DB2大数据量处理综述及关键技术探讨
第一部分 引言
本文主要探讨DB2数据库大数据量处理领域中,几种表分区技术的特点、优缺点和最佳实践。目标读者是联机业务系统和数据仓库的设计、开发、运维管理人员。
在数据库领域,有很多技术和课题需要不断学习、研究。而其中一个很重要的课题是数据规模越来越大,处理复杂度不断提高,交易量巨大的系统按照传统设计方式,效率上已经很难满足业务要求,或灵活性不够。
举例来说,一些业务系统每日的日终时把当前交易表数据归档到历史交易表,可能需要1-4小时,而且如果程序编写不规范,归档过程中还可能造成排他性使用数据的问题。
这些系统一般都存在以下问题:
1. 如何把当天交易从当前表归档到历史表,需要保证数据一致性,同时还要保证效率、减少锁的占用及日志占用量以保证并行性。怎么做才能符合要求?有没有更好的解决方案,甚至取消这个操作?
2. 如何清理过期数据。操作需要多长时间?ONLINE or OFFLINE? 清理数据怎么避免锁表?
3. 如何保证当天交易表和历史交易表的操作效率(成百万、千万条记录的当前表和上亿、甚至百亿条级别的历史表)?
这是一个涉及到数据库管理、开发的常见的也是比较复杂的问题。应对上述问题,各数据仓库厂商提供的主要解决方案,都是把数据分区(拆细),达到在一个子集上操作的效果,从而提高效率,较少锁、日志开销,降低系统资源消耗。数据分区能力的高低,也是评价一个数据库产品的重要指标之一,db2为我们提供了多种分区解决方案,有不少出色的亮点,本文就关注在这类解决方案和技术上。
第二部分 DB2提供的相关技术
针对数据量不断增大的特点,ibm主要提供了以下功能或技术:
1. 提升对单表记录条数的限制,单表空间容量的限制。
就表空间容量限制而言,ibm db2在9版之前,主要靠更大的页面大小来提供大容量,4k页面可以支持64GB,8k支持128GB,16k支持256GB,32k支持512GB。
单表记录条数限制基本受制于表空间最大容量限制。
9.1开始,引入large tablespace,可以认为空间没有上限,主要需要关注的是处理效率。
2. 表分区(即把数据分区,达到在一个子集上操作的效果),主要有以下技术:
A. union all view
视图适用的场景主要包括安全(把部分字段或特定行,开放给特定用户和应用),隔离逻辑层物理层(应用使用视图,当表结构修改时,应用或部分应用不需要修改),数据分区等。本文档主要讨论其数据分区的用法。
B. mdc表(multi-Dimensional Clustering)
我理解mdc表的最初设计思路是在数据库内部建立类似多维分析“Cube”结构的表,典型的应用场景是存放有多个维度属性(比如分支行机构代码、业务品种各级分类、产品编号、币种、资产状态)下的业务数据(比如当期、上月、上年底的余额、发生额、积数),对mdc中的数据,你可以按照任意维度组合去查询汇总信息或明细资料,而保证性能良好。注意是任意维度组合,传统表加索引的技术是无法实现的。
和cube最大的类似之处是都有块索引,不同是mdc并不在索引节点存放汇总信息。
随着mdc的技术不断进步,通用性有所增强,适应范围更广了,目前已经成为数据分区的一个重要选择。
C. range表(Table partition)
range表通过在建表脚本里指定PARTITION BY RANGE (字段1、字段2。。。)来把数据分区,相当于变成了若干对用户透明的子表,该技术从一开始就是为了数据分区而设计的。
D. 多分区技术(DPF,Database partition)
利用多分区数据库特性,把数据分布到多个分区,每个分区相当于一个小数据库。协调分区接受命令后,发送给各分区,各分区运算、处理后再把数据返回协调分区,由协调分区归并后返回给客户端。
多分区(DPF)技术通常仅使用在数据仓库系统中,联机业务系统使用极少,原因是要想利用多分区特性提高效率,应用需要专门的设计,同时开发比较复杂,较难掌控。
该技术主要适用数据仓库场景,不在本文探讨。
第三部分 上述技术的更多探讨
