1同行回答
证券 运维日志管理与日志分析平台采用ELK Stack搭建,ELK Stack是三个开源产品Elasticsearch,Logstash和Kibana的集合。Logstash负责数据收集、传输、预处理。Elasticsearch负责数据存储、分析。Kibana负责数据展现。这三者的有机结合为 证券 运维日志管理与日志分析提供了完整的解决方案。下图是ELK Stack的日志数据处理 基础架构 图: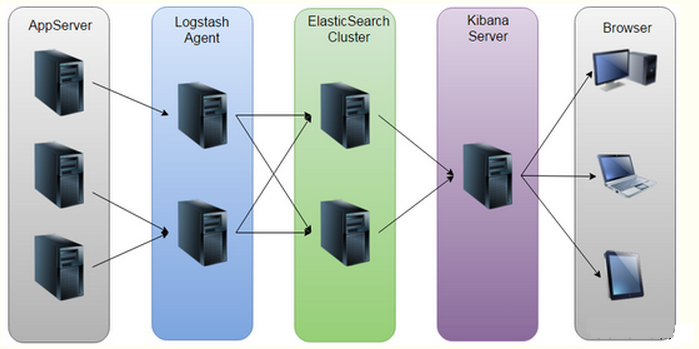
按照 ELK Stack 的数据处理流程和 证券 企业 运维 对 日志管理 与 日志分析 的要求设计 证券 日志管理分析平台。 Elasticsearch(ES)集群的规划, 搭建一个集群我们需要考虑如下几个问题:
- 我们需要多大规模的集群 : 证券 企业 当前的 日志 数据量 大约有 10TB, 数据 年增长率大约10%,ES JVM heap 可以设置32G ,大概能处理的数据量 10TB,考虑未来五年数据量的发展要求ES服务器配置128GB的内存就可以满足需求,随着数据量的增长后续还可以按需扩展。
- 集群中的节点角色如何分配:集群中的节点角色包括主节点、数据节点和协调节点三种,当Master node.master: true 节点可以作为主节点,当DataNode node.data: true 默认是数据节点。当Coordinate node仅担任协调节点时将上两个配置设为false。注:一个节点可以充当一个或多个角色,默认三个角色都有,协调节点是一个只作为接收请求、转发请求到其他节点、汇总各个节点返回数据等功能的节点。
- 如何避免脑裂问题:一个集群中只有一个A主节点,A主节点因为需要处理的东西太多或者网络过于繁忙,从而导致其他从节点ping不通A主节点,这样其他从节点就会认为A主节点不可用了,就会重新选出一个新的主节点B。过了一会A主节点恢复正常了,这样就出现了两个主节点,导致一部分数据来源于A主节点,另外一部分数据来源于B主节点,出现数据不一致问题,这就是脑裂。配置discovery.zen.minimum_master_nodes: (有master资格节点数/2) + 1,这个参数控制的是,选举主节点时需要看到最少多少个具有master资格的活节点,才能进行选举。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
- 索引应该设置多少个分片:ElasticSearch推荐的最大JVM堆空间是30~32G, 所以把你的分片最大容量限制为30GB, 然后再对分片数量做合理估算. 例如, 你认为你的数据能达到200GB, 推荐你最多分配7到8个分片。在开始阶段, 一个好的方案是根据你的节点数量按照1.5~3倍的原则来创建分片. 例如,如果你有3个节点, 则推荐你创建的分片数最多不超过9(3x3)个。当性能下降时,增加节点,ES会平衡分片的放置。对于基于日期的索引需求, 并且对索引数据的搜索场景非常少。也许这些索引量将达到成百上千, 但每个索引的数据量只有1GB甚至更小。对于这种类似场景, 建议只需要为索引分配1个分片。如日志管理就是一个日期的索引需求,日期索引会很多,但每个索引存放的日志数据量就很少。
Logstash在 证券 运维日志管理与日志分析平台 中从 网络设备、防火墙、中间件、 证券交易 系统、内外部接口(如 资金管理 、 帐务核算 、 融资融券 )等 收集数据,并且按照预先编写好的过滤规则来过滤数据,然后按照要求将日志传输到ES集群中 。
Logstash根据logstash-example.conf配置文件对数据源进行数据读取和清洗,并将清洗结果写入指定的目标文件。Logstash可以以命令行参数进行配置,也可以在logstash.yml等setting文件中进行设置。
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
Elasticsearch 集群 收到的数据会被写入到内存的buffer 中,然后在一定的时间间隔后刷到磁盘中,成为一个新的segment,然后另外使用一个commit文件来记录所有的 segment,数据只有在成为segment之后才能被检索。默认的从buffer到segment 的时间间隔是1秒(可以调用/_refresh接口更改)。
采用Translog 保证数据从 buffer 到 segment 的一致性,通过定期保存到磁盘中来实现Translog 的一致性。对于不断生成新的segment,ES 会在后台把零散的 segment 做数据归并,归并完成后删除小的 segment,从而减少 segment 的数量;也会采用不同的归并策略,尽量让每次新生成的 segment 本身就比较大。
为了提高Elasticsearch性能可以通过elasticsearch.yml文件修改配置参数,也可以根据用户系统配置降低配置参数,如jvm.heapsize。
Kibana是一个开源的分析与可视化平台。可以用来搜索、查看、交互存放在Elasticsearch索引里的数据,并使用各种不同的图表、表格、地图等对数据进行分析和可视化。
Kibana3是一个使用Apache开源协议,基于浏览器的Elasticsearch分析和搜索的仪表板,整个项目基于HTML和Javascript写的,不需要任何服务器端组件,一个纯文本发布服务器即可。
Kibana4中Discover标签页可以提交搜索请求,过滤结果,然后检查返回的文档里的数据,默认情况下,Discover显示匹配搜索条件的500个文档。Visualization 用来为搜索结果做可视化,每个可视化都是跟一个搜索关联着的。Dashboard 创建、定制自己的仪表盘。任何需要展示的数据都需要现在 Settings 中进行索引配置,可以选择配置时间索引,这样在 Discover 页面会多出来时间的选项。
Kibana3中config.js核心配置的地方,文件包含的参数都是必须在初次运行Kibana之前提前设置好的。
Kibana4启动,在安装目录运行:
$bin/kibana (Linux/Mac OS X)
$bin\kibana.bat (Windows)
配置可以通过命令行参数或配置文件kibana.yml。
证券 运维日志管理与日志分析平台采用ELK Stack搭建 ,实现了网络与安全设备、服务器、操作系统、中间件、数据库,业务系统等日志数据的自动收集处理与分析展现,降低了运维人员的工作复杂度,提高了运维效率,帮助运维人员 更好地监控、 管理软硬件与业务 系统,真正实现高效、可视化运维。
收起