AIX万兆网卡性能测试与优化
陈炽卉
冯健
李松青
2019-12-15
导言
万兆网卡在当前数据中心环境中使用已经非常普遍。千兆网卡时代,通常网络的主要瓶颈是网卡带宽。而在万兆网卡时代,网络瓶颈往往是每秒钟处理包数,即Packets Per Second (PPS)。尤其是常见的OLTP负载,通常是小数据包为主,对于这类场景,在达到万兆网卡带宽瓶颈之前,往往可能已经达到PPS瓶颈了。
PPS瓶颈主要受限于目前TCP/IP协议栈的实现方式,根本性的优化方向主要是:
- 采用polling轮询机制代替中断机制进行数据包处理;
- 减少内核态操作,将网络数据包直接交付到应用层。
基于这两种优化思路目前市场上已经有一些技术和产品,但相对而言实施复杂度会有明显增加。
本文通过参数调优与测试,验证在 AIX 平台上万兆网卡的 Packets Per Second (PPS) 极限性能;预计完成优化后,能满足绝大多数业务负载对网络PPS的要求。从本案例中的测试结果看,#EN0S网卡在仅使用单万兆口的情况下,能达到至少280万 PPS的性能指标;在使用EtherChannel的情况下,能达到380 PPS。而#EN16网卡在仅使用单万兆口的情况下,能达到206万 PPS。
本文中的测试主要使用netperf工具完成。同时也使用某厂商的分布式应用进行了验证,得到的网络PPS指标与netperf基本一致。
测试环境
硬件配置:
Number Of Processors: 12
Processor Clock Speed: 4190 MHz
CPU Type: 64-bit
Kernel Type: 64-bit
LPAR Info: 3 netcli01.26.212
Memory Size: 81920 MB
Good Memory Size: 81920 MB
Platform Firmware level: SC860_056
Firmware Version: FW860.10 (SC860_056)
Console Login: enable
Auto Restart: true
Full Core: false
NX Crypto Acceleration: Capable and Enabled
网卡:
# lscfg -vpl ent1
ent1 U78CD.001.FZHC336-P1-C1-T1 PCIe2 4-Port Adapter (10GbE SFP+) (e4148a1614109304)
PCIe2 4-Port (10GbE SFP+ & 1GbE RJ45) Adapter:
FRU Number..................00E2715
EC Level....................D77452
Customer Card ID Number.....2CC3
Part Number.................00E2719
Feature Code/Marketing ID...EN0S
Serial Number...............Y250NY67FJUH
Manufacture ID..............98BE9468AB28
Network Address.............98BE9468AB28
ROM Level.(alterable).......30100150
Hardware Location Code......U78CD.001.FZHC336-P1-C1-T1
PLATFORM SPECIFIC
Name: ethernet
Node: ethernet@0
Device Type: network
Physical Location: U78CD.001.FZHC336-P1-C1-T1
共有 3 个客户端以及服务端(本机)采用 #EN0S 卡;还有 2 个客户端采用的 PCIe 一代卡,如下:
# lscfg -vpl ent0
ent0 U497B.001.DBJS863-P2-C8-T1 Int Multifunction Card w/ SR Optical 10GbE (a219100714100904)
Int Multifunction Card w/ SR Optical 10GbE:
Network Address.............E41F13D7595C
ROM Level.(alterable).......0400003260003
Hardware Location Code......U497B.001.DBJS863-P2-C8-T1
PLATFORM SPECIFIC
Name: ethernet
Node: ethernet@0
Device Type: network
Physical Location: U497B.001.DBJS863-P2-C8-T1测试拓扑为简单的 client/server 模式,共 211 、 213 、 215 、 222 、 223 五个客户端通过 netperf ,与 212 服务端(本机)的 netserver 通信。收发包大小均为 200 字节。
测试脚本:
#!/bin/ksh93
#
if [ $1 -gt 0 ]; then
THREAD=$1
else
THREAD=1
fi
n=0
while ((n<$THREAD))
do
nohup netperf -t TCP_RR -l 7200 -H 192.168.26.212 -- -r 200,200 &
((n++))
done网卡收发队列调整
网卡的接收队列(并发中断数)设置是非常关键的并发控制因素,此设置直接影响系统 kernel CPU 使用率与发包速率。
不同的万兆网卡支持的并发中断数不同,举 #EN0S 为例,最大支持的并发中断数 (queues_rx) 为 7 。
可以使用如下命令,将 #EN0S 收发队列均改为最大值 (7) 。
注意不同型号的网卡其收发队列属性名称、最大值也不同,可以通过 lsattr -Rl entX -a queues_rx 查询取值范围;此处的queues_rx应当替换为实际查询到的队列属性名。例如:
\#EN0S 网卡示例:
#lsattr -Rl ent0 -a queues_rx
1...7 (+1)
vnic 网卡示例:
注意,在 vnic 环境中队列数名称为 rx_que_num ,
#lsattr -Rl ent0 -a rx_que_num
1...16 (+1)修改:(注意需要针对物理网卡进行查询修改,而不是针对 EC 聚合网卡修改)
#chdev -l ent1 -a queues_rx=7 -a queues_tx=7查询:
# lsattr -El ent1|grep queues
queues_mgt 1 Requested number of management queues False
queues_rx 7 Requested number of Rx queues True
queues_tx 7 Requested number of Tx queues True绑定网卡中断
如果需要达到网卡极限性能,可以考虑进行中断绑定。中断绑定的方法如下。
查询网卡中断号
PCIe 一代卡或更早期的网卡的中断号可以直接通过 lsattr 查询到。而 PCIe 二代或以上网卡通常只在 lsattr 中显示基础中断号,实际运行环境中使用的中断号需要通过 entstat 查询。而且如果删除网卡重新配置的话,重配后使用的中断号可能会略有差异,需要注意相应调整绑定命令。
# lsattr -El entX
adapter_type ethernet Adapter Type False
alt_addr 0x000000000000 Alternate Ethernet address True
bar0 0xa3800000 Bus memory address 0 False
bar1 0xa3000000 Bus memory address 1 False
bar2 0xa4130000 Bus memory address 2 False
busintr 30752 Bus interrupt level False
…
#entstat -d
…
Assigned Interrupt Source Numbers:
30752 MGT
30753 NIC TX,RX
30754 NIC TX,RX
30755 NIC TX,RX
30756 NIC TX,RX
30757 NIC TX,RX
30758 NIC TX,RX
30759 NIC TX,RX
确定 CPU 逻辑号
# smtctl
This system is SMT capable.
