,因为有四个控制器,整体最高性能波动从 50% 降低为 25% ,实际测试中因为不会达到设备性能的最大值,业务层面不会有感知。 VMAX 升级为在线进行,不需要停止控制器的运行,因此核心在微码升级场景新系统较原有系统有了极大提升。同时, VPLEX 和 VMAX 的方案可以与我行原有的 RecoverPoint 完美集成,不需要改动本地 CDP 和异地灾备系统,节省了大量异地灾备重构的时间和资金成本。
三、数据中心存储数据迁移
本次升级生产中心、同城灾备存储规划:
1 、生产中心和同城灾备中心分别部署一台 DELLEMC VMAX250F 高端全闪存储阵列;
2 、生产中心和同城灾备中心分别部署一台 DELLEMC VPLEX V6 存储虚拟化网关,实现多台存储阵列的虚拟化和存储双活。
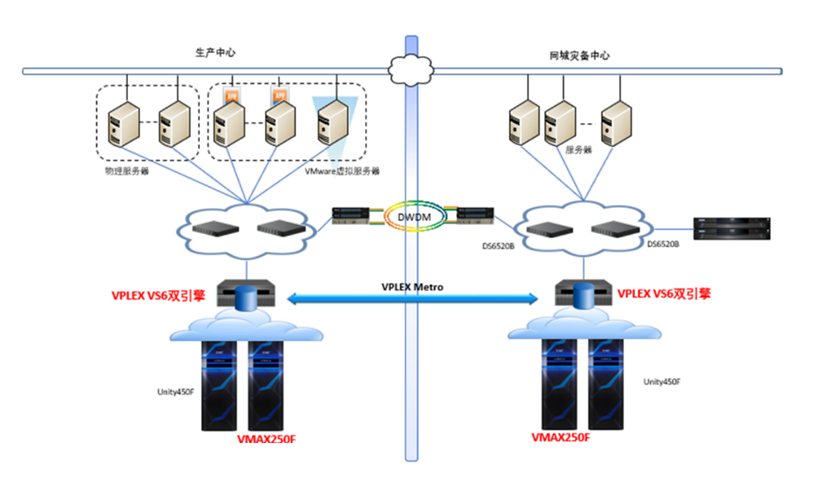
图 1. 生产中心与同城灾备存储架构图
新购设备到货并完成初始化和简单配置后,我行计划将已经超长服役的 EMC VNX 系列存储和 VPLEX 下线淘汰, EMC VNX 系列存储的数据全部迁移到 VMAX250F ,涉及的系统包含核心系统、现代支付系统、网银、电子银行、综合前置、短信银行等重要业务系统,主机环境包括了 VMware 环境、 AIX 环境、 Oracle 数据库和 GPFS 文件系统,同期还需要对 POWERPATH 多路径软件升级、部分数据分布进行调优。
