基于 LLM 的知识图谱另类实践
本文整理自社区用户陈卓见在「夜谈 LLM」主题分享上的演讲,主要包括以下内容:
- 利用大模型构建知识图谱
- 利用大模型操作结构化数据
- 利用大模型使用工具
利用大模型构建知识图谱

上图是之前,我基于大语言模型构建知识图谱的成品图,主要是将金融相关的股票、人物、涨跌幅之类的基金信息抽取出来。之前,我们要实现这种信息抽取的话,一般是用 Bert + NER 来实现,要用到几千个样本,才能开发出一个效果相对不错的模型。而到了大语言模型时代,我们有了 few-shot 和 zero-shot 的能力。
这里穿插下 few-shot 和 zero-shot 的简单介绍,前者是小样本学习,后者是零样本学习,模型借助推理能力,能对未见过的类别进行分类。
因为大语言模型的这种特性,即便你不给模型输入任何样本,它都能将 n+ 做好,呈现一个不错的效果。如果你再给模型一定的例子,进行学习:
is_example = {
'基金':[
{
'content': '4月21日,易方达基金公司明星基金经理张坤在管的4只基金产品悉数发布了2023年年报'
'answers':{
'基金名称':['易方达优质企业','易方达蓝筹精选'],
'基金经理':['张坤'],
'基金公司':['易方达基金公司'],
'基金规模':['889.42亿元'],
'重仓股':['五粮液','茅台']
}
}
],
'股票':[
{
'content': '国联证券04月23日发布研报称,给予东方财富(300059.SZ,最新价:17.03元)买入评级...'
'answers':{
'股票名称':['东方财富'],
'董事长':['其实'],
'涨跌幅':['原文中未提及']
}
}
]
}
就能达到上述的效果。有了大语言模型之后,用户对数据的需求会减少很多,对大多数人而言,你不需要那么多预算去搞数据了,大语言模型就能实现数据的简单抽取,满足你的业务基本需求,再辅助一些规则,就可以。
