手把手从零部署与运营生产级的 Kubernetes 集群与 KubeSphere
本文来自 KubeSphere 社区用户 > Liu_wt> 投稿,欢迎所有 KubeSphere 社区用户参与投稿或分享案例与经验。
KubeSphere 开发者社区:kubesphere.io -> 开发者社区
本文将从零开始,在干净的机器上安装 Docker、Kubernetes (使用 kubeadm)、Calico、Helm 与 KubeSphere,通过手把手的教程演示如何搭建一个高可用生产级的 Kubernetes,并在 Kubernetes 集群之上安装 KubeSphere 容器平台可视化运营集群环境。
一、准备环境
开始部署之前,请先确定当前满足如下条件,本次集群搭建,所有机器处于同一内网网段,并且可以互相通信。
⚠️⚠️⚠️:请详细阅读第一部分,后面的所有操作都是基于这个环境的,为了避免后面部署集群出现各种各样的问题,强烈建议你完全满足第一部分的环境要求
两台以上主机
每台主机的主机名、Mac 地址、UUID 不相同
CentOS 7(本文用 7.6/7.7)
每台机器最好有 2G 内存或以上
Control-plane/Master至少 2U 或以上
各个主机之间网络相通
禁用交换分区
禁用 SELINUX
关闭防火墙(我自己的选择,你也可以设置相关防火墙规则)
Control-plane/Master和Worker节点分别开放如下端口
Master节点
| 协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 6443* | Kubernetes API 服务器 | 所有组件 |
| TCP | 入站 | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | 入站 | 10250 | Kubelet API | kubelet 自身、控制平面组件 |
| TCP | 入站 | 10251 | kube-scheduler | kube-scheduler 自身 |
| TCP | 入站 | 10252 | kube-controller-manager | kube-controller-manager 自身 |
Worker节点
| 协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | kubelet 自身、控制平面组件 |
| TCP | 入站 | 30000-32767 | NodePort 服务** | 所有组件 |
其他相关操作如下:
友情提示 ,如果集群过多,可以学习 ansible 来批量管理你的多台机器,方便实用的工具。
进行防火墙、交换分区设置
为了方便本操作关闭了防火墙,也建议你这样操作
systemctl stop firewalld
systemctl disable firewalld
关闭 SeLinux
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
关闭 swap
swapoff -a
yes | cp /etc/fstab /etc/fstab_bak
cat /etc/fstab_bak |grep -v swap > /etc/fstab
更换CentOS YUM源为阿里云yum源
安装wget
yum install wget -y
备份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
获取阿里云yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
获取阿里云epel源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
清理缓存并创建新的缓存
yum clean all && yum makecache
系统更新
yum update -y
进行时间同步,并确认时间同步成功
timedatectl
timedatectl set-ntp true
⚠️⚠️⚠️以下操作请严格按照声明的版本进行部署,否则将碰到乱七八糟的问题
二、安装 Docker
2.1、安装 Docker
您需要在每台机器上安装 Docker,我这里安装的是 docker-ce-19.03.4
安装 Docker CE
设置仓库
安装所需包
yum install -y yum-utils \
device-mapper-persistent-data \\
lvm2
新增 Docker 仓库,速度慢的可以换阿里云的源。
yum-config-manager \
--add-repo \\
https://download.docker.com/linux/centos/docker-ce.repo 阿里云源地址
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装 Docker CE.
