DeepFlow 是如何通过 Wasm Plugin 实现业务可观测性?
今天我们来聊一下可观测性领域的核心项目—— DeepFlow,即 “基于 eBPF 和 Wasm 技术,实现 Zero Code ( 零侵扰 )和 Full Stack ( 全栈 )的可观测性 ” 。
如何定义 DeepFlow Wasm Plugin?
DeepFlow 的 Wasm Plugin 机制是整个 DeepFlow Pipeline 机制中的重要组成部分,它为用户提供了一个可编程的、安全的和资源消耗可控的运行沙箱环境。此机制为 deepflow-agent 增加了灵活性和可扩展性,使用户能够以一种安全可靠的方式自定义和扩展代理的功能。
1、Wasm Plugin 机制为用户提供了可编程性
通过使用 Wasm 编程语言,用户可以编写自定义的插件逻辑,以满足特定的需求和应用场景。这种可编程性使得用户能够根据具体的业务需求,对流量进行更细粒度的处理和分析。用户可以通过编写自定义的 Wasm 模块来实现特定的协议解析、数据处理、安全策略等功能,从而高度定制化代理的行为。
2、Wasm Plugin 机制提供了安全性
Wasm Plugin 运行在一个安全的沙箱环境中,这意味着插件的执行受到严格的限制和监控,以确保其不会对代理的稳定性和安全性造成威胁。Wasm 的设计理念和安全机制使得插件的运行受到严格的隔离,防止恶意插件对代理或底层系统进行攻击或滥用资源。这种安全性保证了代理的运行环境的可信度和可靠性。
3、Wasm Plugin 机制还具有资源消耗可控性
通过限制插件的资源使用,例如 CPU 时间、内存等,Agent 可以有效地控制插件的运行消耗,以避免插件对代理性能产生不利影响。 这种资源消耗可控性使得代理能够在处理大规模流量时保持高效和稳定,避免因插件的运行而引起的性能下降或崩溃。
综上,DeepFlow Wasm Plugin 机制通过增强原生支持的协议、支持私有协议解析、提供零侵扰分布式追踪和自定义脱敏功能等,为用户提供了更强大和灵活的工具。这些增强功能使得用户能够深入分析和处理协议数据,满足不同业务场景需求,并提升系统的性能、安全性和可扩展性。
