
银行一体化监控平台建设与选型思路的十个典型问题
一、前言
在以客户服务为中心的银行服务体系下,要求银行在诸多关键业务应用上都必须保障业务连续性,以达到服务客户的宗旨。因为一旦业务中断将会对银行企业的收入、声誉等各方面造成重大影响。而且要在成千上万个系统中发现问题、定位问题。
在传统监控体系下,这是一个十分漫长而痛苦的过程,尤其目前很多银行又面临着传统集中式基础架构与虚拟化、云、容器等新兴分布式基础架构相融合的混合IT环境。在这种情况下,如何事先定位问题、隔离问题、诊断故障根源、解决问题成为银行在监控运维领域不断在探索的难题。
银行一直在不断探寻解决这些难题的应对方法,为了确保系统安全运行,为第一时间发现出现的故障,最短时间恢复业务连续性,针对各类设备、业务系统构建了各种监控,有网络监控、应用监控、业务监控、操作系统监控、基础设施监控、主机存储硬件监控、数据库和中间件监控等等,通过短信、邮件和微信等方式发送给维护人员预警。
然而各个厂商、不同类别的监控系统就像一座座孤岛占满了监控大屏,各种监控各管一段,有些复杂的故障问题或性能问题的定位就变的尤其复杂,影响了问题的快速定位和故障处置。因此,如何构建一个一体化监控体系(或者统一监控体系),让IT运维人员掌控系统的整体运行情况和运行效能,预知未来系统运行的趋势,确保系统的安全稳定、高效运行,成为一个愈来愈紧迫的问题。
二、 十个典型问题
【问题1】银行建设统一/一体化监控平台的主要原因?
从需求角度分析原因:
从技术发展上,目前很多银行目前已经上了新核心,用到了云,容器,微服务等新技术。从业务要求上,业务对稳定性要求越来越高,要求故障出现后更加及时的恢复,避免带来业务的损失。一方面,目前无论是大型、中型还是小型银行都有统一监控平台的需求,不仅仅因为事件需要集中,为实现业务系统端到端的监控,必然需要多样的监控手段和技术去支撑,带来监控源的多样化,必然也需要统一的运维数据分析平台去揉合这些监控数据,辅助运维人员定位根因,甚至结合历史处理方式,直接定位故障根因和处理方法。另一方面,统一监控平台是应用稳定运行保障的基石(参考谷歌SRE),一体化的监控平台解决应用、业务、用户视角的监控,帮助用户实现根因分析,根因定位,容量预测等等。是企业数字化转型的必备工具。
从技术角度分析原因:
监控方式、技术和类型过多,需要一个统一的事件平台来集中丰富、处理和分析不同监控源的告警事件;还需要一个统一的数据接入平台(运维大数据)来对不同监控源性能数据、日志和告警数据进行整合、分析、统计,借助AI的能力,智能辅助运维快速定位和根因分析;倘若银行企业端到端的监控源都比较完善(BPM、NPM、基础监控、APM、TPM等),可以进一步结合IT架构可视化系统,深化统一监控平台项目建设,通过将IT架构与多类数据源结合的方式,让架构图更加生动,运维人员在统一的可视化架构下,更为精准的定位故障。没有做到集中、统一监控、统一分析,那么各个系统是一套套毫无关联散沙,告警风暴来临时,多个告警平台同时告警,事件丰富的方式、联系人员也不同,运维人员像没头苍蝇,不仅无法快速判断故障根源,还可能会因多套监控平台的告警事件扰乱故障定位。
【问题2】银行信息系统监控领域产品类型有哪些?每类产品主要技术路线有哪些?
整理了一张表格简要介绍下信息系统监控领域的产品类型和主要技术路线: 
【问题3】银行信息系统监控体系整体架构层次和关系是怎样的?