而这些大语言模型的能力,主要是大模型的 ICL(In-Context Learning)能力以及 prompt 构建能力。ICL 就是给定一定样本,输入的样本越多,输出的效果越好,但是这个能力受限于模型的最大 token 长度,像是 ChatGLM-2,第一版本只有 2k 的输入长度,像是上面的这个示例,如果你的输入特别多的话,可能很快就达到了这个模型可输入的 token 上限。当然,现在有不少方法来提升这个输入长度的限制。比如,前段时间 Meta 更新的差值 ORp 方法,能将 2k 的 token 上限提升到 32k。在这种情况下,你的 prompt 工程可以非常完善,加入超多的限制条件和巨多的示例,达到更好的效果。
此外,进阶的大模型使用的话,你可以采用 LoRA 之类的微调方式,来强化效果。如果你有几百个,甚至上千个样本,这时候辅助用个 LoRA 做微调,加一个类似 A100 的显卡机器,就可以进行相关的微调工作来强化效果。
利用大模型操作结构化数据

结构化数据其实有非常多种类,像图数据也是一种结构化数据,表数据也是一种结构化数据,还有像是 MongoDB 之类的文档型数据库存储的数据。Office 全家桶之前就在搞这块的工作,有一篇相关论文讲述了如何用大模型来操作 Sheet。
此外,还有一个相关工作是针对 SQL 的。前两年,有一个研究方向特别火,叫:Text2SQL,就是如何用自然语言去生成 SQL。

大家吭哧吭哧做了好几年,对于单表的查询这块做得非常好。但是有一个 SQL 困境,就是多表查询如何实现?多表查询,一方面是没有相关数据,本身多表查询的例子就非常少,限制了模型提升;另一方面,多表查询本身就难以学习,学习条件会更加复杂。
而大语言模型出来之后,基于 GPT-4,或者是 PaLM 2 之类的模型,去训练一个 SQL 版本的模型,效果会非常好。SQL-PaLM 操作数据库的方式有两种。一是在上下文学习(In-context learning), 也就是给模型一些例子,包括数据库的 schema、自然语言的问题和对应的 SQL 语句,然后再问几个新问题,要求模型输出 SQL 语句。另一种方式是微调(fine-tuning),像是用 LoRA 或者是 P-tuning。

上图就是一个用 Prompt 工程来实现 Text2SQL,事先先把表的 schema 告诉大模型,再提问,再拼成 SQL… 按照这种方式给出多个示例之后,大模型生成的 SQL 语句效果会非常好。还有一种就是上面提到的微调,将 schema 和 question 组合成样本对,让大模型去学习,这时候得到的效果会更好。具体可以看下 SQL-PaLM 这篇论文,参考文末延伸阅读;
