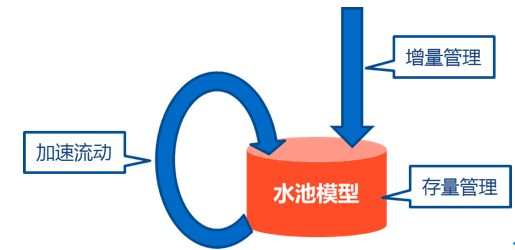
CMDB的数据可分为自动发现数据和人工录入数据两大类。第一策略是尽最大努力扩大自动发现范围(因为自动发现的数据一定是最准确),降低配置管理的成本。常见的自动发现数据源有云管平台、安全管理系统、网管平台、负载均衡系统、带外管理系统等,总之要团结一切能够自动发现的力量。但接下来总要面对人工录入数据,这里用水池模型来解释。要一个水池干净,一是保证流入的增量干净,二是净化水池中的存量,三是要水循环流动起来。类似的,CMDB增量变更数据由场景流程来控制,存量数据靠数据资产明确属主并提高犯错成本。最后通过场景消费形成正反馈机制。三管齐下。