滴滴 Redis 异地多活的演进历程
为了更好的做好容灾保障,使业务能够应对机房级别的故障,滴滴的存储服务都在多机房进行部署。本文简要分析了 Redis 实现异地多活的几种思路,以及滴滴 Redis 异地多活架构演进过程中遇到的主要问题和解决方法,抛砖引玉,给小伙伴们一些参考。
Redis 异地多活的主要思路
业界实现 Redis 异地多活通常三种思路:主从架构、Proxy双写架构、数据层双向同步架构。
主从架构

主从架构的思路:
- 各机房的 Redis 通过 Proxy 对外提供读写服务,业务流量读写本机房的 Redis-proxy
- 主机房里的 Redis-master 实例承担所有机房的写流量
从机房里的 Redis-slave 实例只读,承担本机房里的读流量
主从架构的优点 :
实现简单,在 Proxy 层开发读写分流功能就可以实现
Redis 层使用原生主从复制,可以保证数据一致性
主从架构的缺点 :
- 从机房里的 Redis-proxy 需要跨机房写,受网络延时影响,业务在从机房里的写耗时高于主机房
- 主机房故障时,从机房的写流量也会失败,需 要把从机房切换为主机房,切换 Redis-master
网络故障时,从机房的写流量会全部失败,为了保障数据一致性,这种场景比较难处理
Proxy 双写架构

Proxy 双写架构的思路:
- 各机房的 Redis 通过 Proxy 对外提供读写服务,业务流量读写本机房的 Redis-proxy