DeepFlow Wasm Plugin 到底是如何工作的?
在深入了解 Wasm Plugin 的执行流程之前,建议先对 Deepflow 协议解析有一个基本的认识。了解 Deepflow 协议解析的概念和原理可以为理解 Wasm Plugin 的执行流程提供有益的背景知识。
当我们提及 Wasm Plugin 时,通常作用于 Web 浏览器中执行高性能的计算任务,而 Deepflow 协议解析则涉及到数据传输和处理的协议层面。通过深入了解 Deepflow 协议解析,我们可以更好地理解 Wasm Plugin 在数据传输和处理过程中的作用和应用。因此,在探讨 Wasm Plugin 的执行流程之前,对 Deepflow 协议解析进行一个基本的认识是非常有帮助的,它为我们建立起了一个更完整和全面的技术背景,使我们能够更好地理解和应用 Wasm Plugin 的相关概念和功能。
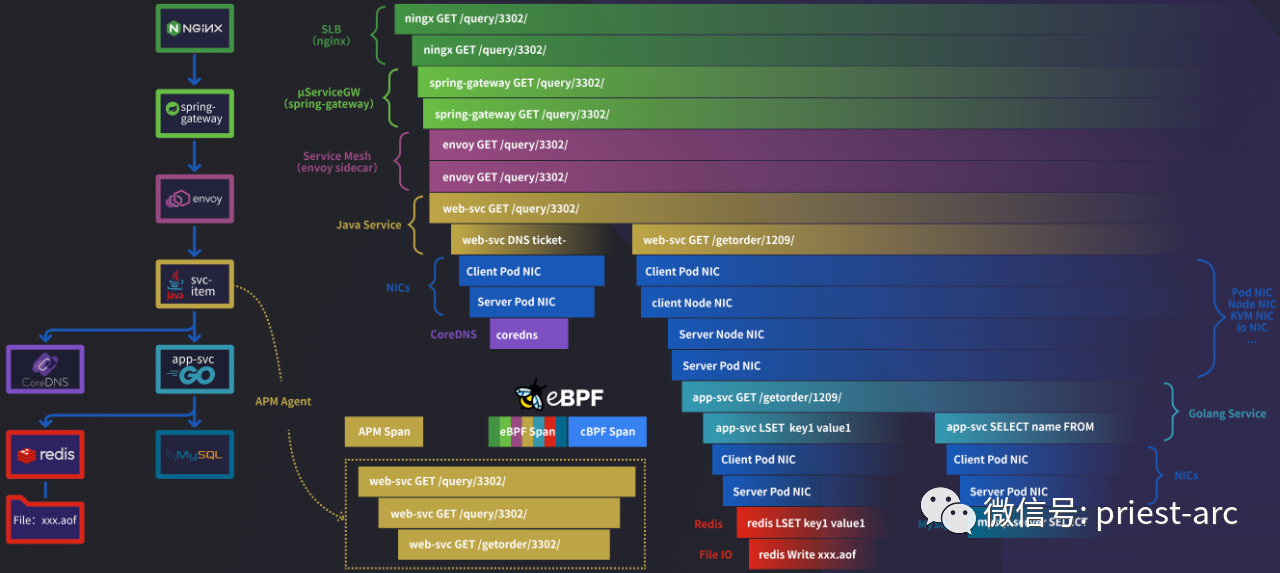
在 deepflow-agent 中,数据包从原始字节转化为应用层结构的过程涉及以下几个关键阶段。在这些阶段中,我们会使用到一些重要的数据结构和接口,它们发挥着关键的作用,具体可参考:
1、L7Protocol(第七层协议):其源码位于 l7_protocol.rs 文件中。L7Protocol 用于标识不同的协议常量,例如 HTTP、HTTPS、DNS 等。通过使用 L7Protocol,我们可以在流量中准确地识别和标记不同的应用层协议。
2、L7ProtocolParser(第七层协议解析器):其源码位于 l7_protocol_log.rs 文件中。这个 trait 主要用于协议的判断和解析,它能够根据特定的规则和模式,从流量数据中解析出 L7ProtocolInfo(第七层协议信息)。L7ProtocolParser 的实现类可以根据具体的协议特征,进行解析和识别,从而获得有关协议的详细信息。