This system supports up to 4 SMT threads per processor.
SMT is currently enabled.
SMT boot mode is not set.
SMT threads are bound to the same physical processor.
proc0 has 4 SMT threads.
Bind processor 0 is bound with proc0
Bind processor 1 is bound with proc0
Bind processor 2 is bound with proc0
Bind processor 3 is bound with proc0
proc4 has 4 SMT threads.
Bind processor 4 is bound with proc4
Bind processor 5 is bound with proc4
Bind processor 6 is bound with proc4
Bind processor 7 is bound with proc4
proc8 has 4 SMT threads.
Bind processor 8 is bound with proc8
Bind processor 9 is bound with proc8
Bind processor 10 is bound with proc8
Bind processor 11 is bound with proc8
...
绑定策略以及原则
- CPU 0 上不要绑中断,原因是在CPU 0进行中断绑定后,无法使用命令直接解除绑定;
建议使用每个物理 CPU 的第一个逻辑 CPU进行绑定,例如 4, 8, 12.. ( 当前为 SMT 4时)
bindintcpu 30753 4 #NIC TX,RX bindintcpu 30754 8 #NIC TX,RX bindintcpu 30755 12 #NIC TX,RX bindintcpu 30756 16 #NIC TX,RX bindintcpu 30757 20 #NIC TX,RX bindintcpu 30758 24 #NIC TX,RX bindintcpu 30759 28 #NIC TX,RX- 查看绑定结果
可以对相应中断号进行查询,例如30753号中断查询结果如下:
# bindintcpu -q 30753
Interrupt level 30753 is bound to cpu(s): 4
- 如何去除绑定
使用-u参数可以去除绑定:
# bindintcpu -u 30753
# bindintcpu -q 30753
Interrupt level 30753 is unbound- 查询中断统计
# vmstat -i
priority level type count module(handler)
0 2 hardware 35397 i_mpc_int_handler(2bd3b80.16)
0 589825 hardware 0 /usr/lib/drivers/planar_pal_chrp(4216248.16)
1 655360 hardware 0 /usr/lib/drivers/vconsdd(c01fd460.16)
3 30752 hardware 948 /usr/lib/drivers/pci/shientdd(47bf4f0.16)
3 30753 hardware 25891343 /usr/lib/drivers/pci/shientdd(47bf4f0.16)
3 30754 hardware 40320368 /usr/lib/drivers/pci/shientdd(47bf4f0.16)
3 30755 hardware 54025973 /usr/lib/drivers/pci/shientdd(47bf4f0.16)
3 30756 hardware 25172777 /usr/lib/drivers/pci/shientdd(47bf4f0.16)
3 30757 hardware 37041591 /usr/lib/drivers/pci/shientdd(47bf4f0.16)
3 30758 hardware 36470087 /usr/lib/drivers/pci/shientdd(47bf4f0.16)
3 30759 hardware 41979320 /usr/lib/drivers/pci/shientdd(47bf4f0.16)
3 655362 hardware 485284 /usr/lib/drivers/vioentdd(4510710.16)
3 655382 hardware 30709 /usr/lib/drivers/vscsi_initdd(c01589b0.16)
可以看到,网络中断主要发生在 30753~30759 共 7 个中断号上。
调整 schedo 参数
在 AIX 7.2 TL3 SP3 以及后续版本,调整 schedo 参数 krlock_enable ,可以防止 特定场景下 出现 锁争用 时 kernel 自旋 (spin) 过多。 此调整可以有效降低 kernel CPU 使用率, 7.2TL4 以后该调整已改为默认设置:
#schedo -p -o krlock_enable=1注意,该参数在更早的版本中也存在,但因为没有包含下面列出的补丁,不升级系统到7.2TL3SP3或后续版本就直接修改不会有效果。
如果按上文提高了网卡收发队列数,则此项参数强烈建议设置,否则可能造成系统CPU消耗上升。
相关补丁:
Fix krlock issues
IJ12449 latency on drw_lock_done by write owner
IJ12456 schedo changes for drw_lock_read krlock spin
RAS / tuning- around krlocks
IJ12451 splat not reporting krlock activity correctly
# schedo -h krlock_enable
Help for tunable krlock_enable:
Purpose:
krlock bitwise options
1-enabled(any other bit enables too)
2-limit to one owner
4-do not skip CPUs with pending interrupts
8-allow up to three shared owners
16-enable krlock spinning on DRW locks.
