企业容灾选型指南-3:数据容错恢复技术
【摘要】 : 随着全球IT产业的飞速发展,企业的IT建设逐步成为主导业务发展的核心驱动力,基于企业IT架构容灾建设的各种行业标准以及监管标准也相应提高。提高企业整体容灾体系标准是摆在企业面前的挑战,但是面对技术的日新月异和信息技术的多元化发展,很多企业在容灾架构的选型过程当中也存在着诸多困惑。因此旧事重提,我们通过一系列的文章来重新阐述这个IT界经久不衰的话题。
# 1. 企业容灾可能面临的数据灾难场景?
之前在《企业容灾选型指南-2:企业容灾的数据复制技术》文章当中,我们介绍了企业容灾建设过程当中经常会用到的远程数据复制技术,主要集中笔墨在其正常场合下的数据复制原理和机制上。那么有正常场合就有异常场合,一个成熟的数据复制技术必须能处理异常场合下的数据损坏和丢失故障。本文我们探讨的异常场景,主要是因数据中心之间的通讯故障、主数据中心数据存储设备故障等引起的其中一个数据镜像不可用(数据损坏、复制中断、镜像失效等)的场景。归纳为以下两个问题:
① 异常发生期间,数据变化如何保存记录?
② 异常恢复之后,镜像数据如何恢复到正常复制状态?
围绕以上两个问题,我们接下来探讨从系统层面、数据库层面以及存储层面用什么样的机制或者策略来保障以上问题的完美解决 。
2. 操作系统层面如何完成数据镜像恢复?
2.1 基于逻辑卷管理器模式的数据复制技术

如图所示,发生了一个镜像不可用的场景。
首先,第一个问题“异常发生期间,数据变化如何保存记录?”。
逻辑卷管理器是可以通过参数控制逻辑卷的读写行为是否一定要双写(例如 AIX参数:Keep Quorum Checking On=yes/no )。如果我们设置双写控制参数为是,那么这个时候整个逻辑卷的写请求就会被挂起,逻辑卷被认为不可用,业务中断。如果我们设置宽松的双写控制参数,那么这个时候整个逻辑卷的写请求会等待 PV2的ACK回复,如果超过系统默认Timeout时间,那么认为PV2失效,将其标注为Disable,之后的写行为就不会顾及PV2的镜像复制了,业务无中断,但是之后的数据更新不会有任何辅助手段去记录。
其次,第二个问题“异常恢复之后,镜像数据如何恢复到正常复制状态?”
当PV2所面临的异常环境恢复之后,虽然PV2的硬件环境和设备都已经恢复正常,但是逻辑卷的镜像PV2已经被标注为失效状态,因此不会有任何自愈行为。这个时候需要我们手动去做以下几步操作来恢复数据镜像同步状态:
① 命令方式手动拆除逻辑卷对应PV2的镜像。
② 命令方式手动创建PV2物理卷设备,并加入卷组创建成为逻辑卷的新镜像。
③ 命令方式执行镜像之间的数据同步。
这一系列过程,第三步的原理是PV2会作为一个新的设备存储空间,逐个读取原来PV1对应镜像里面的数据,然后以PP为单元进行复制同步,本身会很耗费时间和系统的读写性能。
2.2 基于ASM模式的数据复制技术
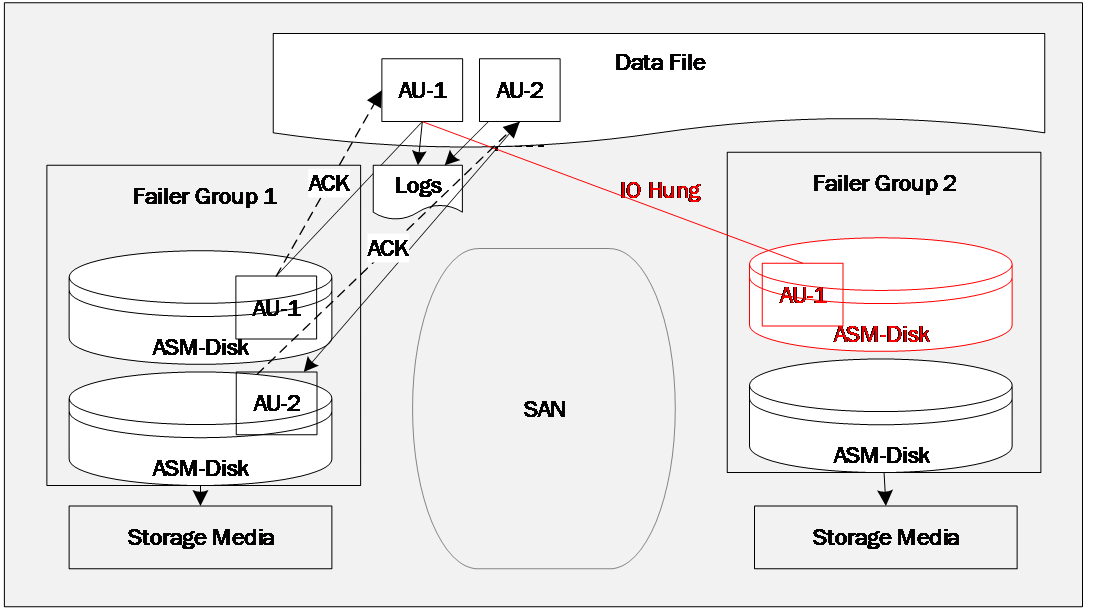
如图所示, Failure Group 2对应的数据副本部分或者全部不可用的场景 。