3、L7ProtocolInfo(第七层协议信息):其源码位于 l7_protocol_info.rs 文件中。L7ProtocolInfo 是由 L7ProtocolParser 解析出来的数据结构,它包含了有关协议的详细信息,例如协议类型、协议版本、源IP地址、目标IP地址等。L7ProtocolInfo 在后续的会话聚合和分析中发挥着重要的作用。
4、L7ProtocolInfoInterface(第七层协议信息接口):其源码同样位于 l7_protocol_info.rs 文件中。所有的 L7ProtocolInfo 都需要实现这个接口,以提供一致的方法和属性。通过实现 L7ProtocolInfoInterface,我们可以对协议信息进行统一的操作和处理,以满足后续的需求。
5、L7ProtocolSendLog(发送到深度流分析服务器的第七层协议日志):其源码位于 pb_adapter.rs 文件中。L7ProtocolSendLog 是一个结构体,用于将解析后的第七层协议信息统一发送到深度流分析服务器。通过使用 L7ProtocolSendLog,我们可以将协议信息传递给服务器进行进一步的处理和分析。
通过以上组件和接口的协同工作,deepflow-agent 能够准确地识别和解析不同的应用层协议,并将相关的协议信息发送到 deepflow-server器,为后续的流量分析和应用提供有价值的数据基础。这些组件和接口的设计和实现,为 deepflow-agent 的功能和性能提供了坚实的基础。
综上所述,针对 Deepflow 协议解析而言,其 整体的流程可概括为如下: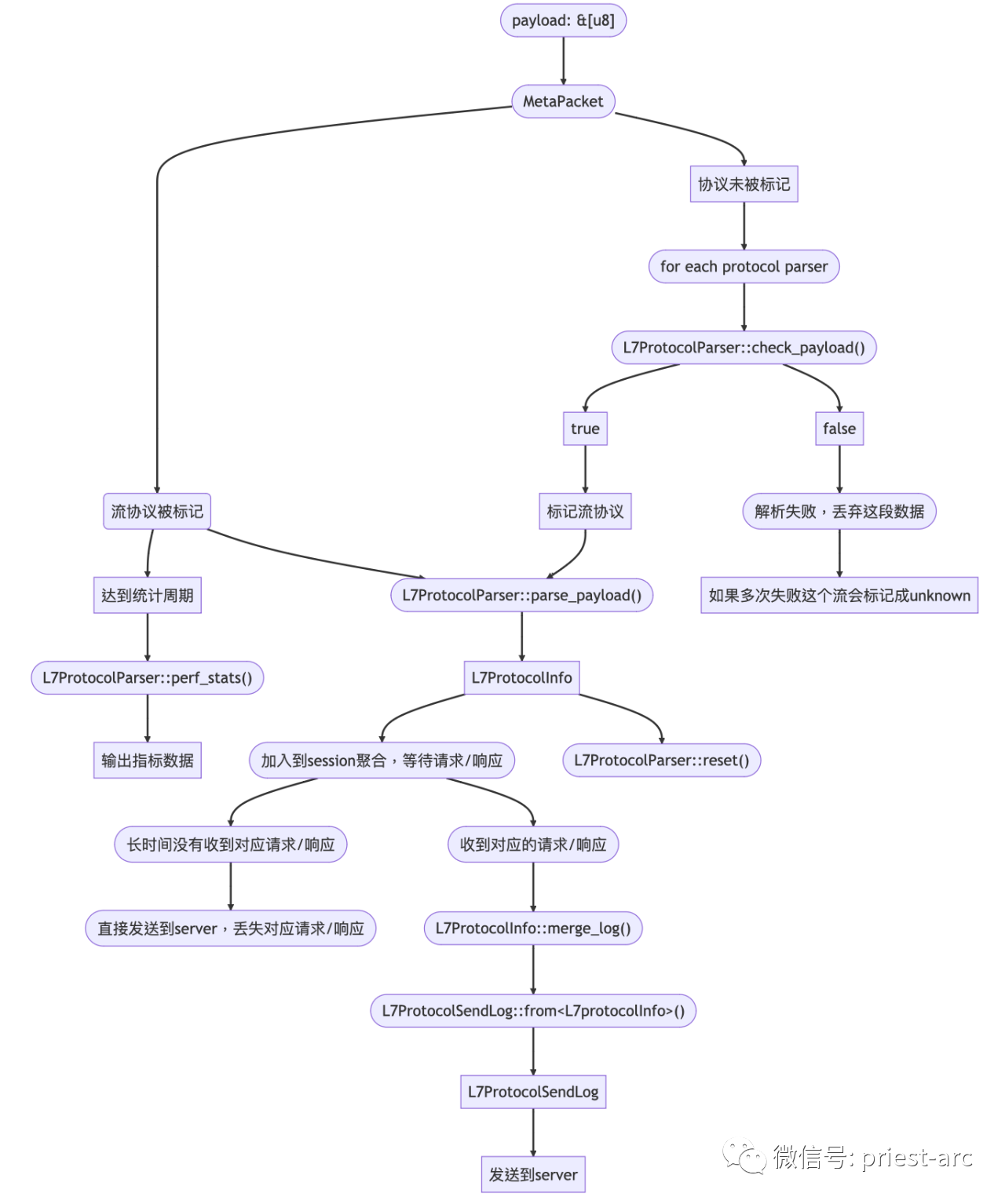
了解完 Deepflow 的协议解析后,我们回到 Wasm plugin,Wasm plugin 整体的执行流程如下所示:
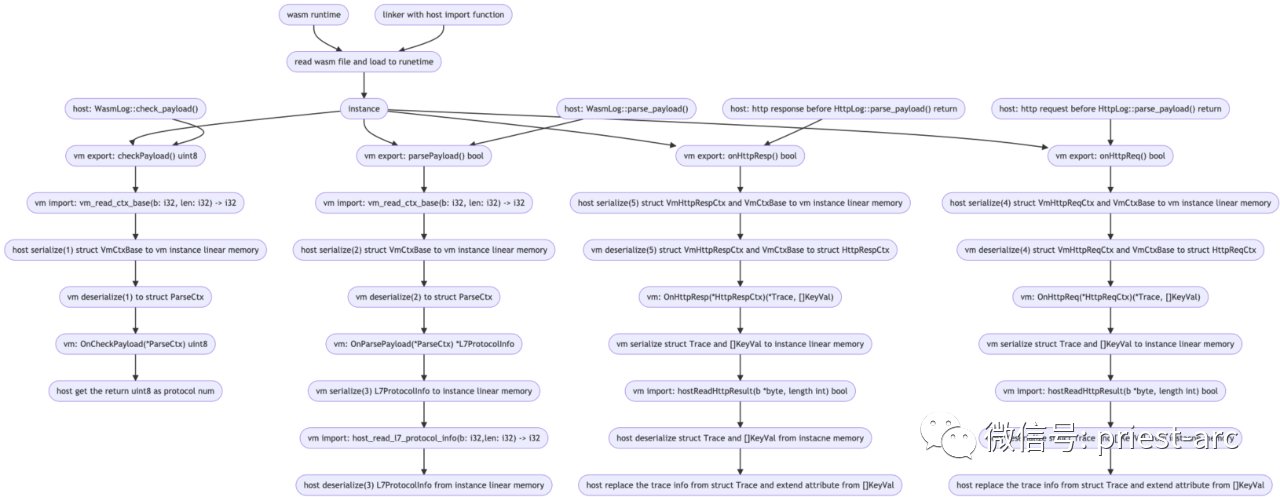
针对上述执行流程结构,其中序列化/反序列化的结构主要涉及如下6个,具体可参考如下:
VmCtxBase