- 不区分主从机房,每个机房都是独立的 Redis 集群
- 各机房的读写流量都是访问本机房的 Redis 集群
Proxy 层在写本机房成功后,将写请求异步发送到对端机房
Proxy 双写架构的优点:
- 实现简单,在 Proxy 层开发双写功能就可以实现
- 一个机房故障时,其他机房的流量不受影响
网络故障时,各机房内部的流量也不受影响
Proxy 双写架构的缺点:
- 不能保证数据一致性,Proxy 异步 write 请求可能会失败,失败丢弃请求后,导致双机房数据不一致
- 假设机房-A的集群先上线,机房-B 后上线,Proxy 双写架构不能支持把机房-A的存量数据同步到机房-B
网络故障时,异步 write 会失败后丢弃,网络恢复后,之前失败的数据已经丢弃,导致双机房数据不一致
数据层双向同步架构

数据层双向同步架构的思路:
- Proxy 不关心底层 Redis 数据同步
- 业务流量只访问本机房里的 Redis 集群
在 RedisServer 层面实现数据同步
数据层双向同步架构的优点:
- 机房-A故障时,机房-B不受影响,反向如是
- 网络故障时,本机房流量不受影响,网络恢复后,数据层面可以拉取增量数据继续同步,数据不丢
- 支持存量数据的同步
- 业务访问 Redis 延时低,访问链路不受机房间网络延时影响
