1同行回答
 1、之前有过一个分享,可供参考:背景2016除夕,相信很多朋友都非常关注支付宝的“咻一咻”和微信的“摇一摇”。通过这两个产品,我们不难发现,手机红包“仅在短短三年时间”里,就成为互联网金融的现象级产品。然而传统金融行业如何利用自己的优势,加速互联网入口布局,成为了我们的...
1、之前有过一个分享,可供参考:背景2016除夕,相信很多朋友都非常关注支付宝的“咻一咻”和微信的“摇一摇”。通过这两个产品,我们不难发现,手机红包“仅在短短三年时间”里,就成为互联网金融的现象级产品。然而传统金融行业如何利用自己的优势,加速互联网入口布局,成为了我们的...1、之前有过一个分享,可供参考:
背景
2016除夕,相信很多朋友都非常关注支付宝的“咻一咻”和微信的“摇一摇”。
通过这两个产品,我们不难发现,手机红包“仅在短短三年时间”里,就成为互联网金融的现象级产品。然而传统金融行业如何利用自己的优势,加速互联网入口布局,成为了我们的一个重要课题。
今年春节我司希望借此良辰佳节,运用互联网的技术方式,展开“太保‘友’你,太保有礼”的除夕微信红包活动与初五迎财神抽奖活动,用千万“猴”礼,回馈新老客户。
活动之前,腾讯就评估本次微信活动参与人次可能会达到1.5亿人次,高峰并发请求量达到每秒400万次。
面对如此之大的用户量与交易量,不禁让我们思考,是否传统架构可以承受并支持业务活动的顺利开展?是否有比传统架构更好的方式或技术来支持?
传统架构分析
针对上述的三个问题,我们首先针对业务活动情况,在传统架构基础上做了部署规划方案及承载能力数据统计。但是从数据结果上看,使用传统架构来实现业务支持是不可能的。不仅资源准备周期长,同时部署过程繁琐,无法如期满足业务活动需要。即便连夜赶工完成,可能也要面临部分节点故障导致的应用服务问题。
同时在传统架构上,我们也发现了另外一个严重问题。由于我司大部分应用是在虚拟机上使用Weblogic和Websphere来部署,每个节点的资源利用率上,很不平均,部分应用服务可能在本次活动中,并不会存在大并发量或者产生很多业务数据,却要占用相当一部分的资源。如果压缩资源,又担心是否会存在不稳定的情况? 不仅如此,相应的应用维护压力也会出现,如何保障应用服务稳定,也是一个难题。
需求分析
面对传统架构部署可能带来的这些问题,我们重新对业务活动及本身的我司微信应用做了全面的分析及解决方案的规划:
1. 需要更高效的虚拟化技术。 由于我司业务特性,本次活动需要同时部署十多个类型的应用。对于不同的应用,传统方式需要不同的软硬件部署方案。为减少软硬件部署周期,需要提出更高效的虚拟化方案和技术。
2. 需要更快的部署和交付。 由于准备时间周期短(1个月),如何更快的部署开发、测试、生产环境,并且交付保质保量的环境,需要更快和高质量的应用部署方案。
3. 更轻松的迁移和扩展。 面对三个环境的部署,且各环境对并发量需求存在不同。需要迁移的应用迁移及能适应环境需求的扩展方案。
4. 更简单的管理。 面对大量的应用服务,需要有效和简易的应用服务管理方案,来实现自动恢复及异常容错能力。
新技术选型
带着这些问题,我们结合行业内优秀技术方案和经验,决定使用容器化技术(Docker)来支持我们的业务活动。
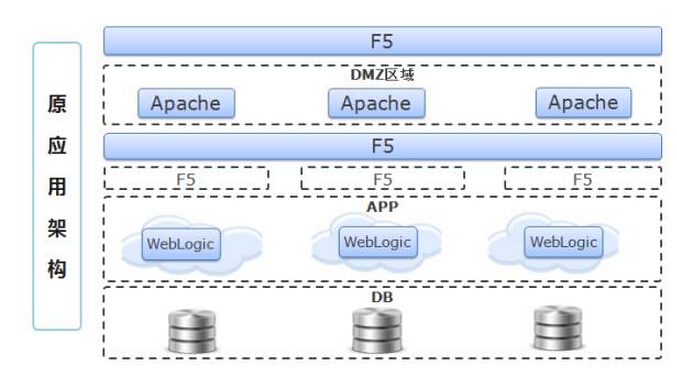