Values:
Default: 1
Range: 0 - 31
Type: Dynamic
Unit: numeric
Tuning:
This parameter is mutually exclusive with fast_locks.
考虑关闭 Spectre/Meltdown 补丁
根据 POWER8 的 rPerf 分值估算,Spectre/Meltdown补丁的性能影响大约是 5-7% ;但系统出现网络瓶颈,尤其是 PPS 极高的场景,影响可能超过此值。
由于 POWER9 各机型默认激活了该补丁,在网络瓶颈场景下性能影响可能会比较明显。建议在 ASMI 上关闭此 firmware 补丁(选红色框,即Speculative execution fully enabled),如下图 ( 注意该修改必须在下电的情况下才能进行 ) :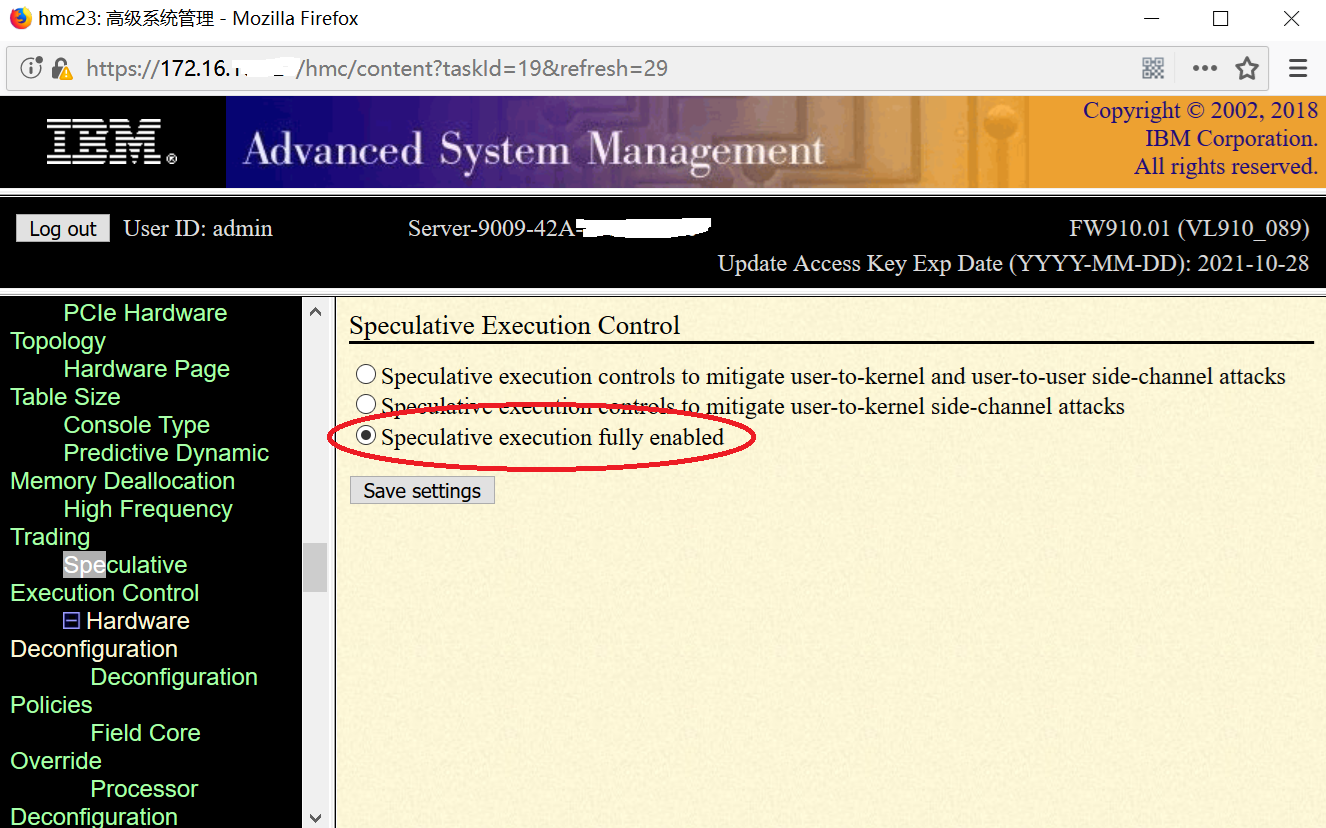
如果 firmware 不含有 Spectre/Meltdown 补丁,则 AIX 补丁不起作用;
AIX 7.2 环境,使用 lparstat –x 可以查看当前的预测执行安全级别;
# lparstat -x
LPAR Speculative Execution Mode : 0说明:
默认值为 2 ,表示同时 enable meltdown 和 spectre 补丁;
取值为 1 表示仅打开 meltdown 补丁;
取值为0表示不启用补丁(推荐值);
EtherChannel 配置兼容性建议
在 AIX 上建议的 EtherChannel 配置模式为 802.3ad, Hash Mode 采用 src_dst_port . 具体如下:
其他注意事项
- 网卡尽量放在系统节点上,使用性能较高的 PCIe 插槽,具体放置规则需要查看相关机型的红皮书以及 knowledge center ;
例如 E980 + EN0T :
https://www.ibm.com/support/knowledgecenter/9080-M9S/p9eab/p9eab_980_slot_details.htm
EN0T 的放置槽位优先级 :
从观察看 , EN0T 放置在 Slot 1 网络性能要优于 Slot 8.
