一文带你深入探索eBPF可观测性技术底层奥秘
Hello folks,我是 Luga,今天我们来聊一下 云原生生态核心技术—— 可观测性,即 “eBPF 观测 ak” 。
当今,可观测性领域正在经历一场颠覆性的转变,其中核心驱动力便是 “eBPF”(扩展伯克利数据包过滤器)技术。作为下一代改革先锋,eBPF 技术正在彻底改变我们对系统观测和监控的认知。在之前的文章中,我们已经详细介绍了 eBPF 技术及其对可观测性的影响。
在本篇博文中,我们将深入探索下一代可观测性技术 eBPF 所涉及的底层奥秘。然而,在深入讨论之前,让我们简要回顾一下 eBPF 的概念和原理。
认识不一样的 eBPF
eBPF(Extended Berkeley Packet Filter)是一个强大的编程框架,旨在在 Linux 内核中安全地运行沙盒程序,而无需对内核代码进行修改。eBPF 最初是为 Linux 开发的,目前仍然是该技术领域最成熟和广泛应用的平台。然而,令人振奋的是,Microsoft 目前也正在积极推进 eBPF 在 Windows 操作系统上的实现,为 Windows 用户带来了更多的机会和潜力。
eBPF 的设计注重高效性和安全性,这使得成为许多网络和系统开发人员的首选工具。eBPF 程序经过内核验证,以确保它们不会对操作系统的稳定性或安全性造成任何威胁。这意味着开发人员可以放心地使用 eBPF 来编写高性能的网络过滤器、安全工具、性能监控和调试工具等应用程序,而无需担心对系统的影响。
通过使用 eBPF,开发人员可以利用其丰富的功能和灵活的编程模型来实现各种功能。eBPF 可以在数据包级别对网络流量进行高效地过滤和处理,从而实现网络安全和流量控制。此外,eBPF 还可以用于系统性能分析和调优,通过在内核中收集和分析性能相关的数据,帮助开发人员发现和解决性能瓶颈。
为了理解这一点,我们再来回顾一下用户空间(User space)和内核空间 (Kernel space ) 的概念。

用户空间 (User space ) 是应用程序运行的环境,是应用程序的执行区域,但不能直接访问物理硬件。相反,应用程序通过系统调用与内核进行交互,请求内核执行特定的操作。
内核空间 (Kernel space ) 位于用户空间 (User space ) 和物理硬件 (Physical hardware ) 之间,充当了一个中介。内核空间负责管理系统的硬件资源和提供对这些资源的访问权限。它接收来自用户空间的系统调用,并根据请求执行相应的操作。
用户空间中的应用程序通过系统调用与内核进行通信,以获取对硬件的访问权限。例如,当应用程序需要访问内存、进行文件读写或进行网络通信时,它会发起系统调用请求,由内核代表应用程序执行相应的操作。
内核负责管理内存访问,文件读写和网络流量等系统资源。它还处理进程的并发管理,确保多个应用程序能够在系统中同时运行而不互相干扰。
简而言之,所有与系统资源的交互都通过内核 (Kernel space ) 进行。具体可参考如下图所示:
eBPF 在生产环境的落地及应用
其实,纵观可观测性技术的演进,围绕 eBPF 的技术已经发展了很长一段时间,并且已经发展了约 30 年。
自从 2014 年 eBPF 技术的问世以来,在过去的几年发展岁月里,eBPF 已经被多家大公司大规模使用,现在我们正在进入一个 eBPF 的使用逐渐成为主流的时代。
1、2016 年,Netflix 成为广泛采用 eBPF 进行跟踪的先驱,该方案的实施者Brendan Gregg 因其在基础设施和运营领域的专业知识而成为 eBPF 的权威人物。
2、2017 年, Facebook 开源了 基于 eBPF 技术, 名为 Katran 的负载均衡器。自那时起,每个发送到 Facebook.com 的数据包都经过 eBPF 处理,从而显示了 eBPF 在 Facebook 的网络架构中的重要性。
3、 2020 年,Google 将 eBPF 纳入其 Kubernetes 产品的一部分。eBPF 现在为Google Kubernetes Engine(GKE)的网络、安全和可观察层提供支持。此外,像Capital One 和 Adobe 等公司也广泛采用了 eBPF 技术作为核心基建技术。
4、2021 年,Facebook、Google、Netflix、Microsoft 和 Isovalent 共同宣布成立 eBPF 基金会,旨在管理和推动 eBPF 技术的发展。这个基金会的成立凸显了这些科技巨头对 eBPF 的重视,并将进一步促进 eBPF 在各个领域的应用和创新。
如今,eBPF 已经成为数千家公司使用的技术,并且每年都涌现出数百个新的 eBPF 项目,用于探索各种不同的用例。
eBPF 的普及程度和广泛应用的规模在不断扩大。越来越多的企业和组织意识到 eBPF 的潜力,并将其纳入他们的技术栈和生产环境中。这些公司来自各个行业,包括云计算、网络安全、性能监控、数据分析和分布式系统等领域。
回顾历史,由于明显的原因,更改内核源代码或操作系统层中的任何内容都极为困难。
Linux 内核庞大而复杂,拥有约 3000 万行代码。将任何更改从想法变为广泛可用的状态需要数年的时间。首先,Linux 社区必须达成共识,并接受这些更改。然后,这些更改必须成为官方 Linux 版本的一部分。接着,几个月后,这些更改才会被 Red Hat、Ubuntu 等发行版采纳,从而吸引更广泛的用户群体。
从技术上讲,人们可以将内核模块加载到自己的内核中并直接进行修改,但这是非常高风险的,并且涉及复杂的内核级编程,因此几乎普遍被避免采用。
然而,eBPF 的出现解决了这个问题,并提供了一种安全有效的机制来在内核中附加和运行程序。
eBPF 可观测性是如何工作的呢?
