DB2深度健康检查系统设计与实现
1. 前言
“天呐,又要对几百台服务器做巡检了~~”,做IT运维人员的时候,是不是经常听到这样的抱怨?是啊,每次巡检都要登录机器,收集数据,登出机器,而后再登录机器,收集数据,登出机器…循环上百次操作,几天下来,人都成了木头人,能不苦闷嘛。那么,在这篇文章里,我将以亲身经历为大家介绍一下如下能开发一个既功能强大,又方便维护的DB2自动巡检工具了,暂且为它取名为“DB2深度健康检查系统”。
作为DBA来说,虽然说遇到突发问题时解决问题的能力非常重要,但是日常对系统进行巡检的工作更是尤其的重要。对于生产系统,DBA的日常运维工作主要是对系统进行巡检,提早发现问题并解决问题,而不是等到系统出现问题以后再来解决,所以对于DBA来说有一套成熟的深度健康检查系统可以大大的解放DBA的生产力。
2. 功能模块
就功能而言,本系统主要分为五大块:数据收集,数据分析,指标扩展,报表展示,系统管理,整个系统结构如下图所示。

图1 DB2深度健康检查系统结构图
数据收集子系统通过连接到所有需要检查的数据库去收集必须的数据,收集方法可以是优先通过JDBC调用存储过程或者查询系统视图,如果不能通过JDBC完成,再考虑执行系统命令或分析文本等,收集时间可以是手动触发或者定时执行。为了日后报表出的比较详尽,在数据收集阶段尽量收集较多的数据,然后将收集到的数据自动录入到系统数据库中。数据收集子系统功能如图2所示。
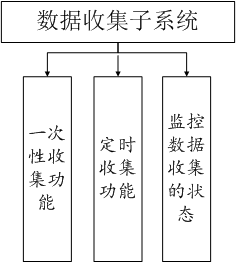
图2 数据收集子系统功能图
数据分析子系统主要针对收集到的数据进行分析,根据每个定义的指标,得出健康状况,其功能如图3所示。

图3 数据分析子系统功能图
报表展示子系统主要是数据和监控状态以报表的形式展示出来。报表展示子系统功能如图4所示。

图4 报表子系统功能图
除了这些基本功能,为了方便扩展指标,我们还需要考虑再设计一个扩展模块子系统,其作用是允许开发人员在不改变原有代码的基础上对新增指标进行扩展,其基本功能如图5所示。

