用匠心精神,打造高可用分布式系统
1 引言
一切的一切,始于一场战争。
1.1 夜王之死,论高可用的重要性
《权利的游戏》第八季今年 ( 捂脸,这文章拖得时间太久了,这都 2020 年了 …) 终于开播,让众多权游迷大跌眼镜的是,从第一季辛辛苦苦走了八季来到我们面前的夜王,刚出场一集就被二丫杀死,成功获得年度最悲催男人的封号。
夜王虽然死了,我们可爱的、看热闹不怕事大的程序猿却进行了积极的思考,一篇《夜王一死,异鬼咋就团灭?这是个严肃的科学问题》的文章瞬间在工程师中间开始流传。文章中深入浅出的分析了夜王与其所控制的异鬼与冰龙之间的关系,并与人类军队进行了对比,最终得出了一个重要的结论:
临冬城之战,实际上是一场“中心化系统”和“非中心化系统”之间的战斗。
夜王与其控制的异鬼军团,是一个“中心化系统”,“中心化系统”尽管非常强大,但是它只要失败一次,就永远玩完;“去中心化系统”可以屡败屡战,星火不灭总可燎原。
如果这次夜王不死,他应该将自己升级为一个高可用系统,再来统一整个维斯特洛大陆。 **
1.2 挖掘机,高可用杀手
夜王刚死不久,挖掘机再次闪亮登场。 2019 年 6 月 2 日凌晨,某云数据中心光缆被挖断,托管在其上的众多应用无法提供服务,其中大家喜闻乐见某英语学习 APP 也无法正常使用,为我们辛苦的中国小朋友献上儿童节贺礼:终于可以休息休息,不用再上课。
1.3 做了异地多活,系统就可用了吗?
生命诚可贵,系统价更高。历经无数次开发变更、再开发再变更,经历九九八十一难建设好的系统,难道真的就对一个挖掘机束手无策吗?
非也、非也!方案总比问题多,使用在金融行业多年的两地三中心、流行于互联网的异地多活方案,为我们指明了方向。
1.3.1 异地多活架构
下图是蚂蚁金服 2019 年在互联网大会上分享的三地五中心架构,它已经不是一个多中心之间互相做灾备的架构,而是一个多地多中心多活的架构。 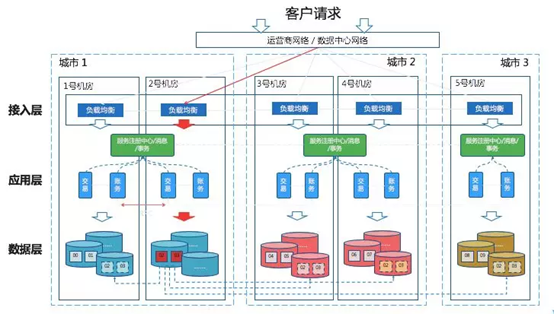
(图片来源于网络)
在多活架构情况下,实际上可以做到在不同的中心之间任意的去划拨用户的流量。 在2018年的云栖大会上蚂蚁金服副CTO胡喜在ATEC主论坛现场模拟挖断支付宝近一半服务器的光缆。结果只用了26秒,模拟环境中的支付宝就完全恢复了正常。 --《蚂蚁金服资深总监韩鸿源:像使用集中式数据库一样使用OceanBase分布式数据库》
1.3.2 架构是万能的吗?
那么,采用了先进的异地多活架构、在部署层面做了各种高可用,我们的系统就可以高枕无忧、做到 7*24 小时无间断运行吗?
理想与现实总是有差距:没有架构是不行的,但架构也不是万能的。
以下是一个真是的案例:
现象:某网站的前置网关应用突然故障,处理请求的线程池用满,无法再接收新的服务请求;网关应用其他指标均正常;
原因:该网关应用负责代理后台微服务应用请求,新上线的一个后台服务存在响应缓慢故障;网关线程池逐渐都被该故障服务请求转发占满,导致无法响应用户请求;
紧急处理方式:停止对故障应用的请求转发,重启网关应用集群,恢复服务。
其实,在微服务体系下,如果实现引入了服务熔断机制,就会更加优雅和有效避免在外调失败时,对自己的系统造成不良影响,避免级联失败。
2 方法论
2.1 高可用定义
首先先看一下维基百科对高可用性的定义:
高可用性(英语:high availability,缩写为 HA),IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度。是进行系统设计时的准则之一。高可用性系统与构成该系统的各个组件相比可以更长时间运行。
我们经常用几个 9 来评判一个系统的可用性是否足够高,下表是可用性与系统一年中不可用时间的对应关系。
| 可用性 | 年故障时间 | |
| 2个9 | 99% | 3天15小时36分 |
| 3个9 | 99.9% | 8小时46分 |
| 4个9 | 99.99% | 52分34秒 |
| 5个9 | 99.999% | 5分15秒 |
| 6个9 | 99.9999% | 32秒 |
2.2 高可用系统 PDCA 环
那么,有没有一种行之有效的方法,能帮我们打造一个高可用的分布式系统呢?