- 网卡 PPS 极限性能对内存延迟敏感,因此分区规模不是越大越好,可以参考 K1 Power System 的 DPO功能对分区资源分布进行优化(相关文档请自行搜索K1 Power DPO 手册) ;
- 许多用户习惯性在 AIX 主机上设置 no 参数 tcp_nodelayack=1, 这样将使得 AIX 主机对所有收到的包马上回送一个消息体为空的 ACK 应答;这种做法通常只有性能损失而没有收益,只在少部分存在异构系统兼容性问题时可能有帮助。
在正常的 OLTP TCP 通信场景中, Request/Response 通常是成对出现的,因此 ACK 应答通常可以捎带在 Response 消息中(称之为 piggybacked ACK ),而不必单独发送,这样可以提高有效数据包的比例。因此,请确保 tcp_nodelayack 取值为 0 ,即:
#no -p -d tcp_nodelayack在 tcp_nodelayack 取值为 0 的情况下,系统会尽量尝试在正常的数据包 ( 业务回包 ) 中捎带 ACK 应答;如果短时间没有业务回包,则最长不超过 200 毫秒(由系统 fast timer 控制,可以通过 no 参数调整),系统会主动回复 ACK.
测试数据
EN0S 网卡性能测试结果
测试客户端 211 、 213 、 215 与测试服务端(本机) 212 分区 CPU 与网卡配置基本相同,各启动 100 个 netperf 实例;