Ibm提供的各种技术有哪些优缺点、适用哪些场景、如何正确使用?本部分就这些技术进行探讨。
一. union all view(uav)
该技术起源较早,目前仍被广泛使用。比较普遍的用法是按年或季度或月等时间维度,把数据放在不同的表里,然后建立视图。
举例:
CREATE TABLE "ACCINFO "."ACSTHSP2008" (
"EYDT" DATE NOT NULL ,
"BBK_NUM" CHAR(2) NOT NULL ,
"BRN_NUM" CHAR(4) NOT NULL ,
"CRY_NUM" CHAR(2) NOT NULL ,
"ACC_ITM" CHAR(6) NOT NULL ,
"BAL_DR" DECIMAL(15,2) ,
"BAL_CR" DECIMAL(15,2) ,
"YR_JS_DR" DECIMAL(18,2) ,
"YR_JS_CR" DECIMAL(18,2) )
IN "HISDTA_TBS" INDEX IN "HISIDX_TBS" ;
--Check是必须的,以便告诉视图数据如何区分存放位置:
ALTER TABLE "ACCINFO "."ACSTHSP2008"
ADD CONSTRAINT "C_EYDT" CHECK
(EYDT BETWEEN '2008-01-01' AND '2008-12-31')
ENFORCED
ENABLE QUERY OPTIMIZATION;
-- 历史表视图,可读可写,主要提供给数据处理程序使用。
CREATE VIEW ACCINFO.V_ACSTHSP AS
SELECT * FROM ACCINFO.ACSTHSP2008
UNION ALL
SELECT * FROM ACCINFO.ACSTHSP2009
UNION ALL
SELECT * FROM ACCINFO.ACSTHSP2010;
由于该视图的每个基表都有check限定c_eydt的起止日期,这些日期段没有交叉,又完全覆盖所有日期,所以该视图可读可写,无论插入、更新还是查询,都能准确定位到哪一个或一些基表。
Uav的优点:
1. 每个子表可以有自己的索引。
2. 可读可写视图,按视图select/insert/delete/update只要指定eydt条件,就可以定位到具体的表,减少了数据范围,达到了数据分区的效果。
3. 历史数据清理简单。Drop table重新建立view就可以了,但是不能online。
缺点:
1. 视图下不能有太多子表,建议最好6、7个子表以下,不要超过10个,再多可能导致语句堆满无法执行,或者失去数据分区作用(无法定位到基表)。
2. 数据分区有限,一般拆到季度就不错了。
3. 到了最后那年,需要建立新表和重建视图,如果不做会出错,而且做的时候要短暂停应用。
4. 清理一个子表的数据虽然简单(必需按表清理),但是也需要重建视图,需要短暂的停止应用时间。
5. 出于效率考虑,数据量大到一定程度就需要建立专门的当前表,造成应用处理无法统一,而且当前表必须要归档到历史表,开销很大,同时开发这类程序需要一定的技巧,才能保证完整性、尽量少的锁占用(以较少对并行性的影响)、合理的日志开销、良好的效率。
6. 当前、历史表这种规划模式,在使用过程中对统计信息依赖性很强,必须在数据大量变动后马上收集统计信息,才能保证后续应用的效率。
适用场景:
一般当前表数据量达到几百万、上千万,历史表是当前表的100期量级数据。历史表3-5张就够用。此时可以用历史表+当前表的设计。
如果数据量再小一些,也许只用历史表,不需要当前表,也能保证效率,并提供应用层统一的处理,转历史就不需要了,过期数据清理也比较容易。
uav是一种比较传统和稳妥的处理方式,一直被广泛采用。在使用过程中也暴露出统计信息收集不及时,会造成历史数据归档后可能出现优化器算法不优化的问题。
二. Range表
Range表相当于把大表拆成若干子表。相对简单的一种技术。
建表脚本举例:
CREATE TABLE SALES(SALE_DATE DATE, CUSTOMER INT,...)