业务单元化部署时,双机房 Redis 会有较高的数据一致性
数据层双向同步架构的缺点:
实现相对比较复杂,RedisServer 改动比较大
滴滴 Redis 架构
Codis 架构(早期架构,现已废弃)

Kedis 架构(线上架构)

滴滴 Redis 异地多活架构的演进
**第一代多活架构
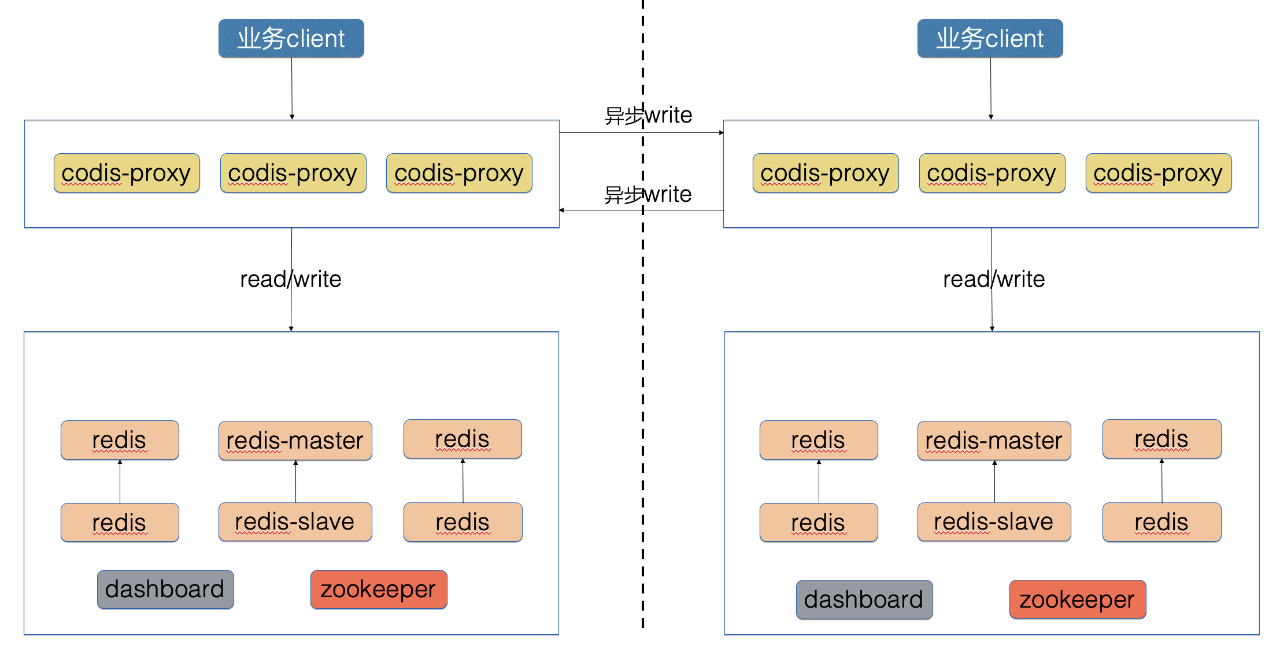
第一代 Redis 多活基于 Codis 架构在 proxy 层实现了双写,即本机房的 Proxy 将写流量转发到对端机房的 Proxy, 这个方案的特点 是快速实现,尽快满足了业务多机房同步的需求。 如前面 Proxy 双向架构思路所讲,本方案还存在着诸多缺点, 最主要的是网络故障时,同步数据丢失的问题, 为了解决这些问题,我们开发了第二代多活架构。
第二代多活架构
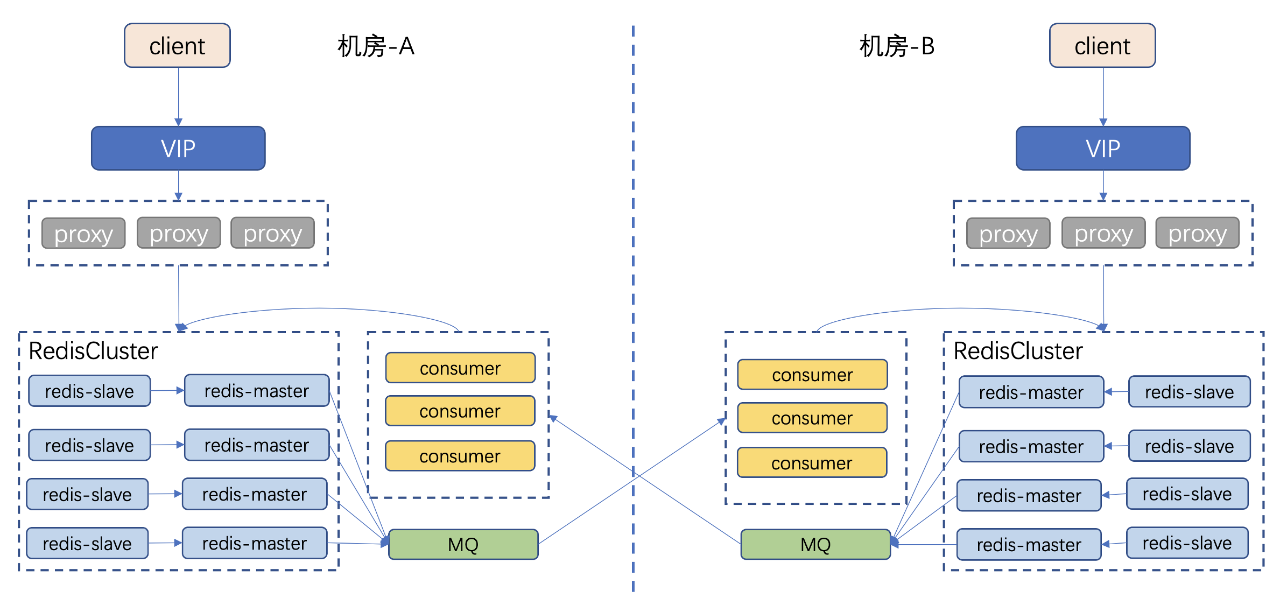
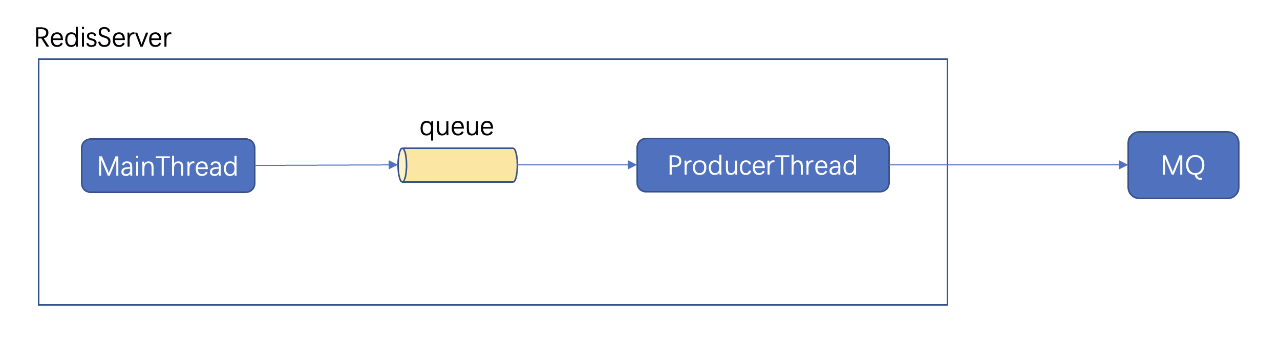
第二代多活基于 Kedis 架构,对 Redis-server 进行改造,可以把增量数据从 Redis 直接写入本机房的 MQ 中,由对端机房的 consumer 来消费 MQ,consumer 将数据写入对端 Redis 中。 网络故障时,数据会在 MQ 堆积,待网络恢复后,consumer 可以基于故障前的 offset 继续进行消费,写入对端 R edis ,从而保证在网络故障时 Redis 多 活不会丢数据。