- 在目前所有的 Export 函数调用的时候,host 会将 VmCtxBase 序列化到线性内存,序列化的格式参考:vm.rs#L199
- 同样地,instance 也会反序列化,具体代码可以参考:mod.rs#L152
L7ProtocolInfo
- 在 Export 函数 parse_payload 最后,instance 会序列化 L7ProtocolInfo 到线性内存,
- host 也会反序列化。
VmHttpReqCtx
- 在 http 请求解析完成返回之前,会调用 Export 函数 on_http_req,host 会序列化 VmCtxBase 和 VmHttpReqCtx 到 instance 的线性内存
- VmHttpReqCtx 的序列化的代码和格式可以参考:vm.rs#L328
- instance 反序列化的代码参考:serde.go#L173
VmHttpRespCtx
- 在 http 响应解析完成返回之前,会调用 Export 函数 on_http_resp,host 会序列化 VmCtxBase 和 VmHttpRespCtx 到 instance 的线性内存
- VmHttpRespCtx 的序列化的格式参考:vm.rs#L395
- instance 反序列化的代码参考:serde.go#L232
Trace,[]KeyVal
- 在 Export 函数 on_http_req/on_http_resp 返回之前,instance 会将 Trace 和 []KeyVal 序列化到线性内存
- 序列化的代码和格式可以参考:serde.go#L515
- 反序列化的代码和格式可参考:abi_import.rs#L376
如何基于 Golang SDK 开发 DeepFlow Wasm Plugin ?
通常而言,Wasm Plugin 可支持多种语言进行开发。这里,我们以 Golang 为例,简要解析如何使用 Golang 快速开发 Wasm Plugin。需要注意的是,本项目中 Golang SDK 编译需要用到 TinyGo 工具链。
为什么需要 TinyGo ?