PARTITION BY RANGE(SALE_DATE)
(STARTING ‘1/1/2006’ ENDING ‘12/31/2006’,
STARTING ‘1/1/2007’ ENDING ‘12/31/2007,
STARTING ‘1/1/2008’ ENDING ‘12/31/2008’,
STARTING ‘1/1/2009’ ENDING ’12/31/2009’);
这样,会把数据拆分到四个子表,这些子表由系统自动管理,用户不能直接使用(也不需要)。会有一个block index指向每个子表。
看起来代替历史表union all view 比较合适。和UAV比较起来,range除了没有local index(DB2V9.7已经提供local index支持了),似乎没有其他缺点了。
优点:
1. 代替uav比较合适,可以突破只能有几个子表的限制,而且子表对用户透明,维护、管理得到简化。
2. 不同子表可以选择不同表空间,利用不同性能的存储。
3. 如果能够拆细到日(严格说是拆细到当前表的数据时间周期),那么当前表就不需要了,当前数据归档到历史表这个重量级操作就没有了。
4. 增加了range partition锁粒度,不会升级到表锁,不妨碍其他子表的访问。(但对于本子表来说,还相当于表锁。)
5. 提供了attach/deatch方法,把子表贴上来或者拆离。对于数据清理非常方便高效,且可以online。
6. 相当于按分区键建立了索引,按分区键做汇总或全量查询效率好。其实就和UAV一样,但uav不能把数据分区分太细。
缺点:
1. 子表不能太多,个人建议一般1000个以内比较保险,同时整个数据库不能有太多这种表,否则系统表开销可能会太大。
2. 空的子表也要2个extent, 和普通表一样。而且空间预先分配的。
3. range需要精确指定每个子表的条件, 比如按年, 你也许需要写到2015年, 到2015年你需要alter table。比如按分行, 新增分行时你也需要通过alter table增加该新分行的子表。
4. PARTITION BY RANGE字段数量不能太多,最好只有一个字段,多了插入效率下降。
5. 清理历史数据不能用delete,而是需要用detach,才能保证效率和系统开销以及并行性。对于程序开发不透明。detach一般可以在非业务高峰期联机做,db2非常高明地做到了索引异步重构,而且重构过程中完全可以一切正常地使用。
6. 9.1/9.5版本还没有local index(不过9.7里就有了,而且可以进行子表压缩。),导致索引效率不如UAV。
7. attach操作要慎重,一般attach到历史表不建议,因为历史表数据量巨大,重构索引成本太高,除非你用9.7,并且仅有local index而没有全局索引,这样才不需要索引重构。
最佳实践:
每个range的数据量,最好最少也能有50M,或者准确说填满一个extent,如果有几GB会比较好;最好控制在1000个range以内比较保险,一般range数量达到2500个以后效率开始下降;最好只有一个分区字段,多了插入效率变差。
三. Mdc
建表脚本举例:
CREATE TABLE TestTable
(A INT, B INT, region INT, year INT 。。。)
ORGANIZE BY DIMENSIONS (regin,year)
该例中,对region和year的每个组合,建立一个cell,该cell由若干block组成,每个block在物理存储上是一个extent。
DBMS会帮你建立3个block index,on region、year、(region、year)。
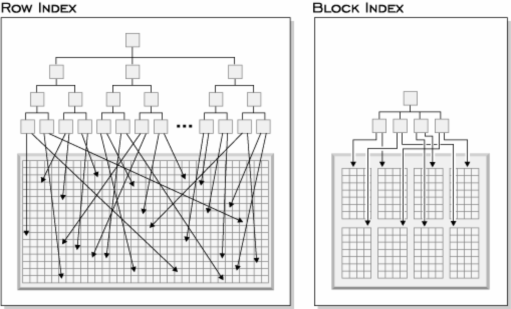

优点:
1. 基本上Range能做到的mdc也能做到。不过mdc没有local index,也不能按cell压缩。
2. Mdc可以有更多ORGANIZE BY DIMENSIONS字段,效率不会下降。当然每个cell下要有足够多的记录满足至少填满一个extent的要求。
3. 没有空cell的空间开销,事先是不存在的,新开cell时才分配空间。用到才分配空间这种做法,不需要担心效率,普通表新增extent时也是这样的,有开销但不大,同时不经常发生。
4. 从建表语法上可以看出,不像range,要指定每个子表的条件,而是指定区分cell的字段集。不必像range那样担心新的一年到来是否需要修改range定义,mdc加新cell是自动的。
5. Mdc的block index的cluster属性是最好的,比cluster index更好。而且Reorg index/table永远不需要。
6. 按块索引查找或汇总数据,效率非常好。
7. Mdc的不同cell的数据插入,可以并行,注意是并行的一个手段(要用好是有讲究的,在后面讲述),而range是按子表来顺序处理的。这也是mdc的一个突出优势。
8. 清理数据比较方便,继续使用delete来清理数据(where条件必须是分区键的子集或全集),通过设置db2set MDC_ROLL_OUT=on可以达到数据“roll_out”的效果,通过设置db2set MDC_ROLL_OUT=defer,可以达到数据“roll_out”,同时索引清理异步的效果。
所谓数据“roll_out”,指的是仅使用少量锁(锁粒度block),少量日志(非常少),较低的系统开销,很快的操作速度,可以联机的特性。
索引异步清理,指的是delete操作在极短的时间内完成,索引不立即清理/重构,delete完成后才启动后台的索引重构,我们测试和使用的经验是,整个过程没有出现读到脏数据或无法访问其他cell数据的情况,也没有出现无法利用正在重构的索引的情况,一切都合乎逻辑,Perfect! 索引重构也许需要几分钟甚至更长时间,取决于数据量,我们发现即使数据量达到几百GB,也没有发现资源严重消耗或阻塞应用的情况。
