ubuntu安装与测试hadoop1.1.0版本
最近没什么事,就使用之前测试openstack的机器,测试一下hadoop,看看他到底是干嘛的?
测试环境为ubuntu 12.04 64位系统,hadoop版本是1.1.0
下面是安装过程
1、安装jdk
- apt-get install openjdk-7-jdk
安装完成后测试一下
- root@openstack:~/hadoop/conf# java -version
- java version "1.6.0_24"
- OpenJDK Runtime Environment (IcedTea6 1.11.5) (6b24-1.11.5-0ubuntu1~12.04.1)
- OpenJDK 64-Bit Server VM (build 20.0-b12, mixed mode)
可以看到我的jdk是1.6版本的
2、下载hadoop
- wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.1.0/hadoop-1.1.0.tar.gz
3、安装hadoop
先解压
- tart zxvf hadoop-1.1.0.tar.gz
然后重命名
- mv hadoop-1.1.0 hadoop
然后对hadoop进行配置
(1)修改conf/core-site.xml
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://localhost:9000</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/home/hadoop/tmp</value>
- </property>
- </configuration>
注意:hadoop.tmp.dir是hadoop文件系统依赖的基础配置,很多路径都依赖它。它默认的位置是在/tmp/{$user}下面,在local和hdfs都会建有相同的目录,但是在/tmp路径下的存储是不安全的,因为linux一次重启,文件就可能被删除。导致namenode启动不起来。
(2)修改conf/hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- </configuration>
(3) 修改conf/mapred-site.xml
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>localhost:9001</value>
- </property>
- </configuration>
(4)为了是hadoop能找到java,所以在conf/hadoop-env.sh最后一行添加jdk的路径,我的java路径为
- export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk-amd64
然后再检测一下
- root@openstack:~/hadoop/conf# java -version
- java version "1.6.0_24"
- OpenJDK Runtime Environment (IcedTea6 1.11.5) (6b24-1.11.5-0ubuntu1~12.04.1)
- OpenJDK 64-Bit Server VM (build 20.0-b12, mixed mode)
可以看到我的jdk是1.6版本的
(5)在namenode端cd到hadoop文件夹下,格式化分布式文件系统:
- bin/hadoop namenode -format
下面是我的操作结果
- root@openstack:~/hadoop/conf# cd ..
- root@openstack:~/hadoop# bin/hadoop namenode -format
- 12/11/27 14:10:43 INFO namenode.NameNode: STARTUP_MSG:
- /************************************************************
- STARTUP_MSG: Starting NameNode
- STARTUP_MSG: host = openstack/127.0.1.1
- STARTUP_MSG: args = [-format]
- STARTUP_MSG: version = 1.1.0
- STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.1 -r 1394289; compiled by 'hortonfo' on Thu Oct 4 22:06:49 UTC 2012
- ************************************************************/
- 12/11/27 14:10:43 INFO util.GSet: VM type = 64-bit
- 12/11/27 14:10:43 INFO util.GSet: 2% max memory = 17.77875 MB
- 12/11/27 14:10:43 INFO util.GSet: capacity = 2^21 = 2097152 entries
- 12/11/27 14:10:43 INFO util.GSet: recommended=2097152, actual=2097152
- 12/11/27 14:10:44 INFO namenode.FSNamesystem: fsOwner=root
- 12/11/27 14:10:44 INFO namenode.FSNamesystem: supergroupsupergroup=supergroup
- 12/11/27 14:10:44 INFO namenode.FSNamesystem: isPermissionEnabled=true
- 12/11/27 14:10:44 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
- 12/11/27 14:10:44 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
- 12/11/27 14:10:44 INFO namenode.NameNode: Caching file names occuring more than 10 times
- 12/11/27 14:10:44 INFO common.Storage: Image file of size 110 saved in 0 seconds.