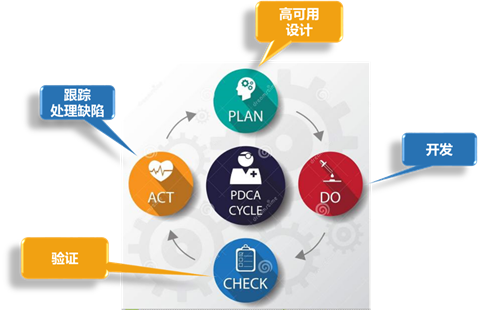
笔者通过对行业领先者先进实践的研究,得出如下切实可行的方法,称之为“高可用系统 PDCA 环”。“ PDCA ”戴明环在包括项目管理等多个领域有着广泛的应用,同样可以指导我们打造高可用分布式系统。
整个“高可用系统 PDCA 环”包括如下四部分:
Plan :对分布式系统进行高可用设计,参考业内成熟的设计模式、先进实践进行高可用设计;
Do :对设计进行落地,开发出可运行的分布式系统;:
Check :对系统进行测试验证,检验系统的可用性。目前业内也有了验证系统可用性的一套方法和工程实践(混沌工程),可以借鉴采用;
Action :对测试验证中发现的缺陷进行跟踪处理,再次出发高可用设计,循环迭代提升系统的可用性。
本文后续部分将重点针对分布式系统的高可用设计和验证展开阐述。
3 设计一个高可用分布式系统
3.1 互联网场景下高可用面临的挑战
互联网场景往往面对海量用户,从而带来了两个海量问题:海量数据、海量并发。
海量数据:海量用户带来了海量的数据,数据的存储与访问都面临着巨大的压力。对于传统的单一数据库或者单一数据库集群(数据库主从部署,支持读写分离等),都面临着达到硬件处理能力瓶颈,数据访问缓慢甚至不可用,导致整个系统可用性出现问题;
海量并发:高并发带来对系统处理性能的更高要求,能够在并发压力的不断增加下保持稳定的响应时间,对于高可用至关重要;没有经过精心设计的系统,响应时间会随着并发的增大急剧变长,从而导致系统处理能力急剧下降,影响系统的高可用。
3.2 弹性系统提供无线扩容能力
3.2.1 基于应用和数据分布式提供系统弹性能力
我们谈一个系统的高可用性,往往会谈到系统的弹性伸缩,《 The art of scalability 》一书中,提出了一个系统扩展模型( scale cube ),描述了分布式系统弹性扩展的三个维度:
X 轴:代表运行多个负载均衡器之后运行的实例,即通过应用服务器集群提供系统的处理能力和可用性,但数据库层面不支持水平扩展;
Y 轴:应用功能分解,将应用层和数据模型层的垂直切分,实现微服务架构。各应用可以独立的进行水平扩展,单一应用内部数据库层面仍然无法实现水平扩展;
Z 轴:数据分片,对应用内的数据进行分库分表,实现数据库层面的水平扩展。
这三个维度的划分,在一定意义上也代表了一个单体系统向分布式系统演进的一个路径:
第一阶段:单体应用,通过应用服务器集群来提高系统的可用性,支持应用层级的弹性扩展。但是,随着数据量的不断增大,开发人员已经使用了缓存、读写分离等策略,仍然会达到单一数据库集群处理能力瓶颈,无论再怎么增加应用服务器都无法提高系统的处理能力,这是系统往往会演进到第二阶段;
第二阶段:微服务应用,应用和数据库按照业务领域独立部署,形成多个微服务应用集群。该阶段一定程度上缓解了系统压力,能够提供更好的性能;同时,各微服务应用之间相互独立部署,在交付周期和故障隔离方面能够提供更高的灵活性。但是,每个微服务应用由于还是使用单一数据集群,在系统的容量、高并发等方面,存在着无法逾越的瓶颈;
第三阶段:数据分布式,领域数据库进行分库分表或者读写分离,在数据库层面提供水平扩展能力。基于数据的分布式,可以有效的解决数据库瓶颈问题,让系统处理能力形成进步一的提升;但是,面对数据库连接数限制的问题,在扩展到一定规模之后,单纯的分库分表或读写分离也会遇到扩容瓶颈,这时候就需要逻辑数据中心( LDC )闪亮登场了。
3.2.2 基于逻辑数据中心( LDC )实现数据库无限扩展