图5 扩展模块子系统功能图
除了这些基本功能子系统,为了便于管理,这个系统还应该有一些基本的管理功能,其功能如下图6所示。

图6管理子系统功能图
3. 检查指标
除了基本功能的开发,我们所碰到的另外一个最大的难题便是确定检查指标。因为指标设计的好坏决定了整个系统的实用性和权威性,所以我们根据我们的具体需求和实际情况,总结出了以下三十多个指标。
1. 重组表检查
检测方法:call REORGCHK_TB_STATS(‘T’,’ALL’)
指标阈值:无
指标意义:检查需要对哪些表做重组
2. 重组索引检查
检测方法:call REORGCHK_IX_STATS(‘T’,’ALL’)
指标阈值:无
指标意义:检查需要对哪些索引做重组
3. 统计信息检查
检测方法:检查syscat.tables的stats_time字段距现在的时间
指标阈值:无
指标意义:对没有启动自动runstats的库进行检查
4. db2diag.log检查
检测方法:SYSPROC.PD_GET_DIAG_HIST
指标阈值:无
指标意义:检查是否有严重的报错日志
5. DB2内存检查
检测方法:SYSPROC.ADMIN_GET_DBP_MEM_USAGE(-1)
指标阈值:<=50%
指标意义:检查DB2的总内存占系统总内存的百分比是否合理
6. DB2参数检查
检测方法:sysibmadm.dbcfg和sysibmadm.dbmcfg
指标阈值:无
指标意义:根据上线文档进行比对
7. 缓冲池命中率
检测方法:sysibmadm.BP_HITRATIO
指标阈值:优秀>95% 良好>80%
指标意义:检查当前的缓冲池命中率
8. 锁等待,锁升级,死锁
检测方法:sysibmadm.snapdb
指标阈值:无
指标意义:检查锁等待、锁升级和死锁的情况
9. 排序溢出
检测方法:sysibmadm.snapdb
指标阈值:<=1
指标意义:检查是否有排序溢出的情况
10. SQL性能分析
检测方法:Total execution time/Num of excutions
指标阈值:<1ms
指标意义:分析整体SQL的读写是否正常
11. SQL语句分析
检测方法:sysibmadm.snapdyn_sql
指标阈值:无
指标意义:分析执行时间最长的SQL
12. 表状态检查
检测方法:
select substr(tabschema,1,10) as tabschema,substr(tabname,1,30) as tabname,status,type from syscat.tables where status != 'N'
指标阈值:Status != 'N'
指标意义:找到状态不正常的表
13. 有效索引读
检测方法:
select Rows_read / (Rows_Selected+1) as IREF from sysibmadm.snapdb
指标阈值:OLTP<=5 SAP系统<=3
指标意义:多少行属于有效的读取
14. 包缓存命中率
检测方法:1-(Package Cache Insert/Package Cache Lookup)
指标阈值:1,或者能够长时间接近1的稳定数值
指标意义:有多少查询语句可以直接在包缓存中找到
15. 平均结果集大小
检测方法:
select ROWS_SELECTED/(SELECT_SQL_STMTS+1) as Avg_Result_Set from sysibmadm.snapdb
指标阈值:OLTP<=10
指标意义:平均每条Select SQL语句返回的结果行数
16. 同步读取比例
检测方法:
select 100-(((pool-async_data_reads+pool_async_index_reads)*100)/(pool_data_p_reads+pool_index_p_reads+1))as SRP from sysibmadm.snapdb where DB_NAME = 'DB1'
指标阈值:OLTP>=90%
指标意义:数据库同步读的比率
17. 数据、索引页清除
检测方法:async writes/total writes
指标阈值:>=95%
指标意义:页面清除进程(线程)是否能够有效地将脏页在后台刷入磁盘
18. 脏页偷取
检测方法:
select POOL_DRTY_PG_STEAL_CLNS from sysibmadm.snapdb
指标阈值:>10
指标意义:系统的脏页偷取过多
19. 缓冲区读写I/O响应时间
检测方法:
select tbsp_name,(POOL_READ_TIME /(POOL_DATA_P_READS + POOL_INDEX_P_READS +POOL_TEMP_DATA_P_READS +POOL_TEMP_INDEX_P_READS +1) as TSORMS from sysibmadm.snaptbsp order by TSORMS desc fetch first 10 rows only
指标阈值:1~10ms
指标意义:找出读时间最慢的表空间
20. Direct I/O时间
检测方法:
select DIRECT_WRITE_TIME/DIRECT_WRITES from sysibmadm.snapdb
指标阈值:1~10ms
指标意义:查看直接读数I/O时间
21. 编目缓冲区命中率
检测方法:catalog cache inserts/catalog cache lookups
指标阈值:0,或者接近0的数值长时间维持稳定
指标意义:调整catalogcache_sz大小
22. 排序溢出比例
检测方法:sort overflow/total sorts
指标阈值:0,或者接近0的数值长时间维持稳定
指标意义:查看是否有排序溢出
23. 平均排序时间
检测方法:total sort time/total sorts
指标阈值:远小于系统预期平均语句的执行时间
指标意义:平均每次排序所消耗的时间
24. 平均每条交易的排序次数
检测方法:total sorts/(Commit statements attempted +Rollback statements attempted)
指标阈值:OLTP<5
指标意义:查看每条交易所需排序数量
25. 总的事务数量
检测方法:commit statements attempted +Rollback statements attempted
指标阈值:无
指标意义:查看交易事务总量
26. 每个事务包含的查询SQL语句数量
检测方法:查询语句总数/交易总数
指标阈值:OLTP<=10
指标意义:查看每个事务的SQL语句数量
27. 每个事务包含的增删改语句数量
检测方法:
select decimal(UID_SQL_STMTS)/decimal(COMMIT_SQL_STMTS +ROLLBACK_SQL_STMTS+1) as uidpertxn from sysibmadm.snapdb
指标阈值:OLTP<=5
指标意义:查看每一个事务使用的更改语句
28. 每个事务返回的结果集行数
检测方法:选择的行数/事务总数
指标阈值:尽量接近得到的数据集
指标意义:查看每个事务返回的结果集行数
29. 每个事务返回的读的行数
检测方法:读取的行数/事务总数
指标阈值:OLTP尽量靠拢前一个指标
指标意义:查看每个事务读取的行数
30. 每个事务需要的缓冲区逻辑读
检测方法:逻辑读总数/事务总数
指标阈值:OLTP尽量低
指标意义:查看每个事务需要的缓冲区逻辑读
31. 每个事务需要的索引逻辑读
检测方法:逻辑索引读总数/事务总数
指标阈值:OLTP尽量低
指标意义:查看每个事务需要的索引逻辑读
32. 日志写入数度
检测方法:日志写时间/日志写次数
指标阈值:<3
指标意义:查看日志写的速度
33. CPU 内核/内存比例
检测方法:
select TOTAL_MEMORY/TOTAL_CPUS from SYSIBMADM.ENV_SYS_INFO
指标阈值:4~8G
指标意义:平均每个CPU可使用的内存数
34. 表空间状态检查
检测方法:
select TBSP_ID,TBSP_NAME,tbsp_state from SYSIBMADM.TBSP_UTILIZATION
指标阈值:tbsp_state = 'NORMAL'
指标意义:检查表空间状态是否正常
35. Package状态检查
检测方法:db2 "select VALID from syscat.packages"
指标阈值:VALID = 'Y'
指标意义:检查Package状态
36. 数据库大小
检测方法: call get_dbsize_info(?,?,?,-1)
指标阈值:<60%
指标意义:检查数据库总大小
4. 系统实现
在实现上,为了降低耦合度,增大系统的灵活性,我将这个系统分为HealthCollector,HealthReporter,HealthODS和PolicyExtender四个子项目,这四个子项目的关系如下所示:

图7子系统管系统
其中HealthODS子项目主要是封装对数据库的操作,可以采用ORMapping的技术,屏蔽掉不同数据库语法的差异。同时该子系统还包含数据库连接池,数据库密码的加密解密功能,其基本类包括DAO类,BO类和ConnectionFactory类。主要功能类关系如下所示:

图8 HealthODS子项目的类图
HealthCollector子项目主要是实现数据收集的逻辑,主要类只有一个叫HealthCollector,其基本功能就是实现数据收集流程,调用PolicyExtender子系统完成数据收集。
从下面功能类图中可以看出,HealthCollector类的入口函数是run()函数,在run()函数里调用createCheckInfo()函数保存这次检查的信息和结果,接着调用initclient()初始化数据库连接,最后调用startCollect()函数完成对各个指标的收集。startCollect()函数实际上调用的是PolicyExtender子项目的方法,为了能降低的指标的开发量,在实现上有多个地方需要使用反射来实现。
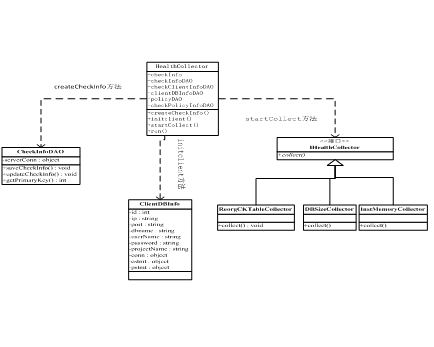
图9 HealthCollector子项目的类图
HealthReporter子项目的主要功能是报表的展现,类图如下图所示:

图10 HealthReporter子项目的类图
从上面的功能类图可以看出,ReportAction类中的listCheckInfo()、listReorgCKTableByDBandCheckinfo()、generateReport()和showReport()函数来完成HealthReporter的主要功能。generateReport函数调用Reportservice类中的generateReport()函数,然后通过generateReport()函数分别调用ReorgCKTableDAO类、ClientDBInfoDAO类和CheckResultDAO类来创建检查报告。ListCheckInfo函数通过调用CheckInfoDAO类中的getCheckInfo()函数来获取CheckInfo类的检查操作的相关信息。showReport()函数通过CheckResultDAO类中的getCheckResult()方法来获得CheckResult类中相关数据库的检查结果。listReorgCKTableInfoByDBandCheckinfo()函数通过调用ReorgCKTableDAO类中的getReorgCKTableInfoByDBandCheckinfo()函数来获得ReorgCKTable类中关于Reorg检查的相关信息。
5. 总结
在准备做这个系统之前,我们曾经考察过一些工具,希望能有一些现成的产品可以支持DB2的健康检查,但是结果令人失望。这篇文章虽然只有寥寥几页,但是希望可以激发出一些有志青年,投身于自动化健康检查的实现,填补这块市场的空白!
本文节选自《数据库与信息治理》,作者:民生银行 朱彬、王帅、甘荃
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞3作者其他文章
评论 1 · 赞 0
评论 2 · 赞 4
评论 1 · 赞 1
评论 0 · 赞 0
评论 1 · 赞 0
添加新评论5 条评论
2015-12-11 17:22
2015-11-17 08:03
2015-11-17 08:02
2015-11-10 17:14
2015-11-05 15:55