DELLEMC 原厂可以提供 VPLEX VS2 到 VPLEX VS6 的在线升级,然后通过 VPLEX 的 Local 方式进行数据迁移,但是此过程是以 LUN 为单位进行的,很难对原有 LUN 分布进行优化,同时 VS2 升级到 VS6 的过程时间较长。因此,我行经过慎重考虑,选择更加灵活的蚂蚁搬家式数据迁移。根据环境应用环境不同,从数据库、文件系统和 VMware 虚拟机层面进行迁移。以下迁移均选择夜间、业务量小的时候对系统系统进行,详细迁移方法如下:
1、VMware 虚拟机迁移:登陆到 vCenter ,识别 VPLEX VS6 分配过来的 LUN ,创建 DataStore ,逐台扫描识别存储;业务空闲时间逐个迁移业务系统虚拟机,采用 Storage vMotion 将数据迁移到新的 DataStore 上。此种迁移方式,迁移过程中虚拟机不关机、业务不中断,保障了业务系统的高可用。
2、ORACLE RAC 数据库迁移,通过 ASM 磁盘组方式进行迁移,迁移过程中,业务系统数据库不停库,保障了数据库的高可用。迁移步骤如下:
1)SSH 登录每个数据库节点,扫描识别 VPLEX VS6 分配的磁盘,检查两台主机 LUN 的 WWID 一致,确保一致后将块设备转换为字符设备;
2)grid 用户的登录一个节点, sqlplus / as sysasm 登录 asm 实例;使用 alter diskgroup OCRVDISK … 添加删除磁盘,并重新 rebalance 数据 ; 迁移过程中查询 v$asm_operation 视图查看迁移进度。
3、GPFS 集群文件系统迁移,通过 GPFS 集群软件在线增减磁盘,迁移过程中, GPFS 文件系统对业务无感知,保障业务系统持续稳定。操作步骤如下:
1)SSH 登录登录主机,扫描识别 VPLEX VS6 分配的磁盘,配置 cfg 文件,通过 mmcrnsd 创建 nsd 磁盘。
2)使用 mmadddisk 在 GPFS 文件系统中添加磁盘,添加完后 mmlsdisk 确认磁盘状态,确认无误后通过 mmdeldisk 删除 EMC VNX 存储对应磁盘。
4、Power 小型机、非虚拟化物理服务器更新需要有停机窗口,主要是对多路径软件进行升级,同步将原有数据卷映射给 VPLEX VS6 做虚拟化,通过 VPLEX 的 Local 镜像功能,实现数据从原有设备到新购 VMAX250F 的迁移。因为虚拟化的时间比较块就可以实现,数据迁移主要在底层进行,大部分的时间是多路径软件的大版本升级和重启时间。实际停机窗口在 1 小时左右。此次迁移完成后,拟对部分非集群部署的服务器通过中间件集群、操作系统集群、数据库集群等集群技术进行集群改造,从而提高系统可用性。
四、分布式开源集中监控的初步探索
我行之前的监控体系较为分散,从设备来说每种品牌的服务器、存储和 SAN 网络都有各自品牌的监控软件,从应用来说操作系统和数据库也是分开监控的,这个日常运维带来了很大不便。为实现存储设备、存储网络、服务器、数据库等运行状况集中监控并且能在出现问题时及时解决,我行在本次设备更换中也对分布式开源集中监控进行了初步探索,经过认真地调研选择 Zabbix 和 Grafana 构建我行开源监控集中平台。
Zabbix 是国外银行 IT 人员在运维中积累的脚本基础上发展来的的开源软件,是基于 web 界面的企业级开源监控软件,提供分布式系统监控与网络监视功能。具备主机的性能监控,网络设备性能监控,数据库性能监控,多种告警方式,详细报表、图表的绘制等功能。