但这一代架构仍不够完美,存在以下问题:
- ProducerThread 把数据写入 MQ 时,如果触发 MQ 限流,数据会被丢掉
- RedisServer 内部包含了 ProducerThread,当中间内部 queue 累积数据量超过10000条时,数据会被 MainThread 丢掉
- 中间同步数据写入 MQ,增加了跨部门依赖,同步链路长,不利于系统稳定性
- 中间同步链路重试会造成非幂等命令执行多次,例如 incrby 重试可能造成命令执行多次造成数据不一致
- 对于新建双活链路,不支持同步存量数据,只能从当前增量数据开始同步
Redis 增量数据写入 MQ,导致成本增加
为了解决以上问题,我们开发了第三代架构。第三代多活架构
在第三代架构中,我们细化了设计目标,主要思路是保证同步链路中的数据不丢不重,同时去掉对 MQ 的依赖,降低多活成本。
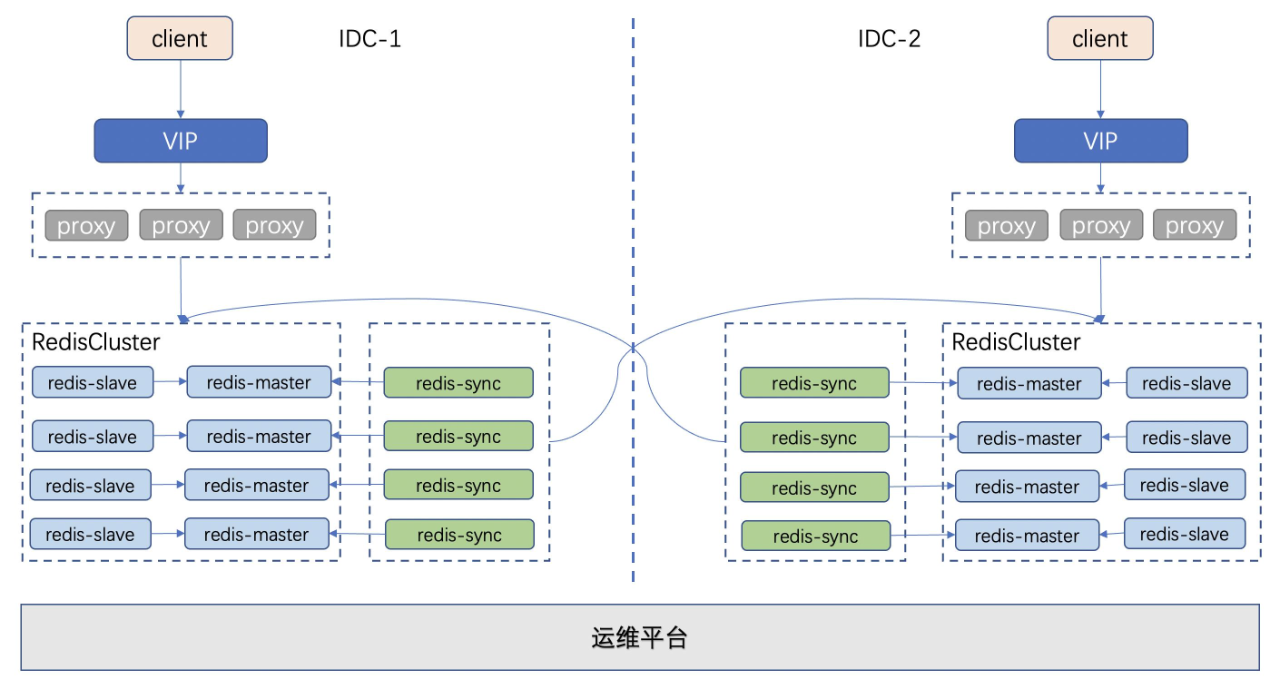
第三代架构中,我们去掉了 MQ 和 consumer,新增了 syncer 组件。 syncer 组件模拟 Redis-slave 从 Redis-master 中拉取增量数据,这样把数据同步和 Redis 进行解耦,便于后续多机房扩展。
