
DB2 pureScale 性能监控和调优
DB2 pureScale 是同时兼备高扩展性和高可用性的数据库集群,同时对于应用是透明的。无论是连接到数据库的哪个成员,应用都无需任何更改,对于应用来说,可以认为它仅仅是连接到单个的数据库。DB2 pureScale 工作负载均衡特性帮助数据库更好的充分利用资源。但是毕竟 DB2 pureScale 是一个数据库集群,运用的技术远比单机版数据库复杂。同时新技术的运用对性能带来什么样的影响,以及如何去监控和应对,都是用户在使用 DB2 pureScale 集群后亟需解决的问题。
首先从 DB2 pureScale 集群的架构出发,下面这张图显示了 DB2 pureScale 集群所使用到的产品和比较重要的技术。DB2 pureScale 使用了 IBM 的 TSA(Tivoli System Automation)集群软件整合所有资源,并自动化所有资源的行为,从而搭建整套的集群环境。
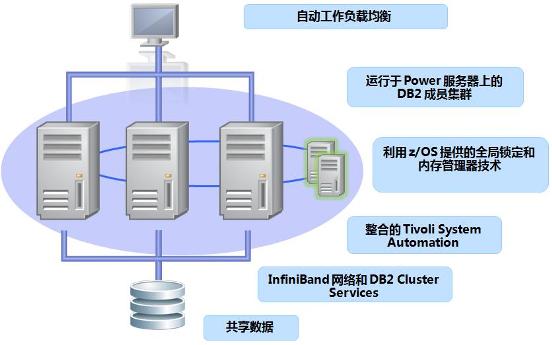
图 1. DB2 pureScale 集群的架构
DB2 pureScale 集群可以有多个成员(member)组成,每个成员都可以看成是一个能够提供完全数据库服务的节点。任何应用只需要连接到一个成员即为连接到整个数据库,所以在 DB2 pureScale 集群里面有多少成员对于应用是透明的。
DB2 pureScale 集群的自动工作负载均衡能将工作负载均衡到多个数据库成员上,从而充分利用成员的硬件资源,满足高性能的需求。DB2 pureScale 集群的高扩展性能够帮助用户通过增加成员来满足更高性能的需求。
DB2 pureScale 集群 CF在 DB2 pureScale 集群里面,成员之间的协作是由 CF(Cluster Caching Facility)帮助完成的。在数据库成员和 CF 之间有高速网络相连(Infiniband 网络),成员和 CF 之间通过 RDMA(远程内存直接访问)的方式交互数据,这种技术跳过了网络协议所需要的交互,是非常快的。CF 主要管理整个数据库集群的通信,控制全局锁和全局缓冲池等。可以说 CF 就是 DB2 pureScale 集群的大脑,它对于性能会有很大的影响。
DB2 pureScale 集群网络在 DB2 pureScale 集群里面,成员和 CF 需要两种高速网络互联:Infiniband 网络和高速以太网。如果网络出现问题或者拥挤,会对性能有影响。
DB2 pureScale 集群共享存储DB2 pureScale 是使用共享存储的数据库集群。所有数据库的存储需要连接到所有成员和 CF。DB2 pureScale 会在存储上创建 GPFS 文件系统。GPFS 文件系统是一种高速的共享文件系统,它同样是一个文件系统集群,具有高可用性和易扩展性,易管理性等。成员的 CPU,内存等可以通过增加新的硬件资源或者增加成员等方式来满足。但是存储这边就没有那么简单,所以需要监控存储的利用率确定是否遇到瓶颈而导致性能问题。
关于硬件资源的所带来的性能影响,例如内存不够,网络拥挤,磁盘 IO 瓶颈等,这些可以通过系统的监控工具来确定。非集群 DB2 数据库可能遇到的性能问题和解决方法,在 DB2 pureScale 集群同样适用。下面会就 DB2 pureScale 集群本身的特点所带来的性能问题做一些探讨。
探讨数据库成员的工作负载DB2 pureScale 自动工作负载均衡是数据库集群里面对性能非常有帮助的一个特性。DB2 pureScale 支持连接级别和事务级别的工作负载均衡。这个两种级别的负载均衡可以在 DB2 客户端配置启用,DB2 客户端就会从数据库集群获取所有成员的负载信息,然后根据负载信息来确定下一个连接或者事务运行到负载低的数据库成员上,从而达到负载均衡的效果。所以 DB2 pureScale 性能课题之一就是如何用好自动负载均衡特性,解决成员节点出现瓶颈的性能问题。

图 2. 自动工作负载均衡
DB2 提供了工具直接查看 DB2 pureScale 集群成员的负载信息。db2pd 是 DB2 提供的一个功能强大和丰富的工具,占用资源少,速度快。db2pd 可以查看数据库级别的负载信息。
清单 1. 查看 DB2 pureScale 集群成员的负载信息
