中小银行大数据平台建设实践分享
摘要:
面对业务发展、数据化转型等各方面的需求,基于传统架构的银行数据仓库体系面临极大的挑战。我行目前既有传统架构的数据仓库,也引入了基于主流Hadoop体系的大数据平台。为优化数据重复加工与存储,促进信息管理应用的数据融合共享,本文在采用大数据技术构建统一的企业级数据管理平台,重构数据仓库方面进行了探索,以论证传统数据仓库往大数据平台迁移的可行性,为我行在大数据战略上的规划提供一定的支持。探索过程涉及现状调研安排、架构设计、模型迁移与优化、数据迁移、ETL迁移、数据访问接口的迁移、容量规划等多个核心环节,并依照我行的特点进行了一些有意义的尝试。
一、银行大数据平台建设背景
在全球经济进入数字化转型时期,数字化转型已成为传统企业必须付诸行动的必选题。当下数字化转型已经渗入人们日常的衣食住行、工作生活、生产服务等方方面面。在消费金融具有极大发展潜力及前景的情况下,银行进行数字化转型更为迫切。
而面对数字化转型的需要,银行体系中的传统数据仓库普遍面临极大的挑战:
(1) 现有数据仓库的数据分析模式,不能有效支撑数据快速分析和价值发现,需要新的交互模式发掘数据的统计相关性、因果关系、关联关系等规律。
(2) 数据源不断增多,访问和数据同步变得复杂。
(3) 数据量增大、应用作业不断增加,运行沉重缓慢。
(4) 难于支撑海量非结构化数据存储与检索需求,如影像数据、音频数据。
我行使用传统数据仓库多年,虽然尚未完全触碰到上述问题的极限情况,数据仓库依然稳定的在支撑我行业务的运作,但随着业务的发展,上述传统数仓的困境在我行也有了一定的展现。为提前布局,灵活应对,我们进行了多种尝试,包括继续深挖现有系统潜力、迁移到大数据平台等。
经过对业界和同行的调研,我们了解到,相当部分的银行最终选择了将数据仓库迁移到大数据平台,而我行从2017年开始,已经引入了源于Hadoop体系的科技大数据平台,具备迁移的能力。下文是我们结合同业经验,在我行探索环境中实验的,对我行数据仓库进行模拟迁移中所作的一些探索经验。
二、软件架构选型
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,Hadoop框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。Hadoop是当前世界企业管理大数据的基础支撑技术。
分布式文件系统HDFS:
HDFS(Hadoop Distributed File System),作为Google File System(GFS)的实现,是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
HDFS的架构如下图所示:
一般情况下副本系数为3,HDFS的副本放置策略是:将第一个副本放在本地节点,将第二个副本放在本地机架上的另一个节点,而第三个副本放到不同机架上的节点。这种方式减少了机架间的写流量,从而提高了写的性能。机架故障的机率远小于节点故障。这种方式并不影响数据可靠性和可用性的限制,并且它确实减少了读操作的网络聚合带宽,因为文件块仅存在两个不同的机架,而不是三个。文件的副本不是均匀的分布在机架当中,1/3的副本在同一个节点上,1/3副本在同一个机架上,另外1/3个副本均匀地分布在其他机架上。