在 第三代架构中, Redis 遇到了回环、重试、数据冲突、 增量数据存储和读取等问题,接下来一一介绍我们应对这些问题的解决方案。
1、回环问题
机房-A 写入的数据同步到机房-B,防止数据再传回机房-A。
为了解决回环问题,我们开发了防回环机制:
- Redis 增加 shardID 配置,标识唯一分片号
- Redis 请求中增加 opinfo,记录元信息,包含 shardID
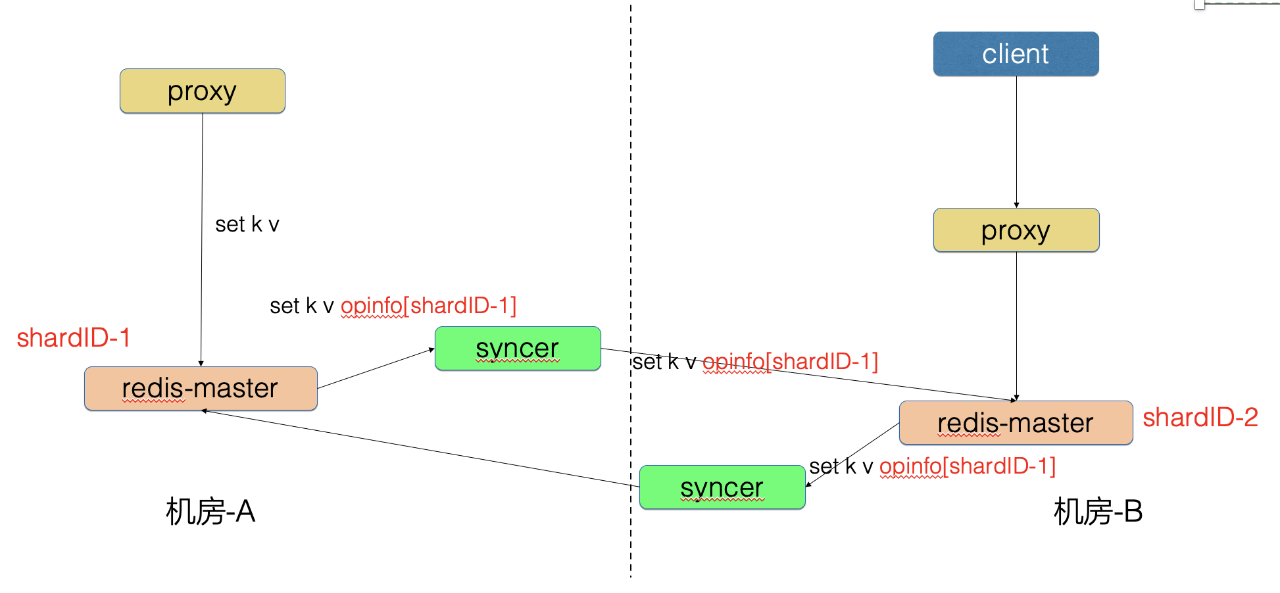
- 机房-A 的 Proxy 写入了 set k v 请求
- 机房-A 的 Redis-master 向 syncer 同步 set k v opinfo[shardID-1] 请求
- syncer 向机房-B 写入 set k v opinfo[shardID-1] 请求
这样机房-B 根据 shardID-1 识别出这条请求是机房-A 生产的数据,因此不会再向机房-A 同步本条请求
2、重试问题
机房-A 写入的 incrby 请求同步到机房-B,由于中间链路的重试,导致机房-B 可能执行了多次。
为了解决重试问题,我们开发 了防重放机 制:
- Redis 增加 opid,标识唯一请求号
- Redis 请求中增加 opinfo, 记录元信息[opid]
- 机房-A 的 Proxy 写入了 incrby k 1 请求