通过采用逻辑数据中心架构,可以实现分布式系统容量的无线扩容,同时保持恒定的交易响应时间。
逻辑数据中心的含义是:对物理数据中心进行逻辑上的划分,每个逻辑数据中心相互独立;每个逻辑数据中心部署相同的应用,但应用数据库通过分库分表之后均匀分布在每个逻辑数据中心中;每个客户交易请求只会在一个逻辑数据中心内处理。由于每个逻辑数据中心里可以稳定支撑固定数量的客户交易请求,当系统容量达到上限时,可以通过增加新的逻辑分区实现系统容量的提升,满足更大的数据量、更高的并发量。
以同城两个数据中心为例,每个数据中心再在逻辑上划分为两个数据中心,这样我们就有 4 个逻辑数据中心,这样我们就得到一个典型的基于逻辑数据中心的同城双活架构图: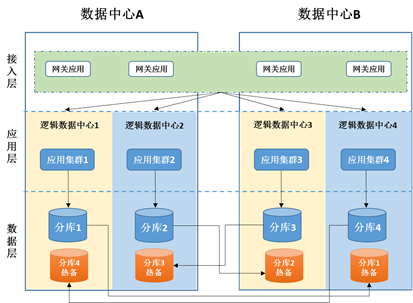
从横向上来看,该架构主要包含了以下几层:
接入层:该层横跨两个数据中心,部署路由应用,负责服务请求的分发。网关应用通过解析服务请求报文,根据路由规则确定该请求该路由至哪个逻辑数据中心;
应用层:每个逻辑数据中心部署相同的核心应用集群,每个集群只连接本逻辑数据中心的数据库;
数据层:对数据按客户进行分库分表处理,平均分为 4 份;每个逻辑数据中心只存储其中的 1 份。最终在物理部署上,可以在逻辑数据中心之间进行跨机房热备,进行数据库层面高可用部署。
从纵向来看,每个分区单元都是独立自包含的,按照分区规则服务固定的客户;当某个分区出现故障时,只有该分区的客户交易会受到影响,其它分区可以正常工作,这也在一定程度上提高了系统的可用性和业务连续性。
3.3 从弹性到韧性,提供自愈能力
高可用 IT 系统,我们希望它具有良好的韧性,通俗讲就是具有鲁棒性,而非一碰就倒的花瓶、需要精心维护。
3.3.1 面向高可用的两个设计原则
设计一个韧性的系统,通常遵循以下两方面的设计原则:
面向失败设计:充分考虑分布式微服务架构下会存在的各类故障,针对故障进行针对性的设计;进行故障测试,系统是否具备应对故障的能力。这样,当故障真正发生时,才能从容应对,避免造成严重影响;
面向恢复设计:充分考虑系统中应用节点出现宕机等不可用情况时,能够及时发现并自动恢复。这里讲的恢复既包括集群中应用节点宕机之后的重新启动,也包括对宕机应用处理中的业务的自动恢复。
3.3.2 面向失败设计
应用运行中会遇到各种各样不可预期的故障,从大的设计方向来说,可以分为单点故障和级联故障(中间件和数据库的高可用方案不在本次讨论范围)。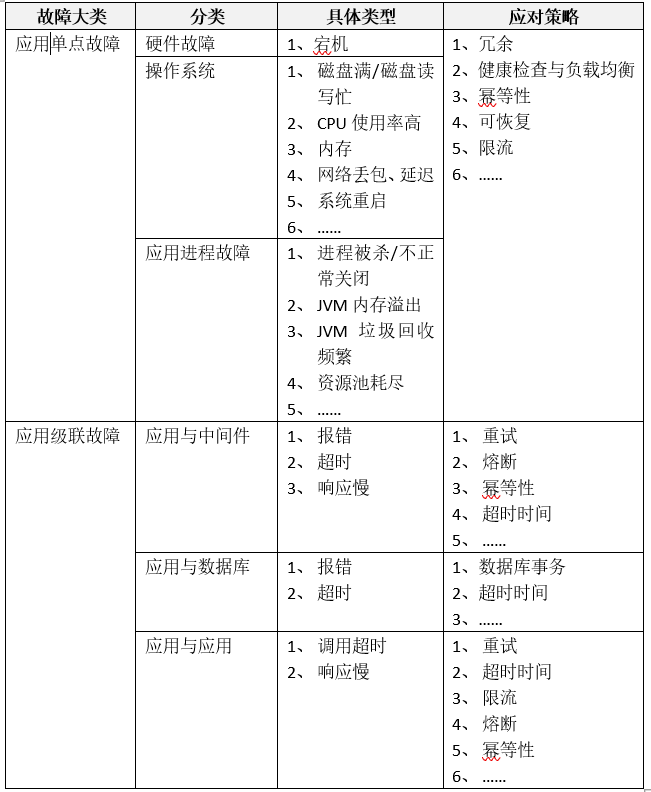
针对分布式架构几类有效的面向失败设计方法,主要包括以下几点:
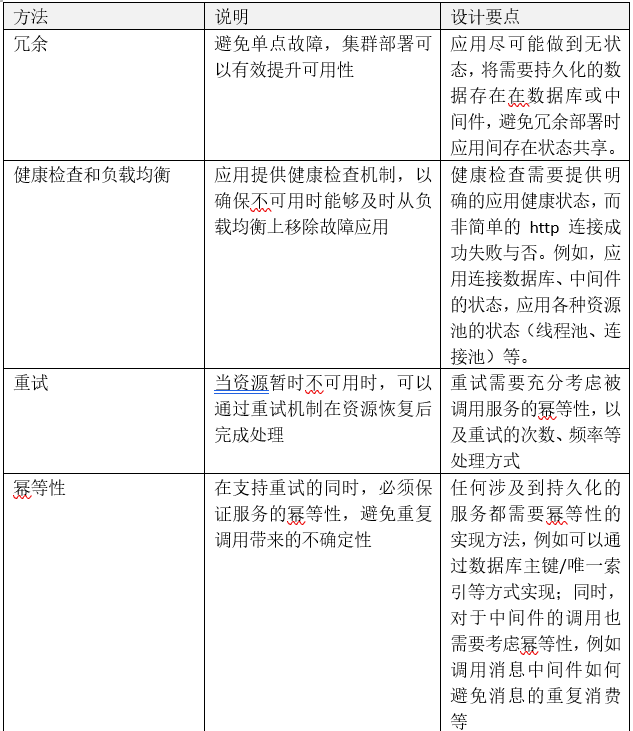
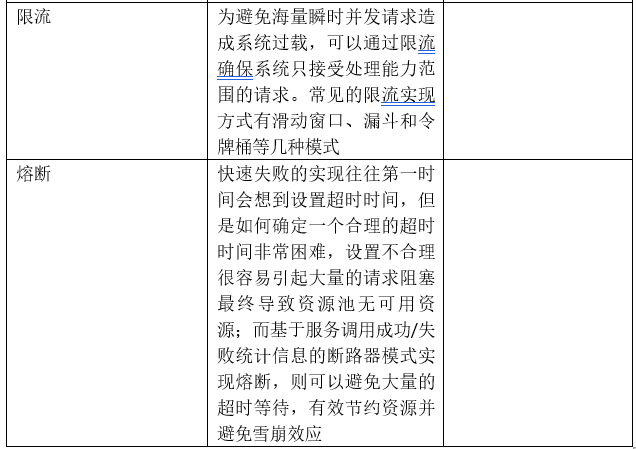
3.3.3 面向恢复设计
虽然进行了针对性的面向失败设计,但是故障是不可避免的。在分布式环境下,存在着大量的远程调用和分布式事务,任何一个节点的故障都会带来连锁反映。在进行应用设计、各种组件设计时,通过考虑自动恢复设计可以为系统提供自愈能力,从而更好提高系统可用性。
有以下几类场景,可以帮助我们更好的理解自动恢复的必要性:
应用存在分布式事务:例如一个业务处理过程中,需要调用数据库创建订单,同时需要调用消息中间件创建物流消息。在不使用传统 XA 事务机制的方式下,如何保证应用宕机时,创建成功订单、未发送的消息最终能够发送成功;
应用存在主从调度机制:应用集群中的主节点负责调度,其他节点作为从节点被调度负责具体任务的执行。主节点故障时,如何自动恢复寻找新的主节点继续进行调度;从节点故障时,如何接管正在该节点执行的任务;