db2inst1@idb1122a:~> $ db2pd -db testdb -serverlist Database Member 0 -- Active -- Up 6 days 19:51:36 -- Date 05/15/2012 10:47:07 Server List: Time: Tue May 15 10:46:47 Database Name: SX2 Count: 2 Hostname Non-SSL Port SSL Port Priority TESTDBM0 50000 0 62 TESTDBM1 50000 0 100如清单中所示,当前有连个数据库成员 TESTDBM0 和 TESTDBM1,它们提供了 Non-SSL 端口连接,每个成员的负载信息是看 Priority 这一项。这个数值越大,这个成员上的负载就越轻。如果这个成员出现异常不能工作,那么它的 Priority 就会是 0。
清单 2. 异常成员的负载信息
$ db2pd -db testdb -serverlist Database Member 1 -- Active -- Up 7 days 00:31:12 -- Date 05/15/2012 11:00:32 Server List: Time: Tue May 15 11:00:05 Database Name: testdb Count: 2 Hostname Non-SSL Port SSL Port Priority TESTDBM1 50000 0 100 TESTDBM0 50000 0 0数据库成员 TESTDBM0 被终止后,它的 Priority 值变为 0. 如果其他的成员 Priority 比较小,而某个成员的 Priority 是 100,说明这个成员是完全空闲的。
分配 DB2 pureScale 集群成员负载分配应用工作负载均衡到 DB2 pureScale 集群各成员有两种方式,一种是使用自动工作负载均衡特性,另一种是自定义应用连接到指定的数据库成员。
如何启用自动工作负载均衡特性可以参考作者的另外一篇文章《如何部署 DB2 pureScale 工作负载均衡特性》或者其他资料。这里探讨一下在使用了自动工作负载均衡之后的行为。数据库的负载信息一直在变化,客户端什么时候会感受到这个变化呢?客户端从数据库服务器获取了服务器列表的负载信息,然后储存在本地。一段时间间隔后,客户端会重新获取当前的服务器负载信息,更新本地的服务器列表。这个时间间隔如果比较长,那么客户端对服务器负载信息的反应就不会很敏捷,自动工作负载均衡的效果就会受到一定的影响。但是如果这个时间间隔设置的太短,那么收集服务器负载信息的工作就会变的频繁,相应的开销也会变大。所以这里需要考虑的是估算一个比较合适的时间间隔。这个时间间隔由客户端配置参数 maxRefreshInterval 控制。
清单 3. db2dsdriver.cfg(maxRefreshInterval)
<configuration> <DSN_Collection> <dsn alias="LCO" name="LCO" host="node102.pureScale.demo" port="50001" /> </DSN_Collection> <databases> <database name="LCO" host="node102.pureScale.demo" port="50001"> <parameter name="connectionLevelLoadBalancing" value="true" /> <WLB> <parameter name="enableWLB" value="true" /> <parameter name="maxTransportIdleTime" value="-1" /> <parameter name="maxTransportWaitTime" value="true" /> <parameter name="maxTransports" value="-1" /> <parameter name="maxRefreshInterval" value="30" /> </WLB> </database> </databases> <parameters> <parameter name="CommProtocol" value="TCPIP"/> </parameters> </configuration>DB2 客户端可以使用 db2dsdriver.cfg 配置文件来配置 maxRefreshInterval 参数。对于 JAVA 应用,JDBC 驱动里面也有这个参数。这个参数的默认配置是 30 秒,也就是 DB2 客户端每 30 秒从数据库服务器获取负载信息并更新本地保存的服务器列表。
另一种方式就是不使用自动的负载均衡,而是应用指定使用哪个数据库成员。客户端偏好设置(Client Affinity)就是这样一种工作方式。如果用户了解自己的应用负载状况,那么就可以合理的安排应用去连接数据库成员,从而利用所有成员的资源。例如用户可以把负载高的成员上的应用连接到其他负载低的成员。这种方式对用户要求比较高。