- 12/11/27 14:10:44 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/home/hadoop/tmp/dfs/name/current/edits
- 12/11/27 14:10:44 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/home/hadoop/tmp/dfs/name/current/edits
- 12/11/27 14:10:46 INFO common.Storage: Storage directory /home/hadoop/tmp/dfs/name has been successfully formatted.
- 12/11/27 14:10:46 INFO namenode.NameNode: SHUTDOWN_MSG:
- /************************************************************
- SHUTDOWN_MSG: Shutting down NameNode at openstack/127.0.1.1
- ************************************************************/
(6)然后再启动服务,由于我的单节点安装,所以就全部启动
- bin/start-all.sh
下面是我的操作
- root@openstack:~/hadoop# bin/start-all.sh
- starting namenode, logging to /root/hadoop/libexec/../logs/hadoop-root-namenode-openstack.out
- localhost: starting datanode, logging to /root/hadoop/libexec/../logs/hadoop-root-datanode-openstack.out
- localhost: starting secondarynamenode, logging to /root/hadoop/libexec/../logs/hadoop-root-secondarynamenode-openstack.out
- starting jobtracker, logging to /root/hadoop/libexec/../logs/hadoop-root-jobtracker-openstack.out
- localhost: starting tasktracker, logging to /root/hadoop/libexec/../logs/hadoop-root-tasktracker-openstack.out
然后再输入jps查看本机的启动情况
- root@openstack:~/hadoop# jps
- 9340 SecondaryNameNode
- 9665 TaskTracker
- 9426 JobTracker
- 9822 Jps
- 8853 NameNode
- 9091 DataNode
可以看到namenode与datanode都启动了
如果你不是单机模式,多节点的话,你在namenode看到的就只有namenode而没有datanode,反之在datanode也是一样。
然后再打开http://localhost:50030与http://localhost:50070查看运行情况,由于我的机器的ip是192.168.1.30,所以我如果不在本机查看的话,就可以使用http://192.168.1.30:50030查看
下面是http://192.168.1.30:50030的界面
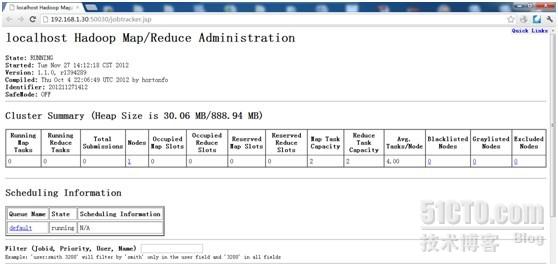

下面是http://192.168.1.30:50070的界面
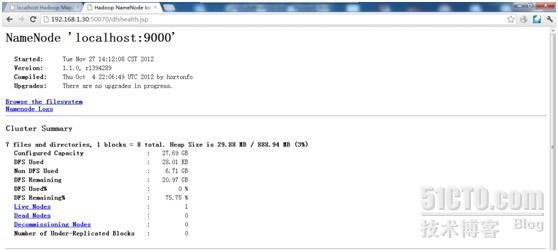

4、测试hadoop
我是使用hadoop自带的wordcount测试
(1)、通过hadoop的命令在HDFS上创建/tmp/test目录,命令如下:bin/hadoop dfs -mkdir /tmp/test
(2)、先在系统里创建test1与test2文件,内容分别为:
test1 "hello world,this is my hadoop test"
test2 "welcome to hadoop world"
创建的命令为
- echo "hello world,this is my hadoop test">/tmp/test1
- echo "welcome to hadoop world">/tmp/test2
(3)、然后再通过copyFromLocal命令把本地的test1与test2复制到HDFS上,命令如下:bin/hadoop dfs -copyFromLocal /tmp/test[1-2] /tmp/test
然后再到hds里查看一下
- root@openstack:~/hadoop# bin/hadoop dfs -ls /tmp/test
- Found 2 items
- -rw-r--r-- 1 root supergroup 35 2012-11-27 15:01 /tmp/test/test1