数据库采用主从模式部署:例如 mysql 主从部署,主节点故障时如何自动切换到从节点。
如何实现自动恢复,涉及到以下两个关键点:
故障自动感知 :自动识别故障节点或应用。例如,对于分布式事务,需要能够识别出已经中断的事务(而非执行中的事务);主从调度类应用,能够自动识别出主从节点的可用性;对于主从模式数据库,能够及时识别主库是否可以正常提供服务;
故障自动恢复 :自动对发生的故障进行恢复。例如,对于分布式事务,自动按照预设的模式进行补偿或回滚;主从调度类应用,主节点自动选择新的主节点并接管调度,从节点故障由新从节点自动接管其未完成任务;对于主从模式数据库,自动进行切换让从节点变为主节点继续提供服务。
针对两个关键点,应用系统运行过程中其实必须要提供两种角色:故障识别角色与故障恢复角色。两种角色可以是由同一个技术组件实现,也可以是独立的实现;物理部署上可以是独立于应用外部署的管理角色,也可以让应用集群中的任意应用节点具备这两种角色。
3.3.4 实际案例
3.3.4.1 MQ 消息发送与消费高可用
3.3.4.1.1 业务场景需求
之前到一个业务场景,订单应用调用数据库创建订单的同时,需要调用消息中间件创建物流消息;物流应用对消息消费以生成物流单。该场景的高可用有以下两方面的要求:
² 数据库订单创建成功,物流消息必须通过 MQ 发送成功;
² 物流消息的消费,有且只能有一次,避免重复消费。
在设计过程中,需要充分考虑面向故障与恢复设计,例如订单应用节点宕机、消息服务器不可用、物流应用节点宕机等各种故障可能性。
3.3.4.1.2 高可用方案
为了确保消息发送与消费的高可用,需要用到面向故障设计里的“数据库事务”、“重试”与“幂等性”等方法。
方案中 MQ (消息)客户端有两个角色:“ MQ 发送客户端”和“ MQ 消费客户端”;具体实现方式可参考下图。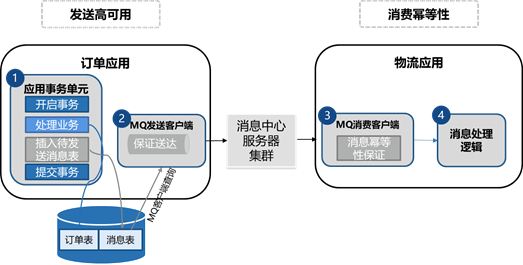
消息发送高可用设计关键点,是采用“共享事务设计模式”和“重试”,确保消息一定发送成功:
- 在订单创建的数据库事务中,同时往附加“消息表”中插入一条“待发送消息”记录;
- 数据库事务完成后, MQ 发送客户端会读取到“消息表”中的“待发送消息”,发送给 MQ 之后修改状态为“已发送”;
- “ MQ 发送客户端”可以与“订单应用”打包部署,也可以独立部署;打包部署的好处是当一个“订单应用”宕机之后,集群中的其它应用中的“ MQ 发送客户端”同样可以完成消息的发送;独立部署则需要实现“ MQ 发送客户端”的集群高可用。
消息消费高可用设计关键点,是采用“幂等性”确保消息消费不会重复:
- 在进行消息消费时,需要基于“幂等性”确保消息消费且只消费一次,避免重复消费带来的不可预期问题;
- 具体实现方式可以通过“消息消费表”使用“消息 ID ”作为主键,每次消费消息前先往该表中插入一条记录来实现幂等性。如果消息消费成功了,回调 MQ 消息中心失败该如何处理呢?各位同学可以自己想想,解决起来也不难。
3.3.4.2 K8s 副本机制
我们再看一个大家都很熟悉的高可用案例—— K8s 中通过副本机制 (replication controller) ,确保应用 Pod 崩溃时能够自动恢复,确保维持预设数量以提供足够的系统处理能力。
在 k8s 中, Controller 担当了故障识别与恢复的角色。
回到面向恢复设计的两个关键点:故障自动感知、故障自动恢复,简单探究一下 K8s 是怎么实现的。