9. 拆细到日(严格说是拆细到当前表的数据时间周期),那么当前表就不需要了,当前数据归档历史这个重量级操作就没有了。
缺点:
1. Mdc有时需要generated column,此时优化器可能不灵。需要格外注意。
2. 不能按cell压缩。整表压缩有以下顾虑:压缩表被update后较容易产生溢出,而溢出情况下在db2早期版本中容易出现优化器误认为nested loop join比hash join效率好。
使用注意事项:
1. range可按range partition粒度进行锁升级(避免表锁),mdc也有这种机制,但由优化器选择:
insert 靠 alter table locksize blockinsert
delete 靠 DB2_MDC_ROOLOUT=YES 或deffer。
update完全靠优化器决定。
2. mdc可以设置 alter table locksize blockinsert, 来选择插入时是行锁还是block锁, 需要慎重地合理设置。
已经提过,mdc一个优势是并行插入。其前提是:要求多个并发事务, 每个并发事务插入一个分组的大量数据(不同并发事务不能插入同一分组), 这种情况下利用blockinsert可以达到并行提高效率。
但是如果不同并发插入相同分组数据,那么建议不要用blockinsert, 否则会开辟很多block, 可能造成空间浪费及效率下降。这种情况下还是用行锁更稳妥。
3. Db2set MDC_ROLL_OUT的可选值,在9.1中只有on/off,来规定数据“roll_out”,但索引必须同步重构,造成排他性问题,时间也比较长,且消耗大量日志,大量锁。9.5增加了deffer选项,达到索引异步重构的效果,这是一个非常重要的选项,甚至因为这个选项和能力,你需要放弃9.1而升级到9.5或以上。
4. 如何验证一个delete语句是否会用”roll_out”?
在db2expln中找“CELL DELETE” 。
5. V95之后,在delete命令发出之前,可以通过命令修改Delete statement special register来确保DEFER的索引清除:
SET CURRENT ROLLOUT MODE DEFERRED CLEANUP
Mdc的最佳实践:
首先了解一下mdc表的空闲页面机制和特点。
Mdc表的空闲页面结构设计和搜索算法与传统表不同。mdc空闲页面查找开销更大,传统表每500个页面有一个空闲列表,而mdc每个cell下的每个block都有空闲页面信息。一个block对应数据库表空间的一个extent。Mdc插入效率和传统表的差异,是由空闲页面搜索的成本决定的,mdc的空闲页面搜索成本由2部分构成,第一部分是确定使用哪一个cell,第二部分是查找该cell下的适合的空闲block,其中第一部分成本相对较低,而第二部分,随着数据量增长,block数量增长,成本会越来越大。这部分成本,准确地说,是和block,即extent的数量相关,同样的数据量,extent size越大,block越小,成本也就越小。
您可以做一个测试,每次插入一条记录(都插入到一个cell中),然后commit,不断地循环,记录每个事务的耗时,用耗时做一条曲线(柱状图),你会发现基本上耗时是固定的,比如1ms,当达到1万个extent时,开始出现个别事务耗时很长,出现尖刺,extent越多则尖刺越多,同时尖刺高度越大。假设记录每分钟的事务数,则在1万个extent之后,每分钟事务数总体趋势会急剧下降。
假如你建立另外一个表空间,其extent对应的空间大小和刚才不一样,你会发现性能基本上只和extent数量相关。
最佳实践:
1. 当一个cell里面数据量非常少时(填不满一个block),会发生非常严重的空间浪费和效率下降。
2. 当一个cell里数据量很大的时候,插入效率会急剧下降,甚至下降一两个量级。一般一个cell下面block数量达到1万个这个数量级时,会开始出现性能下降。尽量不要超过1万个block。
3. 有多少个cell似乎不用过分担心,至少2000个cell是没有问题的。
4. 为保证插入效率,您可以做的包括如下要点,都是围绕减少block数量来设计的:
a.合理设置mdc key,保证每个cell下数据量不会太多或太少。Mdc key多一个字段,则cell数会变多,同时最大的cell下的block数量会下降。
b.使用更大的pagesize,更大的extent size。
c.启用表压缩。
5. 如果通过上述方法block数量无法降低到1万这个数量级,可以设置db2set DB2_TRUST_MDC_BLOCK_FULL_HINT,多数情况下能解决问题或大大缓解。该参数的含义大致解释一下,在搜索空闲页面时,充分相信上次搜索到的第一个有空闲页面的block指针(即前面没有空闲页了),从这里为起点向后找就可以了。该方案的不足是,如果经常有比较大量数据删除的时候,无法重用删除带来的可用空间。除非删除很频繁且删除的数据量很大,则该设置只会带来好处。个人建议,经过评估后,即使block数量不会超过1万个,也要设置这个参数。
我们的实践是该参数有很大帮助。测试表明,数据量在2万到3万个block的时候,效率下降到1/2,在7万个block的时候,效率下降到1/4。和普通表相比,数据量很小的时候,mdc插入效率和普通表差不多,但是普通表没有发现数据量增长后插入效率明显下降的情况。
6. 如果还是不行,考虑range partition和mdc的组合使用,可以大大减少每个cell下的block数量。但一个稳妥起见的建议是,先把range partition和mdc都从理论到实践搞熟练了,才考虑组合使用。
7. 在db2V9.5版本或更高版本上使用mdc,并设置Db2set MDC_ROLL_OUT为deffer,来获得使用delete命令删除一个或多个cell时,异步的索引重构。这是可以充分信赖的好方法。