yum install -y containerd.io-1.2.10 \
docker-ce-19.03.4 \\
docker-ce-cli-19.03.4
启动 Docker 并添加开机启动
systemctl start docker
systemctl enable docker
2.2、修改 Cgroup Driver
需要将Docker 的 Cgroup Driver 修改为 systemd,不然在为Kubernetes 集群添加节点时会报如下错误:
执行 kubeadm join 的 WARNING 信息
目前 Docker 的 Cgroup Driver 看起来应该是这样的:
$ docker info|grep "Cgroup Driver"
Cgroup Driver: cgroupfs
需要将这个值修改为 systemd ,同时我将registry替换成国内的一些仓库地址,以免直接在官方仓库拉取镜像会很慢,操作如下。
⚠️⚠️⚠️:注意缩进,直接复制的缩进可能有问题,请确保缩进为正确的 Json 格式;如果 Docker 重启后查看状态不正常,大概率是此文件缩进有问题,Json格式的缩进自己了解一下。

三、安装 kubeadm、kubelet 和 kubectl
3.1、安装准备
需要在每台机器上安装以下的软件包:
- kubeadm:用来初始化集群的指令。
- kubelet:在集群中的每个节点上用来启动 pod 和容器等。
- kubectl:用来与集群通信的命令行工具(Worker 节点可以不装,但是我装了,不影响什么)。
** 配置K8S的yum源
这部分用是阿里云的源,如果可以访问Google,则建议用官方的源**
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
官方源配置如下
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
3.2、开始安装
安装指定版本 kubelet、 kubeadm 、kubectl, 我这里选择当前较新的稳定版 Kubernetes 1.17.3,如果选择的版本不一样,在执行集群初始化的时候,注意 --kubernetes-version 的值。
增加配置
cat < /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward=1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
加载
sysctl --system
安装
yum install -y kubelet-1.17.3 kubeadm-1.17.3 kubectl-1.17.3 --disableexcludes=kubernetes
启动并设置 kubelet 开机启动
systemctl start kubelet
systemctl enable --now kubelet
⚠️⚠️⚠️WARNING
如果此时执行 systemctl status kubelet 命令,系统日志将得到 kubelet 启动失败的错误提示,请忽略此错误,因为必须完成后续步骤中 kubeadm init 的操作,kubelet 才能正常启动
四、使用 Kubeadm 创建集群
4.1、初始化 Control-plane/Master 节点
在第一台 Master 上执行初始化,执行初始化使用 kubeadm init 命令。初始化首先会执行一系列的运行前检查来确保机器满足运行 Kubernetes 的条件,这些检查会抛出警告并在发现错误的时候终止整个初始化进程。然后 kubeadm init 会下载并安装集群的 Control-plane 组件。
在初始化之前,需要先设置一下 hosts 解析,为了避免可能出现的问题,后面的 Worker 节点我也进行了同样的操作。注意按照你的实际情况修改Master节点的IP,并且注意 APISERVER_NAME 的值,如果你将这个 apiserver 名称设置为别的值,下面初始化时候的 --control-plane-endpoint 的值保持一致。
提示:为了使 Kubernetes 集群高可用,建议给集群的控制节点配置负载均衡器,如 HAproxy + Keepalived 或 Nginx,云上可以使用公有云的负载均衡器,然后在以下部分设置 > MASTER_IP > 和 > APISERVER_NAME > 为负载均衡器的地址(IP:6443) 和域名。
设置hosts
echo "127.0.0.1 $(hostname) " >> /etc/hosts
export MASTER_IP=192.168.115.49
export APISERVER_NAME=kuber4s.api
echo " ${MASTER_IP} ${APISERVER_NAME} " >> /etc/hosts
友情提示:
截止2020年01月29日,官方文档声明了使用 kubeadm 初始化 master 时,--config 这个参数是实验性质的,所以就不用了;我们用其他参数一样可以完成 master 的初始化。
--config string kubeadm 配置文件。警告:配置文件的使用是试验性的。
下面有不带注释的初始化命令,建议先查看带注释的每个参数对应的意义,确保与你的当前配置的环境是一致的,然后再执行初始化操作,避免踩雷。
初始化 Control-plane/Master 节点
kubeadm init \
--apiserver-advertise-address 0.0.0.0 \
API 服务器所公布的其正在监听的 IP 地址,指定“0.0.0.0”以使用默认网络接口的地址
切记只可以是内网IP,不能是外网IP,如果有多网卡,可以使用此选项指定某个网卡
--apiserver-bind-port 6443 \
API 服务器绑定的端口,默认 6443
--cert-dir /etc/kubernetes/pki \
保存和存储证书的路径,默认值:"/etc/kubernetes/pki"
--control-plane-endpoint kuber4s.api \
为控制平面指定一个稳定的 IP 地址或 DNS 名称,
这里指定的 kuber4s.api 已经在 /etc/hosts 配置解析为本机IP
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
选择用于拉取Control-plane的镜像的容器仓库,默认值:"k8s.gcr.io"
因 Google被墙,这里选择国内仓库
--kubernetes-version 1.17.3 \
为Control-plane选择一个特定的 Kubernetes 版本, 默认值:"stable-1"
--node-name master01 \
指定节点的名称,不指定的话为主机hostname,默认可以不指定
--pod-network-cidr 10.10.0.0/16 \
指定pod的IP地址范围
--service-cidr 10.20.0.0/16 \
指定Service的VIP地址范围
--service-dns-domain cluster.local \
为Service另外指定域名,默认"cluster.local"
--upload-certs
将 Control-plane 证书上传到 kubeadm-certs Secret
不带注释的内容如下,如果初始化超时,可以修改DNS为8.8.8.8后重启网络服务再次尝试
kubeadm init \
--apiserver-advertise-address 0.0.0.0 \
--apiserver-bind-port 6443 \
--cert-dir /etc/kubernetes/pki \
--control-plane-endpoint kuber4s.api \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version 1.17.3 \
--pod-network-cidr 10.10.0.0/16 \
--service-cidr 10.20.0.0/16 \
--service-dns-domain cluster.local \
--upload-certs
接下来这个过程有点漫长(初始化会下载镜像、创建配置文件、启动容器等操作),泡杯茶,耐心等待,你也可以执行 tailf /var/log/messages 来实时查看系统日志,观察 Master 的初始化进展,期间碰到一些报错不要紧张,可能只是暂时的错误,等待最终反馈的结果即可。
如果初始化最终成功执行,你将看到如下信息:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME /.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config
sudo chown $(id -u):$(id -g) $HOME /.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join kuber4s.api:6443 --token 0j287q.jw9zfjxud8w85tis \
--discovery-token-ca-cert-hash sha256:5e8bcad5ec97c1025e8044f4b8fd0a4514ecda4bac2b3944f7f39ccae9e4921f \
--control-plane --certificate-key 528b0b9f2861f8f02dfd4a59fc54ad21e42a7dea4dc5552ac24d9c650c5d4d80
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join kuber4s.api:6443 --token 0j287q.jw9zfjxud8w85tis \