TinyGo 是一个专门为嵌入式设备和 WebAssembly(Wasm)环境设计的 Go 编程语言工具链。它是 Go 语言的一个轻量级替代品,旨在在资源受限的环境中运行和编译 Go 代码。
TinyGo 的目标是提供一个高效的 Go 编译器和运行时环境,以便在小型设备和嵌入式系统上运行 Go 程序。相较于标准的 Go 编译器,TinyGo 优化了编译输出的大小和性能,以适应资源受限的环境。这使得开发者可以使用 Go 语言的简洁性和强大的工具生态系统来构建嵌入式系统、物联网设备和其他资源有限的应用。
除了针对嵌入式设备,TinyGo 还支持 WebAssembly,使得开发者可以使用 Go 语言编写的代码在 Web 浏览器环境中运行。这使得开发者可以在浏览器中直接运行高性能的 Go 代码,从而扩展了 Go 语言的应用范围。
针对 Wasm Plugin 的开发实现,我们可以参考:https://deepflow.io/docs/zh/integration/process/wasm-plugin/,其关键步骤主要涉及如下,具体:
1、 获取 Golang SDK 进行项目创建
go mod init {ProjectName}
go get github.com/deepflowio/deepflow-wasm-go-sdk
需要注意的是:确保在执行这些命令之前,已经正确设置了 Go 开发环境,并且可以访问 GitHub。
2、 实现协议解析逻辑
package main
import (
"github.com/deepflowio/deepflow-wasm-go-sdk/sdk"
)
func main(){
sdk.Warn("plugin loaded")
sdk.SetParser(SomeParser{})
}
type SomeParser struct {
}
func (p SomeParser) HookIn() []sdk.HookBitmap {
return []sdk.HookBitmap{
// 一般只需要 hook 协议解析
sdk.HOOK_POINT_PAYLOAD_PARSE,
}
}
func (p SomeParser) OnHttpReq(ctx *sdk.HttpReqCtx) sdk.Action {
return sdk.ActionNext()
}
func (p SomeParser) OnHttpResp(ctx *sdk.HttpRespCtx) sdk.Action {
return sdk.ActionNext()
}
func (p SomeParser) OnCheckPayload(ctx *sdk.ParseCtx) (uint8, string) {
// 这里是协议判断的逻辑, 返回 0 表示失败