为了充分理解 eBPF 可观察性背后的底层机制,通常,我们需要深入了解 Hook(钩子)的概念。 Hook( 钩子)是一种特殊的机制,用于在特定事件发生时触发 eBPF 程序。通过Hook( 钩子),我们可以捕获和处理相关事件的数据,以实现可观测性的目的。
首先, Hook ( 钩子) 可以存在于内核空间或用户空间。这意味着 eBPF 可以用于监视用户空间应用程序以及内核级事件。无论是在内核空间还是用户空间,eBPF 可以通过钩子与目标程序或事件进行交互。
其次, Hook( 钩子) 可以是预先确定的或静态的,也可以动态插入到正在运行的系统中,而无需重新启动系统。预先确定的 Hook( 钩子) 是在编译或配置阶段就确定的,它们在程序或系统启动时就已经存在。动态插入的 Hook( 钩子) 是在系统运行时动态添加的,可以根据需要灵活地插入或移除 Hook( 钩子) ,而无需重新启动整个系统。
针对上述机制,eBPF 提供了四种不同的操作机制,以满足各种需求和场景。这些操作方式包括:
1、 内核跟踪点(Kernel Tracepoints): 内核跟踪点是由内核开发人员预定义的事件,可以使用 TRACE_EVENT 宏在内核代码中设置。 这些跟踪点允许 eBPF 程序挂接到特定的内核事件,并捕获相关数据进行分析和监控。
2、USDT(User Statically Defined Tracing):USDT 是一种机制,允许开发人员在应用程序代码中设置预定义的跟踪点。通过在代码中插入特定的标记,eBPF 程序可以挂接到这些跟踪点,并捕获与应用程序相关的数据,以实现更细粒度的观测和分析。
3、Kprobes(Kernel Probes):Kprobes 是一种内核探针机制,允许 eBPF 程序在运行时动态挂接到内核代码的任何部分。通过在目标内核函数的入口或出口处插入探针,eBPF 程序可以捕获函数调用和返回的参数、返回值等信息,从而实现对内核行为的监控和分析。
4、Uprobes(User Probes):Uprobes 是一种用户探针机制,允许 eBPF 程序在运行时动态挂接到用户空间应用程序的任何部分。通过在目标用户空间函数的入口或出口处插入探针,eBPF 程序可以捕获函数调用和返回的参数、返回值等信息,以实现对应用程序的可观察性和调试能力。
上述这些机制提供了丰富而灵活的方式,让 eBPF 能够与内核和应用程序交互,捕获关键事件和数据,并实现深入的可观察性和调试功能。通过结合这些机制,开发人员可以更好地理解系统的行为、排查问题,并进行性能优化和故障排除。
在内核空间 (Kernel space ) 和用户空间 (User space ) 中,存在一些预定义的 H o ok ( 钩子) ,可以方便地将 eBPF 程序附加到这些 H o ok 上。这些 H o ok 包括系统调用、函数进入/退出、网络事件以及内核跟踪点等。通过将 eBPF 程序挂接到这些 H o ok 上,我们可以轻松地监控和分析系统的行为。
然而,更有趣的是 Kprobes 和 Uprobes 机制。当在生产环境中遇到问题且缺乏足够的信息时,我们可以使用 Kprobes 和 Uprobes 来动态添加检测,从而提供强大的可观测性。具体可参考如下示意图所示:

> 1. Kprobes 机制
通常来讲,对于开发人员,我们在内核或者模块的调试过程中,往往需要知道一些函数的执行流程,何时被调用,执行过程中的入参及返回值等,较为简单的做法便是在内核代码对应的位置添加日志打印,但是这种方式往往需要重新编译内核或者模块,操作较为复杂甚至可能会破坏原有的代码执行过程。