首先,我们针对原有微信项目架构进行回顾:
面对原有以应用为单位的部署方案上,需提高资源利用率,降低虚拟机资源和中间件部署的耗费。为了解决这个问题,我们以Mesos、Marathon为核心,实现容器资源的分布式调度与协调。同时服务引流方面,鉴于原有Apache方案和应用本身特性上,采用了HAProxy来实现。
其次,部分应用存在有状态Session或者热点数据,这个方面上与我们实施的方案存在冲突。为了解决这个问题,并且规避实时数据丢失,我们采用了Redis将Session数据集中存储,并使用容器挂在共享nas的方式来集中存储文件(例如影像等)。
第三,为实现准确的应用监控及应用健康状态检查方案,我们针对每一个应用镜像都植入了“APM探针”,实时获取应用服务信息,如:线程数、交易响应时间等,并将数据实时记录。同时通过这些监控指标信息,来具体分析应用能力,实现应用服务自动伸缩。

最后,在此基础上增加日志分析平台、自动化运维平台、端到端监控的APM平台等用于资源的统一管理、监控及问题分析,继而形成一套完整的DCOS架构。
过程回顾
虽然本次活动顺利收官,但是过程中遇到了一些问题:
比如在压测过程中,跨网段的服务器,因网络问题致使mesos-slave与mesos-master失联,导致mesos-slave容器自动销毁。此时master无法再获取到资源节点上的容器信息,导致大量容器服务不能被发现。当时面临这个问题,第一时间还以为是资源节点服务器宕机,但是登录问题节点后才发现是slave容器不存在。在尝试重启slave后,发现容器依然自动停止。通过日志查询才发现是无法与master进行通讯。
对此我们添加了docker_kill_orphans、recovery_timeout配置文件,避免在网络异常情况下,出现slave容器停止情况。
由于部分应用使用资源上需要大于1c,但是测试环境资源有限,出现资源争用现象,压测数值一直不理想。
在压测过程中,以上两个问题,导致项目几经波折,几乎要面临回归传统架构的方式。最后经过反复尝试,采用了限制容器CPU的参数配置方式,从而避免了由于资源互相争用而导致的服务能力不稳定。
另外,容器平台的使用对传统的运维方式也带来了巨大的挑战,传统的应用监控、日志采集分析方法由于容器平台的动态扩展特性,效果都不理想。通过采用APM及日志分析平台与容器镜像的集成,解决了容器平台的使用给生产运维带来的困扰。
太保Docker未来之路的思考
经过本次项目后,借助Docker的一次创建,到处运行的特性搭建了我司的DCOS平台,不仅为开发人员提供了便利,也保证了开发环境、测试环境和生产环境的一致性。
但是从居安思危的角度考虑,我们还是在很多方面需要完善,比如镜像版本过多后,我们该如何管理?如何将DCOS平台部署的部署方案细化?还有就是最近大家都在关心的容器安全问题,是否有要求和有标准的选择共有仓库中的镜像?
为了做好这个功课,也是为了更好的推广DCOS平台,我们制定了包含镜像版本管理规则、软件版本升级规则在内,含盖开发、环境管理、生产运维领域的一系列容器相关规范、流程及技术方案。
后续我们还将持续对DCOS平台在稳定性、安全性及可维护性方面进行优化。并大力推进容器技术在新项目及原有系统中的使用。
案例中所有应用都运行在虚拟机上,当然物理机也是可以的。
收起