// return 0, "" return 1, "some protocol"
}
func (p SomeParser) OnParsePayload(ctx *sdk.ParseCtx) sdk.Action {
// 这里是解析协议的逻辑
if ctx.L4 != sdk.TCP|| ctx.L7 != 1{
return sdk.ActionNext()
}
return sdk.ActionNext()
}
注:以上是一个简单的插件示例,展示了如何使用 "deepflowio/deepflow-wasm-go-sdk" 库来开发自定义的插件,并实现不同的回调函数来处理网络数据包。在实际的业务场景中,我们可以根据自己的需求进一步扩展和修改这些回调函数的实现逻辑,以满足自身的场景诉求。
3、编译为 Wasm Plugin
建议 go 版本不低于1.21,tinygo 版本不低于 0.29tinygo build -o wasm.wasm -target wasi -gc=precise -panic=trap -scheduler=none -no-debug *.go
执行命令后,将会生成名为"wasm.wasm"的WebAssembly文件,可以在支持 WebAssembly 的环境中加载和运行。
Wasm Plugin 开发完后,我们需要将其部署至 DeepFlow 中,针对 Wasm Plugin 的部署主要涉及如下步骤:
1、将编译好的插件上传至 Deepflow-Server
deepflow-ctl plugin create --type wasm --image wasm.wasm --name wasm-devops
执行命令后,Deepflow-ctl 将会创建一个名为"wasm-devops"的 WebAssembly 插件,并将指定的 WebAssembly 文件作为插件的执行代码。我们可以根据需要进一步配置和管理这个插件。
2、Agent 端加载 Wasm Plugin
static_config:
ebpf:
对于 deepflow-agent 原生不支持的协议, eBPF 数据需要添加端口白名单才能上报
kprobe-whitelist:
port-list: 9999
如果配置了 l7-protocol-enabled,别忘了放行 Custom 类型的协议
l7-protocol-enabled:
Custom
other protocol
wasm-plugins:
wasm-devops // 对应 deepflow-ctl 上传插件的名称
注:目前修改此配置后 deepflow-agent 会自动重启。
3、验证是否成功加载
kubectl -n deepflow logs -f deepflow-agent-xxxxx | grep -i plugin
至此,一个 Wasm Plugin 已成功开发完成,并应用至我们的业务场景中。
