重复数据删除技术详解(二)
在上一篇文章“重复数据删除技术详解(一)”中,介绍了重复数据删除技术的基本原理和主要分类,本篇文章就块级重复数据删除技术(后文简称“重删”)的实现原理进行讲解。
块级重删是指将数据流或者文件根据某种方式进行切片(也叫分块),以数据块为单位进行hash计算,以此找到相同的数据块进行删除。块级重删又分为定长重删和变长重删。为了方便,本文将围绕下图所示的一串数据进行讲解。

定长重删
定长重删其实很好理解,实现逻辑也比较简单。将要备份的数据以固定长度进行分块,并计算每个分块的hash值(value)。
如下图所示,每4个数据进行分块,共分成了6块,计算各个分块的hash值。首次备份时,得到value1,value2,value3,value4,value5共5个hash值,其中第1个数据分块和第6个数据分块value一致,都是value1,数据也一致,那么第6个数据分块只需记录索引,不需要再进行存储,以此达到减少存储空间的效果。

对于备份系统来讲,数据经常需要保留多个副本,因此生产数据产生变化后进行二次备份的重删效果就比较重要。先来看看数据产生变化的情况,如下图所示,当第3个数据分块中的数据产生了变化后(CABB->CEBB),整串数据中仅第3个数据分块的hash值发生了变化,不影响其他数据分块的hash值,整体重删效果较好。

但生产数据常常出现在中间位置进行新增和删除数据的情况,这种情况下,定长重删的效果就非常不理想。如下图所示,整个数据串中插入了数据“E”,这就导致整个数据串重新分块,且所有数据分块的hash值相比首次备份都无法匹配,重删率等于0。

因此,根据不同的场景,定长重删的效果差异很大。一般来讲,定长重删的方式更适用于卷备份、虚拟机备份等场景,这些场景下备份对象的数据长度基本很少发生变化。解决定长重删的问题,就是使用变长分块。目前比较常见的变长分块方案有2种:滑动窗口分块和基于内容分块(CDC:content-defined chunkingcontent-defined chunking)。
变长重删:滑动窗口分块
如下图所示,基于滑动窗口分块方案的首次备份与定长重删方案一致,它选用固定的长度对整串数据进行分块,并计算各个分块的hash值。选用的这个固定的长度就是窗口的长度。

二次备份的时候,利用窗口的滑动来尝试寻找和匹配相同的数据。如下图所示,第3个数据分块中的数据发生了变化(CABB->CEBB)。首先计算CEBB的hash值,因为数据的变化会发现无法匹配到hash值(hash value1')。这个时候不着急处理下一个数据分块,而是将窗口向前移动一个单位,继续计算这个窗口下的数据的hash值(hash value2')并尝试匹配,直到找到可以匹配的hash值为止。这个过程需要注意以下点:
- 如果在窗口内找到匹配的hash值,那么就可以认为这个窗口内的数据分块是重复且可以删除的,下一次的窗口可以直接从当前这个数据分块的末尾开始,以此提升计算效率。
- 如果窗口持续滑动(滑动长度 >= 窗口的长度)而找不到匹配的hash值,说明产生变化的数据量比较大,这种情况下同样以窗口的长度对数据进行分块。
- 如果窗口滑动后,很快找到了匹配的hash值(滑动长度 < 窗口长度),那么就将窗口滑过的部分进行单独分块。综合第2点可以得出:分块的长度<=窗口长度。

同样的,我们来看下数据变化和数据新增场景下重删的效果。如下图所示,当某个数据发生变化的时候,其效果与定长重删效果一样,可以获得一样的重删率。

当数据串中新增了数据时,根据上述滑动窗口的原理,会产生一个新的数据分块(仅包含一个"A");且仅2个数据块因为hash值不匹配而需要重新存储,大部分的数据分块得以重删。此种场景下,重删效果相比定长重删要好很多。

滑动窗口的方案不仅仅应用于重删,同样应用于rsync增量同步、文件查重等场景。此方案可以带来良好的查重效果,但是也引入了“数据碎片”的缺陷。上图中的数据分块“A”即是碎片。碎片如果过多最终会影响整体效率。
变长重删:CDC分块
在讲解CDC分块前,先简单介绍下Rabin指纹。Rabin指纹是一种高效的指纹计算函数,利用hash函数的随机性,它对任意数据的计算结果表现出均匀分布。其原理大致是这样子的:假设有一串固定长度的数据S,有一个hash计算函数h(),针对S进行hash计算并对固定值D取余,即hash(S) mod D = r。由于hash值的随机性,最终r会在一定的[0,D)的区间内均匀分布。基于文件内容的分快就是利用了这样的技术,设置一个固定长度的滑动窗口、一个固定值D和一个固定值R(R<D),当滑动窗口内的数据S满足hash(S) mod D = R时,那么就认为这是一个分块的边界。
本文中假设滑动窗口的固定长度为4,当窗口内的数据串末位为数据“A”时,满足条件 hash(“窗口内的数据串”) mod D = R。如下图所示,窗口从第初始位置滑动。
- 初始位置为“AABA”,末位为A,满足 hash("AABA") mod D = R。因此可以认为产生了一个分块边界。
- 下一次滑动从边界后开始。"CACC"不满足条件,向前滑动一个单位;“ACCC”不满足条件,继续向前滑动一个单位;“CCCA”满足条件,产生新的分块边界。那么新的分块就是“CACCCA”。
- 以此类推,直到整个数据串滑动完为止。滑动结束,数据串的分块也就结束了。
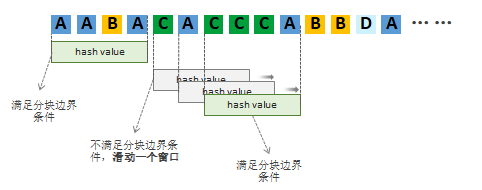
根据上述的分块方式,最终可以得出首次备份的数据串分块如下图。共分为5个数据分块,针对这5个数据分块生成hash值,value1,value2,value3,value4,value5。

如果二次备份出现数据变化的情况,那么影响范围最多只影响2个分块(变化的分块以及其后面的一个数据分块)。如下图,第2个数据分块产生数据变化仅影响其数据分块本身,重删效果较好。

如果二次备份出现新增数据的情况。如下图所示,新增数据不影响数据分块方式,需要备份的仅第一个数据分块。此外没有产生数据碎片,相比滑动窗口分块方案要更具优势。

CDC方案实际在使用过程中容易出现问题,如果固定值D、R和窗口长度设置不当,容易出现一些极端情况。比如:滑动过程中始终找不到分块边界,导致数据分块过大。再比如:滑动过程每次都匹配上了,且窗口设置较小,导致分块过多。要解决这些问题,有以下几个方案可供参考:
- 消除过小分块:设置分块的最小长度,如果在最小长度内遇到分块边界,则忽略此边界。
- 消除过大分块:设置分块的最大长度,如果在最大长度内未找到分块边界,则直接使用最大长度分块。
- 双因子分块:设置2组固定值进行Rabin指纹计算,此种方式一般是配合分块最小长度和最大长度使用,在长度区间内选择可用的指纹。
以上便是要介绍的重复数据删除技术的全部内容了,希望对大家有帮助。
作者:Q先生,“灾备有道”公众号作者,灾备行业工作多年。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞5作者其他文章
评论 1 · 赞 3
评论 0 · 赞 1
评论 1 · 赞 4
评论 3 · 赞 6
评论 4 · 赞 20
添加新评论0 条评论