分布式计算框架MapReduce:
MapReduce是面向大数据并行处理的计算模型、框架和平台,它隐含了以下三层含义:
(1)它是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。它允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。
(2)它是一个并行计算与运行软件框架(Software Framework)。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
(3)它是一个并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理。
三、服务器架构选型
目前市面上主流的服务器有intel X86架构和ARM架构。
X86架构于1978年推出的Intel 8086中央处理器中首度出现。X86架构(The X86 architecture)是微处理器执行的计算机语言指令集,指一个Intel通用计算机系列的标准编号缩写,也标识一套通用的计算机指令集合。X86架构的强大并不在于它本身,而在于围绕着它所建立起来的:软件生态。而X86架构上面建立了各种各样的基于X86指令架构的程序,这就是它的强大之处。
ARM架构过去称作进阶精简指令集机器(AdvancedRISCMachine,更早称作:AcornRISCMachine),是一个32位精简指令集(RISC)处理器架构,其广泛地使用在许多嵌入式系统设计。由于节能的特点,ARM处理器非常适用于移动通讯领域,符合其主要设计目标为低耗电的特性。
在性能方面,对于大数据负载来说,英特尔®至强®可扩展处理器为代表的x86处理器性能高于ARM处理器。 在生态方面,大数据平台选择得到充分验证和优化的硬件平台尤为重要,大数据工作负载在Intel X86平台上已经适配多年,有着很好的成熟度,也不需要企业对软件(如移植)进行额外投资,对于IT人员来说,也能快速掌握在Intel X86平台上的开发运维。例如Spark、DeepLearning、MongoDB等,英特尔®至强®可扩展处理器都有经过验证的优化指南。在开放性方面,采用英特尔®至强®可扩展处理器为代表的x86服务器脚骨可以实现跨厂商解决方案的兼容性和可持续性。
综合性能、生态和开放性等方面,大数据平台选择采用英特尔®至强®可扩展处理器为内核的x86服务器作为计算节点和数据节点。
大数据平台很多应用场景属于计算密集型,在计算密集作业下CPU是系统运行效率的关键,CPU性能提升能够大幅度加速整体作业的运行效率。第三代英特尔®至强®可扩展处理器提供了具备多至8路的扩展能力,每个处理器最多可达40个核心,可为大数据平台提供进一步突破性能瓶颈的基础。
四、迁移选型要求
完全开源的Hadoop项目对中小银行而言有较大的挑战。首先,开源的Hadoop技术在对GB到TB级数据的处理效率较低,需要较深入的底层调优。其次,只有对海量的数据进行高效的分析及利用才能将大数据中存在的巨大潜在价值转换为实际的商业价值,企业亟需完备的解决方案来加速大数据应用的业务创新。最后,中小银行因编制因素,科技人员数量有限,熟练掌握大数据技术的技术人员更是稀少,需要成熟的服务商进行早期的引导和技术支持。