探讨 DB2 pureScale 集群全局缓冲池(GBP)技术DB2 pureScale 集群里面 CF 扮演了很重要的角色,其中之一就是引入了全局缓冲池的概念。全局缓冲池是 CF 加载的一部分内存区,顾名思义是缓冲整个集群的数据库数据。那么与此对应,每个数据库成员自己的缓冲池就称为本地缓冲池(LBP)。下面通过一个例子来看 LBP 和 GBP 的关系。

图 3. 查询数据(GBP 和 LBP)
上图所示,在 member 1 上有个应用想要访问 page 501 里面的数据,这个时候 member 1 的本地缓冲池并没有这个数据,但是 CF 的全局缓冲池里面是有的。那么 Member 1 就会通过 RDMA 的方式直接访问 CF 获取这个数据,并放置到本地缓冲池中。在上面这个例子中,如果 CF 的全局缓冲池没有 page 501,那么 member 1 需要从本地磁盘读取。因为 RDMA 是直接物理访问对方内存,比从本地磁盘读取还要快很多。所以如果需要访问的数据能在全局缓冲池里找到,那么访问的性能会更好。
监控全局缓冲池的性能指标本地缓冲池有命中率的概念,命中率越高,那么说明需要访问的数据在内存里发现的比率越高,相应的性能就会越好。对于全局缓冲池来说也是一样,成员需要访问的数据在 GBP 里面发现的次数越多,说明从磁盘读取的次数越少,也是性能会更好。所以监控 GBP 就是监控它的命中率。DB2 提供了 MON_GET_BUFFERPOOL 表函数提供这些信息。
清单 4. 使用 MON_GET_BUFFERPOOL 的方法
WITH BPMETRICS AS ( SELECT bp_name, POOL_DATA_GBP_L_READS as data_logical_reads, POOL_DATA_GBP_P_READS as data_physical_reads, POOL_INDEX_GBP_L_READS as index_logical_reads, POOL_INDEX_GBP_P_READS as index_physical_reads, member FROM TABLE (MON_GET_BUFFERPOOL('',-2)) AS METRICS) SELECT VARCHAR(bp_name,20) AS bp_name, data_logical_reads, data_physical_reads, CASE WHEN data_logical_reads > 0 THEN DEC((1 - (FLOAT(data_physical_reads) / FLOAT(data_logical_reads))) * 100,5,2) ELSE NULL END AS data_HIT_RATIO, index_logical_reads, index_physical_reads, CASE WHEN index_logical_reads > 0 THEN DEC((1 - (FLOAT(index_physical_reads) / FLOAT(index_logical_reads))) * 100,5,2) ELSE NULL END AS index_HIT_RATIO, member FROM BPMETRICS;使用 db2 命令运行上面的语句,会得到所有缓冲池有关 GBP 的命中率。

图 4. 调用 MON_GET_BUFFERPOOL 表函数结果
从上面的命令输出结果来看,GBP 的命中率都比较低。如果是因为 GBP 的内存不够大而引起很多的 paging,那么增大 GBP 的大小会有助于提高缓冲池的命中率,从而提高查询的性能。
探讨 DB2 pureScale 集群全局锁管理(GLM)技术DB2 pureScale 集群里数据库成员之间的锁机制是由 CF 的 GLM 管理的。与缓冲池类似,数据库成员本地是有锁机制的,也就是内存里的 LockList 块。但是本地锁只能管理本地资源的交互。如果多个数据库成员同时需要更改同一页内的数据,就会产生竞争,为了保持数据的一致性,这种行为就需要锁的控制。来看一个例子。

图 5. 更新数据(GBP 和 GLM)