监测对象可以是 Linux 或 Windows 服务器,也可以是路由器、交换机等网络设备,通过 SNMP 、 zabbix Agent 、 PING 、端口监视等方法提供对远程网络服务器等监控、数据收集等功能。
Grafana 是 Graphite 和 InfluxDB 仪表盘和图形编辑器。 Grafana 是开源的,功能齐全的度量仪表盘和图形编辑器,支持 Graphite , InfluxDB 和 OpenTSDB ,能够非常美观的展示和分析监控数据的工具,支持手机数据展示、告警等功能。
1 、 Zabbix 监控架构:
Zabbix 根据系统架构、网络环境、监控规模等外界因素分为三种架构: server-client (直接连接)、 master-node-client ( Node 架构)、 server-proxy-client ( proxy 架构)。结合我行容灾系统架构,设备数量不多的具体情况,选择 server-proxy-client 架构部署 Zabbix 开源监控平台,在生产中心部署集中监控中心、 DB 采集引擎,以及 Grafana ;在生产中心、同城灾备、异地灾备分别部署分布式代理对操作系统、数据库、应用系统、存储、网络等进行采集和推送。架构图如下:
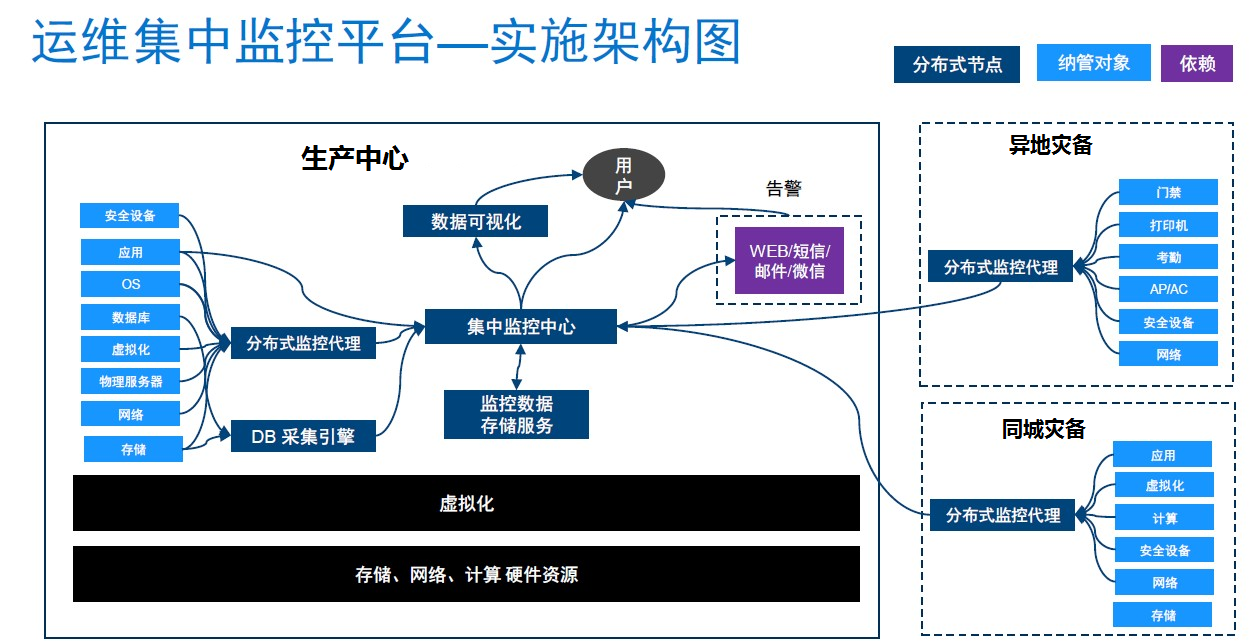
图 2. 运维集中监控平台实施架构图
2 、存储、 SAN 交换机监控实现
