分布式数据库先行者使用之后的思考与架构变化,从存算一体走向存算分离
近日,与一机构交流,分布式数据库划分为近100个分片,生产中心3副本,同城3副本,异地2副本,合计8副本,单台服务器配置4块3.2TB NVMe SSD,本地盘做软RAID10(又除2副本),16份。单分片独享这组服务器,受数据库单分片限制,一般单片就1TB有效数据,1TB/4/3.2TB就7.8%,除以本地3副本,利用率就2.5%!利用率低到令人惊讶。(单台服务器4块盘,假如单盘0.8万,3.2万成本,实际有效数据量就1TB,相当于3.2万/TB,这个远比现在高端闪存存储还贵)。数据库节点接近500台服务器,业务交易峰值就近3000多TPS,单分片节点分担不到40TPS,CPU利用率也很极其的低。
数据库可以灵活配置本地和同城的任意副本同步返回就返回给上层代理节点。 因为主节点本地盘就那么四块盘,加上跨同城IP网络复制,性能影响大,特别是晚上跑批压力更大,其它从节点盘也承担不了压力,就在那里“看”,平时CPU利用率很低。本地盘出现过慢盘,超时盘,数据库节点就快速的踢掉此服务器节点,业务切换到新的主节点,系统告警,接下来恢复操作很复杂。首先,这台服务器故障了,需要再取新的空闲机器,重新安装系统,数据库软件,接入系统为从节点,第二步,为了不占用生产网络带宽,此数据库要从前一天的备份系统恢复数据,然后从主节点追增量数据,直到一致。重建副本得多长时间?而且还要流控不影响正常业务,不影响跑批。因为一块慢盘故障,干掉整个服务器,就带来一系列复杂善后工作,值得不?10几年前做存储系统踢盘都严苛,简单粗暴的踢盘会带来巨大的恢复工作,更别说要踢CPU了。
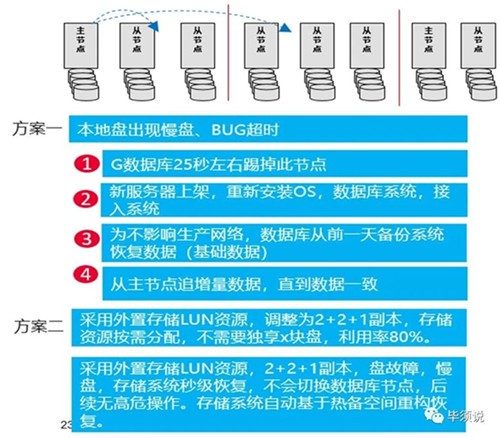
客户讲,基于这些问题,为提升资源利用率,节约成本,提升可靠性,除了这个已经上线的关键生产系统,其它系统全面采用G数据库+外置企业存储Dorado方案,已经上线了支付系统等A类系统。采用数据库+外置存储方案:
1,挂的盘更多,统一整合做了RAID2.0池化均衡,上限性能更高,不会出现瓶颈,跑批就不影响。
2,外置存储利用率高达80%,按需分配,跟CPU解藕,可靠性高,可以减少副本,不需要堆那么多SSD盘和服务器资源,节约成本,8副本副本减少到2+1+1副本,软件许可也减少了。
3,可靠性方面,盘级故障专业存储都能秒级快速隔离,不会导致数据库节点切换,后续那些复杂善后操作就不需要了,凌晨3点也不需要起来跟领导汇报如何做高危操作。
4,假如服务器因为内存等因素故障了,将外置存储LUN映射给新服务器,追增量数据,不需要从备份重建副本基础数据操作。
仔细看看,有些厂家想当然的认为服务器便宜,就不管利用率,不去思考软件架构怎么提升利用率和效率来减少成本,就不断堆副本资源,想当然的认为成本没问题,多副本成了分布式架构的最顶级牛逼特性,软件工程和算法怎么会堕落到以写多副本为荣!当下经济下行,还能这么铺张吗?
因为本地盘IO能力有限,容量有限,因为网络复制性能影响较大,就不断的堆服务器CPU资源,不断增加1主多从的服务器,这个逻辑也是很奇特的,CPU其实更贵,SSD拉CPU下水玩,成本更高。其实现在鲲鹏服务器的算力是很强的,测试过1主两从,性能可以干到1.8万TPS,结果整这么多分片,如果做到均衡的话,单节点才不到40TPS的压力,这是为何呢?硬件其实是金刚钻,而软件系统感觉用成了是“烧火棍”。
守正创新,不切实际的乱创新、伪创新,只会给金融机构带来巨大的风险和损失,还是要实事求是。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞1作者其他文章
评论 0 · 赞 2
评论 1 · 赞 0
评论 0 · 赞 1
评论 1 · 赞 1
评论 0 · 赞 4
添加新评论0 条评论