首先,第一个问题“异常发生期间,数据变化如何保存记录?”。
Oracle ASM本身对于磁盘或者整个Failure Group是否可用的判断,也是有参数可以控制的 (例如 Disk_Repair_Time,Failuregroup_repair_time )。 如果超过参数设置的Timeout时间,那么认为磁盘或Failure Group失效,将其标注为Unavailable,之后的写行为就不会再往Failure Group 2写入了。但是这个时候它会有一个机制来保存后续短时间内的数据增量变化。
其次,第二个问题“异常恢复之后,镜像数据如何恢复到正常复制状态?”
当Failure Group 2所面临的异常环境恢复之后,ASM会通过设置的参数来判断是否可以自愈,如果不能在参数所限条件下进行自愈,一样需要手动通过命令进行再同步的操作。
1). 小于等于参数 disk_repair_time(默认3.6H)时,认为是暂时性failure,会一直跟踪涉及failure磁盘extents修改,等该磁盘恢复后,重新同步将修改过的extents同步到failure磁盘。此过程无感知。
2). 大于 disk_repair_time。ASM会自动离线failure磁盘。需要人为使用命令剔除无效设备,并添加有效设备进入Failure Group2,然后ASM会自动通过扫描复制方式完成镜像的同步。
2.3 基于并行文件系统模式的数据复制技术

如图所示,灾难发生后,经过仲裁之后,右侧数据中心的节点 Node-2和Failure Group2当中的所有磁盘对于集群都处于不可用状态。
首先,第一个问题“异常发生期间,数据变化如何保存记录?”。
GPFS 本身不会通过自身的参数控制来判断磁盘是否不可用,它完全是依赖操作系统对IO状态判断的反馈来执行它的操作。如果GPFS的主节点Node-1通过ping判断负责failure Group2的节点Node-2是可用的,但是Node-2写入磁盘的IO被操作系统判断为failed或者hung。GPFS会通过Recovery Log来记录元数据和镜像数据的增量变化;如果GPFS的主节点Node-1发现负责Failure Group2的节点Node-2失败了,那么集群会通过选举算法剔除Node-2,并选择与Node-2同数据中心的其他节点来负责Failure Group2的读写;如果节点和磁盘同时发生了故障(数据中心级别故障),那么GPFS集群会剔除失败节点,并且启用Recovery Log来记录元数据及镜像数据的增量变化。
其次,第二个问题“异常恢复之后,镜像数据如何恢复到正常复制状态?”
当环境所面临的异常恢复之后,需要通过命令将节点和NSD磁盘组加入到集群资源当中,然后GPFS集群会通过自身算法重新分配节点和磁盘组资源的映射关系,然后进行镜像数据的同步。同步的时候由于文件系统本身的结构特点所致,它是需要有文件系统的Meta数据和文件系统用户数据两部分,GPFS会通过元数据服务器上的Jornal Log和Recovery Log来同步数据镜像。
3. 数据库层如何完成数据副本恢复?