--discovery-token-ca-cert-hash sha256:5e8bcad5ec97c1025e8044f4b8fd0a4514ecda4bac2b3944f7f39ccae9e4921f
为普通用户添加 kubectl 运行权限,命令内容在初始化成功后的输出内容中可以看到。
mkdir -p $HOME /.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME /.kube/config
sudo chown $(id -u):$(id -g) $HOME /.kube/config
建议root用户也进行以上操作,作者使用的是root用户执行的初始化操作,然后在操作完成后查看集群状态的时候,出现如下错误:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
这时候请备份好 kubeadm init 输出中的 kubeadm join 命令,因为将会需要这个命令来给集群添加节点。
⚠️⚠️⚠️提示:令牌是主节点和新添加的节点之间进行相互身份验证的,因此请确保其安全。任何人只要知道了这些令牌,就可以随便给您的集群添加节点。你可以使用 > kubeadm token > 命令来查看、创建和删除这类令牌。
4.2、安装 Pod 网络附加组件
关于 Kubernetes 网络介绍,建议读完这篇 文章。
集群必须安装Pod网络插件,以使Pod可以相互通信,只需要在Master节点操作,其他新加入的节点会自动创建相关pod。
必须在任何应用程序之前部署网络组件。另外,在安装网络之前,CoreDNS将不会启动(你可以通过命令 kubectl get pods --all-namespaces|grep coredns 查看 CoreDNS 的状态)。
查看 CoreDNS 的状态,并不是 Running 状态
$ kubectl get pods --all-namespaces|grep coredns
kube-system coredns-7f9c544f75-bzksd 0/1 Pending 0 14m
kube-system coredns-7f9c544f75-mtrwq 0/1 Pending 0 14m
kubeadm 支持多种网络插件,我们选择 Calico 网络插件(kubeadm 仅支持基于容器网络接口(CNI)的网络(不支持kubenet)),默认情况下,它给出的pod的IP段地址是 192.168.0.0/16 ,如果你的机器已经使用了此IP段,就需要修改这个配置项,将其值改为在初始化 Master 节点时使用 kubeadm init --pod-network-cidr=x.x.x.x/x 的IP地址段,即我们上面配置的 10.10.0.0/16 ,大概在625行左右,操作如下:
获取配置文件
mkdir calico && cd calico
wget https://docs.projectcalico.org/v3.8/manifests/calico.yaml
修改配置文件
找到 625 行左右的 192.168.0.0/16 ,并修改为我们初始化时配置的 10.10.0.0/16
vim calico.yaml
部署 Pod 网络组件
kubectl apply -f calico.yaml
稍等片刻查询 pod 详情,你也可以使用 watch 命令来实时查看 pod 的状态,等待 Pod 网络组件部署成功后,就可以看到一些信息了,包括 Pod 的 IP 地址信息,这个过程时间可能会有点长
watch -n 2 kubectl get pods --all-namespaces -o wide
4.3、将 Worker 节点添加到 Kubernetes
请首先确认 Worker 节点满足第一部分的环境说明,并且已经安装了 Docker 和 kubeadm、kubelet 、kubectl,并且已经启动 kubelet。
添加 Hosts 解析
echo "127.0.0.1 $(hostname) " >> /etc/hosts
export MASTER_IP=192.168.115.49
export APISERVER_NAME=kuber4s.api
echo " ${MASTER_IP} ${APISERVER_NAME} " >> /etc/hosts
将 Worker 节点添加到集群,这里注意,执行后可能会报错,有幸的话你会跳进这个坑,这是因为 Worker 节点加入集群的命令实际上在初始化 master 时已经有提示出来了,不过两小时后会删除上传的证书,所以如果你此时加入集群的时候提示证书相关的错误,请执行 kubeadm init phase upload-certs --upload-certs重新加载证书。
kubeadm join kuber4s.api:6443 --token 0y1dj2.ih27ainxwyib0911 \