案例分享 - 解析 JSON 中的错误信息
在此案例中,被监控 HTTP API 的响应消息为 JSON 格式,当 API 出错时 HTTP 协议的状态码可能仍然是 200,确切的错误信息通过 JSON 中的 OPT_STATUS 等字段返回:
{ "OPT_STATUS": "AUTH_HEADER_ERROR", // 不等于 SUCCESS 时表示调用失败
"DESCRIPTION": "请传递正确的验证头信息", // 详细错误信息
... // 其他返回字段
}
查阅 API 文档后我们得知,OPT_STATUS 的值不等于 SUCCESS 时表示 API 调用失败。 在常规的 DeepFlow 解析流程中,会按照如下方式构造 HTTP 调用日志的各个字段:
- response_code:赋值为 HTTP 响应头中的状态码,例如 200、404、500 等
- response_status:状态码小于 400 时认为正常,4XX 认为是客户端异常,5XX 认为是服务端异常
- response_exception:赋值为 HTTP 异常状态码对应的英文解释,例如 404 时此字段赋值为 Not Found
- response_result:当 HTTP 状态码为异常时赋值为整个 HTTP Payload
当我们安装了 Wasm 插件后,我们可以在上述解析的基础上,将失败 API 的调用日志中的如下字段进行覆写,以实现正确体现业务错误的效果:
- response_code:当 JSON 中 OPT_STATUS != SUCCESS、且 HTTP 状态码小于 400 时,此值覆写为 500
- response_status:按照新的 response_code 重新赋值,例如 500 时赋值为服务端异常
- response_exception:当 JSON 中的 OPT_STATUS != SUCCESS时覆写为 DESCRIPTION 字段的值
- response_result:当 response_code 大于等于 400 时赋值为整个 JSON Payload
我们将 Wasm 插件代码放到了 这个 GitHub 仓库 中。上述 API 行为描述的实际上是 DeepFlow 企业版中的 statistics 服务,下面演示将此 Wasm 插件注入到 DeepFlow Agent 以后,对 DeepFlow 企业版服务的自我观测效果。首先我们在命令行中触发一次 statistics 服务的 API 调用:
请求curl https://cloud.deepflow.io/api/statistics/v1/stats/querier/DBDescription/ShowDatabases
HTTP 响应头
HTTP/2 401