在这个例子中,所有 4 个 member 的 LBP 中都有 page 501. 这个时候 member 1 想要更改 page 501 里面的数据。它就需要向 CF 的 GLM 请求这个 page 的锁。member 1 更新完这个数据,显然其他 member 的 LBP 里面的 page 501 就过时了,CF 会自动的使用 RDMA 技术把所有其他 member 的 LBP 里的 page 501 设置为无效。这样一旦其他 member 还需要访问这个 page 的数据,就不会使用无效的 LBP 的内容,而是从 CF 获取更改过的新的内容。整个过程,GLM 的锁机制保持了数据一致性。如果 member 1 从 GLM 获得了关于 page 501 的锁并没有释放,其他 member 还要更改 page 501 里的其他内容的话,也需要向 CF 申请锁,CF 就会告知此 page 锁已被 member 1 使用,请等待 member 1 释放。这个时候就会出现锁等待。这是需要监控的性能指标之一。如果 member 1 一直不释放锁,那么其他 member 上的应用会因为一直等不到这个锁而产生锁超时而失败。锁超时的次数也是需要监控的。member 之间的锁是 page 这个级别的,如果 GLM 比较小,同一 table 的 page 锁需求又比较多,就可能引起锁升级,也就是这张表的所有 page 锁升级成整张表的表级锁,其他的 member 甚至无法访问其他 page 的数据,这会影响并发性,带来更差的性能。所以全局锁的锁升级次数也是需要关注的。
监控全局锁管理(GLM)的性能指标正如上文所述,我们需要监控与全局锁管理相关的锁等待,锁超时,锁升级等相关性能指标。DB2 提供了多个表函数可以列出全局锁管理的这些监控元素。这里使用其中一个表函数 MON_GET_PKG_CACHE_STMT 来示范。这个表函数会收集当前数据库的 PACKAGE CASH 里面的信息,返回为一张表,可以被 SQL 语句直接调用。
清单 5. 调用 MON_GET_PKG_CACHE_STMT 表函数
db2 "SELECT MEMBER, LOCK_WAITS_GLOBAL,LOCK_WAIT_TIME_GLOBAL, LOCK_TIMEOUTS_GLOBAL,LOCK_ESCALS_GLOBAL, SUBSTR(stmt_text,1,50) as stmt_text FROM TABLE(MON_GET_PKG_CACHE_STMT ( 'D', NULL, NULL, -2)) as T WHERE LOCK_WAITS_GLOBAL <> 0 order by LOCK_WAIT_TIME_GLOBAL desc" MEMBER LOCK_WAITS_GLOBAL LOCK_WAIT_TIME_GLOBAL LOCK_TIMEOUTS_GLOBAL LOCK_ESCALS_GLOBAL ------ ----------------- --------------------- -------------------- ------------------ 0 111 120039 2 1 STMT_TEXT ------------------------------- SELECT a.staffid, a.loginid as在调用 MON_GET_PKG_CACHE_STMT 返回的众多信息中,案例里面查询了 LOCK_WAITS_GLOBAL,LOCK_WAIT_TIME_GLOBAL, LOCK_TIMEOUTS_GLOBAL, LOCK_ESCALS_GLOBAL 等与全局锁管理相关的监控元素。
LOCK_WAITS_GLOBAL:因为锁被其他 member 占用而等待的次数。次数越多说明并发性受影响越大。
LOCK_WAIT_TIME_GLOBAL:等待其他 member 占用的锁的时间。时间越多说明并发性受影响越大。
LOCK_TIMEOUTS_GLOBAL:因为等待其他 member 占用的锁而产生的超时次数。事务会因此失败而回滚。
LOCK_ESCALS_GLOBAL:全局锁升级的次数。锁升级会导致并发性的严重降低。
这个表函数对于在查询当前一段时间的系统性能问题是否是因为全局锁而引起非常有效。因为 Package Cache 的大小是有限的,所以早些时间运行的 SQL 语句可能已经被挤出这个内存块,就不会被这个表函数返回。DB2 还提供了其他一些针对不同对象的表函数,也能反馈这些全局锁的信息。例如 MON_GET_CONNECTION,MON_GET_WORKLOAD,MON_GET_UNIT_OF_WORK 等等。
解决全局锁的性能问题已经从上文中获取到了引起全局锁问题的 SQL 语句,相应的也定位到了相关的应用。现在的问题是已什么样的思路去解决性能指标所示的这些问题。
首先还是从全局锁的产生原因来看。全局锁是 member 之间的锁,也就是在不同的 member 上运行的应用需要访问同一个表的相同 page 内的数据。一种解决的方式就是将这些应用安排到同一个 member 上运行,就不存在 member 间竞争的问题。这种方式可以通过设置客户机偏好的方式。前提是定位到是哪些应用有冲突,单个 member 的系统资源是否足以运行这些应用。