--discovery-token-ca-cert-hash sha256:5204b3e358a0d568e147908cba8036bdb63e604d4f4c1c3730398f33144fac61 \
执行加入操作,你可能会发现卡着不动,大概率是因为令牌ID对此集群无效或已过 2 小时的有效期(通过执行 kubeadm join --v=5 来获取详细的加入过程,看到了内容为 ”token id "0y1dj2" is invalid for this cluster or it has expired“ 的提示),接下来需要在 Master 上通过 kubeadm token create 来创建新的令牌。
$ kubeadm token create -- print -join-command
W0129 19:10:04.842735 15533 validation.go:28] Cannot validate kube-proxy config - no validator is available
W0129 19:10:04.842808 15533 validation.go:28] Cannot validate kubelet config - no validator is available
输出结果如下
kubeadm join kuber4s.api:6443 --token 1hk9bc.oz7f3lmtbzf15x9b --discovery-token-ca-cert-hash sha256:5e8bcad5ec97c1025e8044f4b8fd0a4514ecda4bac2b3944f7f39ccae9e4921f
在 Worker 节点上重新执行加入集群命令
kubeadm join kuber4s.api:6443 \
--token 1hk9bc.oz7f3lmtbzf15x9b \
--discovery-token-ca-cert-hash sha256:5e8bcad5ec97c1025e8044f4b8fd0a4514ecda4bac2b3944f7f39ccae9e4921f
接下来在Master上查看 Worker 节点加入的状况,直到 Worker 节点的状态变为 Ready 便证明加入成功,这个过程可能会有点漫长,30 分钟以内都算正常的,主要看你网络的情况或者说拉取镜像的速度;另外不要一看到 /var/log/messages 里面报错就慌了,那也得看具体报什么错,看不懂就稍微等一下,一般在 Master 上能看到已经加入(虽然没有Ready)就没什么问题。
watch kubectl get nodes -o wide
4.4、添加 Master 节点
需要至少2个CPU核心,否则会报错
kubeadm join kuber4s.api:6443 \\
--token 1hk9bc.oz7f3lmtbzf15x9b \\
--discovery-token-ca-cert-hash sha256:5e8bcad5ec97c1025e8044f4b8fd0a4514ecda4bac2b3944f7f39ccae9e4921f \\
--control-plane --certificate-key 5253fc7e9a4e6204d0683ed2d60db336b3ff64ddad30ba59b4c0bf40d8ccadcd
4.5、补充内容
- kubeadm init 初始化 Kubernetes 主节点
- kubeadm token 管理 kubeadm join 的令牌
- kubeadm reset 将 kubeadm init 或 kubeadm join 对主机的更改恢复到之前状态,一般与 -f 参数使用
移除 worker 节点
正常情况下,你无需移除 worker 节点,如果要移除,在准备移除的 worker 节点上执行
kubeadm reset -f
或者在 Control-plane 上执行
kubectl delete node nodename
- 将 nodename 替换为要移除的 worker 节点的名字
- worker 节点的名字可以通过在 Control-plane 上执行 kubectl get nodes 命令获得
五、Kubernetes 高可用集群
5.1、环境说明
如果你使用的是以上方法部署你的 Kubernetes 集群,想在当前基础上进行高可用集群的创建,则可以按照下面的步骤继续进行。
值得注意的是,这里没有将ETCD放在Master外的机器上,而是使用默认的架构,即官方的 Stacked etcd topology 方式的集群
你需要至少 3 台 Master 节点和 3 台 Worker 节点,或者更多的机器,但要保证是 Master 和 Worker 节点数都是奇数的,以防止 leader 选举时出现脑裂状况。 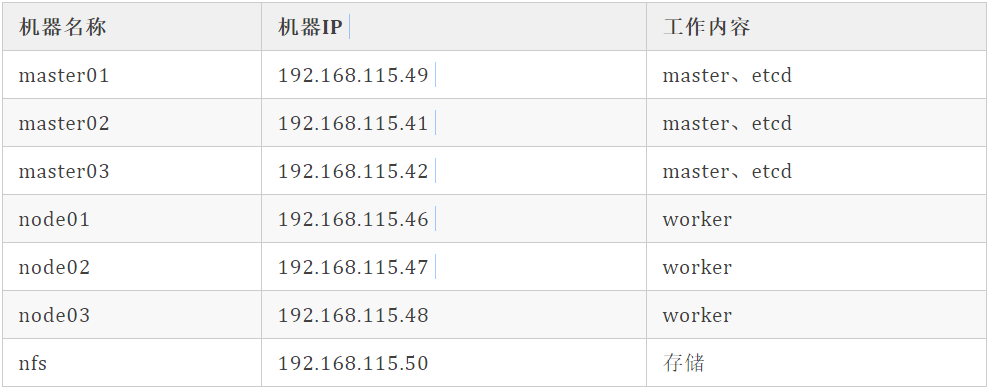
5.2、高可用扩展