在整体监控架构中,我行采用 Zabbix 做监控数据的采集、管理和加工,采用 Grafana 实现数据的展示。 Zabbix 的监控信息采集本身可以通过多种方式实现,比较常见的有 SNMP 、 Zabbix Agent 、 PING 、端口监视等方法,每种方式都有自己的优点和不足。经过研究和尝试,我们发现 SNMP 、 RestApi 和 Zabbix Agent 是目前最常用也是比较好用的方式。
对于服务器和数据库,采用 Zabbix Agent 方式是比较好的监控方式。通过在服务器安装部署 Zabbix agent ,定期收集各项数据。通过内部的讨论以及与外部专家的研讨,我们定义的 Zabbix Server 配置模板对数据库状态、表空间、读写 IO ,操作系统文件系统、内存、 CPU 、网口流量等进行监控和展示。
Grafana 展示监控界面如下:
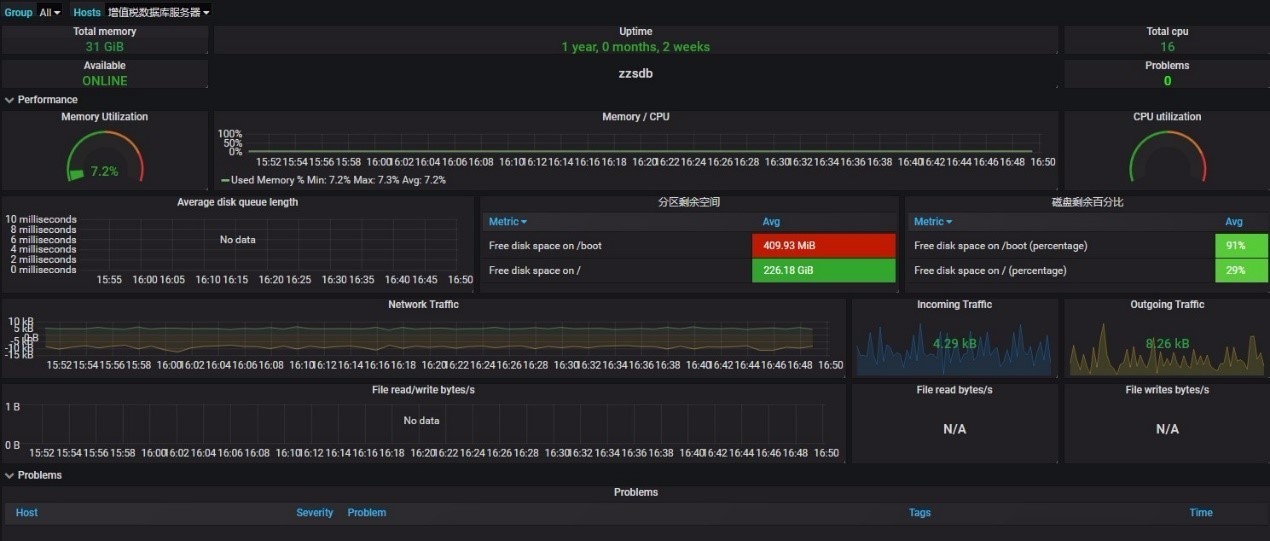
图 3.Grafana 展示监控界面 1
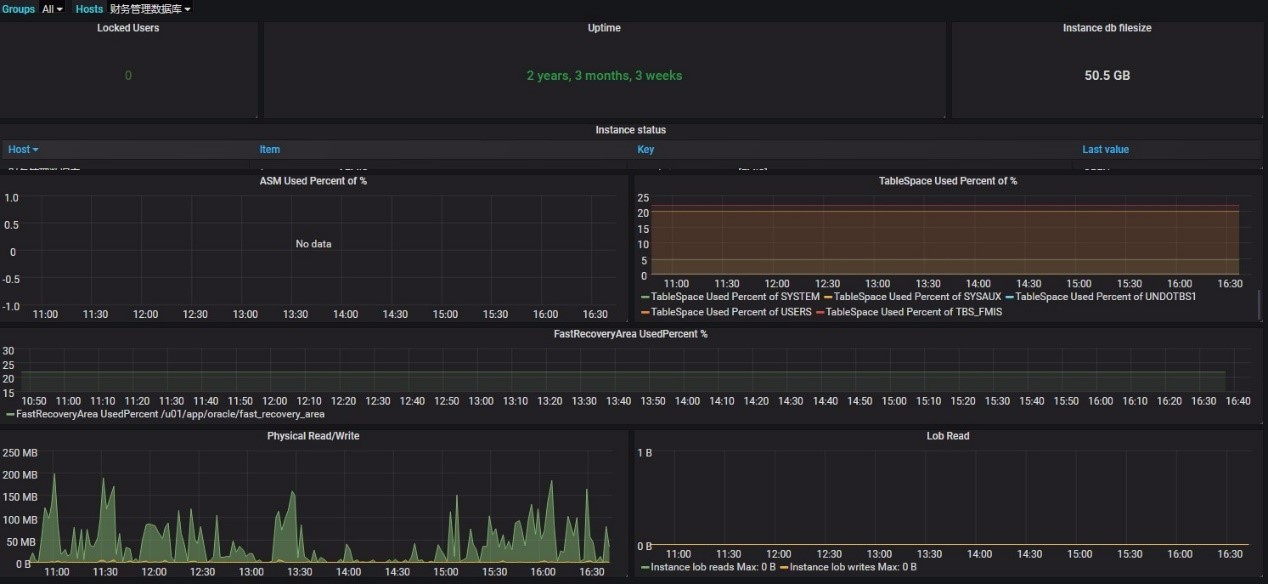
图 4.Grafana 展示监控界面 2
通过 SNMP 和 RestAPI 结合的方式,实现了存储和 SAN 存储网络的监控。 SAN 交换机的监控比较简单,通过 SNMP 协议就可以实现监控,通过配置 SNMP 采集设备信息, snmpwalk 收集、分析交换机运行信息, Zabbix 平台中创建模板并定义自动发现规则、定义监控项,对 SAN 交换机运行状态、温度信息、设备信息、端口状态、出入口流程进行展示和监控。