一文搞懂 JVM GC 行为
在日常的 Java 虚拟机进行监控的时候 ,我们往往会 观测到各种各样的图形,无论是基于 JDK 自带的 Jconsole、Jvisualvm、JMC 还是第三方工具或插件,例如,Jprofile 、 GCeasy 等。 基于对垃圾收集模式的监测 ,我们 可以实时观摩 应用程序的健康状态和性能特征,以方便为后续的性能调优提供数据参考。

在本篇文章中,笔者结合 GCeasy 工具将从以下 5 种 Java GC 图像形态简要为大家分享一些有趣的垃圾收集模式行为,以方便对 Java 虚拟机活动相关基础知识有所了解,为后续的性能调优做好理论准备。
> 1. 健康锯齿状
在实际的业务场景中,若应用程序表现特征呈现为健康时,我们将会看到一个正态分布较为均匀的或具有一定规律特性的锯齿状图像展现,如下图所示,我们可以观测到:堆内存使用量将不断上升,一旦触发 “Full GC” 事件,堆内存使用量将一路下降至底部,每一次操作后基本上维持一个均衡的水位。

基于上述图形展现,我们可以直观的看到,当堆使用量达到大约 5.8 GB 时,黄色箭头所指向方向及位置时,“Full GC” 事件(即图中的“红色三角形”标识)即会被触发。当 “Full GC” 事件运行时,内存利用率一直下降到最低点,即每次基本上都维持在大约 200 MB 左右的水位,如深红色箭头所指向及位置。大家可参考图中的黑色虚线箭头线。基于此种图像特征,其往往表明我们的应用程序处于健康、稳定的运行状态并且没有遇到任何类型的内存问题。
> 2. 内存溢出锯齿状
然而,在实际的业务场景中,往往也存在另一种有规律性的 锯齿状图像,其与健康的锯齿状图像差异之处在于,堆内存使用量在不断上升的情况下,触发 “Full GC” 事件 ,而此时呢?堆内存使用量并非将一泄千丈,而是缓缓的上涨,与上一次的 GC 轨迹相比,其趋向明显的处于上升状态。具体如下图所示:
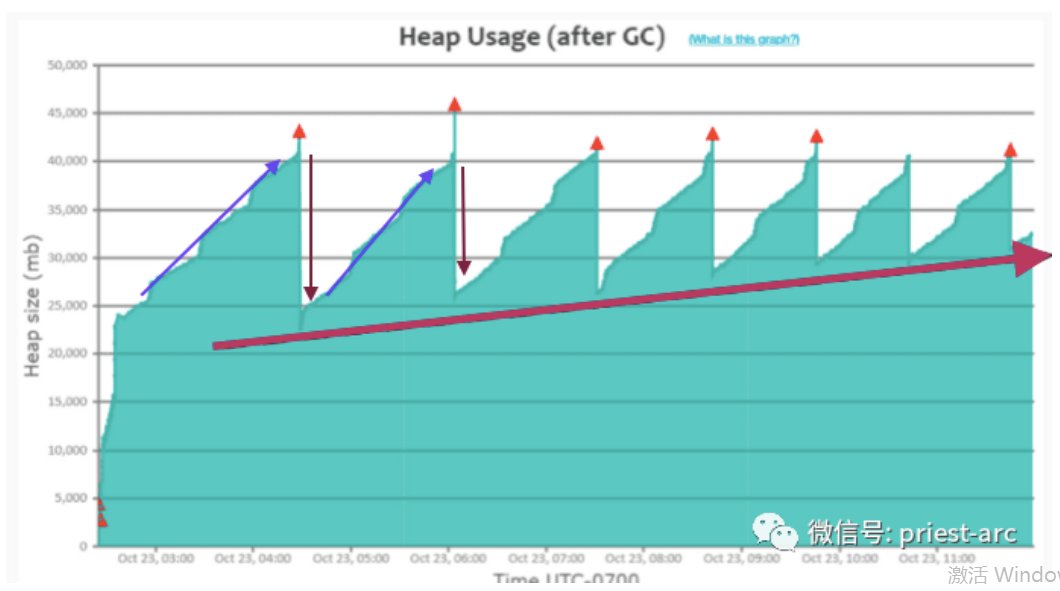
基于此种场景,可能因 Java 内存分配、应用程序代码异常以及所依赖的组件调用等等,在特定的环境中容易遭受这种“严重内存泄漏模式”的困扰。当我们的应用程序遇到此种异常环境时,堆内存使用量会缓慢上升,即使进行 GC 事件操作,最终也将导致 OutOfMemoryError 错误。
基于上述图形展示结果,我们可以看到当堆使用量达到约 43 GB 时触发 “Full GC”(即图中的“红色三角形”标识)事件。在整个活动轨迹中,我们还可以观察到 Full GC 事件可以恢复的堆内存使用量在一段时间内开始下降,但下降量越来越少,可通过图中的朝下方向的深红色箭头体现。即,针对每一次的 GC 事件,我们可以将其活动事件汇总为以下:
第一次 Full GC 事件运行时,堆内存使用量下降到约 22 GB,而 第二次 Full GC 事件运行时,堆内存使用量仅下降到约 25 GB,比第一次少 3 GB, 第三次 Full GC 事件运行时,堆内存使用量仅下降到约 26 GB,一次往后梳理, 在 最终的 F ull GC 事件运行时,堆内存使用量仅下降至约 31 GB,比第一次明显少 9 GB。 我们可以参考 图中的红色粗 箭 头线方向,明显 可 以看 到堆内存 使用量处于逐渐上升状态。 如果我们的应用程序在此环境中运行较长时间,可能是好几天,好几周甚至好几个月,那么后台日志将会抛 “OutOfMemoryError” 内存溢出问题,这个在日常的 Java 开发活动中最为常见的现象了。
接下来,我们再来看另外一组图形展示,具体如下所示:

基于此图形所展示,如果仔细查看图表,我们就会注意到:在上午 8 点左右开始发生持续 的 Full GC 事件 。与此同时,应用程序后台日志在上午 8:45 左右开始抛 OutOfMemoryError 相关异常。在早上 8 点左右,应用程序的 GC 吞吐率大约维持在 99% 左右。但是在早上 8 点之后,GC 吞吐率开始下降到 60% 左右。因为当持续进行 GC 事件时,应用程序不会处理任何客户事务,它只会执行 GC 活动事件。
因此,作为一种主动预防措施,如果我们发现 GC 吞吐量开始下降,那么可以从联机应用服务器集群中中移除存在 JVM 异常的应用服务,这样新的流量请求将不会打到 不健康的微服务上 。基于此种场景策略,我们将最大限度地减少对客户的影响。
> 3. 重缓存锯齿状
上面我们介绍了 2 种 规律性的 锯齿状图像的不同表现特性, 当应用程序在内存中缓存许多对象时,“GC” 事件将无法将堆内存使用率一直降低到图的底部(如之前我们在早期的“健康锯齿”模式中看到的那样)。
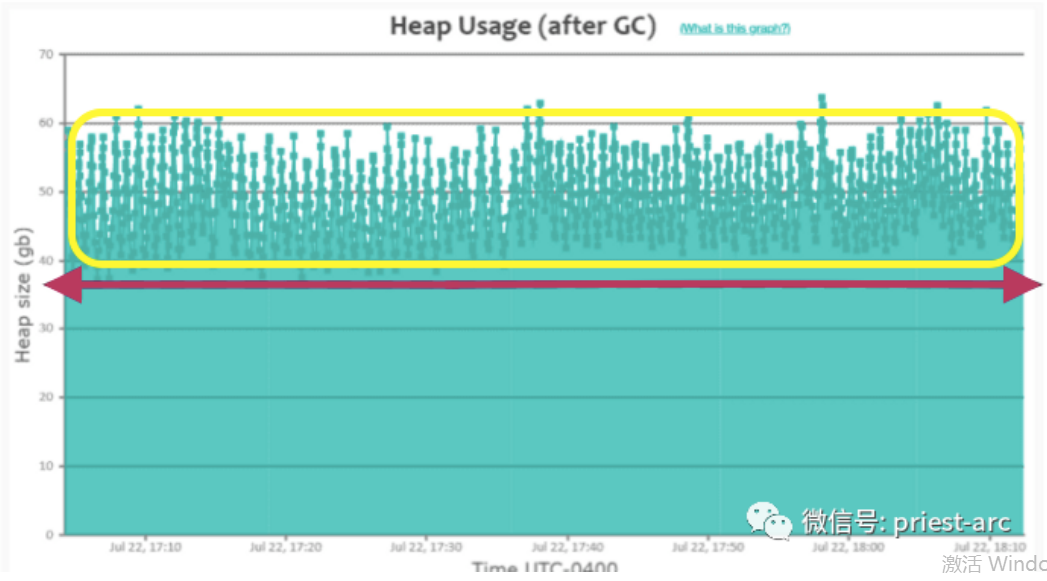
在上述图中,我们注意到堆内存使用量在不断增长,当达到约 60 GB 时,GC 事件(即图中显示为“绿色小方块”标识)即被触发。但是,这些 GC 事件无法将堆使用量降至之前所期望的约 38 GB 以下,如图中红色 粗 箭头线所标注。 相比之下,在早期的“健康锯齿模式”中,我们可以看到 堆 内存使用量一直下降到底部约 200 MB。 当我们看到这种模式时(即,堆使用率一直没有下降到底部),这表明应用程序正在内存中缓存大量对象。
当我们看到这种模式时,我们第一时间可能需要使借助堆转储分析工具(如 Haxxx.jar、HeapHero、Eclipse MAT 等)来追踪应用程序的堆内存使用情况,并确定是否需要在内存中缓存这么多对象。若这种现象频繁发生,我们可能需要调整缓存在内存中的不必要的对象。
> 4. 频繁 Full GC 锯齿状
在某些特定的场景中,比如,秒杀、抢购或发券等促销业务环境下,当业务的流量增长超过 应用程序 的处理能力极限时,可能会出现连续的 Full GC 事件发生,从而影响业务稳定性。