3.3.4.2.1 故障自动感知
k8s 通过 liveness (存活探针)来确定 Pod 是否还可提供服务,如果探活结果最终判定是失败,则会重启容器。需要注意的是,故障结果的判定是通过多次探活失败来确定的,不能通过一次简单的探活失败就认为 Pod 故障,否则极易受网络延时、闪断等因素影响。
Liveness 探针的一个简单示例如下:
livenessProbe:
httpGet:
path: /health
port: 8080
httpHeaders:
- name: X-Custom-Header
value: up
initialDelaySeconds: 3
periodSeconds: 3
livenessProbe 指定 kubelete 需要每隔 3 秒执行一次 liveness probe 。 initialDelaySeconds 指定 kubelet 在该执行第一次探测之前需要等待 3 秒钟。该探针将向容器中的 server 的 8080 端口发送一个 HTTP GET 请求。如果 server 的 /health 路径的 handler 返回一个成功的返回码, kubelet 就会认定该容器是活着的并且很健康。如果返回失败的返回码, kubelet 将杀掉该容器并重启它。
LivenessProbe 还有很多参数用于帮助确定故障发生,例如 timeoutSeconds , successThreshold , failureThreshold 等,在此就不展开描述了。
3.3.4.2.2 故障自动恢复
在 k8s 中,通过各种类型的 Controller 来确保 Pod 始终维持预设的数量,从而实现自动恢复。
以 Deployment 类型的 Controller 为例,一个典型的定义方式如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
示例代码中,定义了一个 nginx 应用的部署,“ replicas: 3 ”明确描述了 nginx 集群的 pod 数量需要维持 3 个。当集群中的一个 pod 发生故障( liveness 检查失败), Controller 会销毁故障的 pod ,重新创建一个新的 nginx 应用 pod 。
3.3.4.3 Mysql 基于 MHA 的高可用
MHA ( Master HA )是一款开源的 MySQL 的高可用程序,它为 MySQL 主从复制架构提供了 automating master failover 功能。 MHA 在监控到 master 节点故障时,会提升其中拥有最新数据的 slave 节点成为新的 master 节点,在此期间, MHA 会通过于其它从节点获取额外信息来避免一致性方面的问题。 MHA 还提供了 master 节点的在线切换功能,即按需切换 master/slave 节点。
3.3.4.3.1 MHA 角色
MHA 服务有两种角色, MHA Manager( 管理节点 ) 和 MHA Node( 数据节点 ) :
MHA Manager :通常单独部署在一台独立机器上管理多个 master/slave 集群 ( 组 ) ,每个 master/slave 集群称作一个 application ,用来管理统筹整个集群。
MHA node :运行在每台 MySQL 服务器上 (master/slave) ,它通过监控具备解析和清理 logs 功能的脚本来加快故障转移。主要是接收管理节点所发出指令的代理,代理需要运行在每一个 mysql 节点上。简单讲 node 就是用来收集从节点服务器上所生成的 bin-log 。对比打算提升为新的主节点之上的从节点的是否拥有并完成操作,如果没有发给新主节点在本地应用后提升为主节点。