存储阵列的监控相对比较复杂, SNMP 能够获取的信息非常有限,因此采用 SNMP 和 RestAPI 相结合的方式,通过配置 SNMP 采集存储设备信息, snmpwalk 收集并分析存储设备信息,对于我行关心需要监控的存储信息包括存储设备运行状态、容量空间、 LUN 信息、 Pool 信息,由 DELLEMC 提供存储监控模板及自定义发现规则、定义监控项进行监控; Grafana 展示监控界面如下:
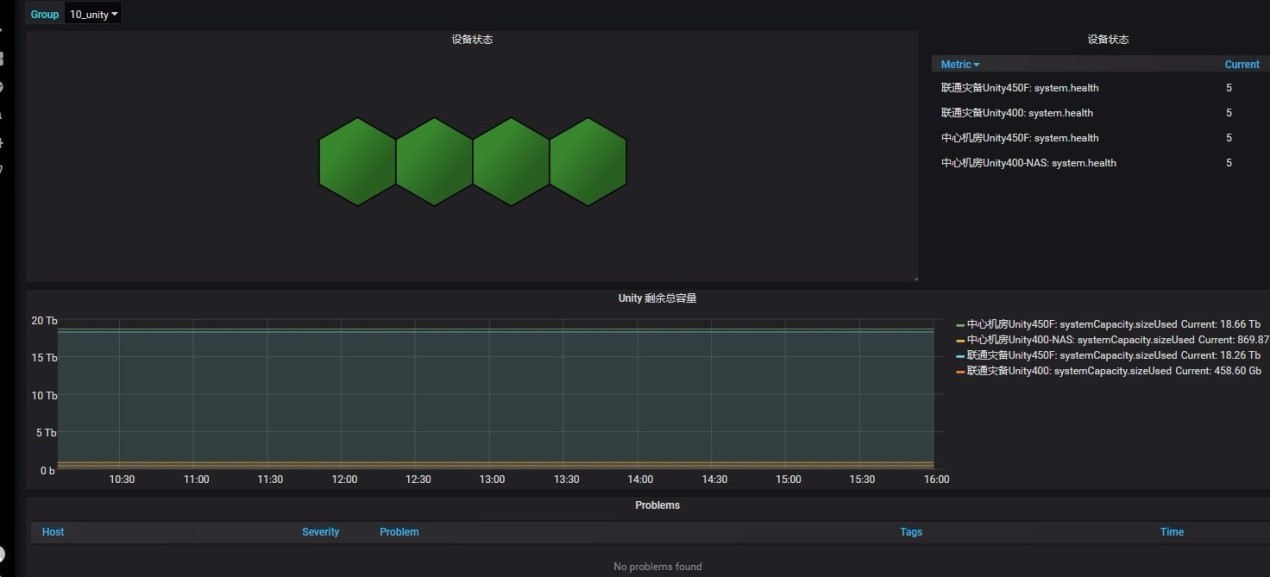
图 5.Grafana 展示监控界面 3
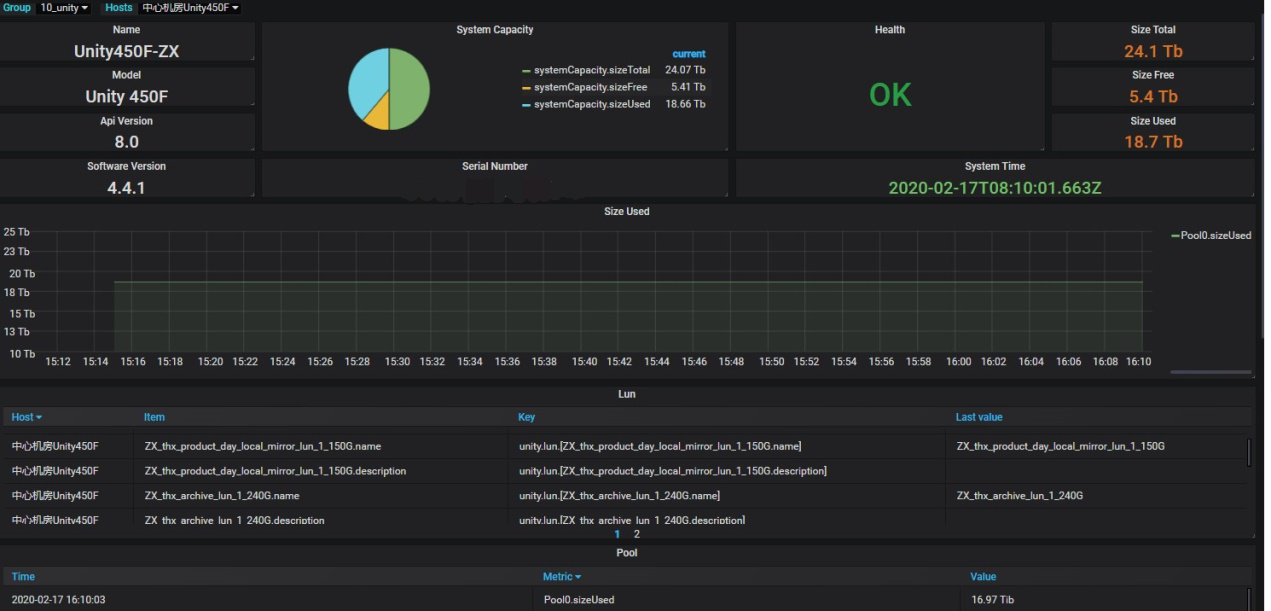
图 6.Grafana 展示监控界面 4
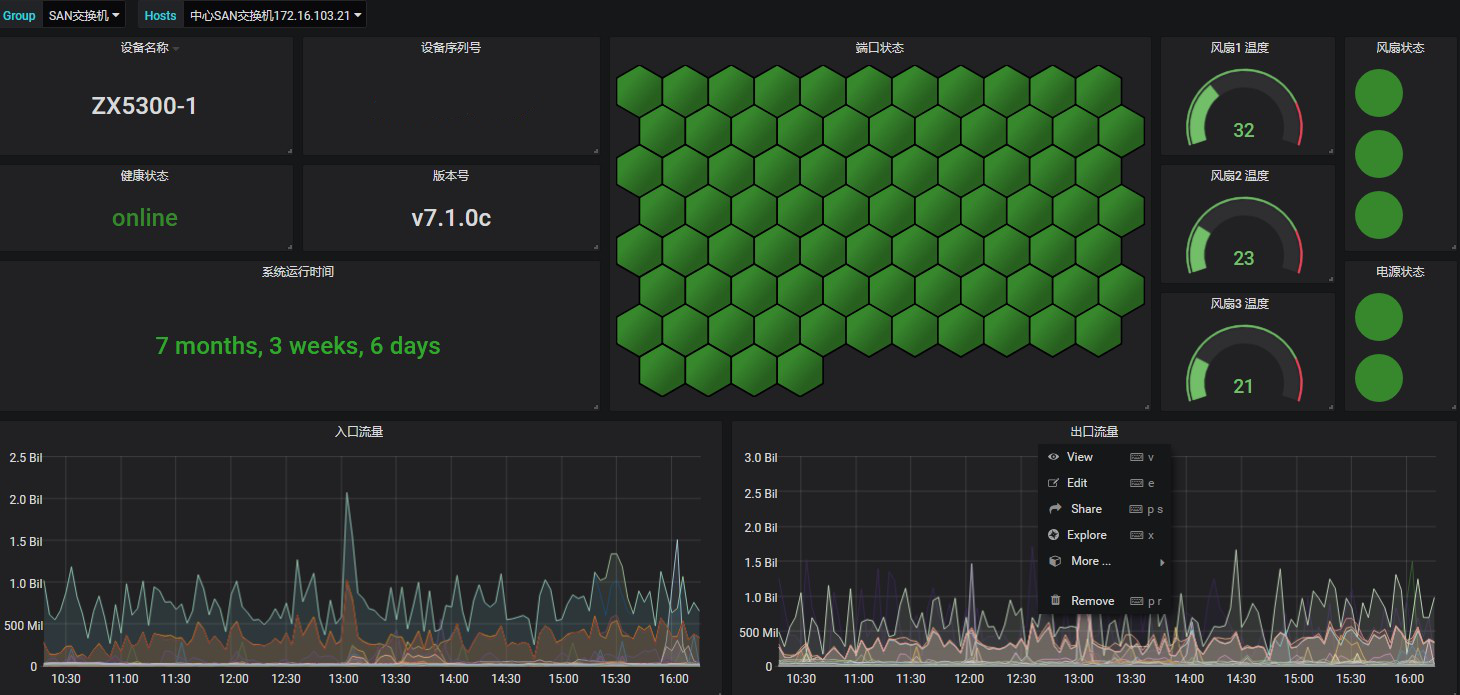
图 7.Grafana 展示监控界面 5
Zabbix+Grafana 开源监控平台实现了物理服务器、存储设备、操作系统、数据库、网络设备监控的全覆盖。监控平台直观的展示 IT 资源运行状况,告警信息通过微信、短信平台推送,极大提升了运维效率,未来我行将不断完善此平台,以此为基础打造全行集中监控平台。
五、总结
通过本次改造,不仅对设备进行了更新了,消除了原有的性能和可靠性隐患,能够满足未来我行三到五年的业务发展需要,而且探索了分布式开源集中监控平台,通过集中监控在发现问题和解决问题的效率大大提升。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞11
添加新评论6 条评论
2022-07-23 22:09
2020-03-19 10:06
2020-03-18 16:38
2020-03-18 16:00
2020-03-16 10:47
2020-03-12 15:08