因此,我行要从自身应用角度出发,通过对国内外众多主流大数据平台产品的技术能力和实现细节详细了解、对比、筛选,并对候选产品进行严格的POC测试,最终选择更符合我行需求的大数据平台产品。
五、迁移策略
为降低迁移风险、缩短迁移周期、保证迁移进度,参考同业经验,我们将采用了“原样迁移、重点优化”的策略模式。
其中,原样迁移策略表示:
(1) 参考信息架构基本不变,保持数据仓库现有的分层架构体系。
(2) 上下游接口基本不变。
(3) 脚本加工逻辑基本不变。
重点优化策略则表示:
(1) 基于新平台特性进行专项优化。
(2) 在维持现有的E-R LDM设计模式基础上,重点优化基础模型。
(3) 基于维度建模构建银行重要业务对象的一致性维度和汇总事实,对应用层重点优化。
为贯彻迁移策略,达到良好的迁移效果,结合项目管理经验,我们将整个迁移过程分为:现状调研、架构设计、模型迁移、数据迁移、ETL迁移、接口迁移等多个步骤。每个步骤都是承上启下,前后关联。
六、迁移关键步骤探索
1.现状调研
了解现状是整个迁移工作的基础,我们要对数据仓库现状进行详细调研,确定大数据上的库架构,整理现有数据仓库的数据迁移范围,完善迁移技术需求和项目实施方案。调研内容包括数据仓库架构、各数据表及数据量统计、各数据模型及DDL、库表的作业运行和依赖、库表的下游使用情况、相关设计文档、设计开发规范等等。
为更好的做好调研工作,我们制定了如下的文档收集指引: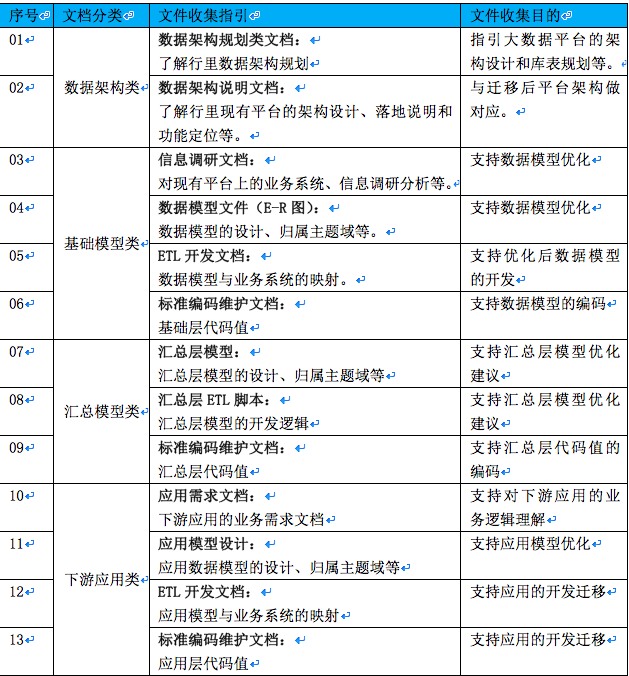
相关调研工作,为后续的设计、开发、测试等工作奠定坚实基础,保障了生产数据迁移的可靠性。
2.架构设计
在架构设计方面,我们即要考虑当前迁移的需求,也要结合行里的规划及场景需求,通盘考虑,相关设计既要立足现在,更能面向未来。为了减少实时类应用与批量类应用之间的相互影响,保证重要系统性能及稳定性,我们优化早期单集群的架构,将重要应用独立到一个集群,称为应用服务区;其余应用部署到另外集群,称为基础数据区,最终逻辑架构设计如下:
对于应用服务区,首先从技术上它只能满足小批量数据处理,对数据的查询及加工处理延时要求比较高,一般要求必须在1秒内返回结果,不能接受超过2秒的延时。其次从业务的角度看在应用服务区的应用都是对我行比较重要的,比如我行的生产运营系统-银行柜面客户历史数据查询系统,又比如我行对客系统进行数据支撑-APP应用中的客户收益明细、实时风险等。
对于基础数据区定义是大批量数据处理平台,海量数据存储平台,它也可以满足小批量数据处理的需求,不过因为存在大批量数据处理应用资源挤压问题,小批量数据处理可能存在性能波动的风险,我们一般用于承载我行数据湖业务、数据仓库业务、营销分析、报表平台等。
采用此架构,两个集群稳定运行,实时查询与批处理等大任务拆分开,实时查询可稳定对外提供服务;基础数据区全天皆可运行批处理等大作业,集群处理能力更强等。
3.基础模型层迁移及优化