3.3.4.3.2 高可用原理
MySQL 复制集群中的 master 故障时, MHA 按如下步骤进行故障转移:
- 从宕机崩溃的 master 保存二进制日志事件 (binlogevents) 。
- 识别含有最新更新的 slave 。
- 应用差异的中继日志 (relay log) 到其它 slave 。
- 应用从 master 保存的二进制日志事件 (binlogevents) 。
- 提升一个 slave 为新 master 。
- 使其它的 slave 连接新的 master 进行复制。
4 验证分布式系统的可用性
到目前为止,我们的分布式系统已经完成优秀的设计和开发,进入到了 PDCA 环的 Check (验证)环节。如何对一个系统的可用性进行验证,目前主流的思路和技术方向是逐渐流行起来的混沌工程,众多大厂都纷纷在谈自己的混沌工程实践,也有很多优秀的开源软件(如 chaosblade )可以供我们使用。如何使用混沌工程来验证我们系统的可用性,是我们本节要讨论的内容。
4.1 混沌工程定义与起源
混沌工程是在分布式系统上进行实验的学科 , 目的是建立对系统抵御生产环境中失控条件的能力以及信心。
这里边有一个关键字 —— “实验”。混沌工程围绕“实验”展开:通过有计划的实验发现系统的故障点,观测故障发生时系统的表现,针对故障点进行修复或提供应急预案,避免在故障出现时系统崩溃,从而提升系统韧性,提升对系统可用性的信息。
混沌工程在 2019 年突然火了起来,然而,混沌工程的起源可以追溯到 2008 年,以下为混沌工程在 Netflix 的发展历史:
2008 年 8 月, Netflix 主要数据库的故障导致了三天的停机, DVD 租赁业务中断,多个国家的大量用户受此影响。之后 Netflix 工程师着手寻找替代架构,并在 2011 年起,逐步将系统迁移到 AWS 上,运行基于微服务的新型分布式架构。这种架构消除了单点故障,但也引入了新的复杂性类型,需要更加可靠和容错的系统。为此, Netflix 工程师创建了 Chaos Monkey ,会随机终止在生产环境中运行的 EC2 实例。工程师可以快速了解他们正在构建的服务是否健壮,有足够的弹性,可以容忍计划外的故障。至此,混沌工程开始兴起;
2010 年 Netflix 内部开发了 AWS 云上随机终止 EC2 实例的混沌实验工具: Chaos Monkey ;
2011 年 Netflix release 了其猴子军团工具集: Simian Army ;
2012 年 Netflix 向社区开源由 Java 构建 Simian Army ,其中包括 Chaos Monkey V1 版本;
2014 年 Netflix 开始正式公开招聘 Chaos Engineer ;
2014 年 Netflix 提出了故障注入测试( FIT ),利用微服务架构的特性,控制混沌实验的爆炸半径;
2015 年 Netflix release 了 Chaos Kong ,模拟 AWS 区域( Region )中断的场景;
2015 年 Netflix 和社区正式提出混沌工程的指导思想 – Principles of Chaos Engineering
2016 年 Kolton Andrus (前 Netflix 和 Amazon Chaos Engineer )创立了 Gremlin ,正式将混沌实验工具商用化;