此外,还有更进阶的用法,和思为之前举的例子有点相似,就是大模型和知识图谱结合。
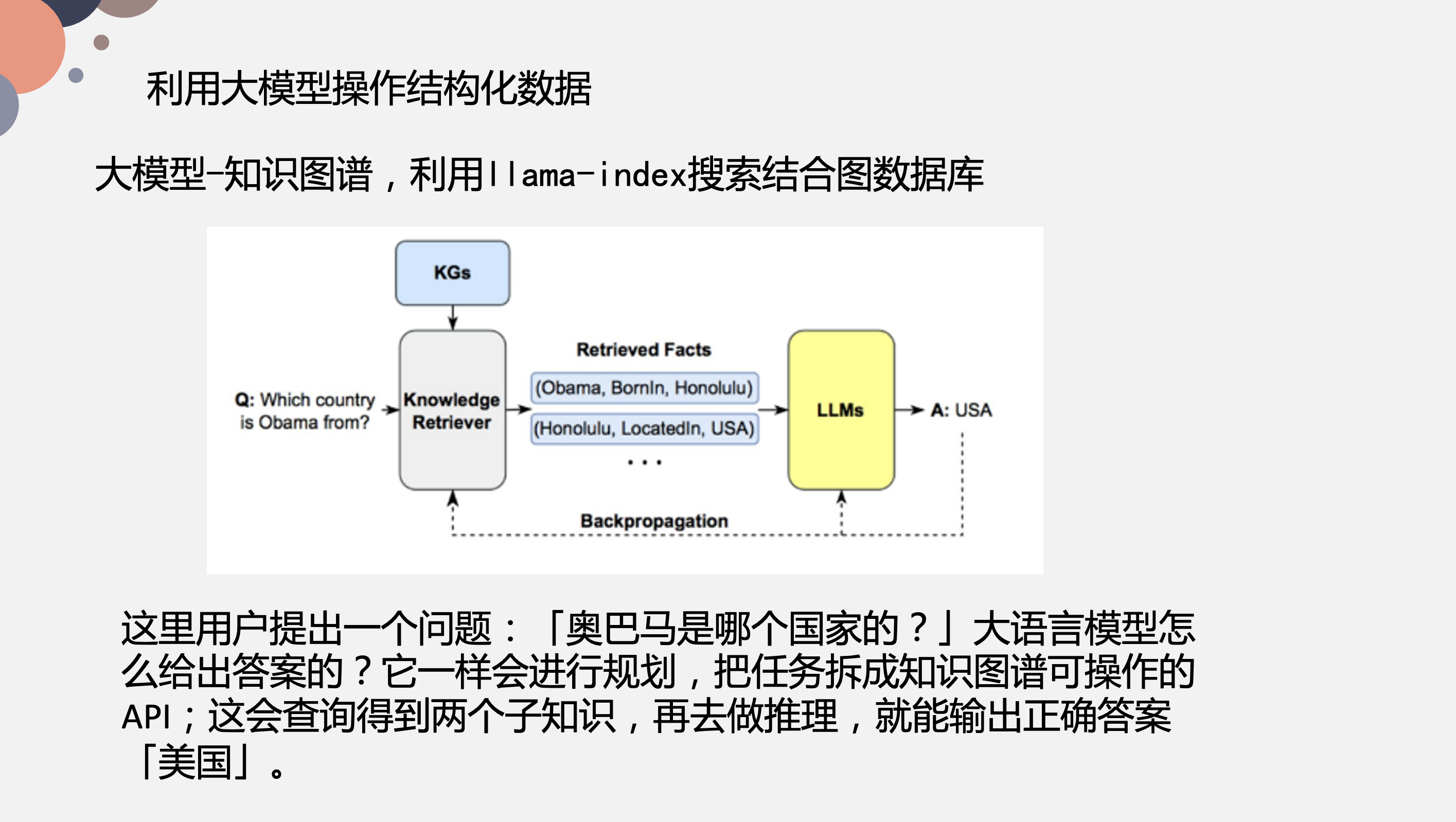
比如说,我想问 “奥巴马出生在哪个国家 “,它就是构建知识图谱 KQs,再进行一个召回,而召回有很多种方法,比如之前思为分享的 Llama Index 的向量召回,而向量召回最大的难点在于模型,像 OpenAI 提供的模型,效果会比较好,但是数据量大的时候,频繁调用 OpenAI API 接口一方面涉及到隐私问题,另一方面涉及到预算费用问题;而自己要训练一个模型,不仅难度大,由于数据量的原因,效果也不是很好。因此,如果你是借助 Llama Index 的向量模型进行召回,可能需要辅助一些额外的关键词模型,基于关键词匹配来进行召回,像是子图召回之类的。
对应到这个例子,系统需要识别出关键词是 Obama 和 Country,关联到美国,再进行召回。这样处理之后,将相关的事实 Retrieved Facts 喂给大模型,让它输出最终的结果。在 Retrieved Facts 部分(上图蓝色部分),输入可能相对会比较长,在图中可能是一个三元组,这样就会相对比较简单。这里还会涉及到上面说的 2k 输入 token 提升问题,还是一样的通过一些微调手段来实现。
大模型使用工具
下面就是本文的重头戏 —— 大模型的使用工具。什么是大模型工具?你可以理解为它是把一些复杂操作集成到一起,让大模型做一个驱动。
举个例子,ChatGPT 刚出来的时候,会有人说 “给我点一个披萨”,这当中就涉及到许多复杂的操作。
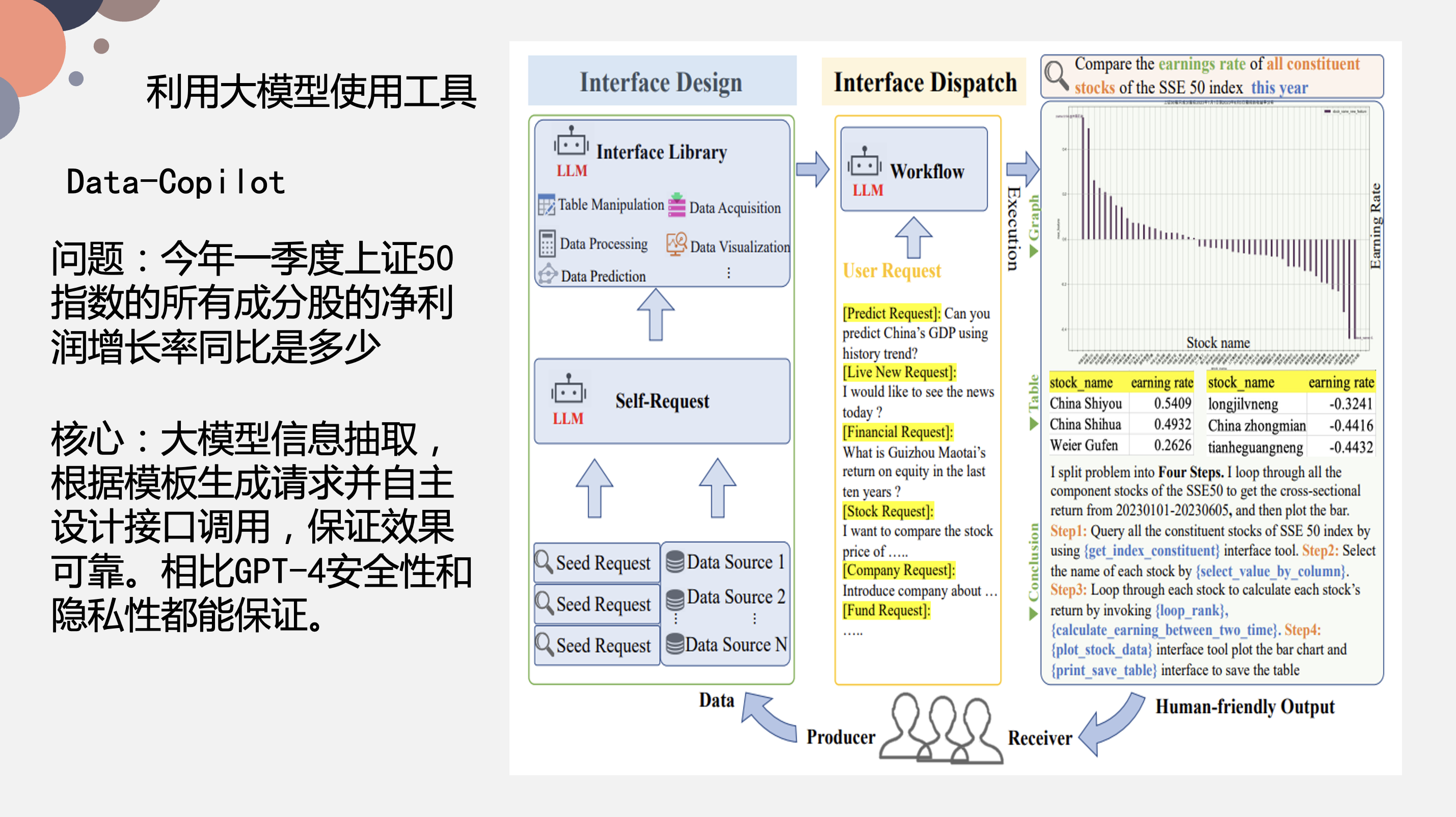
Data-Copilot 是浙大某个团队做的大模型工具,主要是做意图识别和信息抽取。上图右侧是 “输入一句话,把相关的图绘制出来” 的效果展示,这里就要提取一句话中的关键词信息,关键词信息识别之后去对应的数据库中找对应的数据,找到数据之后进行数据处理,最后再生成一个图。这里并没有用到图数据库,而是直接基于 2Sheet 接口来实现的。