- -rw-r--r-- 1 root supergroup 24 2012-11-27 15:01 /tmp/test/test2
可以看到test1与test2已经上传到了hds里
(4)在执行wordcount
- root@openstack:~/hadoop# bin/hadoop jar hadoop-examples-1.1.0.jar wordcount /tmp/test/test* /tmp/test/result
- 12/11/27 15:28:21 INFO input.FileInputFormat: Total input paths to process : 2
- 12/11/27 15:28:21 INFO util.NativeCodeLoader: Loaded the native-hadoop library
- 12/11/27 15:28:21 WARN snappy.LoadSnappy: Snappy native library not loaded
- 12/11/27 15:28:21 INFO mapred.JobClient: Running job: job_201211271500_0002
- 12/11/27 15:28:22 INFO mapred.JobClient: map 0% reduce 0%
- 12/11/27 15:28:31 INFO mapred.JobClient: map 100% reduce 0%
- 12/11/27 15:28:40 INFO mapred.JobClient: map 100% reduce 33%
- 12/11/27 15:28:42 INFO mapred.JobClient: map 100% reduce 100%
- 12/11/27 15:28:44 INFO mapred.JobClient: Job complete: job_201211271500_0002
- 12/11/27 15:28:44 INFO mapred.JobClient: Counters: 29
- 12/11/27 15:28:44 INFO mapred.JobClient: Job Counters
- 12/11/27 15:28:44 INFO mapred.JobClient: Launched reduce tasks=1
- 12/11/27 15:28:44 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=12789
- 12/11/27 15:28:44 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
- 12/11/27 15:28:44 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
- 12/11/27 15:28:44 INFO mapred.JobClient: Launched map tasks=2
- 12/11/27 15:28:44 INFO mapred.JobClient: Data-local map tasks=2
- 12/11/27 15:28:44 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=10558
- 12/11/27 15:28:44 INFO mapred.JobClient: File Output Format Counters
- 12/11/27 15:28:44 INFO mapred.JobClient: Bytes Written=70
- 12/11/27 15:28:44 INFO mapred.JobClient: FileSystemCounters
- 12/11/27 15:28:44 INFO mapred.JobClient: FILE_BYTES_READ=125
- 12/11/27 15:28:44 INFO mapred.JobClient: HDFS_BYTES_READ=261
- 12/11/27 15:28:44 INFO mapred.JobClient: FILE_BYTES_WRITTEN=71664
- 12/11/27 15:28:44 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=70
- 12/11/27 15:28:44 INFO mapred.JobClient: File Input Format Counters
- 12/11/27 15:28:44 INFO mapred.JobClient: Bytes Read=59
- 12/11/27 15:28:44 INFO mapred.JobClient: Map-Reduce Framework
- 12/11/27 15:28:44 INFO mapred.JobClient: Map output materialized bytes=131
- 12/11/27 15:28:44 INFO mapred.JobClient: Map input records=2
- 12/11/27 15:28:44 INFO mapred.JobClient: Reduce shuffle bytes=131
- 12/11/27 15:28:44 INFO mapred.JobClient: Spilled Records=20