2017 年 Netflix 开源 Chaos Monkey 由 Golang 重构的 V2 版本,必须集成 CD 工具 Spinnaker (持续发布平台)来使用;
2017 年 Netflix release 了 ChAP ( Chaos Automation Platform, 混沌实验自动平台),可视为应用故障注入测试( FIT )的加强版;
2017 年 由 Netflix 前混沌工程师撰写的新书“混沌工程”在网上出版;
2017 年 Russell Miles 创立了 ChaosIQ 公司,并开源了 chaostoolkit 混沌实验框架。

而在 2019 年,阿里开源了自己的混沌工程工具( ChaosBlade ),让我们可以看到混沌工程在阿里内部的发展史:
EOS ( 2012-2015 ):故障演练平台的早期版本,故障注入能力通过字节码增强方式实现,模拟常见的 RPC 故障,解决微服务的强弱依赖治理问题。
MonkeyKing ( 2016-2018 ):故障演练平台的升级版本,丰富了故障场景(如:资源、容器层场景),开始在生产环境进行一些规模化的演练。
AHAS ( 2018.9- 至今):阿里云应用高可用服务,内置演练平台的全部功能,支持可编排演练、演练插件扩展等能力,并整合了架构感知和限流降级的功能。
ChaosBlade ( 2019.3 ):是 MonkeyKing 平台底层故障注入的实现工具,通过对演练平台底层的故障注入能力进行抽象,定义了一套故障模型。配合用户友好的 CLI 工具进行开源,帮助云原生用户进行混沌工程测试。
4.2 阿里开源混沌工具 (ChaosBlade)
ChaosBlade 是阿里巴巴开源的一款遵循混沌工程原理和混沌实验模型的实验注入工具,帮助企业提升分布式系统的容错能力,并且在企业上云或往云原生系统迁移过程中业务连续性保障。
Chaosblade 是内部 MonkeyKing 对外开源的项目,其建立在阿里巴巴近十年故障测试和演练实践基础上,结合了集团各业务的最佳创意和实践。
ChaosBlade官网: https://github.com/chaosblade-io/chaosblade
4.3 通过混沌实验验证系统可用性
在面向故障设计设计的内容中,提到了很多种不同类型的故障。针对这些故障,我们可以混沌实验来对其进行模拟,通过 APM (应用性能管理)工具监测故障发生时的系统运行情况,从而采取相应的处理策略。
4.3.1 混沌实验模型
以阿里开源的混沌工程工具 ChaosBlade 为例,我们可以从直观的感觉上了解到什么是混沌实验、混沌实验能帮助分布式系统做哪些故障模拟。以下内容来自 ChoasBalde 对混沌实验的介绍:
对什么做混沌实验? 混沌实验实施的范围是是什么? 具体实施什么实验? 实验生效的匹配条件有哪些? 举个例子:一台 ip 是 10.0.0.1 机器上的应用,调用 com.example.HelloService@1.0.0 Dubbo 服务延迟 3s。
明确以上内容,就可以精准的实施一次混沌实验,抽象出以下模型 (ChaosBlade 混沌实验模型 ) :
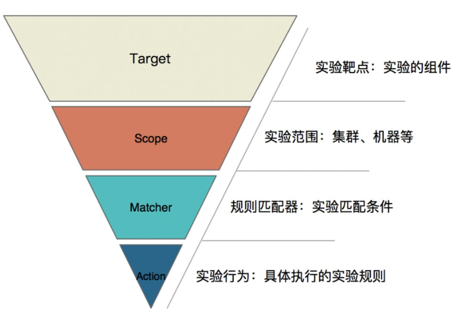
Target:实验靶点,指实验发生的组件,例如容器、应用框架( Dubbo、 Redis、 Zookeeper)等;
Scope:实验实施的范围,指具体触发实验的机器或者集群等;