date: Tue, 22 Aug 2023 01:44:29 GMT
content-type: application/json
content-length: 152
HTTP 响应体
{
"DATA": false,
"DESCRIPTION": "请传递正确的验证头信息",
"ERR": null,
"LEVEL": 0,
"OPT_STATUS": "AUTH_HEADER_ERROR"
}
上述 API 响应中,HTTP 的状态码为 401,OPT_STATUS=AUTH_HEADER_ERROR。我们能在 DeepFlow 页面正确的看到客户端异常指标(本例中插件注入在 cloud.deepflow K8s 集群的 deepflow-agent 中):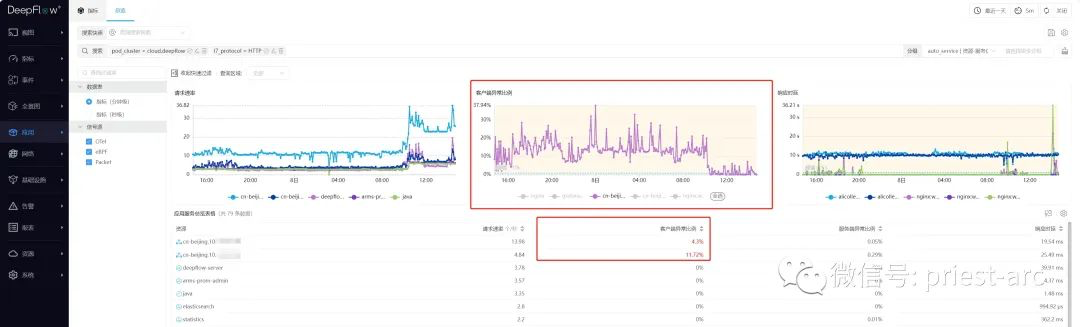
在 DeepFlow 调用日志页面,可以看到客户端异常的调用日志的详情信息,整个 JSON body 放在了 response_result里面: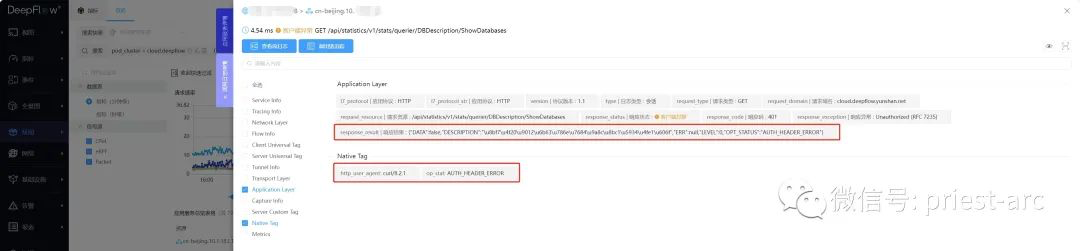
对该调用发起追踪,能看到是因为fauths返回的 401 异常:
下面是详细的调用链。第一步发起 DNS 请求: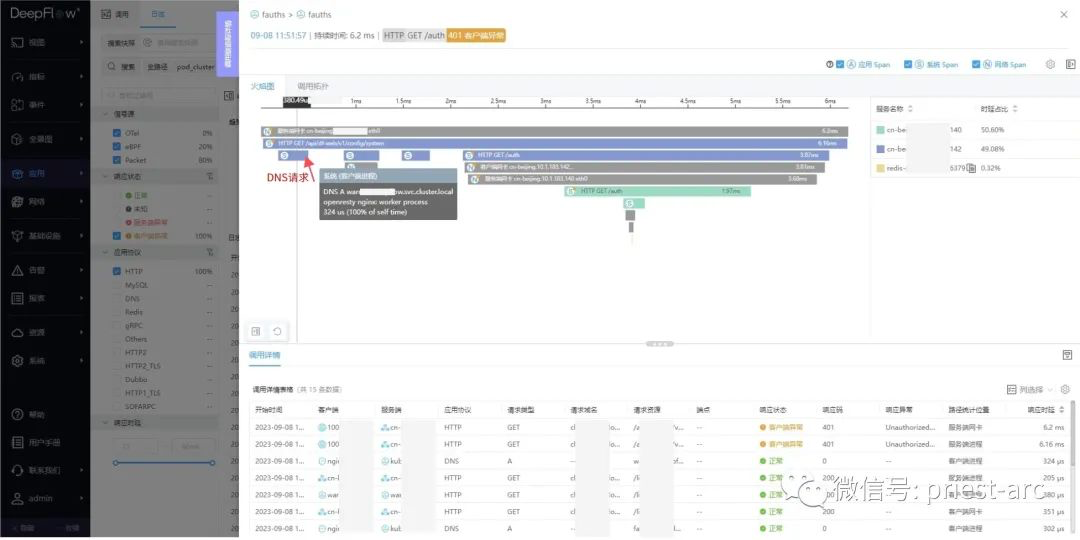
第二步调用后端服务验证 License: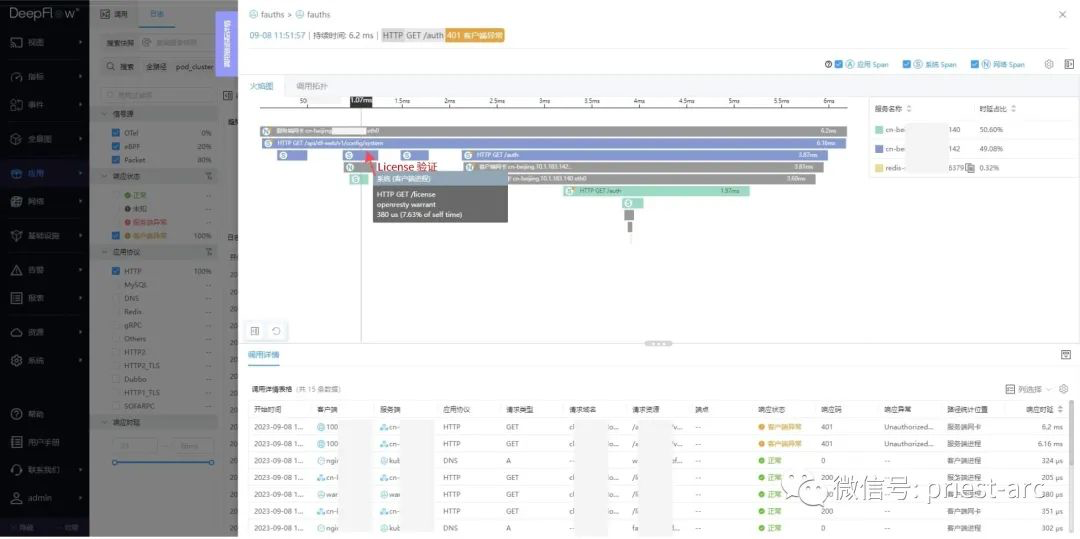
第三步发起 DNS 请求 fauths 服务的地址:
第四步调用 fauth 的 /auth API 验证权限,中间需要访问 Redis 获取用户信息: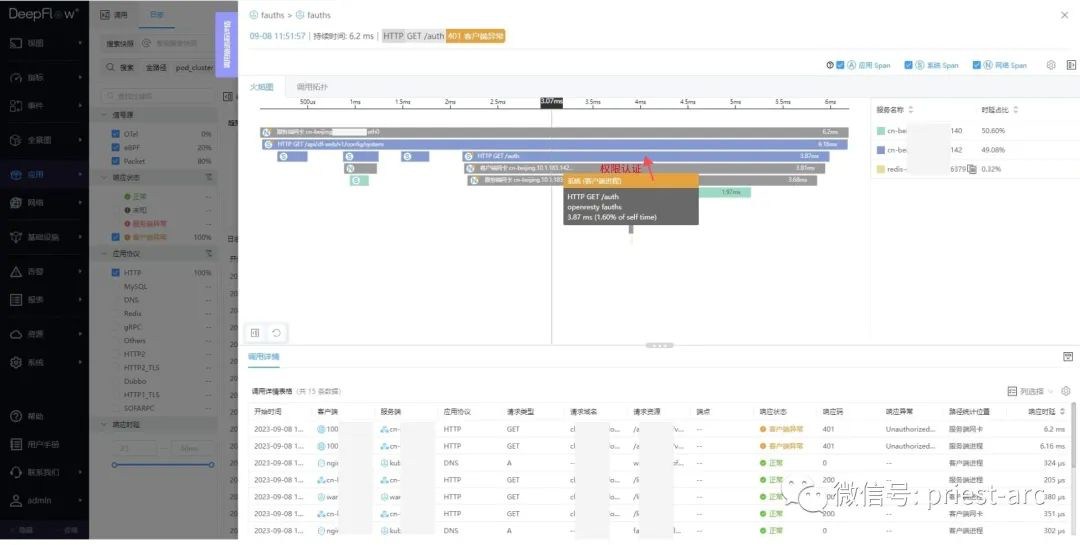
上述案例展示了 DeepFlow 中Wasm Plugin 机制的强大能力,使得在实际业务场景中能够轻松解决问题的跟踪、定位和分析。
通过使用自定义的 Wasm Plugin,我们可以针对特定需求开发定制化的功能,如解析 JSON 中的错误信息。这种能力使得我们能够在流量处理过程中灵活地捕捉和处理问题,无论是在调试阶段还是在生产环境中。
使用 DeepFlow 的 Wasm Plugin 机制,我们可以轻松地扩展原生协议的解析能力,提取更多的业务信息。特别是对于私有协议,如 Protobuf 和 Thrift,我们可以通过自定义插件来解析这些依赖 Schema 的 Payload 内容,从中提取关键的业务字段。这为我们深入了解协议数据提供了便利,使得我们能够更好地理解和利用数据。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞2作者其他文章
评论 1 · 赞 0
评论 0 · 赞 1
评论 4 · 赞 2
评论 4 · 赞 1
评论 6 · 赞 1
添加新评论0 条评论