在我行中,模型层模型主要以E-R(实体-属性)构建逻辑数据模型(LDM),来反映银行的业务属性及其关系,其是逻辑性的,与具体承载平台无关。因此在实际迁移中,我们要基本保证了数据模型的不变。但在项目实施过程中,我们也要借机进行成熟度评估,然后根据平台特性构建新的物理模型。我们结合实际情况整理迁移判断逻辑如下: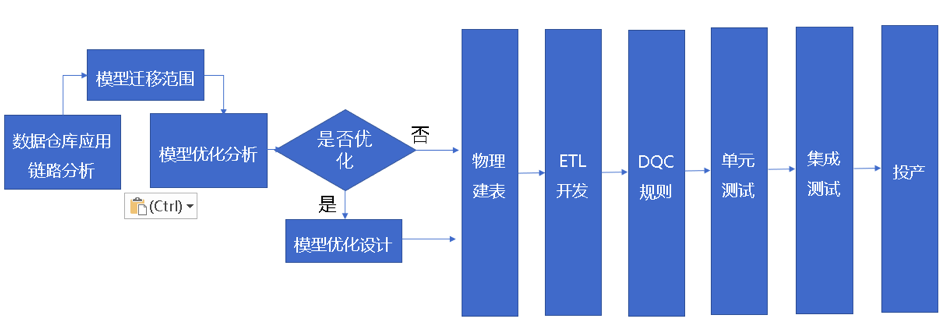
逻辑模型在设计过程中,为保证模型的稳定性,往往采用泛化、子类、抽象、拉链等设计模式。在实际物理化时,往往都是严格遵守了与逻辑模型一致的1:1物理化方式,导致模型的性能问题。针对这些设计模式,可以采用适当的特化、上收下放、还原等优化措施。
泛化适度还原优化示意如下: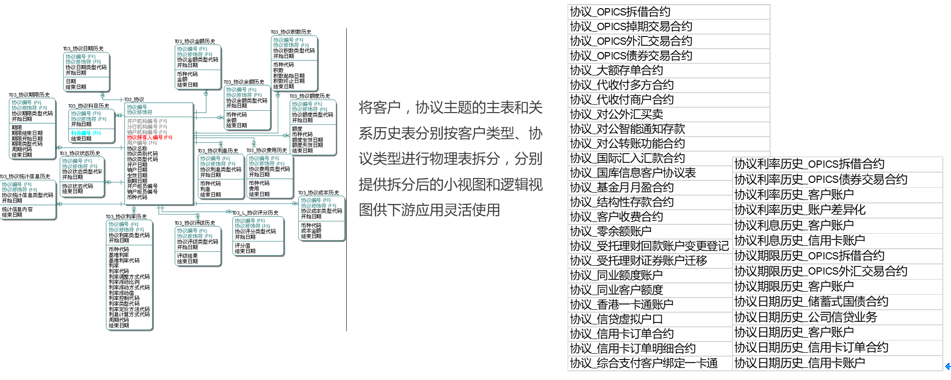
属性按需冗余优化示意如下:
4.数据迁移
在数据的迁移中,为实现迁移的自动化,我们需要使用服务商的数据迁移工具,相关工具要能从现有数据仓库中读取DDL信息,自动转化为大数据平台的DDL。
相关工具转化速度取决于大数据平台的资源限制及网络带宽,根据同业的经验,理论上迁移速率可达100-250M/S甚至更高。迁移过程示意如下: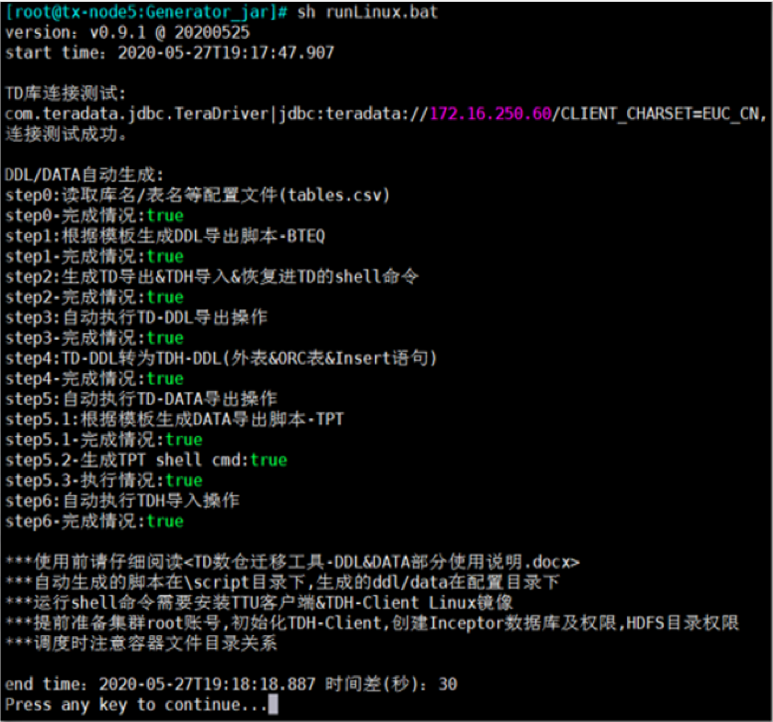
5.ETL迁移
针对数据仓库的ETL工作,从技术实现角度进行分析,主要包括(1)物理模型设计及DDL生成;(2)平台间数据迁移;(3)基础模型层、汇总层、应用层等ETL开发;(4)迁移数据核对这几个部分。其中伍立模型设计及DDL生成是最核心的部分,本次迁移中,我们实施了如下设计原则,充分保障了存量数据迁移的可靠性。
各层模型平台物理化建议: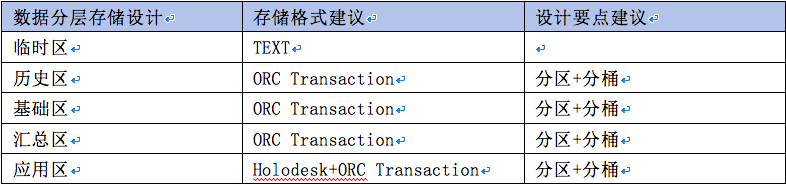
平台模型物理化原则建议:
结合以上原则,我们可以根据现有的ETL脚本,从脚本还原出ETL映射文档,映射文档对脚本中的执行步骤,找出目标表字段与源表、源字段的对应关系,并分离出JOIN、WHERE、GROUP BY,ORDER BY,QUALIFY等子句,然后进行改写,生产大数据平台的存储过程,最终经过核验后落地实施。
6.数据访问接口的迁移—ODBC/JDBC

7.硬件配置
集群27节点采用Intel X86架构物理服务器进行配置,保证各节点的计算性能详细配置如下:
集群各节点磁盘配置详情如下:
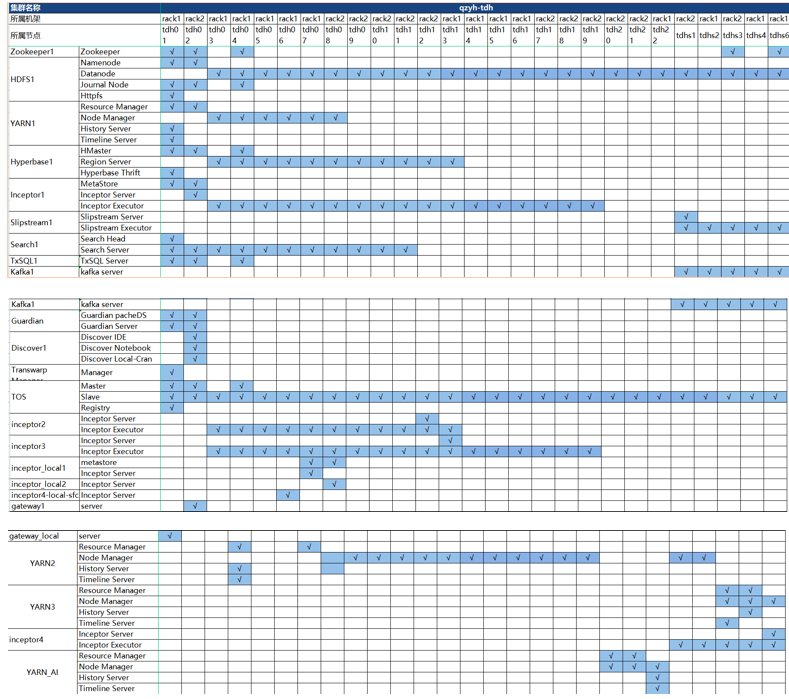
8.角色规划
集群各角色均匀分布在集群节点,详细规划如下:
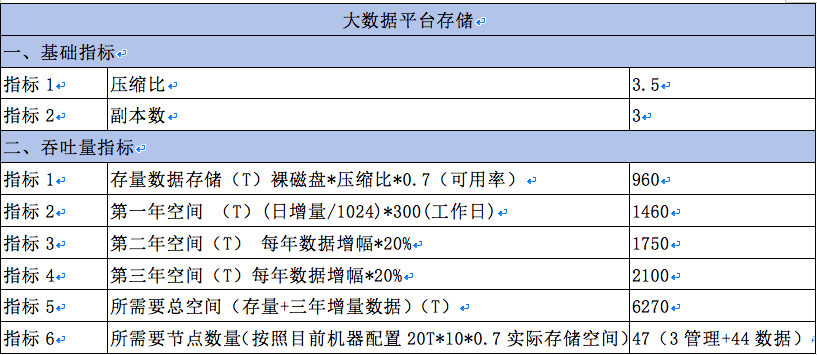
9.容量规划
整体项目容量只要针对存量和增量两大部分进行,下表是我们结合一些数据,对数据仓库迁移所需容量进行的详细规划模拟计算,实际实施时需再根据情况重新计算。
七、一些有意义的尝试
机架感知调整:
HDFS默认情况下虽然有3个副本,理论上能有效的保障数据不丢失,我们为了更有效的提高数据的可用性、可靠性以及更高的网络带宽利用率,可以考虑在实施过程中启用HDFS的机架感知。在默认3副本的情况下,启用机架感知,HDFS的存放策略是将一个副本存放在本地机架节点上,一个副本存放在同一个机架的另一个节点上,最后一个副本放在不同机架的节点上。这样即保证了读写效率,又通过机架的隔离进一步保障了数据安全性。