这里有三张图,供大家参考。
第一张图是整体监控、运维体系架构图,其中统一CMDB为所有系统和平台提供统一的配置基准数据,提升联动的数据质量和效果;自动化运维平台自动采集和发现价值数据和数据关联,供其他系统和平台使用,和各项资源建立自动化关联关系,提供不同自动化运维场景调用API,供其他系统和平台调用;集中监控平台对接所有监控系统和平台,实时收集所有事件和告警,结合CMDB配置数据,第一时间匹配和丰富事件告警内容,以丰富的通知手段和详尽真实的告警详情告知相关负责人;运维大数据通过多样化、不同通道的方式,集成各系统和平台的实时或历史的结构化、非结构化数据,并进行过滤、清洗、加工、整合、分析、输出和数据持久化;IT架构可视化系统通过业务系统部署架构图、业务逻辑架构图、业务网络拓扑图三类架构图的方式,结合运维大数据中,不同数据源的数据,包括智能运维产出的建议,进行实时的展示,让数据和图联动,更为直观的展示业务系统整体运行状况。运维以IT架构可视化为主,智能运维为辅,强调人在运维中不可替代性。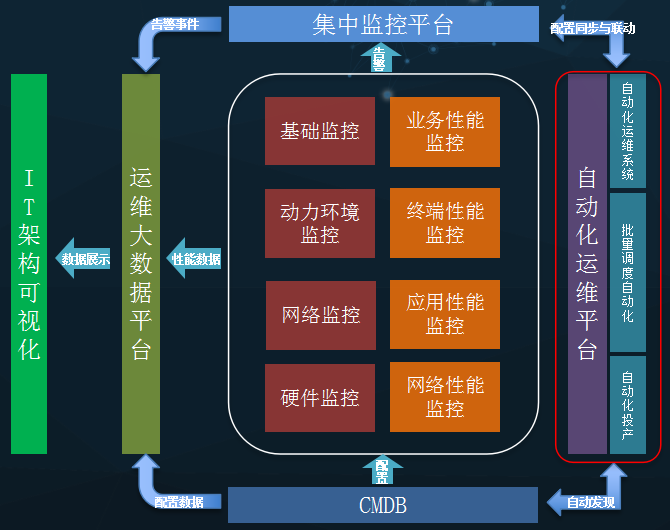
第二张图是网络性能管理(NPM)、运维大数据平台及与现有的基础监控和集中事件平台联动的整体功能逻辑架构图。网络流量报文通过TAP设备发送至NPM服务器和BPC服务器的采集口;NPM系统和BPC系统实时解码模块,对网络原始比特流进行解析,输出网络层指标和业务应用层指标;业务层和网络层 数据分析模块实时分析性能指标:交易量、成功率、交易渠道、交易类型、金额、TCP连接状态、丢包状态、网络时延……等等指标;前台展示模块从运维角度,可以实时的展示每一个节点的业务层和网络层指标情况,并配置实时告警,做到快速发现、快速定位、快速恢复;前台展示模块从业务运营角度,可以对全行交易情况进行实时大屏展示,对业务 交易渠道、交易机构、 交易金额、交易量 、 自定义的统计维度 等进行实时分类统计分析;业务性能监控系统对外的接口包括数据输出接口、交易明细输出、告警接口:数据输出接口可将业务监控系统统计的交易性能数据和交易明细数据按JSON、CSV、xml等方式实时输出,提供给第三方系统。或者第三方系统可以通过RestfulAPI的方式来查询所产生的统计数据、告警数据、明细报文数据等。告警信息可通过syslog、socket等方式发送到第三方事件管理平台进行集成,统一进行汇总处理。 本次实时解析的各系统性能数据,业务交易字段等实时推送给运维大数据平台,为实时运维大数据分析提供真实可信的数据源;业务交易及网络性能监控产生的告警事件,实时推送到现有集中事件平台 ; 运维大数据平台产生的告警事件,实时推送到现有集中事件平台;运维大数据平台可根据故障发生时间点,复原系统的性能、日志、网络报文等信息,辅助故障分析和快速解决 ;在集中了性能、配置、日志、事件等运维数据的基础上, 以运维大数据平台为核心, 开展智能运维在监控方面的建设,如单、多指标预测和分析、建议,告警事件自动关联知识库,指导运维人员快速解决问题,结合多类监控数据,进行可能的根因分析,辅助运维人员快速定位故障源,并在告警日志上下文历史挖掘分析、同类告警周期性规律分析、告警成对成组出现分析、告警相关与因果分析等等方面,进行智能分析,推进运维工作自动化和智能化 ;在各数据源数据统一接入运维大数据平台后,可为不同的用户的行为进行画像,供以后的精准营销或者风控项目消费,进一步指导业务的运营和管理等。