测试客户端 222 、 223 为 16C 780C 分区 +PCIe 一代网卡,各启动 60 个 netperf 实例;
客户端与服务端各网卡收发队列均调整至最大值,网卡中断绑定、 affinity 调整均调整完毕的情况下,最终性能如下: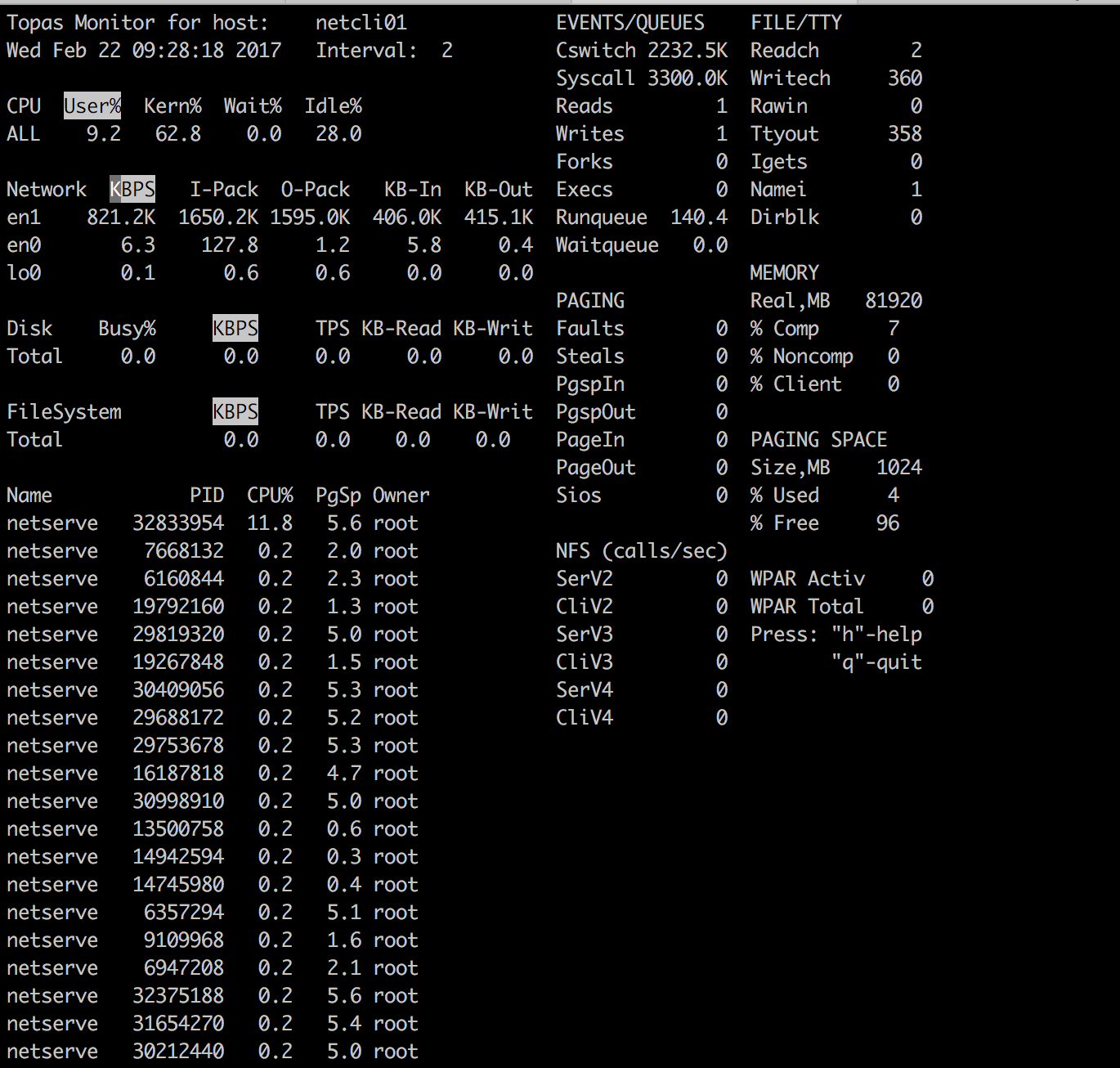
netstat 统计结果: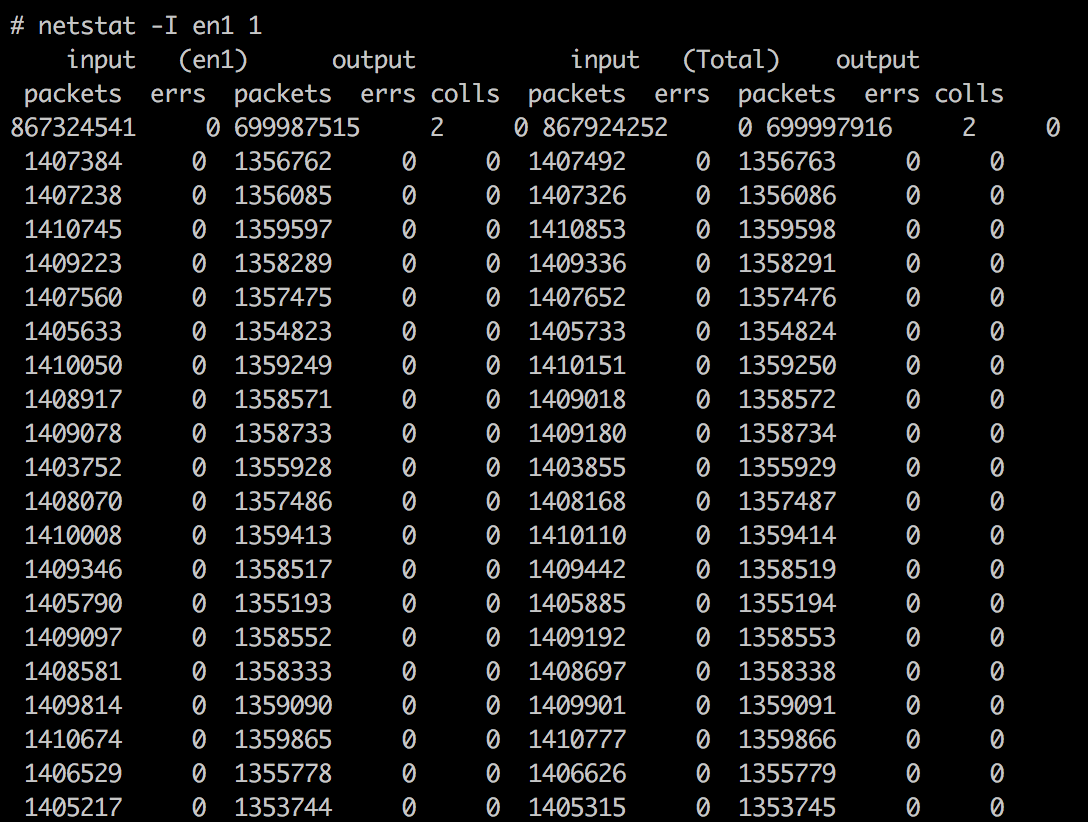
nmon 统计结果 :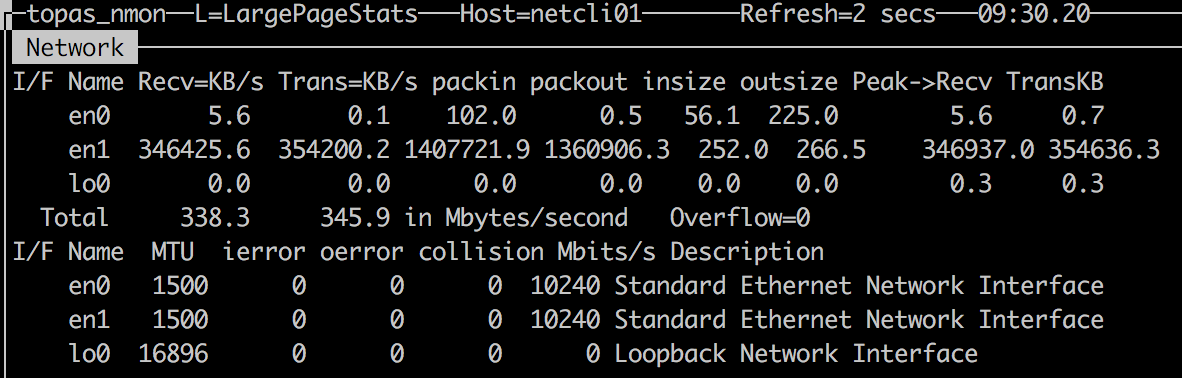
统计结果说明
由于统计工具不同,在系统压力极大的情况下,命令响应时间受到了一定影响,统计数据有少许偏差。其中 topas 统计结果偏大,为 320 万 PPS ;而 netstat 与 nmon 统计结果接近,为 280 万 PPS 。