在上述监控示意图中,我们可以看到图中的黑色箭头标记。06 年 10 月 12:02 到 12:30,Full GC(即图中的“红色三角形”标识)连续运行。但是,在此时间段范围内,堆内存使用率并没有下降。这表明在该时间段内应用程序中的流量激增,因此应用程序开始生成更多对象,而垃圾收集无法跟上对象创建速度。因此,GC 事件开始连续运行。然而,需要关注的是,当一个 GC 事件运行时,往往伴随着其他潜在的风险,具体如下所示:
1、 CPU 消耗会很高(毕竟 GC 活动会进行大量 CPU 计算操作)。
2、 整个应用程序将被暂停,无法正常响应客户需求。
因此,在 06 年 10 月 12 点 02 分到下午 12 点 30 分的此段时间范围内,由于 GC 事件持续运行,应用程序的 CPU 消耗会一直处于暴涨状态,客户不会得到任何事务响应。当这种图形出现时,我们可能需要关注堆内存分配情况、代码逻辑处理以及资源配置优化等多方面要素。
> 5. 内存泄露锯齿状
与其他 GC 行为相对比而言,此场景堪称为一个“经典行为模式”,几乎所有的场景都会看到它的影子,尤其是应用程序运行过程中出现内存异常问题时。

在上述图中,我们注意到图中的黑色箭头标记,基于此,我们可以看到 Full GC(即图中的“红色三角形”标识)事件一直在持续运行。这种模式与之前的 “频繁 Full GC” 模式类似,但有一个明显的差异,即是:在 “频繁 Full GC” 模式中,一旦流量减少,应用程序能够将从重复的 Full GC 运行事件中恢复并返回到正常运行状态。但是,如果应用程序遇到内存泄漏,即使流量中断,它也不会恢复。那么,恢复应用程序的唯一的解决方案便是重新启动应用程序。如果应用程序处于这种状态,我们可以通过使用 Haxxx.jar、HeapHero、Eclipse MAT 等工具来诊断内存泄漏 。
基于上述相关场景的解析,其实,从另一角度,我们可以在生产环境中直接考虑启用应用程序的垃圾收集日志(GC Log),来观测及追踪 Java 虚拟机的垃圾收集行为,毕竟,基于此种策略, 不会给应用程序增加任何可衡量的资源开销,使得统计指标更为客观、准确。以上为不同 GC 行为的简要解析,大家在实际的开发活动中,若有其他场景案例,欢迎参与进来分享、探讨、互动。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3作者其他文章
评论 1 · 赞 0
评论 0 · 赞 1
评论 4 · 赞 2
评论 4 · 赞 1
评论 6 · 赞 1
添加新评论0 条评论