首先,我们需要明确对于数据库层要讨论的数据再同步问题,一定是同步模式设置为近似同步或者是异步的这种模式,如果是绝对同步的模式那么一旦数据复制中断,读写也就挂起了。
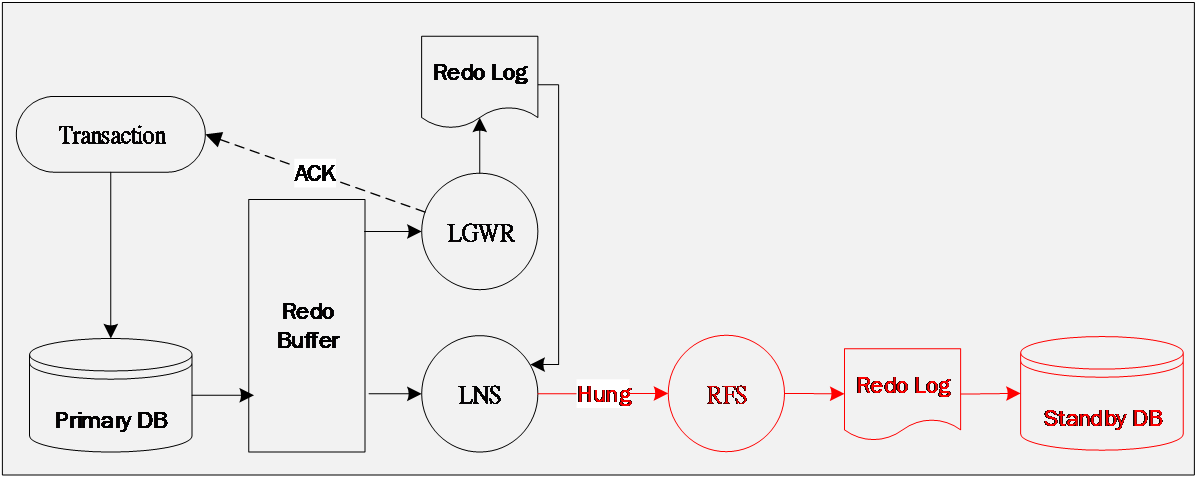
如图所示, 如果是灾备中心数据库完全损毁的场景,只有重新配置Standby DB,并且重新用备份数据为基点进行增量数据的追平。我们讨论的是由于 网络问题或者其他问题导致的 Primary DB 无法访问到Standby DB的场景。
首先,第一个问题“异常发生期间,数据变化如何保存记录?”。
数据库层面的数据复制本身就是日志的应用过程, 当Primary Database的某些日志没有成功发送到Standby Database,这时就发生了归档裂隙(Archive Gap),缺失的这些日志就是裂隙(Gap)。 那么自然发生异常后的时间段内,数据增量变化都会在归档的 Redo日志当中记录。
其次,第二个问题“异常恢复之后,镜像数据如何恢复到正常复制状态?”
当环境所面临的异常恢复之后,需要通过命令将节点和NSD磁盘组加入到集群资源当中
Data guard 具备 自动检测、解决归档裂隙 的能力 。一旦Standby Database被认定是failed,那么Primary Database就会强制进行一次日志切换,以明确的标识出Failed的时间点,也就是达到零数据丢失的时间点,而在这以后产生的redo日志就不再向Standby发送了。 数据库 的连通性 异常 一旦恢复,则所有的实例会自动去解决日志裂隙问题,接着 Primary Database 所有的实例会进行日志切换,以启动LNS进程,继续发送Redo。这种模式只是尽量避免数据丢失,并不能绝对保证数据完全一致。这种模式要求Standby Database必须配置Standby Redo Log,而Primary DATABASE必须使用LGWR、SYNC、AFFIRM方式归档。
除了自动的日志缺失解决,DBA也可以手工解决,这需要作如下操作:
① 确认Standby Database上缺少的日志 ;
② 把这些日志从Primary Database拷贝到Standby Database ;
③ 在Standby Database使用命令手工注册这些日志 。
④ 执行日志应用恢复。
4. 存储层如何完成数据副本恢复?
