Hadoop集群3台服务器系统异常重分析
1.问题环境基本信息
系统环境
物理机 / 虚拟机 / 云 / 容器:物理机
网络环境
外网 / 私有网络 / 无网络:私有网络
硬件环境
机型:Inspur CS5280H/CS5280H
处理器:Hygo
整机类型 / 架构:X86
软件环境
具体操作系统版本:V10-SP2-Server-0524
内核版本:4.19.90-24.4.v2101.ky10.x86_64
2. 问题描述
三台物理服务器异常重启,通过分析 messages 日志,主要内容是 audit 内存泄漏的输出,通过查看 sar。
日志查看内存空间还有剩余,查看 panic_on_oom 值是 0 。根据以上方式查看了三台机器的 sosreport ,结果都是相似的。目前的排查思路是 audit 占用内存导致的系统重启,但正常情况内存忽然升高 sar 没有记录内存不足,也不会导致系统重启,而应该是夯住。从 messages 日志中未发现有其他记录会导致系统重启。
问题截图
strace 打印 rsync –delete 命令执行的信息



3.问题分析
分析vmcore-dmesg.txt app0 5机器的vmcore-dmesg.txt
c3 b8 f0 ff ff ff 5b c3 66 0f 1f
[7775122.304602] RSP: 0000:ffffb606130378c0 EFLAGS: 00010246
[7775122.304605] RAX: 0000000000000000 RBX: 000000000003774f RCX: ffffb606134b1000
[7775122.304607] RDX: 000000000003774f RSI: ffff98a89fbf0240 RDI: 000000000003774f
[7775122.304609] RBP: fffffc7708c88080 R08: fffffc7708c8ff88 R09: ffff98a8bffd6000
[7775122.304611] R10: fffffc7720fcec00 R11: fffffc7708c8f408 R12: fffffc7708c88000
[7775122.304613] R13: fffffc7708c90000 R14: ffffffffffffffff R15: fffffc7708c88000
[7775122.304617] FS: 00007f3ac85ea700(0000) GS:ffff98a89fbc0000(0000) knlGS:0000000000000000[7775122.304620] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[7775122.304622] CR2: 0000000000000007 CR3: 0000000fd84b8000 CR4: 00000000003406e0
[7775122.304624] Call Trace:
[7775122.304636] split_huge_page_to_list+0x7d8/0x820
[7775122.304641] deferred_split_scan+0x1ba/0x310
[7775122.304647] do_shrink_slab+0x11d/0x2a0
[7775122.304651] shrink_slab+0xd9/0x2b0
[7775122.304656] shrink_node+0xe8/0x410
[7775122.304660] do_try_to_free_pages+0xc9/0x370
[7775122.304664] try_to_free_pages+0xf0/0x1b0
[7775122.304671] __alloc_pages_slowpath+0x37d/0xd10
[7775122.304677] __alloc_pages_nodemask+0x245/0x280
[7775122.304681] alloc_pages_vma+0x7c/0x1f0
[7775122.304688] do_anonymous_page+0x10c/0x400
[7775122.304693] __handle_mm_fault+0x672/0x6b0
[7775122.304698] handle_mm_fault+0xdc/0x230
[7775122.304705] __do_page_fault+0x2b5/0x4e0
[7775122.304713] ? __audit_syscall_exit+0x228/0x290
[7775122.304716] do_page_fault+0x31/0x130
[7775122.304723] ? page_fault+0x8/0x30
[7775122.304726] page_fault+0x1e/0x30
[7775122.304732] RIP: 0033:0x7f3f2c31d6a3
[7775122.304734] Code: 47 10 f3 0f 7f 44 17 e0 f3 0f 7f 47 20 f3 0f 7f 44 17 d0 f3 0f 7f 47
30 f3 0f 7f 44 17 c0 48 01 fa 48 83 e2 c0 48 39 d1 74 c0 0f 7f 01 66 0f 7f 41 10 66 0f
7f 41 20 66 0f 7f 41 30 48 83 c1
[7775122.304736] RSP: 002b:00007f3ac85e9258 EFLAGS: 00010206
[7775122.304739] RAX: 00007f3b0bab600c RBX: 00007f396b689b80 RCX: 00007f3b0bac7000
[7775122.304741] RDX: 00007f3b0bae6400 RSI: 0000000000000000 RDI: 00007f3b0bab600c
[7775122.304742] RBP: 00007f3b0bab6008 R08: 00007f3b0bab6000 R09: 00000000071d50a0
[7775122.304744] R10: 0000000000032000 R11: 0000000007152000 R12: 00007f3bec2fda50
[7775122.304746] R13: 00007f3b0bab640c R14: 0000000000000018 R15: 0000000000030400
[7775122.304749] Modules linked in: esmfile(OE) esmnet(OE) iptable_filter bonding rfkill
sunrpc binfmt_misc vfat fat amd64_edac_mod edac_mce_amd kvm_amd ccp kvm ses enclosure
irqbypass ipmi_si crct10dif_pclmul scsi_transport_sas ipmi_devintf crc32_pclmul
ipmi_msghandler pcspkr joydev ghash_clmulni_intel sg k10temp i2c_piix4 ngbe ip_tables xfs
libcrc32c sd_mod ast i2c_algo_bit drm_kms_helper syscopyarea sysfillrect sysimgblt
fb_sys_fops ttm crc32c_intel i40e ahci drm libahci megaraid_sas libata pinctrl_amd dm_mirror
dm_region_hash dm_log dm_mod [last unloaded: esmnet]
[7775122.304791] CR2: 0000000000000007