另外一种方式是在应用的事务中加入更多的 Commit。提交越频繁,锁就释放的比较快,相应的减少锁冲突的几率。
如果某些全局锁无法避免,但是应用会经常因为锁超时而回退。这对终端用户会有很大的影响。这个时候可是适当增加锁超时设置的时间。这个时间可以通过更改数据库参数 LOCKTIMEOUT。这个值如果是 -1,将永不超时。
最后看看全局锁升级的问题。全局锁升级的原因一般是因为全局锁使用的内存不够,只能把多个页级别的锁升级为单个表级别的锁来减少内存开销。所以解决全局锁升级的办法是适当增加 CF 里面这个内存的大小。这个大小由数据库参数 CF_LOCK_SZ 控制。
探讨 DB2 pureScale 集群 Page Reclaiming 行为上一章节描述了多个 member 访问同一 page 会产生锁等待的问题。现在来讨论与此相关的数据库的另外一个行为 -Page Reclaiming(数据页回收)。先通过一个例子来了解 Page Reclaiming 是如何发生的:
假设有两个数据库成员 M1 和 M2。M1 和 M2 想要同时去更行相同数据页里面的两个不同的行。
1. M1 正在更新数据页 P1 里面的行 R1. 它被授以 P1 的独占锁。
2. M2 想要更新 P1 里面的行 R2。它像 CF 请求相同的数据页 P1 上的独占锁并等待。
3. CF 看到 M1 已经占用了这个数据页的独占锁,CF 会向 M1 发送一个回收此页的请求。在此期间,M2 一直等待。
4. M1 处理这个数据页回收请求并把数据页写回到 CF 的 GBP 中,然后释放这个数据页。这个时候 M1 仍然占用着它原有的关于这个表的行级锁。
5. CF 授权 M2 能使用这个数据页。M2 从 GBP 里面把这个数据页读到本地并继续处理。
从 M2 申请数据页到从 GBP 获取到它,这个时间会被计算到应用的运行时间里面,也是数据库性能中重要的一块。我们需要监控这种行为对性能带来的影响。
监控 Page Reclaiming 行为DB2 提供了 MON_GET_PAGE_ACCESS_INFO 表函数来提取相关的信息。这里需要关心的是什么表经常发生这样的行为,这种行为消耗了多少时间。这种行为发生在哪个数据库成员上。
清单 6. 调用 MON_GET_PAGE_ACCESS_INFO 表函数
db2 "SELECT SUBSTR(TABSCHEMA,1,8) AS TABSCHEMA, SUBSTR(TABNAME,1,20) AS TABNAME, RECLAIM_WAIT_TIME, MEMBER, SUBSTR(OBJTYPE,1,10) AS OBJTYPE FROM TABLE(MON_GET_PAGE_ACCESS_INFO(NULL,NULL,-2)) WHERE RECLAIM_WAIT_TIME > 0 ORDER BY RECLAIM_WAIT_TIME DESC FETCH FIRST 10 ROWS ONLY" TABSCHEMA TABNAME RECLAIM_WAIT_TIME MEMBER OBJTYPE --------- -------------------- -------------------- ------ ---------- TFM2 TF_INOUT_TYPE_LOG 51 1 INDEX SYSIBM SYSTABLES 3 0 TABLE 2 record(s) selected.上述的这个方法可以找出数据页回收而消耗的时间最多的表。RECLAIM_WAIT_TIME 返回等待的时间,单位是毫秒。
解决 Page Reclaiming 性能问题Page Reclaiming 其实还是全局锁的问题。解决的思路和前述的解决全局锁问题差不多。对于 Page Reclaiming 的监控能够更直观的发现时间消耗了多少,从而定位系统的性能问题多大程度与此相关。
DB2 pureScale 集群环境性能调优总结我们已经讨论了相对于单节点的数据库,DB2 pureScale 集群环境里面用到的新的技术和事务的处理过程。探讨了这些新的数据库内容对于性能所带来的影响以及怎么去应对。但是数据库集群的性能问题受多方面因素影响,用户需要不仅从 DB2 pureScale 集群环境新的技术角度,还是要从系统资源的角度,从单数据库节点调优的角度去处理数据库的性能问题。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3作者其他文章
评论 3 · 赞 4
评论 1 · 赞 10
评论 3 · 赞 7
评论 2 · 赞 7
评论 2 · 赞 10
添加新评论0 条评论