4.1 基于存储网关镜像的数据复制技术?
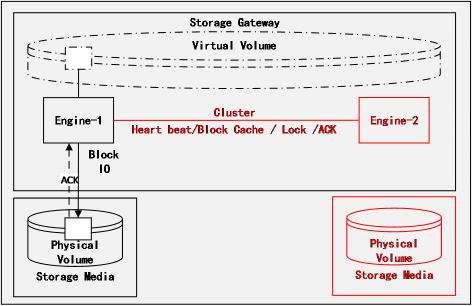
如图所示,以 VPLEX为例 ,灾难发生后,经过仲裁之后,右侧数据中心的引擎和存储卷 处于不可用状态。自然虚拟分布式卷Virtual Volume的另外一个镜像就被置为failed状态。
其实它的恢复原理与操作系统镜像恢复的原理是一致的,无非就两种方法,一个是通过日志记录增量变化,待镜像状态恢复之后重新同步增量的变化;另外一个就是从可用镜像扫描全盘进行拷贝同步。
首先,第一个问题“异常发生期间,数据变化如何保存记录?”。
这个问题其实各家不尽相同,有的存储厂商可以通过一定量的Jornal Log来捕获存储卷上的Block变化,也有的存储厂商相对比较传统,没有这样的记录机制,要区别产品而言。
其次,第二个问题“异常恢复之后,镜像数据如何恢复到正常复制状态?”
就增量事务,一旦异常恢复可以首先通过Jornal Log来进行恢复,原理类似于Oracle ASM的Resync机制。但是也有一些存储厂商采取的是快照机制来进行镜像拷贝复制,虽然对原数据副本的读写性能不会造成太大影响,但也毕竟是全盘的扫描。就用过的VPLEX产品的实践经验来看,从VPLEX Virtual Volume多种场景的同步时间周期来判断,它是具备Jornal Log的机能的。
4.2 基于存储介质块拷贝的数据复制技术?

如图 所示 , 基于存储设备本身实现的数据复制技术与上层对象相关性非常少,仅依靠物理存储设备层实现数据的复制,由于源端和目标端都是同品牌甚至同规格存储设备,那么底层存储 Block的复制以及异常场景后的镜像恢复也会有很多种手段,毕竟自家的设备自家的软件,实现的手段就更多 。
首先,第一个问题“异常发生期间,数据变化如何保存记录?”。
各家不尽相同,但是也很少看见存储厂商真正原理性的东西出来,仅仅宣传可以有增量记录、快照记录等功能可以记录数据的变化。究竟是结果捕获模式还是事务行为记录模式还是要根据具体产品来说。
其次,第二个问题“异常恢复之后,镜像数据如何恢复到正常复制状态?”
如果有两个以上副本的情况,可以通过其他副本延续数据的复制,当然中断点是必须有日志文件可以参考才可以。如果没有其他副本可以通过检查点之后的日志或者增量快照文件进行增量同步。例如SRDF就是通过增量快照实现的。
这里大家可能非常容易看到一个问题,那就是为什么存储层的数据复制技术很多都是采用快照技术来实现增量或者全量数据的同步恢复呢,而系统层镜像复制技术却很少呢?我个人觉得有两点:
① 存储层与上层应用及数据联系甚少,实现增量记录功能就算复杂一些也不会影响业务。
② 快照技术本身就是存储软件层比较得意的衍生功能模块,正所谓做自己擅长的事情。
作者企业容灾选型指南系列文章汇总:
企业容灾选型指南-1:必须知道的概念
企业容灾选型指南-2:跨中心数据复制技术
企业容灾选型指南-3:数据容错恢复技术
企业容灾选型指南-4:关键故障切换
企业容灾选型指南-5:脑裂问题探讨
企业容灾选型指南-6:容灾架构评估
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞5本文隶属于专栏

作者其他文章
评论 5 · 赞 4
评论 10 · 赞 17
评论 2 · 赞 14
评论 7 · 赞 1
评论 0 · 赞 10
添加新评论0 条评论