这里我们向这个模型提出一个需求 “今年上证 50 指数的所有成分股的净利润增长率同比是多少”,这个模型会将其解析成对应的一个个步骤进行操作。上图右侧显示了一共有 4 步:
- Step1 解析关键指标;
- Step2 提取相关数据;
- Step3 数据处理,整理成对应格式;
- Step4 绘制成图;
而大模型是如何实现的呢?主要分为两层,一方面你要设计一个接口调用,供 prompt 调用;另一方面准备好底层数据,它可能是在图数据库中,也可能在关系型数据库中,给接口做承接之用。

这个例子更加复杂,是想让大模型来预测中国未来(下四个季度)的 GDP 增长。这里看到它分成了三部分(上图橙色部分):
- Step1 拿到历史数据;
- Step2 调用预测函数,它可能是线性函数,也可能是非线性函数,也有可能是深度学习模型;
- Step3 绘制成图(上图蓝色部分);
一般来说,金融分析师做相关的金融数据分析的模型会相对统一,这种相对统一的模型我们用函数实现之后,就可以让他的工作更加便捷:分析师只要说一句话,图就画好。这里是 Data Copilot 的 GitHub 地址:https://github.com/zwq2018/Data-Copilot
大模型的最终形态
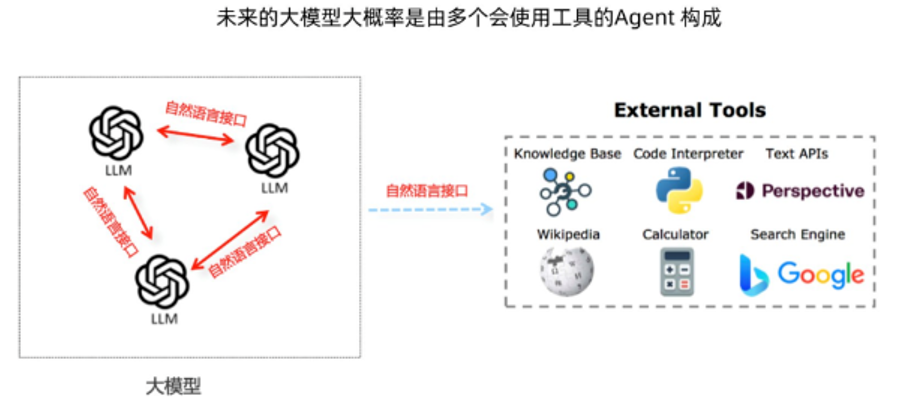
上面展示的形态,基本上人工痕迹还是很明显的:prompt 要人为写,数据接口也得人为写。而我觉得它最终的形态,可能同 GPT4 的形态有点相似,像是前段时间出的 Code Interpreter,代码编译器功能,你只用一句话,后面所有的功能都实现完了。大概实现过程就是上图所示的,用 LLM 作为接口,把整个百科、计算器、搜索、编译器、知识图谱等等接入进来,从而最终实现画图的功能。
而它的最终效果是怎么样的呢?下面是国际友人在推特上 po 出的一张图:
就那么简单,你不需要额外地搞 API,就能实现一个功能。
LLM 你问我答
下面问题整理收集于本场直播,由 Wey 同社区用户陈卓见一起回复。
大语言模型和知识图谱的结合案例
Q:目前大模型和知识图谱的结合案例有吗?有什么好的分享吗 ?