- 12/11/27 15:28:44 INFO mapred.JobClient: Map output bytes=99
- 12/11/27 15:28:44 INFO mapred.JobClient: CPU time spent (ms)=3620
- 12/11/27 15:28:44 INFO mapred.JobClient: Total committed heap usage (bytes)=302252032
- 12/11/27 15:28:44 INFO mapred.JobClient: Combine input records=10
- 12/11/27 15:28:44 INFO mapred.JobClient: SPLIT_RAW_BYTES=202
- 12/11/27 15:28:44 INFO mapred.JobClient: Reduce input records=10
- 12/11/27 15:28:44 INFO mapred.JobClient: Reduce input groups=9
- 12/11/27 15:28:44 INFO mapred.JobClient: Combine output records=10
- 12/11/27 15:28:44 INFO mapred.JobClient: Physical memory (bytes) snapshot=431722496
- 12/11/27 15:28:44 INFO mapred.JobClient: Reduce output records=9
- 12/11/27 15:28:44 INFO mapred.JobClient: Virtual memory (bytes) snapshot=3213344768
- 12/11/27 15:28:44 INFO mapred.JobClient: Map output records=10
然后再查看一下
- root@openstack:~/hadoop# bin/hadoop dfs -ls /tmp/test
- Found 3 items
- drwxr-xr-x - root supergroup 0 2012-11-27 15:28 /tmp/test/result
- -rw-r--r-- 1 root supergroup 35 2012-11-27 15:01 /tmp/test/test1
- -rw-r--r-- 1 root supergroup 24 2012-11-27 15:01 /tmp/test/test2
可以看到2个文件一个文件夹
文件夹的内容为
- root@openstack:~/hadoop# bin/hadoop dfs -ls /tmp/test/result
- Found 3 items
- -rw-r--r-- 1 root supergroup 0 2012-11-27 15:28 /tmp/test/result/_SUCCESS
- drwxr-xr-x - root supergroup 0 2012-11-27 15:28 /tmp/test/result/_logs
- -rw-r--r-- 1 root supergroup 70 2012-11-27 15:28 /tmp/test/result/part-r-00000
然后我们在看之前的运行结果,也就是part-r-00000的内容
- root@openstack:~/hadoop# bin/hadoop dfs -cat /tmp/test/result/part-r-00000
- hadoop 2
- hello 1
- is 1
- my 1
- test 1
- to 1
- welcome 1
- world 1
- world,this 1
在对比一下test1与test2的内容
- root@openstack:~/hadoop# cat /tmp/test1
- hello world,this is my hadoop test
- root@openstack:~/hadoop# cat /tmp/test2
- welcome to hadoop world
可以发现hadoop对这2个文本进行了word的统计,左侧是单词,右侧是出现的次数。
然后我们在查看一下web界面的显示
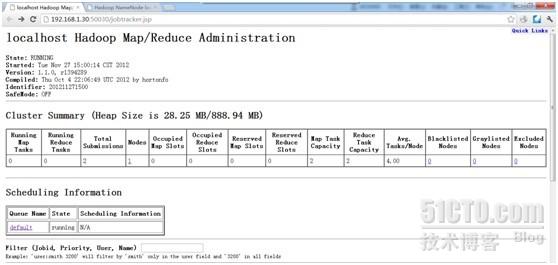
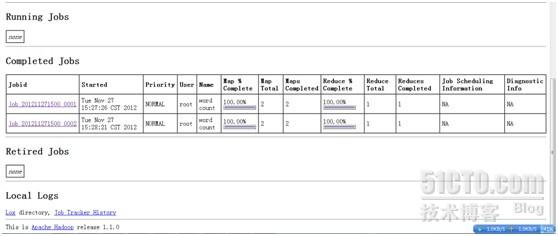
可以发现有之前的操作了,为什么有2个job,是因为我又做了其他的操作
查看第一个job
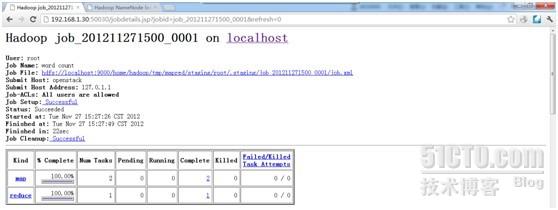

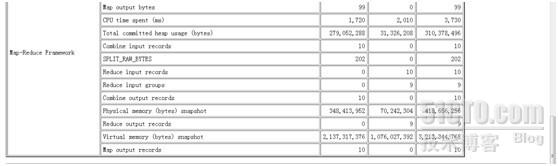

操作都有各自的描述,我就不多说了。
现在我只是使用wordcount简单的测试一下hadoop,了解他的一下简单的概念与作用。
BTW:如果大家认为我写的不错,希望能给我的博客投个票,谢谢!
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 0 · 赞 1
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 0
评论 0 · 赞 1
添加新评论0 条评论