- 机房-A 的 Redis-master 向 syncer 同步了 incrby k 1 opinfo[opid=100] 请求, 之前同步的 opid=99 的请求已经成功
- syncer 向机房-B 写入 incrby k 1 opinfo[opid=100] 请求
- 机房-B 的 Redis 里存储了防重放信息 shardID-1->opid[99]
- 机房-B 的 Redis 发现新请求的 opid=100>本地的99,判断为新请求
- 机房-B的 Redis 执行这条请求,并把防重放信息更新为shardID-1->opid[100]
- 假设机房-A 的 syncer 将本条请求进行了重试,又执行了一遍 incrby k 1 opinfo[opid=100]
- 机房-B 的 Redis 发现新请求 opid=100 等于本地的100,判断为重复请求
- 机房-B 的 Redis 忽略掉本地请求,不执行
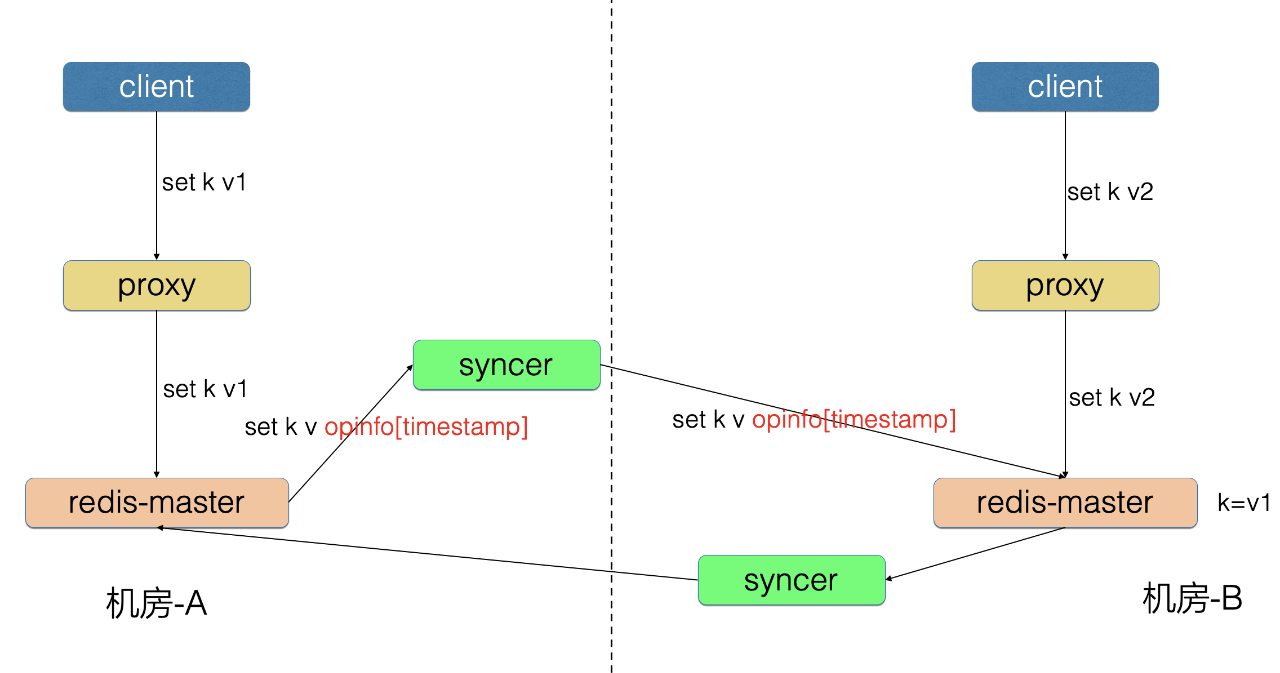
3、数据冲突问题
双机房同时修改同一个 key 导致数据不一致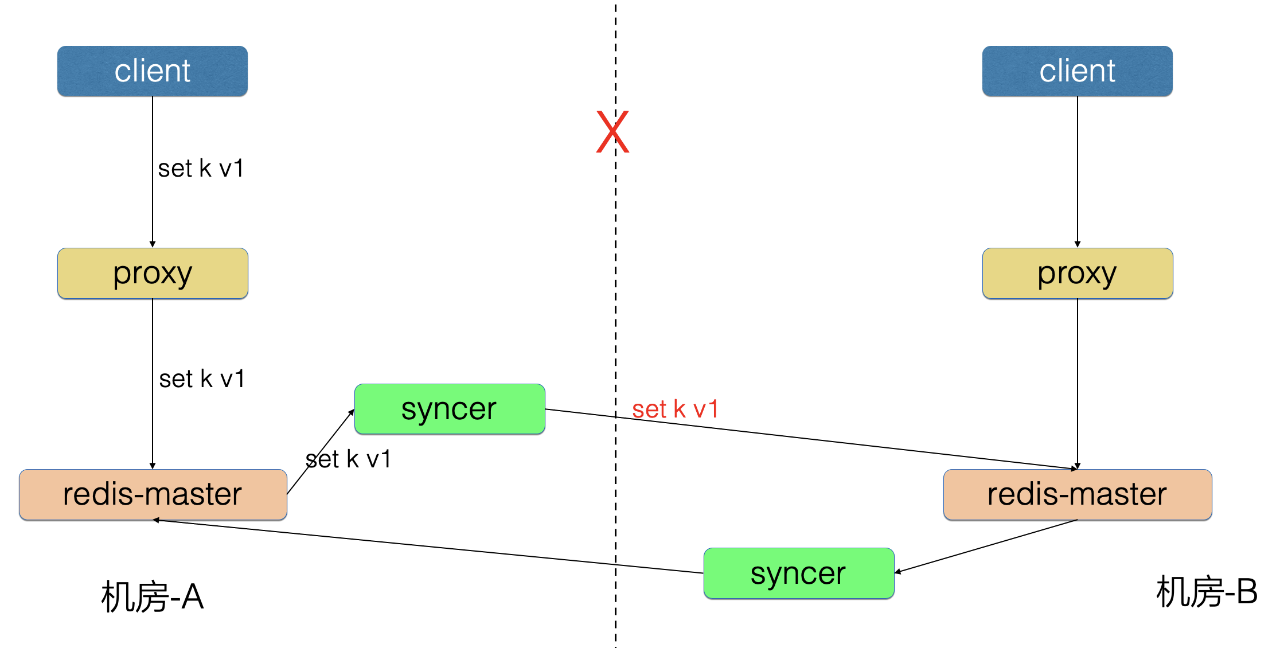
对于数据冲突,不同数据类型的不同操作的数据合并,如果单从存储层解决,是一个非常复杂的话题。 如果业务层做了单元化部署,则不会出现这种问题。 如果业务层没有做单元化,我们开发了冲突检测功能,来帮助业务及时发现数据冲突,最后数据以哪边为准来修正,需要业务同学来决策。