第三张图是运维大数据平台的整体架构图, 自下而上,最下面一层是数据源层,提供各种运维数据库包括结构化数据如关系型数据库以及非结构化数据例如各种系统日志,这些数据可以通过代理采集方式获取;另外一部分数据来源是现有系统,例如监控平台、网管、APM等工具,这些平台本身已经提供了各自该平台的事件或者性能数据,可以通过API的方式进行数据采集或者推送;数据源之上是运维管理总线,运维管理总线提供数据的接入、缓存、预处理,以及各个系统之间的消息传递、API调用。这一层通过搭建异步消息总线例如kafka集群来实现消息交互;第三层是数据处理层,包括两个方面,首先是大数据平台,大数据平台提供的是数据流式解析(例如数据加工、实时告警),数据计算以及存储能力;另外一部分是智能算法层,主要提供、训练各种智能算法模型;数据处理层之上是接口层,接口层是为了根据不同的智能化运维场景提供接口调用,包括服务总线,主要提供API的注册、接口网关、状态、调用的管理,数据网关主要提供数据的查询,数据网关等功能;采用的架构为微服务架构和总线架构:微服务架构可以将运维子系统的所有功能、操作、指令全部转变为原子操作,接受AIOPS的总体调度。运维总线架构可以将各类系统的相互通讯模式由网状变为星型,降低关联耦合度,提高通讯的速度、稳定性、可用性、可扩展性,使得大数据通讯不再成为瓶颈;最上面一层是AIOps场景层,该层次是通过调用API层提供的各种能力来实现智能化场景。场景层的设置是根据事件的生命周期进行设置的,例如在发现问题阶段通过自动基线、通过日志分类来判断异常,发现问题;到通过关联分析、日志深度检查、应用全链路监控等来分析问题;通过匹配知识库,调用运维调度平台来定位问题;最后通过智能预测来预测容量、故障的发生。另外提供了为领导层提供辅助决策的功能,例如系统画像、用户工单、请求分析等。

【问题4】 银行信息系统监控涉及的系统、网络、应用等软硬件种类繁杂,如何进行有效的监控整合,避免各个监控系统之间的数据孤岛?
监控系统之间目前确实很容易存在数据孤岛的问题,比如基础监控和业务监控,和网络监控等,这些监控到的东西,无法形成统一的整体,割裂开来,造成网络做网络的监控、应用做业务的监控、系统做系统的基础监控,大家都是孤立的个体,最多通过统一的事件平台来展示和告警而已。这种现状,显然已经无法满足企业,尤其是银行企业的实际运维监控需求,因此如何把这些孤立的数据,协同、统一起来,变得十分的重要。有两种思路供大家参考:
第一种是:运维大数据,通过对多运维数据源的汇总,分析,归纳,统计,形成一个统一的可视化运维分析平台,出现故障,不再是割裂的,而是统一的各类信息的整合, 实现统一分析,如根因定位,告警的影响性分析,应用容量分析和预测等等。另外运维大数据更重要的是多类监控数据源的数据,有结构化的、非结构化的数据,不断学习,做深入挖掘,帮助运维人员找出可能的根因。
第二种是:IT架构可视化,在统一的网络架构、业务逻辑架构、应用部署架构下,展示所有的运维数据,有实时的基础监控数据、业务性能数据(BPC)、网络性能数据(NPM)、运维大数据分析后的数据(ITOA)、APP终端性能数据(TPM)、流程数据(ITSM)等等,整个统一架构下的,不同数据源的整合,让运维人员,可视化的发现可能的根因。 利用“IT架构图”与数据相互结合的方式,图可以分三类,一类是业务系统所在的网络架构,结合NPM的数据和流程数据,网络架构中的节点,可以关联CMDB的数据和NPM性能数据和告警数据等;二类是业务系统的业务逻辑架构,也就是该业务系统和其他系统的关联关系,这张图上的业务节点,可以关联业务性能指标和流程数据,清晰的知道该业务系统的健康状态,如业务量,业务成功率和系统响应率,和告警,或者近期有没有流程变更等;三类是业务系统的部署架构图,其中的各类组件,比如WEB、中间件、数据库、应用负载、非通用设备等,关联的数据是基础性能数据和流程等。有了这样一套IT可视化系统,各类运维人员,无论是网络、系统还是应用运维人员都可以很清晰的知晓哪里有问题,哪里是关键节点,帮助迅速定位可能的原因。而不是每个运维人员心中一张图,各自定位,信息孤岛,排查问题低效。
【问题5】一体化监控技术选型方案?一体化系统监控包含哪些系统的监控,如何进行技术选型,采用何种研发方式,自研还是外采?