第四部分 几个小提示
1. Range和mdc,和多分区(DPF)表比较,需要数据在不同子表、cell间均匀吗?
不需要。但是每个range的子表,每个mdc的cell,下面的数据量都不要太少,避免连一个extent都填不满的情况。另外对于mdc,最大的cell,extent数量最好不要太多。
2. Range/mdc都不要update分区字段。
3. 如何确定会有多少个range子表或mdc cell?以及每个子表或cell下有多少记录?
假设现在已经有一个普通表tb1( a, b, c, d),共四个字段,你希望改造成以a、b两个字段做分区的range或 mdc,那么做这样的查询:
Db2 –v “select a, b, count(1) as count from tb1 group by a,b order by 3”
输出大概是这样:
A B count
-----------------
1 1 2000
1 2 2035
2 1 2080
1 3 2900
--------------------
(4) rows selected
那么我们就知道:
会有4个子表或cell,每个子表或cell的记录数,最少的2000,最多的2900。你可以知道,记录数比较少的有多少个子表或cell,记录数比较多的有多少个子表或cell。
如果没有现成的表,就根据上述逻辑,结合业务情况进行推算。
第五部分 总结
本文阐述了解决大数量处理效率的几种主要技术方案。总体来讲,Uav,range,mdc都是把数据分细的技术,就分细的程度来说,uav可以分细到1/10左右,range可以分细到1/1000这个量级,mdc可以分到更细。但是在使用时要注意,要利用分细的效果达到缩小搜索范围的目的,查询的时候需要把分区字段(uav的基表check条件字段,range、mdc表的分区字段)包括在where条件里,否则的话,效果未必能达到普通表的水平,这其实是对应用和设计规划提出了要求。
这几种技术,在oltp和bi、olap类应用中都可以使用。推荐做法如下:
一. Range代替UAV是趋势,db2V9.7的range有了local index之后,个人认为通过uav建立数据分区的用法可以退休了(uav的其他用途还是可以继续使用的)。
二. 如果使用range不能仅建立local index,还需要建立全局索引的话,需要考虑是否Mdc更合适,原因是mdc可以把数据拆分得很细(很多cell),以及额外的块索引带来的好处。
三. 9.7版之后range在联机系统和数据仓库系统都可以考虑使用。原因是有local index和子表压缩两大优势。
四. 数据仓库系统更有机会利用mdc的并行插入特性,但是mdc没有local index,无法按cell压缩。可以考虑使用UAV+mdc。或range+mdc。
五. 先把range和mdc使用熟练,才考虑使用range+mdc,尽量避免复杂化,保证一切尽在掌控中。
六. mdc在db2V9.5版本或更高版本上使用,并设置Db2set MDC_ROLL_OUT为deffer。强烈建议,这个特性太棒了。
七. 使用mdc的时候,分区字段除了日期以外,尽量再选择一到二个其他字段(保证cell有足够数据量的前提下),保证每个cell下block数量不会太大。同时可以享受到并行插入的好处(在bi、olap这样的系统中尤其有用,用法前面已经介绍),发挥mdc的最大优势。还有一个好处是查询能够利用block index的机会也会大大增加。
本文节选自《数据库与信息治理》,作者:招商银行数据库管理团队经理 田永江
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞0作者其他文章
评论 5 · 赞 3
评论 1 · 赞 1
评论 2 · 赞 4
评论 0 · 赞 0
评论 1 · 赞 0
添加新评论0 条评论