Wey:之前卓见老师在我们社区分享过一篇文章《利用 ChatGLM 构建知识图谱》,包括我上面的分享,也算是一种实践分享。当然我们后续会有更多的介绍。看看卓见有没有其他补充。
陈卓见:我是相关的 LLM 从业人员,不过内部保密的缘故,这块可能不能和大家分享很多。基本上就是我之前文章所讲的那些,你如果有其他的问题交流,可以给文章留言,大家一起进一步交流下。
大模型入门教程
Q:现在如果要入门大语言模型的话,有什么好的入门教材 ?
Wey:如果是利用大语言模型的话,可以看下 LangChain 作者和吴恩达老师出的教程,据说这个教程还挺不错的。而我个人的话,会看一些论文,或者是追 LangChain 和 Llama Index 这两个项目的最新实现,或者已经实现的东西,从中来学习下 LLM 能做什么,以及它是如何实现这些功能的。而一些新的论文实现,这两个项目也对其做了最小实现,可以很方便地快速使用起来,像是怎么用 Embedding,它们支持哪些 Embedding 模型之类的事情。
陈卓见:思为分享的可能是偏应用层的,而对我们这些 LLM 从业者而言更多的可能是如何训练大模型。比如说,我们想实现某个功能,我们应该如何去构造数据,选择大模型。像是我们团队,如果是来了一个实习生,会看他数学能力如何。假如数学不好的话,会先考虑让他先多学点数学;如果数学水平不错,现在同大模型相关的综述文章也挺多的,会让他去看看综述文章,无论中文还是英文,都有不少相关的资料可以学习。像 transformer 层,大模型训练的细节,分布式怎么做,工程化如何实现 ,都是要去了解的。当然,这里面肯定是有侧重点的,你如果是想了解工程的知识,你可以去多看看工程知识;想了解底层原理,就多看看理论,因人而异。
这里给一些相关的资料,大家有兴趣可以学习下:
- A Survey of Large Language Models:https://arxiv.org/abs/2303.18223,主要了解下基本概念;
- 中文版的综述《大语言模型综述》:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey__Chinese_V1.pdf
如何基于 LLM 做问答
Q:NebulaGraph 论坛现在累计的问答数据和点赞标记,是不是很好的样本数据,可以用来搞个不错的专家客服 ?