监控是个体系化工程,在这个体系内有基础监控部分,包括网络基础监控、动力环境监控、数据库监控、中间件监控、操作系统监控和硬件监控等等,还有业务性能监控(以业务为中心的性能监控),应用性能监控(以应用软件为中心的性能监控),网络性能监控(以网络为中心的性能监控),还有终端体验监控,包括APP SDK或者客户端等终端的监控,应用拨测等等。最后需要一个统一的事件平台来整合管控所有告警事件;需要一个运维方向上的大数据平台,来接入所有监控源数据,包括基础监控,APM,BPM,NPM,TPM,拨测数据,实现历史数据分析和挖掘,实时监控数据整合,通过AI技术实现智能运维;需要一个架构可视化平台,以架构为图,图上的各元素接入运维大数据平台的各监控数据源的数据,来集中展现。像我们中小金融机构,一般采用外采的较多,自研还是偏向基础监控的多些,毕竟基础监控的门槛不是高,脚本开发也是不难,这类可以自研。但一些专业度较高的,业务和网络性能监控,一般通过网络旁路镜像的方式采集数据,报文解码能力要求很高,很难自研,市面上的成熟产品也很多,案例也是非常多,可以直接外采。应用监控的话,看应用是外采还是自研的了,如果是自研的话,也可以顺带开发个监控系统,也未尝不可,若是外采开发的话,通常还是用成熟的应用监控系统,通过收集日志来监控也可以。
【问题6】进行一体化监控项目建设,CMDB系统如何建设及建设的范围?
监控和CMDB系统属于不同的领域,因此都有不同的建设思路,在监控选型的时候,不建议选择在监控系统中内置配置管理的工具,而是考虑CMDB和监控分开建设,然后考虑两个系统的集成。一体化监控所需要的配置信息都纳入到CMDB中进行对接,或者监控自己的CMDB和外部CMDB系统进行数据同步。倘若每个运维监控系统都自己弄一套CMDB,那信息完全紊乱,匹配。全行级CMDB还是必须的,不能单独放到某一个运维系统中去做。
需要考虑的集成的地方有以下几个方面:
1、监控的标准化依赖CMDB,如每种类型对象他的监控指标要标准化,监控的自动化可以和CMDB集成,如监控对象入网后,可以自动化的实现监控,监控的覆盖率和CMDB也有依赖。
2、告警事件的丰富和收敛可以和CMDB紧密结合。
3、CMDB可以提供应用视角的拓扑(Service Map),和告警事件进行关联,实现应用视角的监控和告警分析。
4、CMDB建设容易,但如何持续更新完善数据是关键,有些数据可以通过系统采集,有些数据只能人为录入。因此建立一套符合运维和监控体系的CMDB录入和采集标准和流程是非常有必要的。
【问题7】如何看待监控中的LessAgent和Agent监控方式的问题?