针对这种情况,内核提供了一种调试机制 Kprobe,提供了一种方法,能够在不修改现有代码的基础上,灵活的跟踪内核函数的执行。其实现
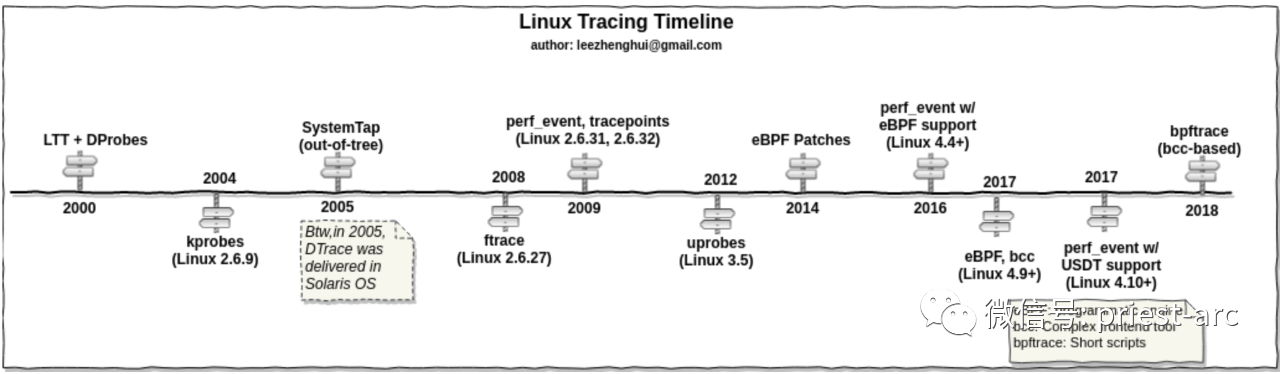
作为一种动态调试机制,Kprobe 主要用于 Debugging、动态跟踪、性能分析、动态修改内核行为等,由IBM于2004年发布,Dprobes 工具集的底层实现机制,于2005年合入 Linux Kernel。Kprobe 主要提供了三种形式的探测点:
1、基础 Kprobe:作为最为基本的探测方式, 是实现后两种的基础,它可以在任意的位置放置探测点(就连函数内部的某条指令处也可以),它提供了探测点的调用前、调用后和内存访问出错3种回调方式,具体如下所示:
(1)pre_handler 函数将在被探测指令被执行前回调;
(2)post_handler 会在被探测指令执行完毕后回调(注意不是被探测函数);
(3)fault_handler 会在内存访问出错时被调用;
2、Jprobe:用于探测某一个函数的入口,并且能够访问对应的函数参数,这个目前已经不再使用。
3、Kretprobe:用于完成指定函数返回值的探测功能,内核函数的退出点。
其中最基本的便是 Kprobe 机制,Jprobe 以及 Kretprobe的实现都依赖于 Kprobe,作为 Linux 内核的一个重要的特性,Kprobe 是其他内核调试工具(perf,systemtap)的基础设施,同时内核 BPF 也是依赖于 Kprobe,它是利用指令插桩原理,截获指令流,并在指令执行前后插入Hook函数。
那么, Kprobe 机制是如何运行的呢?具体来说,主要涉及如下阶段:
1、当注册一个 Kprobe 时,Kprobes 会复制被探测的指令,并将第一个字节(或几个字节)替换为断点指令(例如,在 i386 和 x86_64 上是 int3)。
2、当 CPU 执行到断点指令时,会触发一个陷阱(trap),CPU 的寄存器状态会被保存,并通过 notifier_call_chain 机制将控制权传递给 Kprobes。Kprobes 会执行与 Kprobe 相关联的 "pre_handler",并将 Kprobe 结构和保存的寄存器地址传递给处理程序。
3、接下来,Kprobes 会对其复制的被探测指令进行单步执行。 为了简化操作, Kprobes 并非直接在原地单步执行实际指令,而是对复制的指令进行操作。 这样做是为了避免在单步执行期间需要暂时移除断点指令,从而减少了另一个 CPU 可能在此期间直接通过探测点的时间窗口。
4、在指令单步执行之后,如果存在与 Kprobe 相关联的 "post_handler",Kprobes 会执行该处理程序。然后执行会继续进行,跳到探测点之后的指令。
Kprobes 机制允许在运行时动态挂接到内核代码的任何部分。这意味着我们可以选择在关键的内核函数入口或出口处插入探针,以捕获有关函数调用和返回的信息。通过使用 Kprobes,我们可以在问题发生时实时监测和记录内核行为,从而获取更多的上下文信息,帮助我们进行故障排除和问题分析。
> 2. Uprobes 机制
Uprobes,也称为用户探针,是 Linux 内核提供的一项功能,用于在用户空间应用程序中进行动态检测,而无需修改应用程序的代码。Uprobes 允许在运行中的进程中的特定位置(如函数入口或返回点)附加探测点,并在命中这些探测点时执行自定义处理程序。
Uprobes 机制主要涉及如下活动阶段,具体:
1、注册,首先,需要在用户空间应用程序中的目标探测点上注册一个 U probe 。可以通过提供符号名称或进程内存空间中的地址来指定探测点。