启用机架感知需要配置文件core-site.xml,配置项如下:
<property>
<name>topology.script.file.name</name>
<value>/etc/hadoop/topology.sh</value>
</property>
value是一个shell脚本,主要的功能是输入DataNode的IP返回对应的机架ID。NameNode启动时会判断是否启用了机架感知,若启用则会根据配置查找配置脚本,并在收到DataNode的心跳时传入其IP获取机架的ID存入内存中的一个map中。一个简单的配置脚本示意如下:
#!/bin/bash
HADOOP_CONF=etc/hadoop/config
while [ $# -gt 0 ] ; do
nodeArg=$1
exec<${HADOOP_CONF}/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]; then
result="${ar[2]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default-rack"
else
echo -n "$result"
fi
done
其中topology.data的格式为:节点(ip或主机名) /交换机xx/机架xx,一个参考配置样例如下:
xxx.xxx.xxx.91 tbe192168147091 /dc1/rack1
xxx.xxx.xxx.92 tbe192168147092 /dc1/rack1
xxx.xxx.xxx.93 tbe192168147093 /dc1/rack2
xxx.xxx.xxx.94 tbe192168147094 /dc1/rack3
xxx.xxx.xxx.95 tbe192168147095 /dc1/rack3
xxx.xxx.xxx.96 tbe192168147096 /dc1/rack3
修改完成后,可以使用./hadoop dfsadmin -printTopology查看机架配置信息。
回收站设置:
为防止在线数据被误删,我们建议在实施时,开启了HDFS的回收站功能,开启后,HDFS会为每个用户创建一个专属的回收站目录(/user/${user.name}/.Trash),用户删除文件时,实际上是被移动到了回收站目录,在紧急情况下能够及时从回收站恢复这些数据。其主要配置示意如下:
<property>
<name>fs.trash.interval</name>
<value>4320</value>
<description>Number of minutes after which the checkpoint gets deleted. If zero, the trash feature is disabled.
</description>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>15</value>
<description>Number of minutes between trash checkpoints.
