今天遇到了一个HA停止的问题:当停止HA时候,一个节点的HA进程停止了,另一个节点的HA进程还在.
先说下环境,2台P740做了HA,应用是SAP.
操作系统AIX6100-06-08-1216 HA版本:6.1sp09
配置完成HA后,空脚本执行启动和停止HA都没有问题,
然后再用命令启动应用(DB2和SAP,这里用脚本执行,但资源组里的脚本还是空脚本),启动和停止HA仍然没有问题
现在情况,在资源组里的脚本加上上面测试的脚本,启动没有问题,但是停止的时候,一个节点A的HA进程都停了,
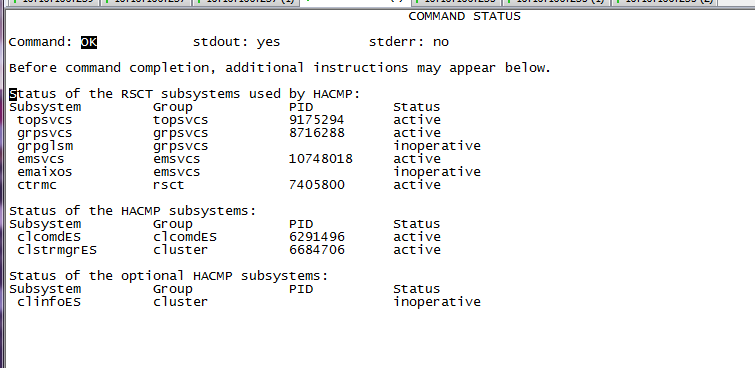
但是B节点的HA还在,如下图,不知道什么问题麻烦大家帮忙解决下.
停止HA后,HA进程应该如下图:inoperative状态,但是另一个节点的状态还是active

另一个B节点的HA关闭不了,
以下是hacmp.out的一些log
:cl_sel[148] ls -rt1 /tmp/ibmsupt/hacmp/eventlogs.2012.10.10.16.06.Z /tmp/ibmsupt/hacmp/event
logs.2012.10.10.16.11.Z /tmp/ibmsupt/hacmp/eventlogs.2012.10.10.17.20.Z /tmp/ibmsupt/hacmp/ev
entlogs.2012.10.10.17.26.Z /tmp/ibmsupt/hacmp/eventlogs.2012.10.10.21.55.Z /tmp/ibmsupt/hacmp
/eventlogs.2012.10.10.22.01.Z
:cl_sel[148] FFDC_LIST=/tmp/ibmsupt/hacmp/eventlogs.2012.10.10.16.06.Z
:cl_sel[151] rm -f /tmp/ibmsupt/hacmp/eventlogs.2012.10.10.16.06.Z
:cl_sel[155] dspmsg scripts.cat 10059 'FFDC event log collection saved to /tmp/ibmsupt/hacmp/
eventlogs.2012.10.10.22.01n' /tmp/ibmsupt/hacmp/eventlogs.2012.10.10.22.01
FFDC event log collection saved to /tmp/ibmsupt/hacmp/eventlogs.2012.10.10.22.01
:cl_sel[157] exit 0
WARNING: Cluster sapcluster has been running recovery program 'TE_FAIL_NODE' for 360 seconds.
Please check cluster status.
WARNING: Cluster sapcluster has been running recovery program 'TE_FAIL_NODE' for 390 seconds.
Please check cluster status.
WARNING: Cluster sapcluster has been running recovery program 'TE_FAIL_NODE' for 420 seconds.
Please check cluster status.
WARNING: Cluster sapcluster has been running recovery program 'TE_FAIL_NODE' for 450 seconds.
Please check cluster status.
WARNING: Cluster sapcluster has been running recovery program 'TE_FAIL_NODE' for 480 seconds.
Please check cluster status.
WARNING: Cluster sapcluster has been running recovery program 'TE_FAIL_NODE' for 540 seconds.
Please check cluster status.
加入现在要重新启动HA的话,报了ha的进程还在
Command: failed stdout: yes stderr: no
Before command completion, additional instructions may appear below.
Verifying Cluster Configuration Prior to Starting Cluster Services.
WARNING: Node(s): prd1 requested to start cluster services.
These nodes are already running cluster services and will not be started.
麻烦大家帮忙下.....................
收起