冲突检测机制:
- Redis 记录 key 的最后 write 时间
- Redis 请求中增加 opinfo,记录元信息 [timestamp]
- 如果 opinfo.timestamp<=key_write_time,则记录冲突 key

时间T1 <T2 <T3
- T1时间,用户在机房-A 写入请求 set k v1
- T2时间,用户在机房-B 写入请求 set k v2,并记录k的最后修改时间为T2
- 由于网络同步延时,T3时间,syncer 把T1时间写入的 set k v1请求发送到了机房-B
- 机房-B 的 Redis 执行 set k v1 时发现 timestamp 为T1,但 k 的最后修改时间为T2
- 由于T1<T2,机房-B 的 Redis 判断这是一次冲突,并记录下来,然后执行该条请求
以上是冲突检测的基本原理,这是一个旁路统计,帮助用户发现一些潜在冲突数据。
4、增量数据存储和读取问题**
因为 syncer 只是同步组件,不会存储数据,所以需要考虑当网络故障时,增量数据的存储和读取问题。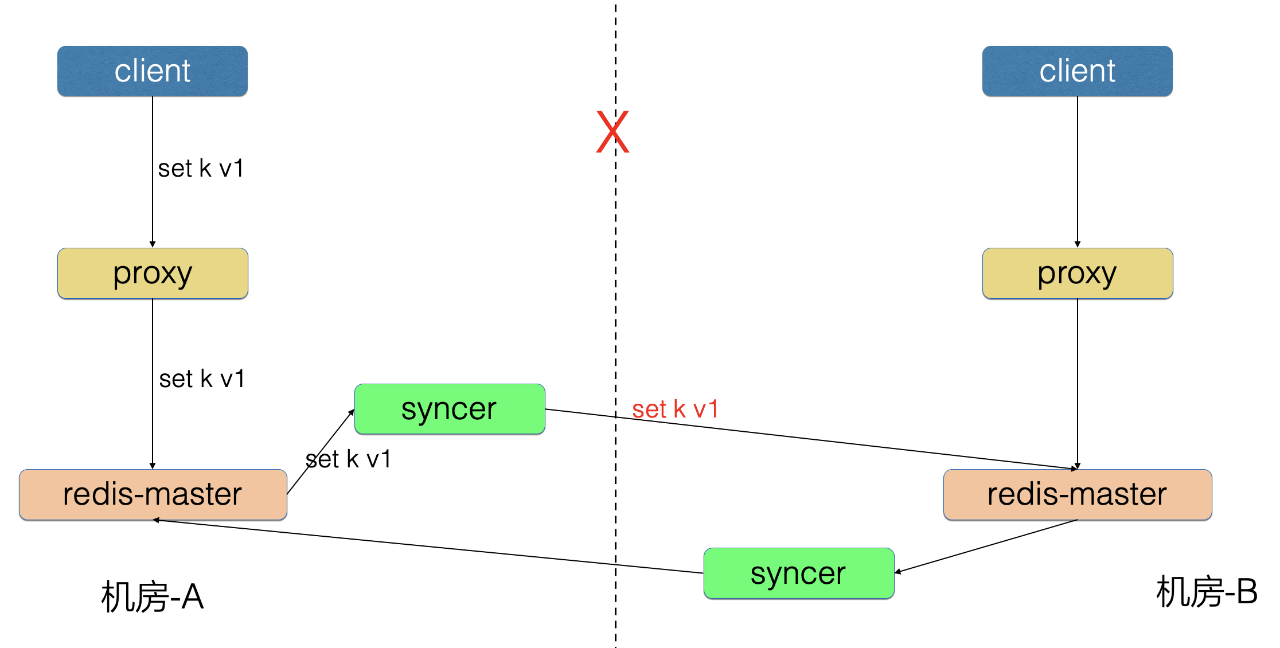
为了解决这个问题,我们对 Redis 的 aof 机制进行了改造,可以在网络故障时,增量数据都堆积在 Redis 的磁盘上,在网络恢复后,syncer 从 Redis 里拉取增量 aof 数据发送到对端机房,避免数据丢失。