Should be smaller or equal to fs.trash.interval.
Every time the checkpointer runs it creates a new checkpoint
out of current and removes checkpoints created more than
fs.trash.interval minutes ago.
</description>
</property>
其中,fs.trash.interval表示回收站数据保存周期,单位是分钟,我们建议设置的4320表示保存3天。fs.trash.checkpoint.interval表示回收站数据判断是否需要清理的检查周期,单位是分钟,我们建议设置的15表示15分钟,能有效的平衡资源使用情况。
Reduce参数调节:
在探索过程中,我们曾尝试调整mapred.reduce.tasks的值,试图找出一个适合我行的实际固定参数,减少任务执行时间,降低资源利用率。调节方式是:set mapred.reduce.tasks = 2,如下是示意图:
但在探索验证中,我们发现初始化reduce也会消耗时间和资源,另外,有多少个reduce,就会有多少个输出文件,如果生成了很多小文件,那这些小文件作为下一次任务的输入,则也会出现小文件过多的问题。因此,固定reduce反而不能动态的应对实际生产中的大多数场景,不能带来预期的效果。最终我们建议真实实施时,将其调回默认值-1,由平台根据实际运行情况进行实际的调度。
八、预计效果
我行大数据平台项目从2017年开始建设到现在,已成功的构建了高可靠性、高安全性、高性能、高可扩展性、高灵活性的基础数据区和应用服务区两个集群,切实验证了大数据平台的技术可靠性。我们上述的研究探索也论证了数据仓库迁移到大数据平台的可行性。参考已经真实迁移的同行经验,我们经过估算,在进行数据仓库迁移后,整体造价成本预计有可能下降50%以上(含软硬件、数据库License等),批量作业优化后预计平均提前30分钟完成,对外供数时间预计整体平均提前60分钟左右。
九、小结与展望
根据业界技术的发展趋势以及同业的实践经验可知,为支撑业务更好的发展,传统数据仓库需要做出改变,迁移到大数据平台是其中一个选择。我行大数据平台的建设已培养和验证了我行相关人员在大数据平台上的技术能力,具备了迁移的前期条件。本次的模拟迁移在多个环节上进行了探索,也基本论证的迁移的可行性。
未来如果我们最终选择将数据仓库迁移到大数据平台,我们会继续提升整体的数字能力,通过不断跟踪大数据及相关软硬件领域的最新技术成果,深入研究大数据领域相关技术应用,积极引入各类先进的分析工具,培育数据挖掘和分析技能,进一步打磨大数据平台,算力、算法和数据整合形成数字化力,基于专业引擎的数据计算访问体系、数据分析服务体系、数据挖掘建模体系,最终形成数据应用价值到最终用户的合理传导机制,实现数据发力,让科技酝酿价值!
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞6
添加新评论1 条评论
2022-01-20 15:45