两种方式各有利弊, 对于安装Agent, 这种方式获取的数据相对来说丰富,配置性也较好,其数据抓取能力是非常强的,仅仅消耗一部分的CPU和内存,即使主控服务器挂掉,仍然可以在恢复后,再次获得数据。 LessAgent的监控方式,则较为依赖网络,如果监控端口出现故障,或者主控服务器出现故障,则监控数据在一段时间内将是空白,而且对于SSH,WMI等监控方式,频繁的访问仍然会加重系统负担,但是好在不会让系统有除业务应用之外的进程,而且频繁的增加Agent会导致系统的进程越来越多, 增加了系统端的压力,并且增加了处理问题的复杂性。
随着技术的发展,现在的流行趋势是将业务逻辑之外的所有基础技术进一步下沉,很多之前分散的基础技术都可以封装在一起,或者说通过AGENT代理去实现,监控也不例外。而通过SSH或者WMI等通讯协议去做这种基础技术的统一管控根本没办法做全做好。所以目前还是偏向于Agent的方式去做更复杂的事情,用Lessagent的方式去做更简单的事情而又不会对增加系统额外开销。
【问题8】 目前很多银行部署了私有云或容器,在面对云与传统结构融合的环境,应该如何部署监控系统,更快速,更准确的发现问题。 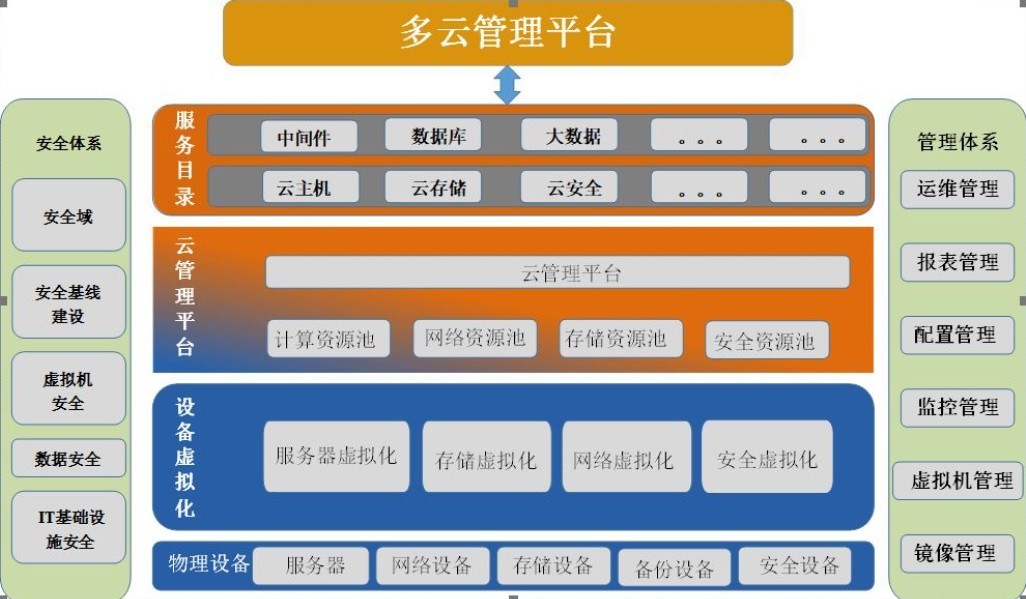
监控是属于右侧运维管理体系中的一个非常重要的工具。
方案一:使用私有云和容器自带的监控工具,进行日常的监控,缺点是监控分散,无法站在应用视角进行监控;
方案二:部署统一的监控系统,通过统一的监控系统监控私有云,容器以及网络,数据库,应用等,从而实现更快速更准确的发现问题。
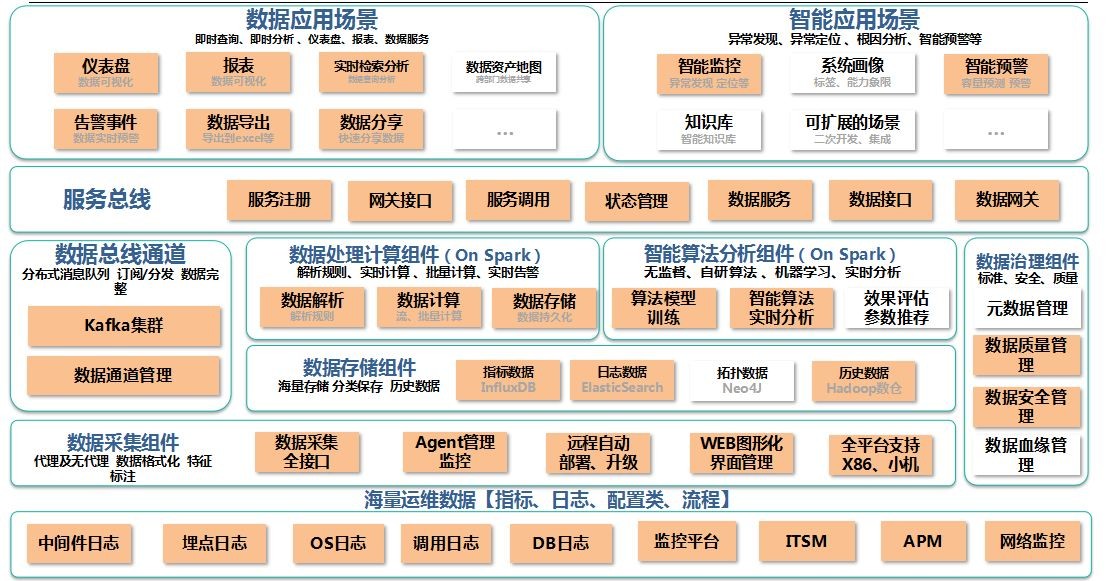
【问题9】银行监控一体化后,海量监控数据如何深度挖掘利用,价值最大化?