aof 机制改造有: aof 文件切分、 aof 增量复制、 aof 异步写盘
- 将 aof 文件切分为多个小文件,保存增量数据
- 当增量数据超过配置的阈值时,Redis 自动删除最旧的 aof 文件
- 当 Redis 重启时,加载 rdb 文件和 rdb 之后的 aof 文件,可以恢复全部数据
当网络故障恢复后,syncer 根据故障前的 opid 向 Redis 请求拉取增量数据,发送到对端机房
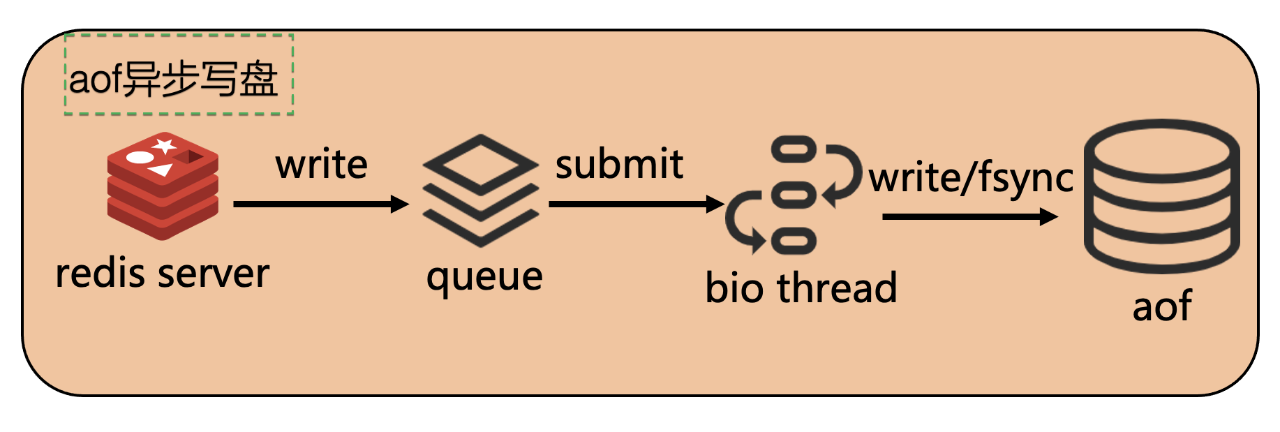
开源 Redis 是在主线程中进行 aof 写盘,当磁盘 IO 过高时,Redis 写盘可能造成业务访问 Redis 耗时抖动。 因此我们开发了 aof 异步写盘机制:
- Redis 的主线程将 aof 数据写入 queue 中
- bio 线程来消费 queue
bio 线程将 aof 数据写入磁盘
这样 Redis 的访问耗时不受磁盘 IO 的影响,更好的保证稳定性。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞8作者其他文章
评论 0 · 赞 4
评论 0 · 赞 0
评论 0 · 赞 3
评论 0 · 赞 4
评论 0 · 赞 3
添加新评论1 条评论
2023-12-15 11:01