你只需要将不同的 Master 和 Worker 节点加入到集群中就行了。加入的指令在你初始化集群时已经给出了。
- 添加 Master 节点:
需要至少 2 个 CPU 核心,否则会报错
kubeadm join kuber4s.api:6443 \\ --token 1hk9bc.oz7f3lmtbzf15x9b \
--discovery-token-ca-cert-hash sha256:5e8bcad5ec97c1025e8044f4b8fd0a4514ecda4bac2b3944f7f39ccae9e4921f \
--control-plane --certificate-key 5253fc7e9a4e6204d0683ed2d60db336b3ff64ddad30ba59b4c0bf40d8ccadcd
- 添加 Worker 节点
在 Worker 节点上重新执行加入集群命令
kubeadm join kuber4s.api:6443 \
--token 1hk9bc.oz7f3lmtbzf15x9b \
--discovery-token-ca-cert-hash sha256:5e8bcad5ec97c1025e8044f4b8fd0a4514ecda4bac2b3944f7f39ccae9e4921f
六、安装 KubeSphere
6.1、KubeSphere简介
Kubernetes 官方有提供一套 Dashboard,但是我这里选择功能更强大的 KubeSphere。
以下内容引用自 KubeSphere 官网:
KubeSphere 是在 Kubernetes 之上构建的以应用为中心的容器平台,提供简单易用的操作界面以及向导式操作方式,在降低用户使用容器调度平台学习成本的同时,极大减轻开发、测试、运维的日常工作的复杂度,旨在解决 Kubernetes 本身存在的存储、网络、安全和易用性等痛点。
除此之外,平台已经整合并优化了多个适用于容器场景的功能模块,以完整的解决方案帮助企业轻松应对敏捷开发与自动化运维、DevOps、微服务治理、灰度发布、多租户管理、工作负载和集群管理、监控告警、日志查询与收集、服务与网络、应用商店、镜像构建与镜像仓库管理和存储管理等多种场景。后续版本将提供和支持多集群管理、大数据、AI 等场景。
6.2、安装要求
KubeSphere 支持直接在 Linux 上部署集群,也支持在 Kubernetes 上部署,我这里选择后者,基本的要求如下:
- Kubernetes 版本:1.15.x ≤ K8s version ≤ 1.17.x;
- Helm 版本:2.10.0 ≤ Helm Version < 3.0.0(不支持 helm 2.16.0#6894),且已安装了 Tiller,参考 如何安装与配置 Helm(预计 3.0 支持 Helm v3);
- 集群已有默认的存储类型(StorageClass),若还没有准备存储请参考安装 OpenEBS 创建 LocalPV 存储类型用作开发测试环境。
- 集群能够访问外网,若无外网请参考 在 Kubernetes 离线安装 KubeSphere。
6.3、安装 Helm
6.3.1、Helm 简介
Helm 基本思想如图所示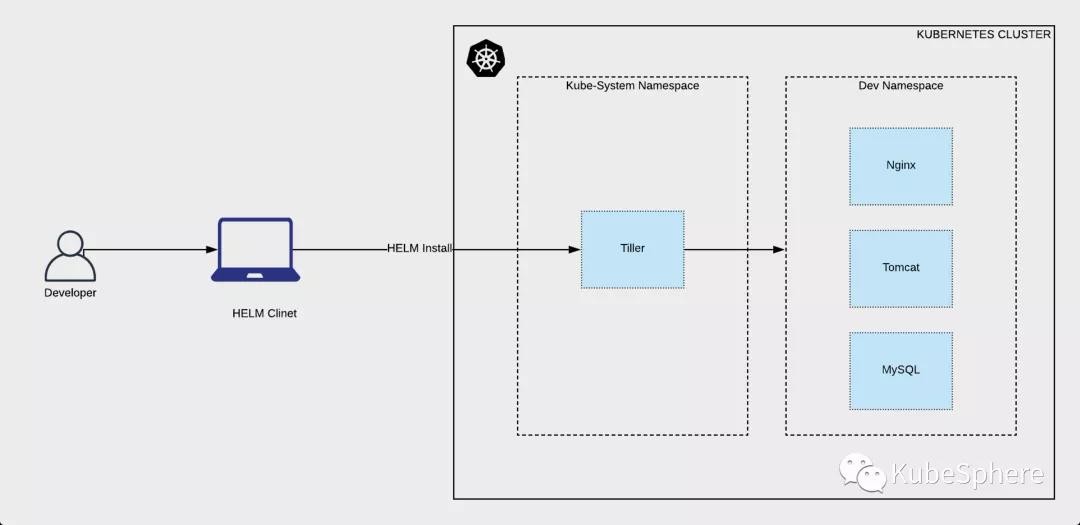
以下内容引用自 此篇文章
Helm 基本概念
Helm 可以理解为 Kubernetes 的包管理工具,可以方便地发现、共享和使用为Kubernetes构建的应用,它包含几个基本概念:
- Chart:一个 Helm 包,其中包含了运行一个应用所需要的镜像、依赖和资源定义等,还可能包含 Kubernetes 集群中的服务定义
- Release: 在 Kubernetes 集群上运行的 Chart 的一个实例。在同一个集群上,一个 Chart 可以安装很多次。每次安装都会创建一个新的 release。例如一个 MySQL Chart,如果想在服务器上运行两个数据库,就可以把这个 Chart 安装两次。每次安装都会生成自己的 Release,会有自己的 Release 名称。
- Repository:用于发布和存储 Chart 的仓库。
6.3.2、Helm 安装
安装过程如下
创建部署目录并下载Helm
mkdir tiller
cd tiller
先使用官方的方式安装,如果安装不了,可以看到下载文件的地址,然后手动下载解压
curl -L https://git.io/get_helm.sh | bash
获取到下载地址后,想办法下载
wget https://get.helm.sh/helm-v2.16.3-linux-amd64.tar.gz
tar zxf helm-v2.16.3-linux-amd64.tar.gz
mv linux-amd64/helm /usr/ local /bin/helm
验证
helm version
部署 Tiller,即 Helm 的服务端。先创建 SA 
创建 RBAC:
kubectl apply -f helm-rbac.yaml