Wey:在之前卓见老师的分享中,也提到了如果有高质量的问答 Pair,且有一定的数据量,是可以考虑用微调的方式,训练一个问答专家。当然,最直接、最简单的方式可能是上面分享说的 RAG 方式,用向量数据库 embedding 下。
部署大模型的路径和实现配置
Q: 想问部署 65b 大模型最低成本的硬件配置和实现路径 ?
陈卓见:先看你有没有 GPU 的机器,当然 CPU 内存够大也是可以的,有一台 256B 内存的机器,应该 65b 也是能推理的。因为大模型分不同精度,一般我们训练用到的精度是 fp16。而 fp16 的话,对于 65b 的模型,它大概显存占用大概是 120GB 到 130GB 之间。如果你用的内存训练的话,内存得超过这个量级,一般是 256GB,就能推理的。但是不大推荐用 CPU,因为它的速度可能只有同等规模 GPU 的 1/10,甚至 1/20、1/50 都有可能的,这具体得看你的环境。
如果你用 GPU,它是有几种选择,如果你用 fp16 的精度想去做推理的话,那么你可能需要 2 张 80GB 显存的机器,比如说 A100、A800 这样机器才能行。但最低实现的话,你可以选择 INT4 精度,这时候需要一个 40GB 左右的显存,比如买个 A6000,48GB 显存,它应该也是能推理的。但这个推理其实是有限制的,因为推理是不断的 next token prediction,是要一直生成 token 的,这就会占用你的显存。如果你让它写一篇长文的话,这时候 48GB 显存应该是不够用的,显存会爆。所以,你准备 2 个 48GB 的显存,在 INT4 下可以方便地进行推理之余,还能搞搞模型并行,QPS 也会有所体现。但是单 48GB 显存的话,内存可能会爆。
最近比较流行的有个 LLaMA CPP 项目,就支持 INT4 量化,而且未来还计划支持 INT2 量化。但 INT2 量化这个效果就不敢保证了,因为 INT4 至少有不少项目,像是 LLaMA、ChatGLM 都做过实验,测试下来精度损失不会那么大,但是 INT2 还没有实践数据出来,不知道到底精度损失会有多少?
小结下,我建议你最好是准备一个 A800 的机器,或者是两个 A6000 这样的机器,或者四个 A30,都能做 65b 的推理。这个配置会比较稳妥一点。 下个问题。
Wey:这里我想追问下卓见一个问题。我有一个穷人版的 24GB 显存,暂时还没试过 Fine-Tuning,但是我现在做正常精度的 6b 推理是 OK 的。如果是 INT4 的话,据说 6GB 显存就可以推理?
陈卓见:这里解释下显存和模型参数量的关系,如果你是 6b 模型的话,一般显存是 12GB,就能做正常的 fp16 推理,而 INT4 的话,直接显存除以 3,大概 4 GB 就可以做 INT4 的推理。如果你现在是 24GB 的显存,其实可以试试 13b 的模型。
非结构化数据如何存储到图
Q:非结构化的数据,比如就一本书,如何先存储到 graph 里 ?
Wey: 穷人的实现思路,这个书如果是有 PDF 的话,直接用 Llama Index 6、7 行代码就可以扫入到数据库中。如果是之前我们的 prompt 的话,用 NLP 专业角度判断的话,它其实效果并没有那么的好,但是可以接受。此外,Llama Index 还有个 hub 项目,如果你的 PDF 是纯光学扫描的话,它会自动 OCR 提取信息。
陈卓见:这里我补充下,你数据存储到图中要干嘛?如果是做一个问答,那么 Llama Index 是个不错的方案。如果是其他的需求,其实一个纯文本的 txt,可能也就行了。
如何准备数据以及训练模型
Q:训练模型或者是进行 Fine-Tuning,在数据准备方面有什么经验分享 ?