Matcher:实验规则匹配器,根据所配置的 Target,定义相关的实验匹配规则,可以配置多个。由于每个 Target可能有各自特殊的匹配条件,比如 RPC领域的 HSF、 Dubbo,可以根据服务提供者提供的服务和服务消费者调用的服务进行匹配,缓存领域的 Redis,可以根据 set、 get操作进行匹配;
Action :指实验模拟的具体场景, Target 不同,实施的场景也不一样,比如磁盘,可以演练磁盘满,磁盘 IO 读写高,磁盘硬件故障等。如果是应用,可以抽象出延迟、异常、返回指定值(错误码、大对象等)、参数篡改、重复调用等实验场景。
还以如下 dubbo 超时为例: Targe 实验组件就是“ dubbo ”, Scope 范围就是“ 10.0.0.1 ”这台机器, Matcher 规则匹配器为 dubbo 服务“ com.example.HelloService@1.0.0 ”, Action 具体场景为“调用延时 3 秒”。
4.3.2 混沌实验场景
以 Chaosblade 为例,目前支持的混沌实验种类如下,基本上能够满足我们绝大多数的实验需求。同时, ChaosBlode 还在持续更新:
基础资源:比如 CPU 、内存、网络、磁盘、进程等实验场景;
Java 应用:比如数据库、缓存、消息、 JVM 本身、微服务等,还可以指定任意类方法注入各种复杂的实验场景;
C++ 应用:比如指定任意方法或某行代码注入延迟、变量和返回值篡改等实验场景;
Docker 容器:比如杀容器、容器内 CPU 、内存、网络、磁盘、进程等实验场景;
云原生平台:比如 Kubernetes 平台节点上 CPU 、内存、网络、磁盘、进程实验场景, Pod 网络和 Pod 本身实验场景如杀 Pod ,容器的实验场景如上述的 Docker 容器实验场景。
4.4 混沌实验平台
ChaosBlade 提供了丰富的混沌实验场景,但是目前还是作为一个命令行工具直接在实验节点上运行;虽然也提供了 httpserver 可以对外提供 restful 服务,然而还没有配套的可视化 Web 应用与其集成。如果需要在企业内部搭建一个混沌实验平台,可以参考阿里云的 AHAS (应用高可用服务)。
在笔者看来,搭建一个混沌实验平台,可以基于最小可行化产品 (MVP) 方式,围绕 ChaosBlade 快速建设一套 Web 可视化平台,同时与现有 APM (应用性能管理)平台进行集成,既可形成一套支撑混沌实验从准备、运行到监控的全流程管理。
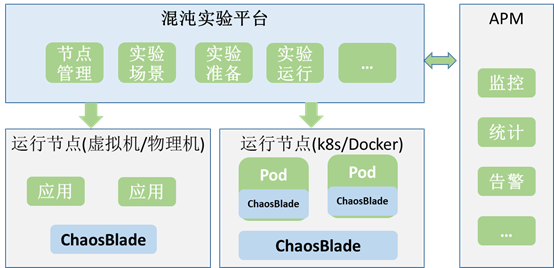
以下是一个简单的混沌实验平台功能架构图:
混沌实验平台:负责管理实验范围 ( 节点 ) 、实验支持的场景,完成实验准备,执行实验运行;
ChaosBlade :负责具体实验执行。以代理( agent )部署在虚拟机、物理机或 k8s 集群的 node 上;以 sidecar 方式部署在 k8s 的 pod 中;
APM :提供对实验过程中对系统高可用情况的监控,以验证系统是否在故障发生时能够从容应对。
参考资料:
- 《干货 | 阿里巴巴混沌测试工具 ChaosBlade 两万字解读》朱小厮 https://blog.csdn.net/u013256816/java/article/details/99917021
2.ChaosBlade 官网: https://github.com/chaosblade-io/chaosblad
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3
添加新评论0 条评论