统计结果的差异与统计命令实际采用的时间间隔精度有关, topas 最为常用,但 netstat 与 nmon 的结果应该更接近实际值。
EN16 网卡性能测试结果
使用 EN16 网卡之后性能为 200 万 PPS 。数据如下: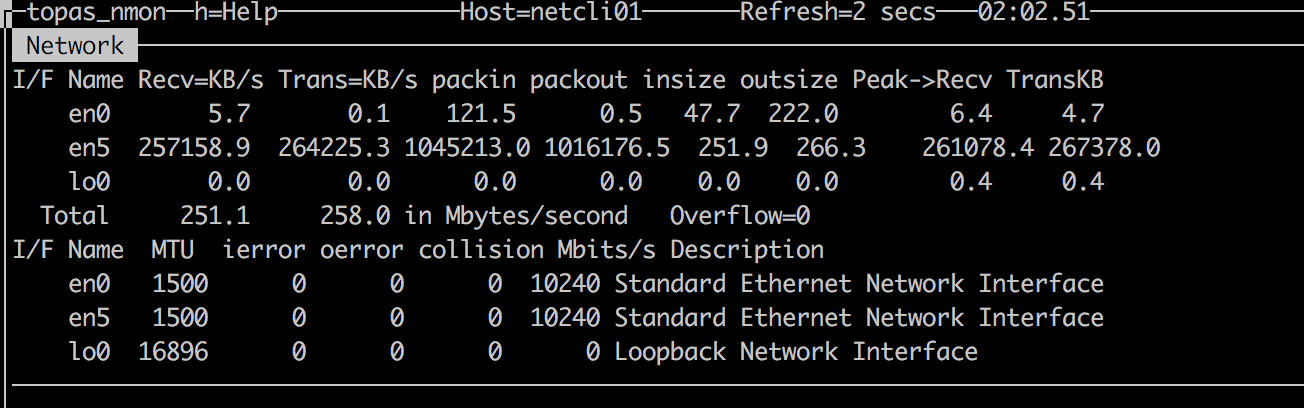
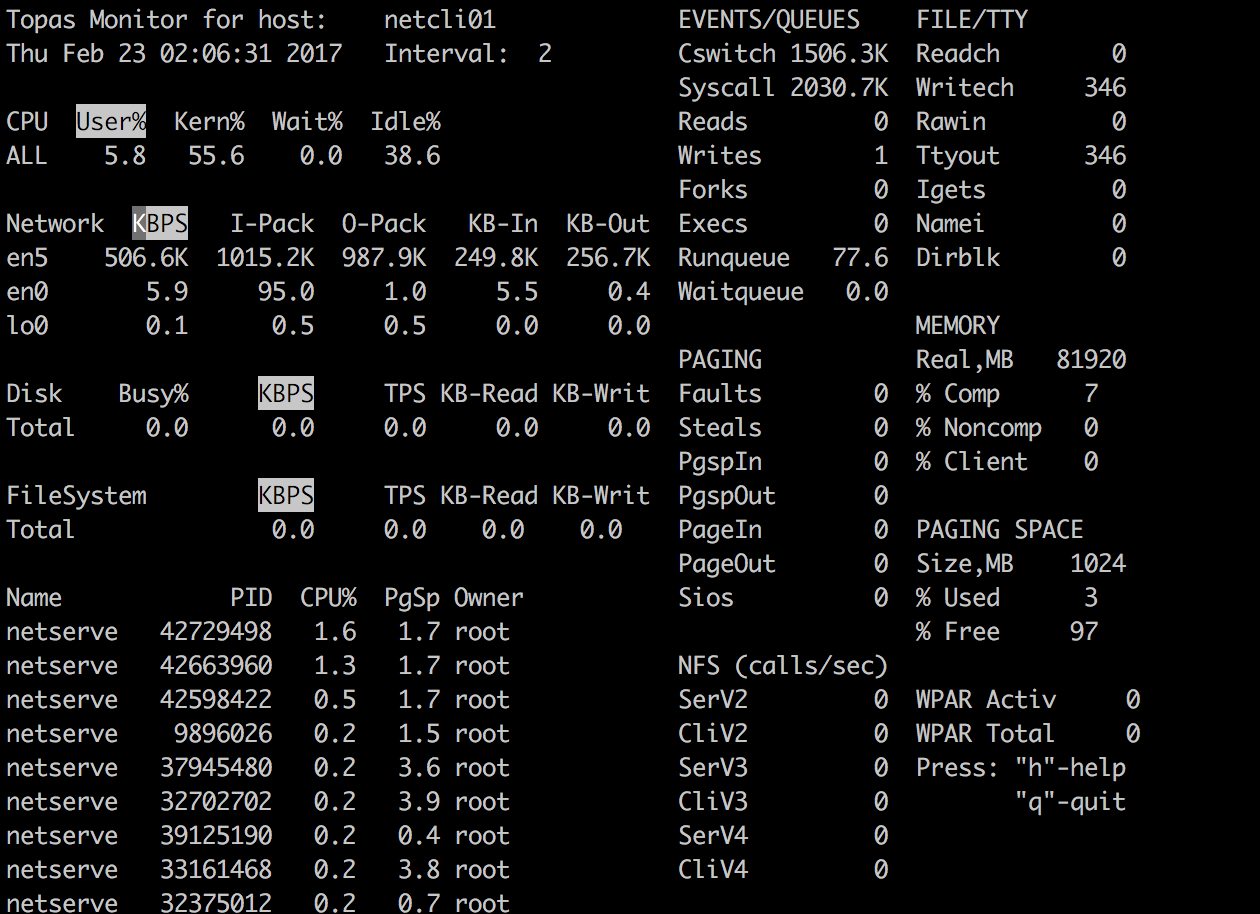
本测试中系统尚有一定空余 CPU , topas 、 nmon 响应都正常,统计数据接近。
附录
使用某厂家的分布式应用对 #EN0S 的场景进行了验证,得到了类似 netperf 的 PPS 极限值: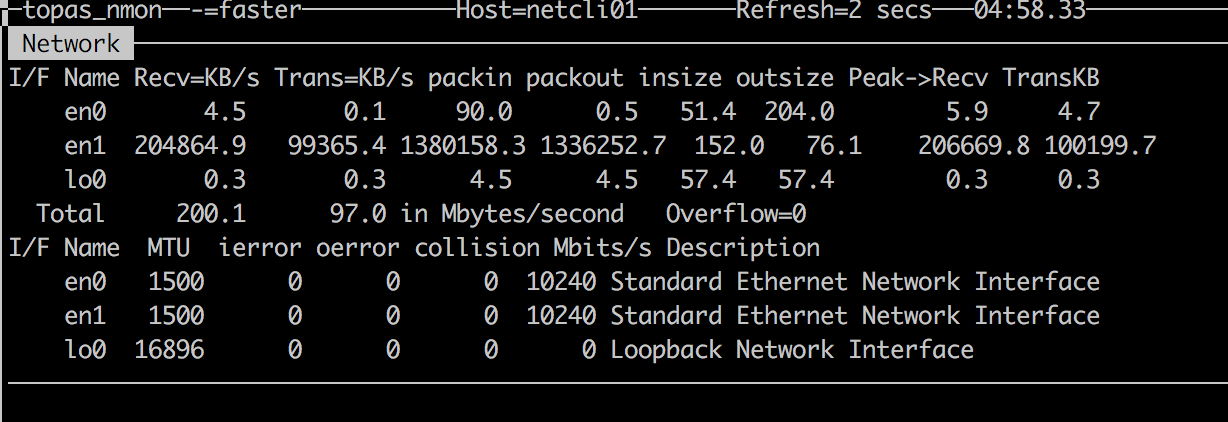