陈卓见:Fine-Tuning 要准备的数据量取决于你要实现的功能,不同的事情难度,所需的数据量是不同的。比如,你要用 LLaMA 做一个中文问答,你要做中文的词表,准备中文的问答数据,再搭配一部分英文的问答数据,这样做一个 LoRA 微调。但你如果是只做英文的问答,中文这块的数据就不需要了,用少量的英文数据,就能很好地调好模型。一般就是写 prompt,再写输出,组成对,LoRA 有标准格式,整成标准格式就能用。
模型的准确性
Q:在实际应用中,如何做领域知识图谱的品控,确保 kg 就是知识图谱的内容完备跟准确性,如果知识图谱的内容都错了怎么办 ?
陈卓见:其实,我们一般是准备好几个模型。大模型只是一部分,比如说我们准备三个模型,第一个模型是用大模型,第二个模型是 Bert + NER,第三个是基于规则的模型,然后这三个模型组成一个类似的投票模型。三个模型都通过的数据就放进去,两个模型通过的数据就让人校验下,只有一个通过的数据,目前我们是不采用的,直接不要。目前,实践下来,大模型的准确率只有 70-80%,准确率并不是很高。但再经过一道 LoRA,准确率会提高点。建议还是做多模型,相对会保险一点。
大模型和 asr
Q:大模型的语言 ASR 处理有什么经验分享,比如:语音的特征提取怎么做 ?
陈卓见:这就是大模型的多模态,一般是先做小模型,对语音、图像进行 Embedding 之后,再归一成一个大模型。可以先看看语音的 Embedding 是如何实现的,再看看多模态的大模型是如何将其相结合。不过目前来说,尚在一个摸索阶段,没有非常成熟的解决方案。
模型固定输出
Q:让模型以固定形式回复问题,怎么构建数据训练模型呢?比如说法律问题要以什么法规去回答问题 ?
Wey:如果是训练的话,我其实没有做过 Fine-Tuning。如果是纯 prompt 的话,有几个原则:给出各种例子、各种强调输出结果格式,prompt 这套就是个黑匣子,有时候你来回调整语序就能得到不错的结果。当然有些边缘 case,可能难以按照固定的格式输出,你可以用正则表达做个兜底,确保最后的一个输出格式。
陈卓见:我们在做 Fine-Tuning 的时候,在数据收集时,可以过滤掉一些偏见数据。还有就是在模型训练的微调阶段,有一个 Reward model,就是回答打分,你可以把某一类问题中你觉得回答的不好的回复打低分,然后在 PPO 阶段,模型进行学习时,就会降低输出这类回答的概率。一般来说,还是在 prompt 里加巨长的 prompt,可能是几百个 prompt,类似于不要回答什么,优先回答什么,写个很长这样的东西让它去做回答。一般不建议在训练阶段,去做输出的格式的实现,因为成本非常昂贵,相对的写 prompt 的成本就低多了。
延伸阅读
- SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL:https://arxiv.org/abs/2306.00739
- 利用 ChatGLM 构建知识图谱:https://discuss.nebula-graph.com.cn/t/topic/13029
- 图技术在 LLM 下的应用:知识图谱驱动的大语言模型 Llama Index:https://discuss.nebula-graph.com.cn/t/topic/13624
- Text2Cypher,大语言模型驱动的图谱查询生成:https://www.siwei.io/llm-text-to-nebulagraph-query/
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1作者其他文章
评论 0 · 赞 0
评论 1 · 赞 1
评论 0 · 赞 0
评论 1 · 赞 1
评论 0 · 赞 0
添加新评论0 条评论