海量监控数据的挖掘利用是需要结合实际运用场景才能实现价值最大化的,这里有一张我们运维大数据平台的整体框架图,最底层是海量运维数据接入层,包括各类指标型、日志型、配置型和流程型数据,第二层是数据采集组件层,通过代理及无代理两种方式进行接入数据的采集,第三层是数据总线和分析层,最上层是运维大数据的各类运用场景,主要包含两大块运用场景,一个是数据的应用场景,包括仪表盘、报表、实时检索分析、数据资产地图、数据的导出和共享等等。另一个是智能应用场景,包括智能监控、系统画像、智能预警、知识库等等场景。具体包括六大智能场景,见下表格,包括应用系统交易智能分析、 企业级系统智能感知、 企业级数据库智能洞察、 企业安全及网络智能防御、 企业级运维智能提升、 企业级存储智能评估。这些场景,目前部分已经实现落地,另一些还在积极摸索实现。
| 产品组件 | 场景价值 | AI算法模型 | 用户 |
| 应用系统交易智能分析 | 可视化交易链路上数字化表现,并直观的深入分析运行状态下应用系统平台的动态交易量异常评估、预警和深层次故障定位 | 故障树AI模型 动态阀值模型 系统知识图谱,单KPI异常检测,多KPI联合异常检测 多KPI异常机器和软件模块定位 调用链分析 | 应用支撑 |
| 企业级系统智能感知 | 结合Aix,Linux,Windows,HP等操作系统特点,智能评估系统运行稳定性状况 | 动态阀值模型 多KPI异常机器和软件模块定位 | 系统管理员 |
| 企业级数据库智能洞察 | 以DBA视角智能评估各项数据库核心指标,并给出数据库性能优化建议,故障定位功能 | 容量预测模型 指标预测模型 性能优化模型 | 数据库DBA |
| 企业安全及网络智能防御 | 基于安全规范框架,实现数字化环境下的持续自适应安全风险监测和防御 | 日志分析模型 日志关联模型 日志聚合模型 | 安全网络专家 |
| 企业级运维智能提升 | 在原有监控平台基础上改善优化运维能力,实现被动规则监控+主动AI模型预警。具有综合故障排查和日志综合分析功能 | 指标预测模型 日志分析模型 故障树AI模型 指标关联关系挖掘 | 系统监控管理员 |
| 企业级存储智能评估 | 存储智能运维针对多元,异构,多站点的数据中心,提供一站式,可视化,自动化,易扩展的智能存储运维。 | 容量预测模型 异常日志模型 存储知识库模型 设备故障预测 | 存储管理员 |
【问题10】统一监控系统的使用的用户到底有哪些?
统一监控系统的使用用户包括: 开发人员、测试人员、应用运维、网络运维、系统运维和业务人员等等,甚至管理决策者也能通过统一监控平台获得很多有价值的决策依据。可以参考以下这张图。这其中一个很重要的原因就是通过监控各数据源采集的数据,可以产生很多有价值的数据,监控已不再是传统的监控CPU、内存、网络、磁盘等基础监控了,而是一个数据中心底层的运行数据的采集、监控和分析挖掘平台,这个范畴涵盖了太多太多指标了。例如,业务人员可以通过业务监控和用户终端体验监控系统来获得不同业务类型的业务量、金额、成功率、用户各类信息等很多有价值的业务信息。开发测试人员可以根据通过应用监控APM,可以监控到代码级执行效率、错误等,帮助开发人员进行相应程序优化。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞5本文隶属于专栏

作者其他文章
评论 17 · 赞 79
评论 8 · 赞 42
评论 0 · 赞 1
评论 0 · 赞 1
评论 0 · 赞 2
添加新评论1 条评论
2021-11-16 10:11