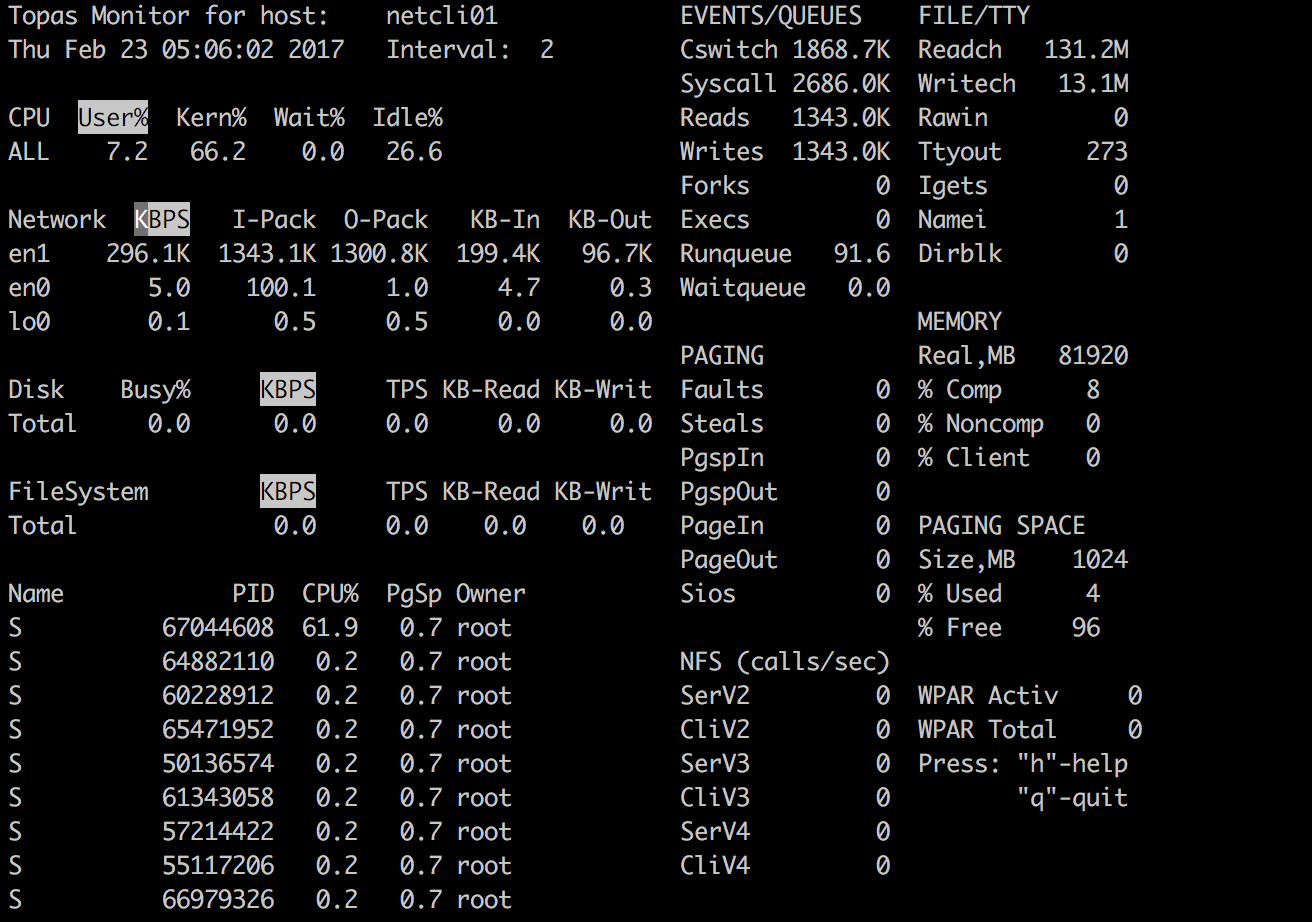
2019 年 12 月 update
在 POWER9环境上搭建环境进行了类似测试, 2 个 EN0S 做 Etherchannel,测试结果为380 万 PPS :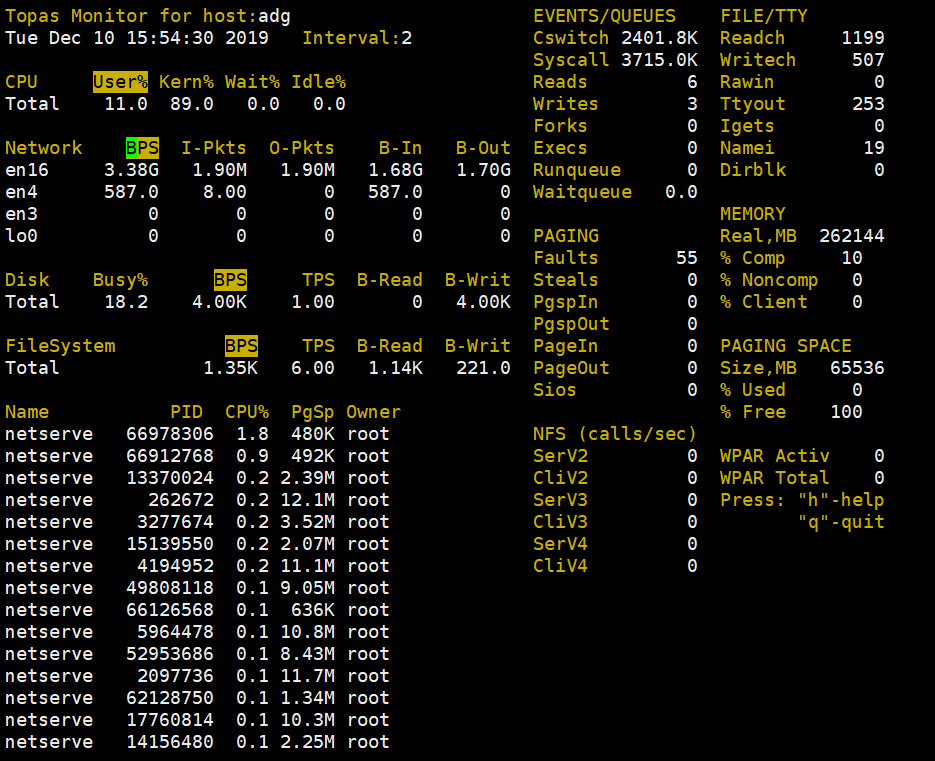
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞5作者其他文章
评论 1 · 赞 6
评论 0 · 赞 0
评论 0 · 赞 1
评论 0 · 赞 2
评论 0 · 赞 3
添加新评论0 条评论