crash> dis -l split_swap_cluster+71
/usr/src/debug/kernel-4.19.90/linux-4.19.90-24.4.v2101.ky10.x86_64/mm/swapfile.c: 2960xffffffffa3a73607 :andb$0xfb,0x7
crash>
查看内核源码,可见split_swap_cluster函数原型如下,问题出在mm/swapfile.c的296行,调用的是函数 static inline void cluster_clear_huge(struct swap_cluster_info
*info) ,由于是inline,所以被嵌入到split_swap_cluster。

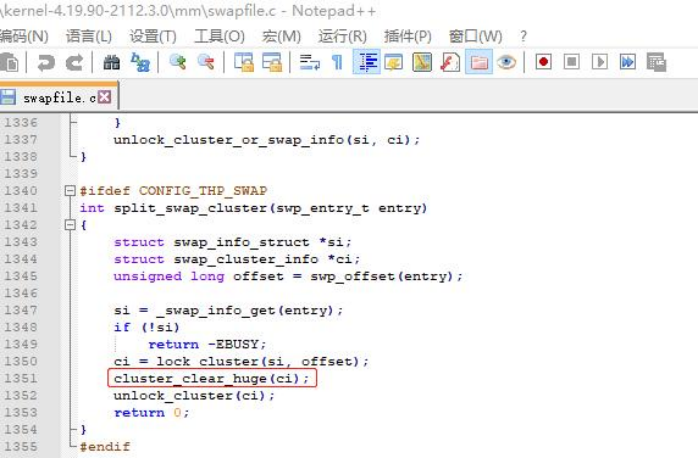
分析cluster_clear_huge(struct swap_cluster_info *info)的函数参数结构体structswap_cluster_info,可见flags在swap_cluster_info中的偏移正好是7 ,如果cluster_clear_huge函数参数info为NULL,则info->flags正好为7。
crash> struct swap_cluster_info -ostruct swap_cluster_info {
[0] spinlock_t lock;
[4] unsigned int data : 24;
[7] unsigned int flags : 8;
}
SIZE: 8
查找网上资料,可见对该问题进行了修复 https://lkml.iu.edu/hypermail/linux/kernel/2009.2/09555.html ,需要cluster_clear_huge函数中对函数参数info进行非NULL判断。


4.问题根因如内核补丁
https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/comm it/?h=linux-4.19.y&id=c4f9c701f9b44299e6adbc58d1a4bb2c40383494
查看hdp app 09机器的vmcore-dmesg.txt 和 hdpapp18机器的vmcore-dmesg.txt,堆栈打印相似都是RIP: 0010:split_swap_cluster+0x47/0x60, unable to handle kernel NULL pointer dereference at 0000000000000007,是同一个问题。
5.问题小结
static inline void cluster_clear_huge(struct swap_cluster_info *info) 函数需要对info进行非NULL判断,才能对info->flag进行赋值,否则如果info为NULL的时候,会触发空指针。
参考链接
1、https://lkml.iu.edu/hypermail/linux/kernel/2009.2/09555.html
2、 https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/commit/?h=linux-4.19.y&;id=c4f9c701f9b44299e6adbc58d1a4bb2c40383494
3、https://access.redhat.com/solutions/5830301
6.问题处理
1、同步社区内核补丁。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞5
添加新评论1 条评论
2023-06-15 14:55