2、Trap 插入及处理:当注册一个 Uprobe 时,Linux 内核会将被探测指令的前几个字节替换为 Trap 指令。当执行被探测指令时,触发 Trap,导致内核接管控制权。当触发 Trap 并且控制权转移到内核时,内核会执行 U probe 处理程序。CPU 的寄存器状态和其他相关信息会被保存,然后传递给处理程序。
3、Uprobe 处理程序执行:执行与注册的探测点相关联的 U probe 处理程序。处理程序可以是用户定义的函数或系统提供的处理程序。它在被探测进程的上下文中执行,可以访问该进程的内存和状态。
4、 恢复执行: Uprobe 处理程序执行完成后,内核会恢复保存的寄存器状态,并允许进程继续正常执行。 执行会从被探测指令之后的位置继续,就好像探测点从未插入过一样。
Uprobes 提供了强大的调试、分析和跟踪用户空间应用程序的能力。它们允许开发人员在不修改原始应用程序的情况下动态地对代码进行检测,从而实现各种运行时分析和监控技术。
Uprobes 机制与 Kprobes 类似,但是针对的是用户空间应用程序。它允许在运行时动态挂接到用户空间应用程序的任何部分。通过在关键的用户空间函数入口或出口处插入探针,我们可以捕获应用程序的执行信息,例如函数调用参数、返回值等。这使得我们能够深入观察应用程序的行为,并在运行时动态添加检测,以解决生产环境中的问题。
通过使用 Kprobes 和 Uprobes,我们可以在不中断系统运行的情况下,实时地添加观测和调试功能,以满足实际需求。这为我们提供了强大的工具,使得在生产环境中进行故障排除和性能优化变得更加灵活和便捷。
什么场景下应该选用 eBPF 可观测性?
基于 eBPF 的定位及技术特性,其主要应用在如下场景,具体:
1、如果我们的服务实例正在运行现代的云原生环境,如 Kubernetes 和微服务架构,我们会发现基于 eBPF 的方法和基于代理的方法之间存在明显差异。基于 eBPF 的方法通常具有更低的性能开销,更高的安全性,并且更容易安装和部署。通过与内核紧密集成,eBPF 能够在运行时提供更高效的观测和监控功能,而无需引入额外的代理或中间件。这使得基于 eBPF 的方法成为现代云原生环境中的首选解决方案。
2、其次,对于大规模运营的组织来说,基于 eBPF 的轻量级代理能够带来显著的改进。这是因为 eBPF 提供了高度灵活且可编程的观测能力,允许通过内核级别的监控来获取深入的洞察力。对于像 LinkedIn、Netflix 和 Meta 这样具有大量足迹的科技公司来说,他们采用 eBPF 的原因之一就是它能够满足他们规模和复杂性的需求,提供更高效、更精确的监控和故障排除。
3、如果我们的团队技术储备有限,并且正在寻找一种几乎不需要安装和维护的观测解决方案,那么直接选择基于 eBPF 的解决方案是一个不错的选择。eBPF 提供了一种以编程方式配置和管理观测功能的方法,而无需额外的基础设施或复杂的设置。这使得我们可以快速启用和配置 eBPF 程序,获取所需的监控数据,而无需处理繁琐的安装和维护任务。
总而言之,基于eBPF的方法在现代云原生环境中展现出许多优势,包括较低的性能开销、更高的安全性和更容易的部署。对于大规模运营的组织来说,基于 eBPF 的轻量级代理能够带来显著的改进。而对于技术储备有限的团队,直接选择基于 eBPF 的解决方案可以提供简单且高效的观测能力,减少安装和维护的负担。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞5作者其他文章
评论 3 · 赞 0
评论 4 · 赞 2
评论 4 · 赞 1
评论 6 · 赞 1
评论 4 · 赞 3
添加新评论0 条评论