初始化,这个过程可能不会成功,具体接着往下看
helm init --service-account=tiller --history-max 300
检查初始化的情况,不出意外的话,墙内用户看pod详情可以看到获取不到镜像的错误。
kubectl get deployment tiller-deploy -n kube-system
如果一直获取不到镜像,可以通过更换到Azure中国镜像源来解决,操作步骤如下:
编辑 deploy
kubectl edit deploy tiller-deploy -n kube-system
查找到image地址,替换为如下地址,保存退出
gcr.azk8s.cn/kubernetes-helm/tiller:v2.16.3
接下来稍等片刻,再次查看deployment和pod详情,就正常了
kubectl get deployment tiller-deploy -n kube-system
6.4、安装 StorageClass
Kubernetes 支持多种 StorageClass,我这选择 NFS 作为集群的 StorageClass。
参考地址:https://github.com/kubernetes-incubator/external-storage/tree/master/nfs-client
6.4.1、下载所需文件
下载所需文件,并进行内容调整
mkdir nfsvolume && cd nfsvolume
for file in class.yaml deployment.yaml rbac.yaml ; do wget https://raw.githubusercontent.com/kubernetes-incubator/external-storage/master/nfs-client/deploy/ $file ; done
修改 deployment.yaml 中的两处 NFS 服务器 IP 和目录 
6.4.2、部署创建
具体的说明可以去官网查看。
kubectl create -f rbac.yaml
kubectl create -f class.yaml
kubectl create -f deployment.yaml
如果日志中看到“上有坏超级块”,请在集群内所有机器上安装nfs-utils并启动。
yum -y install nfs-utils
systemctl start nfs-utils
systemctl enable nfs-utils
rpcinfo -p
查看storageclass
$ kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
managed-nfs-storage fuseim.pri/ifs Delete Immediate false 10m
6.4.3、标记一个默认的 StorageClass
操作命令格式如下
kubectl patch storageclass -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
请注意,最多只能有一个 StorageClass 能够被标记为默认。
验证标记是否成功
$ kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
managed-nfs-storage (default) fuseim.pri/ifs Delete Immediate false 12m
6.5、部署 KubeSphere
过程很简单,如果你的机器资源足够,建议你进行完整安装,操作步骤如下。如果你的资源不是很充足,则可以进行最小化安装,参考地址。我当然是选择完整安装了,香!
下载 yaml 文件
mkdir kubesphere && cd kubesphere
wget https://raw.githubusercontent.com/kubesphere/ks-installer/master/kubesphere-complete-setup.yaml
部署 KubeSphere
kubectl apply -f kubesphere-complete-setup.yaml
这个过程根据你实际网速,实际使用时间长度有所不同。你可以通过如下命令查看实时的日志输出。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
当你看到如下日志输出,证明你的 KubeSphere 部署成功 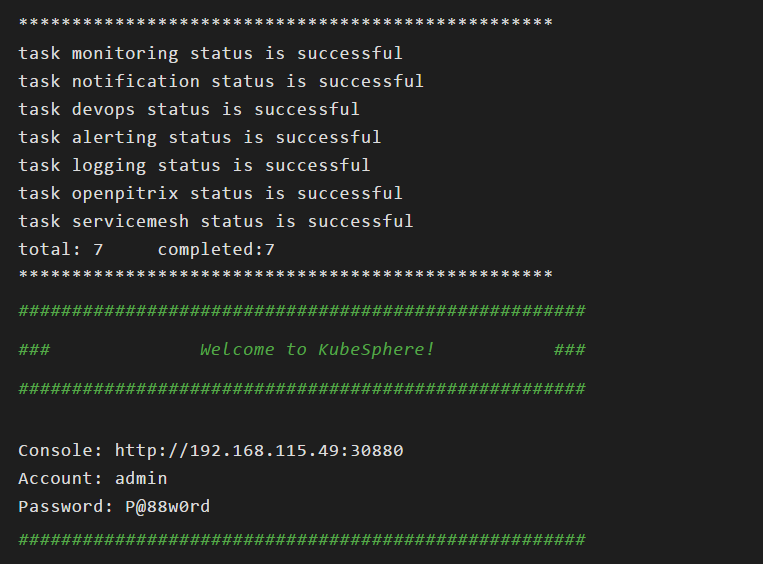
确认 Pod 都正常运行后,可使用 IP:30880 访问 KubeSphere UI 界面,默认的集群管理员账号为 admin/P@88w0rd ,Enjoy it,!

参考
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
添加新评论0 条评论